文章目录
摘要
本周学习了18年的论文GPT,了解到当前大语言模型的前身和背后逻辑,基于transformer的解码器的发展。
Abstract
This week, I studied research papers from 2018 on GPT, gaining an understanding of the predecessors of current large language models and the underlying logic, as well as the development of transformer-based decoders.
1GPT
再transformer之后,随着技术的演进,基于transformer已经形成了三种架构
-
编码器-解码器架构,T5
-
编码器架构,BERT
-
解码器架构,GPT、QWEN、GLM
其中编码器-解码器架构,适合序列到序列的任务,如文本翻译、内容摘要。编码器架构适合对输入内容分析但不需要生成新序列的任务,比如情感分析、文本分类。解码器架构,适合基于已有信息生成新序列的任务,比如文本生成、对话系统。
解码器架构下,又有两个分支:
-
因果解码器,GPT,Qwen
-
前缀解码器,GLM
二者之间的主要差异在于注意力的模式。因果解码器的特点,是在生成每个词元时,只能看到它之前的词元,而不能看到它之后的词元,这种机制通过掩码实现,确保了模型在生成当前词元时,不会利用到未来的信息,称之为"单向注意力"。前缀解码器对于输入(前缀)部分使用"双向注意力"进行编码,这意味着前缀中的每个词元都可以访问前缀中的所有其他词元,但这仅限于前缀部分,生成输出时,前缀解码器仍然采用单向的掩码注意力,即每个输出词元只能依赖于它之前的所有输出词元。

例子中,已经存在了"大家共同努力"这六个词元,模型正在思考如何产生下一个新的词元。此时,"大家共"是输入(前缀),"同努力"是模型解码已经产生的输出,蓝色代表可以前缀词元之间可以互相建立依赖关系,灰色代表掩码,无法建立依赖关系。
因果解码器和前缀解码器的差异在"大家共"(前缀)所对应的3*3的方格中,两种解码器都会去分析前缀词元之间的依赖关系。对于因果解码器而言,哪怕词元是前缀的一部分,也无法看到其之后的词元,所以对于前缀中的"家"(对应第二行第二列),它只能建立与"大"(第二行第一列)的依赖关系,无法看到"共"(第二行第三列)。而在前缀解码器中,"家"可以同时建立与"大"和"共"的依赖关系。
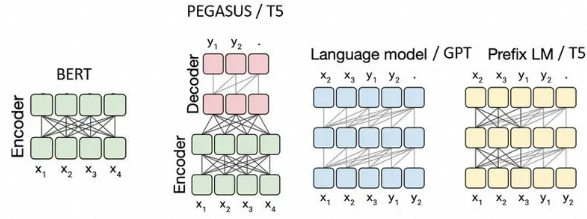
单向注意力和双向注意力,有各自的优势,例如,对于文本生成任务,可能会优先考虑单向注意力以保持生成的连贯性。而对于需要全面理解文本的任务,可能会选择双向注意力以获取更丰富的上下文信息。如上图分别是编码器架构(BERT)、编码器-解码器架构(T5)、因果解码器架构(GPT)、前缀解码器架构(T5、GLM)的注意力模式。
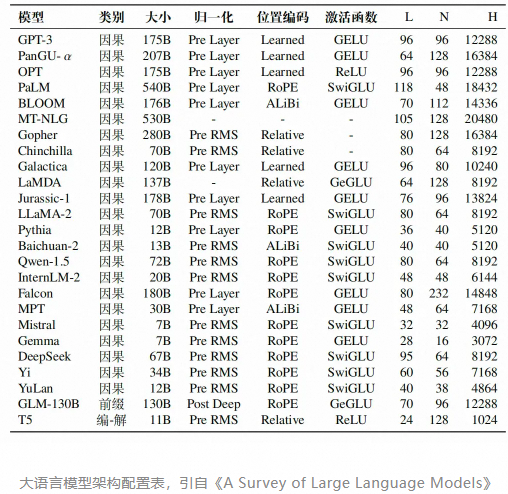
这些架构在当今的大语言模型阶段都有应用,其中因果解码器架构是目前的主流架构,包括Qwen-2.5在内的众多模型采用的都是这种架构。具体可以参考下面的大语言模型架构配置图,其中类别代表架构,L 表示隐藏层层数,N 表示注意力头数,H 表示隐藏状态的大小。
2018年,OpenAI团队的论文《Improving Language Understanding by Generative Pre-Training》横空出世,它提出可以在大规模未标注数据集上预训练一个通用的语言模型,再在特定NLP子任务上进行微调,从而将大模型的语言表征能力迁移至特定子任务中。其创新之处在于,提出了一种新的预训练-微调框架,并且特别强调了生成式预训练在语言模型中的应用。生成式,指的是通过模拟训练数据的统计特性来创造原始数据集中不存在的新样本,这使得GPT在文本生成方面具有显著的优势。
