在深度学习中,我们常见的数据类型主要有两大类:图像数据和序列数据。
对于图像数据,像素在空间上具有强烈的局部相关性,因此我们通常采用卷积神经网络(convolutional neural network, CNN)来捕捉这种空间结构特征。卷积层能够有效提取相邻像素之间的模式,如边缘、纹理或形状。
而另一类更具时间或顺序特征的数据------例如文本、语音、时间序列传感器读数等------则属于序列数据(sequential data)。这类数据的核心特征是:当前的信息往往依赖于之前的上下文。单靠独立处理的神经网络结构(如全连接网络或 CNN)难以建模这种依赖关系。因此,我们需要一种能够在时间维度上传递信息的模型------这正是循环神经网络(recurrent neural network, RNN)登场的场景。
在自然语言处理中,文本就是一种典型的序列数据。为了让神经网络能够理解和处理文本,我们首先需要把原始的自然语言转化为模型可接受的数值化形式,而这一步的核心就是------文本预处理(text preprocessing)。
本文将以经典的英文小说《时光机器》(The Time Machine)为例,演示文本从原始文件到"词元化(tokenization)"这一关键过程的完整实现,并逐步解释其在后续 RNN 语言模型训练中的作用。
本文的内容复现了《动手学深度学习pytorch版》的第八章:循环神经网络的第二节:文本预处理。其以从H.G.Well的时光机器科幻小说作为文本数据集,笔者最近抽空看完了,打算在知乎连载下双译版本,对此科幻小说感兴趣可在知乎上阅读双语小说。
知乎地址如下:专栏科幻小说分享

本文使用脚本 tm_preprocess.py 复现了《动手学深度学习》(D2L)第 8.2 节"文本预处理"的完整流程。该脚本的目标是将英文小说《The Time Machine》从原始文本转换为可供深度学习模型使用的数字化语料,主要包括数据下载、清洗、分词、词表构建和索引化几个步骤。首先从 D2L 官方数据源下载小说文本,并通过 SHA1 校验保证文件完整可靠;若本地已有并验证通过,则直接复用。接着,对文本进行基础清洗,仅保留英文字母、统一转为小写并去除多余空格,使数据更加规范。在此基础上,tokenize() 函数将文本拆分为词元,可选择按单词或字符进行分词,生成一个二维列表(每行对应一行文本的词元序列)。随后,Vocab 类统计词频并构建词表,为每个词元分配唯一索引,同时保留 标记以处理未知词,并支持过滤低频词。
最后,通过 load_corpus_time_machine() 将所有词元映射为索引,得到一维整数序列(corpus),实现文本的数字化表示。函数同时返回词表对象 vocab,方便后续模型使用或反查词元。脚本末尾还输出若干示例,展示了各步骤的执行结果。
完整代码如下:
python
import os
import re
import hashlib
import urllib.request
import collections
from typing import List, Tuple
DATA_DIR = os.path.join(os.path.dirname(__file__), "data")
URL = "http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt"
FNAME = "timemachine.txt"
SHA1 = "090b5e7e70c295757f55df93cb0a180b9691891a"
def _sha1(path: str) -> str:
h = hashlib.sha1()
with open(path, "rb") as f:
while True:
b = f.read(1 << 20)
if not b:
break
h.update(b)
return h.hexdigest()
def download_time_machine() -> str:
"""下载到本地 data/ 目录,如果已存在且校验通过就直接复用。返回本地路径。"""
os.makedirs(DATA_DIR, exist_ok=True)
fpath = os.path.join(DATA_DIR, FNAME)
if os.path.exists(fpath) and _sha1(fpath) == SHA1:
return fpath
print(f"Downloading {fpath} from {URL} ...")
urllib.request.urlretrieve(URL, fpath)
# 校验
if _sha1(fpath) != SHA1:
raise RuntimeError("SHA1 校验失败,文件可能不完整。")
return fpath
def read_time_machine() -> List[str]:
"""读取文本并做基础清洗:仅保留字母,转小写,strip。"""
path = download_time_machine()
with open(path, "r", encoding="utf-8") as f:
lines = f.readlines()
# 与课本一致的清洗
return [re.sub("[^A-Za-z]+", " ", line).strip().lower() for line in lines]
def tokenize(lines: List[str], token: str = "word") -> List[List[str]]:
"""按单词或字符进行词元化。"""
if token == "word":
return [line.split() for line in lines]
elif token == "char":
return [list(line) for line in lines]
else:
raise ValueError(f"未知 token 类型: {token}")
class Vocab:
"""与课本一致的词表实现"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
tokens = tokens or []
reserved_tokens = reserved_tokens or []
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 0 号位保留给 <unk>
self.idx_to_token = ["<unk>"] + reserved_tokens
self.token_to_idx = {tok: i for i, tok in enumerate(self.idx_to_token)}
for tok, freq in self._token_freqs:
if freq < min_freq:
break
if tok not in self.token_to_idx:
self.idx_to_token.append(tok)
self.token_to_idx[tok] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(t) for t in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[i] for i in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens) -> collections.Counter:
"""统计词频;支持二维 tokens(行 → 词元列表)。"""
if len(tokens) == 0 or isinstance(tokens[0], list):
tokens = [t for line in tokens for t in line]
return collections.Counter(tokens)
def load_corpus_time_machine(max_tokens: int = -1, level: str = "char") -> Tuple[List[int], Vocab]:
"""返回扁平化后的索引序列 corpus 以及词表 vocab。"""
lines = read_time_machine()
tokens = tokenize(lines, token=level)
vocab = Vocab(tokens)
corpus = [vocab[t] for line in tokens for t in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
if __name__ == "__main__":
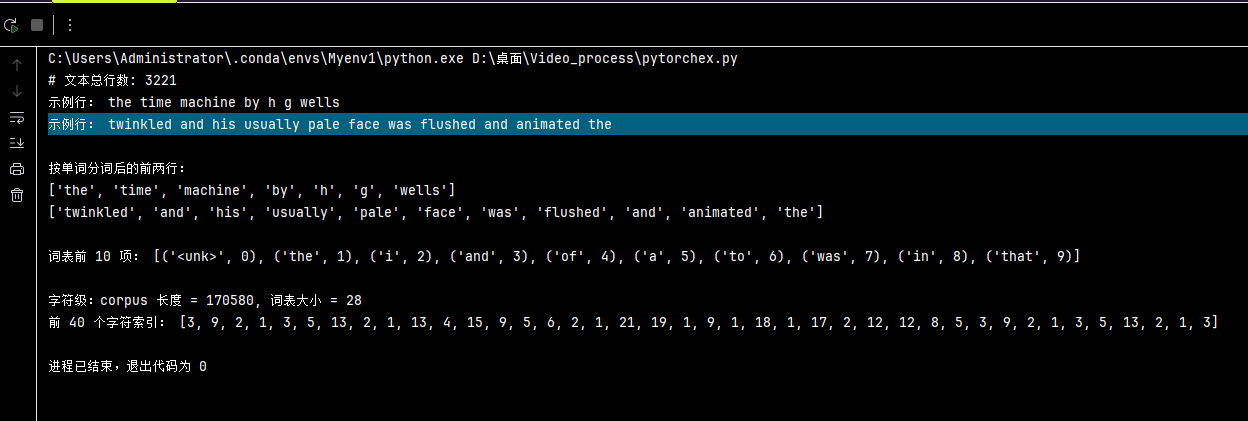
lines = read_time_machine()
print(f"# 文本总行数: {len(lines)}")
print("示例行:", lines[0])
print("示例行:", lines[10])
# 词元化(按单词)
word_tokens = tokenize(lines, "word")
print("\n按单词分词后的前两行:")
print(word_tokens[0])
print(word_tokens[10])
# 构建词表
vocab = Vocab(word_tokens, min_freq=1)