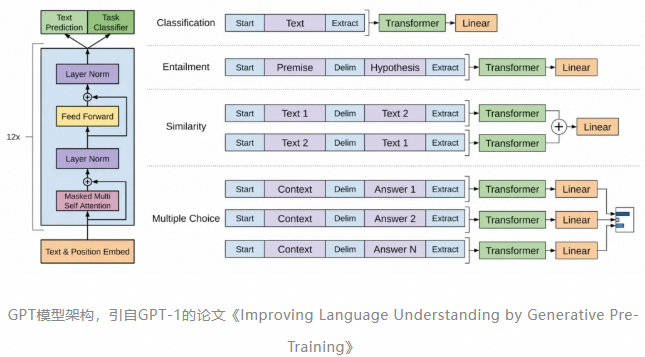
上图来自于GPT-1的论文,图片左侧是GPT涉及到的核心组件,这是本文的重点内容。图片右侧是针对不同NLP任务的输入格式,这些格式是为了将各种任务的输入数据转换为Transformer模型能够处理的序列形式,用于模型与训练的过程。
GPT使用了Transformer的解码器部分,同时舍弃了编码器中的交叉注意力机制层,保留了其余部分。整体上模型结构分为三部分:
- 输入层(Input Layer):将文本转换为模型可以处理的格式,涉及分词、词嵌入、位置编码等。
- 隐藏层(Hidden Layer):由多个Transformer的解码器堆叠而成,是GPT的核心,负责模型的理解、思考的过程。
- 输出层(Output Layer):基于隐藏层的最终输出生成为模型的最终预测,在GPT中,该过程通常是生成下一个词元的概率分布。
在隐藏层中,最核心的两个结构分别是
- 掩码多头自注意力层(Masked Multi Self Attention Layers,对应Transformer的Masked Multi-Head Attention Layers,简称MHA,也叫MSA)。
- 前置反馈网络层(Feed Forward Networks Layers,简称FFN,与MLP类似)。
MHA的功能是理解输入内容,它使模型能够在处理序列时捕捉到输入数据之间的依赖关系和上下文信息,类似于我们的大脑在接收到新的信息后进行理解的过程。FFN层会对MHA的输出进行进一步的非线性变换,以提取更高级别的特征,类似于我们的大脑在思考如何回应,进而基于通过训练获得的信息和知识,产生新的内容。
举个例子,当我们输入"美国2024年总统大选胜出的是"时,MHA会理解每个词元的含义及其在序列中的位置,读懂问题的含义,并给出一种中间表示,FFN层则会对这些表示进行进一步的变换,进而从更高级别的特征中得到最相近的信息------"川普"。

隐藏层不只有一层,而是一种多层嵌套的结构。如上图,Attention是MHA,Multilayer Perceptron(MLP)是FFN,它们就像奥利奥饼干一样彼此交错。这是为了通过建立更深的网络结构,帮助模型在不同的抽象层次上捕捉序列内部的依赖关系,最终将整段文字的所有关键含义,以某种方式充分融合到最后的输出中。隐藏层的层数并不是越多越好,这取决于模型的设计,可以参考前文贴过的模型参数表,其中的L就代表该模型的隐藏层的层数。较新的Qwen2-72B有80层,GPT-4有120层。
目前主流的大模型,在这两层都进行了不同程度的优化。比如Qwen2使用分组查询注意力(Grouped Multi-Query Attention,简称GQA)替代MHA来提高吞吐量,并在部分模型上尝试使用混合专家模型(Mixture-of-Experts,简称MoE)来替代传统FFN。GPT-4则使用了多查询注意力(Multi-Query Attention)来减少注意力层的KV缓存的内存容量,并使用了具有16个专家的混合专家模型。关于这里提到的较新的技术,在后文中会详细阐述。
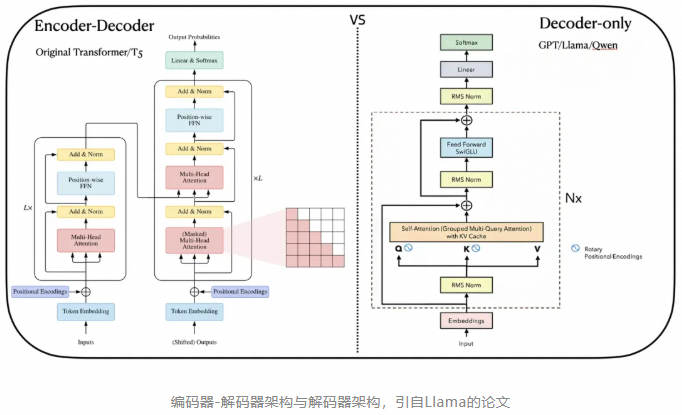
此外,模型还保留了Transformer的其他部分,包括了(参考上图右半部分,该图片的细节更多一些)
- 词嵌入 (Embedding,对应GPT论文中的Text & Position Embed)。
- 位置编码(Positional Encodings,简称PE,对应GPT论文中的Text & Position Embed,Rotary Positional Encodings是位置编码的一种技术)。
- 层归一化(Layer Norm,上图中表示为RMS Norm,通常与残差连接一起用,Layer Norm和RMS Norm是归一化的两种不同技术)。