print("\n词表前 10 项:", list(vocab.token_to_idx.items())[:10])
# 将文本转为索引序列(演示按字符)
corpus, char_vocab = load_corpus_time_machine(level="char")
print(f"\n字符级:corpus 长度 = {len(corpus)}, 词表大小 = {len(char_vocab)}")
print("前 40 个字符索引:", corpus[:40])运行结果如图:
代码讲解:
首先导入了 Python 标准库中实现文本预处理各步骤所需的功能模块:
python
import os
import re
import hashlib
import urllib.request
import collections
from typing import List, Tupleos 用于处理文件和目录操作,例如创建文件夹、拼接路径、判断文件是否存在等。re 提供正则表达式(regular expression)功能,用于文本清洗。在本代码中用来删除非字母字符;替换标点和数字为空格;实现文本标准化(只保留英文单词)。hashlib 用于计算文件的哈希值(如 SHA1、MD5 等),验证文件是否完整、未被破坏。urllib.request 提供从网络下载文件的功能,本脚本通过它从 D2L 官方服务器下载小说文本文件 timemachine.txt。collections 包含一些高效的数据结构,如 Counter、defaultdict 等。这里主要用于统计每个词元(token)的出现次数;词表构建提供词频依据。Liststr 表示函数返回一个字符串列表;TupleList\[int, Vocab] 表示返回一个由列表和词表组成的二元组。
python
DATA_DIR = os.path.join(os.path.dirname(__file__), "data")
URL = "http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt"
FNAME = "timemachine.txt"
SHA1 = "090b5e7e70c295757f55df93cb0a180b9691891a"这几行代码定义了脚本运行所需的全局常量,用于确定数据的保存位置、下载来源和文件校验方式:
- DATA_DIR表示数据保存的本地目录。os.path.dirname(file) 获取当前脚本所在的文件夹路径;os.path.join(..., "data") 在该路径下拼接一个名为 "data" 的子目录。所有下载的数据都会保存在脚本所在目录下的 data/ 文件夹中。
- URL是小说《The Time Machine》的下载链接。指向 D2L 官方托管的数据文件(使用 Amazon S3 加速存储)。该地址用于后续通过 urllib.request.urlretrieve() 下载文本。
- FNAME是保存到本地的文件名,即 "timemachine.txt"。它与下载链接中的文件名一致,便于在 data/ 文件夹中查找和管理。
- SHA1是文件的 SHA1 哈希校验值。用于验证文件是否完整、是否在下载过程中损坏或被篡改。在下载完成后,脚本会重新计算文件的哈希值,与这里保存的字符串对比;若不一致,则抛出校验错误。
python
def _sha1(path: str) -> str:
h = hashlib.sha1()
with open(path, "rb") as f:
while True:
b = f.read(1 << 20)
if not b:
break
h.update(b)
return h.hexdigest()这段函数 _sha1() 作用是计算指定文件的 SHA-1 哈希值,用于检测文件是否完整或是否被篡改。该函数接收一个文件路径 path,按二进制方式读取文件内容,逐块计算其 SHA-1 哈希值(secure hash algorithm 1),并返回对应的十六进制字符串。
拓展:哈希值(hash value) 是通过一种哈希函数(hash function)把任意长度的数据(比如一个文件、一段文本)转换成一个固定长度的字符串的结果。这个转换过程就像"数字指纹":无论输入的数据有多大或多小,哈希函数都会输出一个独一无二的、固定长度的"指纹"。哈希函数有一个重要特性------输入稍微不同,输出会天差地别。
python
def download_time_machine() -> str:
"""下载到本地 data/ 目录,如果已存在且校验通过就直接复用。返回本地路径。"""
os.makedirs(DATA_DIR, exist_ok=True)
fpath = os.path.join(DATA_DIR, FNAME)
if os.path.exists(fpath) and _sha1(fpath) == SHA1:
return fpath
print(f"Downloading {fpath} from {URL} ...")
urllib.request.urlretrieve(URL, fpath)
# 校验
if _sha1(fpath) != SHA1:
raise RuntimeError("SHA1 校验失败,文件可能不完整。")
return fpath如果本地已有并且通过 SHA1 校验 → 直接使用;否则从网络下载 → 再次校验。"最后返回下载或复用的文件路径。
python
def read_time_machine() -> List[str]:
"""读取文本并做基础清洗:仅保留字母,转小写,strip。"""
path = download_time_machine()
with open(path, "r", encoding="utf-8") as f:
lines = f.readlines()
# 与课本一致的清洗
return [re.sub("[^A-Za-z]+", " ", line).strip().lower() for line in lines]读取小说《The Time Machine》的文本内容,并对每一行进行基础清洗,使其变为统一、干净的纯英文小写文本。
首先调用前面定义的 download_time_machine();确保小说文件存在并通过 SHA1 校验;返回文件路径,用于后续读取。以 UTF-8 编码打开文件;一次性读取所有行;得到一个列表,每一行是一个字符串(含原始标点和换行符)。使用正则表达式替换所有非英文字母字符为空格;去除首尾空格并转小写。列表推导式处理所有行:对每一行进行上述清洗;返回一个干净的字符串列表。
python
def tokenize(lines: List[str], token: str = "word") -> List[List[str]]:
"""按单词或字符进行词元化。"""
if token == "word":
return [line.split() for line in lines]
elif token == "char":
return [list(line) for line in lines]
else:
raise ValueError(f"未知 token 类型: {token}")把清洗后的文本拆分成更小的"词元"(token),即进行词元化(tokenization)处理。它可以选择按单词或字符为单位进行切分。
if token = = "word":使用 Python 内置的 .split() 按空格拆分字符串;每行文本被分割成若干单词;适合进行词级语言建模。
elif token = = "char":把每行字符串转成字符列表;即每个字母(包括空格)都作为一个 token;适合进行字符级语言建模。
如果用户传入的 token 参数不是 "word" 或 "char",程序会报错,提示"未知 token 类型"。
接下来:构建"词元 ↔ 索引"的双向映射表(词表),并保存词频信息。
python
class Vocab:
"""与课本一致的词表实现"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
tokens = tokens or []
reserved_tokens = reserved_tokens or []
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 0 号位保留给 <unk>
self.idx_to_token = ["<unk>"] + reserved_tokens
self.token_to_idx = {tok: i for i, tok in enumerate(self.idx_to_token)}
for tok, freq in self._token_freqs:
if freq < min_freq:
break
if tok not in self.token_to_idx:
self.idx_to_token.append(tok)
self.token_to_idx[tok] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(t) for t in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[i] for i in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs定义Vocab(vocabulary)词表类,负责:
- 统计语料中每个词元(token)的出现频率;
- 按词频降序排列;
- 给每个词元分配一个唯一索引;
- 建立**"词元→索引"与"索引→词元"**的双向映射;
- 预留特殊符号 表示"未知词"。
python
def count_corpus(tokens) -> collections.Counter:
"""统计词频;支持二维 tokens(行 → 词元列表)。"""
if len(tokens) == 0 or isinstance(tokens[0], list):
tokens = [t for line in tokens for t in line]
return collections.Counter(tokens)函数 count_corpus() 的作用是统计整个语料中每个词元(token)出现的次数(词频),并返回一个 collections.Counter 对象。它是 Vocab 类中计算词频的辅助函数。
python