- 线性层(Linear,负责将FFN层的输出通过线性变换,通常用于将模型的输出映射到所需的维度)。
- Softmax(Softmax层,负责生成概率分布,以便进行最终的预测)。
这些部分单独拿出来看会有些抽象,尝试将一段文本输入给大模型,看一看大模型的整体处理流程
1.分词(Tokenization):首先大模型会进行分词,将文本内容分割成一系列的词元(token)。
2.词嵌入(Embedding):分词后的词元将被转换为高维空间中的向量表示,向量中包含了词元的语义信息。
3.位置编码(PE):将词元的在序列中的位置信息,添加到词嵌入中,以告知模型每个单词在序列中的位置。
4.掩码多头自注意力层(MHA):通过自注意力机制捕捉序列内部词元间的依赖关系,形成对输入内容的理解。
5.前馈反馈网络(FFN):基于MHA的输出,在更高维度的空间中,从预训练过程中学习到的特征中提取新的特征。
6.线性层(Linear):将FFN层的输出映射到词汇表的大小,来将特征与具体的词元关联起来,线性层的输出被称作logits。
7.Softmax:基于logits形成候选词元的概率分布,并基于解码策略选择具体的输出词元。
因果解码器的特点,是在生成每个词元时,只能看到它之前的词元,而不能看到它之后的词元。也就是说,无论模型在自回归过程中生成多少词元,此前已经生成的词元对上下文内容的理解,都不会发生任何改变。因此我们在自回归过程中,不需要在生成后续词元时重新计算已经生成的词元的注意力。
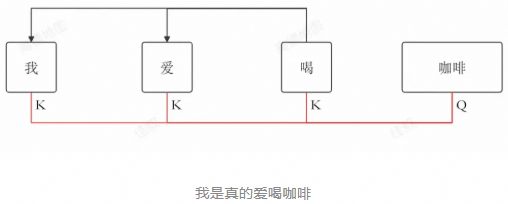
但是,新生成的词元的注意力需要计算,这会涉及新生成的词元的Q与其它词元的K计算点积,并使用其它词元的V生成上下文向量。而此前生成的词元K、V,实际上始终不会改变,因此我们可以将他们缓存起来,在新生成的词元计算注意力的时候直接使用,避免重复计算,这就是KV缓存。如上图,已经生成的词元"我"、"爱"、"喝"都不会重新计算注意力,但是新生成的"咖啡"需要计算注意力,期间我们需要用到的是"咖啡"的 Q,和"我"、"爱"、"喝"的K、V。
KV缓存的核心思想是:
- 缓存不变性:在自回归生成过程中,已经生成的词元的键(Key,K)和值(Value,V)不会改变。
- 避免重复计算:由于K和V不变,模型在生成新词元时,不需要重新计算这些已生成词元的K和V。
- 动态更新:当新词元生成时,它的查询(Query,Q)会与缓存的K进行点积计算,以确定其与之前所有词元的关联。同时,新词元的K和V会被计算并添加到缓存中,以便用于下一个词元的生成。
在使用KV Cache的情况下,大模型的推理过程常被分为两个阶段
-
预填充阶段(Prefill):模型处理输入序列,计算它们的注意力,并存储K和V矩阵到KV Cache中,为后续的自回归过程做准备。
-
解码阶段(Decode):模型使用KV缓存中的信息,逐个生成输出新词元,计算其注意力,并将其K、V添加到KV Cache中。
其中预填充阶段是计算密集型的,因为其涉及到了矩阵乘法的计算,而解码阶段是内存密集型的,因为它涉及到了大量对缓存的访问。
GPT的目标函数
L 1 ( u ) = ∑ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; θ ) L_1(u)=\sum_i log P(u_i|u_{i-k},...,u_{i-1};\theta) L1(u)=∑ilogP(ui∣ui−k,...,ui−1;θ),其中 u i − k , . . . , u i − 1 u_{i-k},...,u_{i-1} ui−k,...,ui−1代表当前要预测的词的前 k k k个词,根据前 k k k个词和模型 θ \theta θ来预测当前出现的词的概率。
总结
本周学习了一些GPT方面的内容,模型种transformer的应用越来越多,下周将继续学习transformer的应用。