def load_corpus_time_machine(max_tokens: int = -1, level: str = "char") -> Tuple[List[int], Vocab]:
"""返回扁平化后的索引序列 corpus 以及词表 vocab。"""
lines = read_time_machine()
tokens = tokenize(lines, token=level)
vocab = Vocab(tokens)
corpus = [vocab[t] for line in tokens for t in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab函数 load_corpus_time_machine() 是整个文本预处理流程的最后一环,把清洗后的小说文本转化为数字化语料(corpus)和对应的词表(vocab),从而可以直接用于神经网络模型的训练。
python
if __name__ == "__main__":
lines = read_time_machine()
print(f"# 文本总行数: {len(lines)}")
print("示例行:", lines[0])
print("示例行:", lines[10])
# 词元化(按单词)
word_tokens = tokenize(lines, "word")
print("\n按单词分词后的前两行:")
print(word_tokens[0])
print(word_tokens[10])
# 构建词表
vocab = Vocab(word_tokens, min_freq=1)
print("\n词表前 10 项:", list(vocab.token_to_idx.items())[:10])
# 将文本转为索引序列(演示按字符)
corpus, char_vocab = load_corpus_time_machine(level="char")
print(f"\n字符级:corpus 长度 = {len(corpus)}, 词表大小 = {len(char_vocab)}")
print("前 40 个字符索引:", corpus[:40])这部分代码是整个脚本的主程序入口,在直接运行脚本时(而不是作为模块被导入时),演示整个文本预处理流程的执行结果。
分为四部分:
① 读取清洗后的文本
python
lines = read_time_machine()
print(f"# 文本总行数: {len(lines)}")
print("示例行:", lines[0])
print("示例行:", lines[10])调用 read_time_machine() 读取并清洗小说文本;输出文本的总行数;打印第 0 行和第 10 行作为示例。
② 词元化(按单词)
python
word_tokens = tokenize(lines, "word")
print("\n按单词分词后的前两行:")
print(word_tokens[0])
print(word_tokens[10])调用 tokenize(),设置 token="word";将文本拆分为单词级词元;打印前两行分词结果。
③ 构建词表(Vocabulary)
python
vocab = Vocab(word_tokens, min_freq=1)
print("\n词表前 10 项:", list(vocab.token_to_idx.items())[:10])使用分词结果 word_tokens 创建词表;min_freq=1 表示所有出现过的单词都收录;打印前 10 个词及其对应的索引。
将文本转为索引序列(按字符)
python
corpus, char_vocab = load_corpus_time_machine(level="char")
print(f"\n字符级:corpus 长度 = {len(corpus)}, 词表大小 = {len(char_vocab)}")
print("前 40 个字符索引:", corpus[:40])调用 load_corpus_time_machine(),设置 level="char";将整本书转为字符级索引序列;最后打印:corpus 总长度(文本中字符总数);词表大小(去重后的字符数量);前 40 个字符索引样例。
总结:
这段脚本完整复现了《动手学深度学习》(D2L)第 8.2 节"文本预处理"的实现逻辑,展示了从原始自然语言文本到神经网络可处理数据的完整转换流程。它以小说《The Time Machine》为示例,依次完成了以下任务:
- 数据下载与校验
从 D2L 官方源自动下载文本文件,并使用 SHA1 哈希值校验文件完整性,确保数据可靠。 - 文本读取与清洗
仅保留英文字母;统一转为小写;去除标点与多余空格;输出干净的行文本列表。 - 词元化(Tokenization)
将文本拆分为可选粒度的词元序列:单词级(word level);字符级(character level)。 - 构建词表(Vocabulary)
统计语料中每个词元出现的频率;建立 "词元 ↔ 索引" 的双向映射;预留 用于处理未知词;
可根据 min_freq 筛除低频词。 - 生成数字化语料(Corpus)
将文本中的词元序列转化为对应的索引序列;得到一维整数列表;可限制长度(max_tokens)以控制数据规模。 - 示例演示
主程序展示了文本行数、分词结果、词表示例及索引序列;方便验证各阶段输出是否符合预期。