目录
一、引言
混合高斯模型(GMM)作为描述基于傅里叶频谱语音特征的统计模型,在传统语音识别系统的声学建模中发挥了重要作用。本文将详细讲解相关算法以及Python代码完整实现。
二、随机变量
随机变量是概率论和统计学中最基本的概念。随机标量变量是一个基于随机实验结果的实数函数或实数变量。随机向量变量是彼此相关或独立的随机标量变量的一个集合。因为实验是随机的,所以随机变量的取值也是随机的。随机变量可以被理解为从随机实验到变量的一个映射。根据实验和映射的性质,随机变量可以是离散值、连续值或离散值与连续值的混合。因此有离散型随机变量、连续型随机变量及混合型随机变量。随机变量的所有可能取值都被称为它的域(Domain)。
连续型随机变量x的基本特性是它的分布或概率密度函数(Probability density function,PDF),通常记为p(x)。连续型随机变量在x=a处的概率密度函数定义为
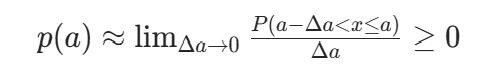
其中,P(⋅)表示事件的概率。
连续型随机变量x在x=a处的累积分布函数(Cumulative distribution function)定义为
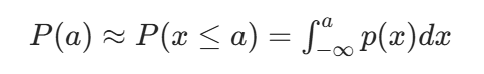
概率密度函数需要满足归一化性质,即
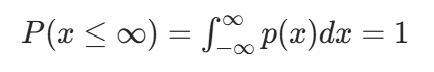
如果没有满足归一化性质,则我们称这个概率密度函数是一个不当密度或非归一化分布。
对一个连续随机向量 ,我们可以简单地定义它们的联合概率密度为
,我们可以简单地定义它们的联合概率密度为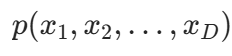 。进一步,对每一个在随机向量x中的随机变量
。进一步,对每一个在随机向量x中的随机变量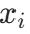 ,边缘概率密度函数(Marginal PDF)定义为
,边缘概率密度函数(Marginal PDF)定义为
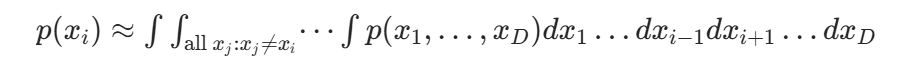
它和标量随机变量的概率密度函数具有相同的性质。
三、高斯分布和混合高斯随机变量
如果连续型标量随机变量x的概率密度函数是
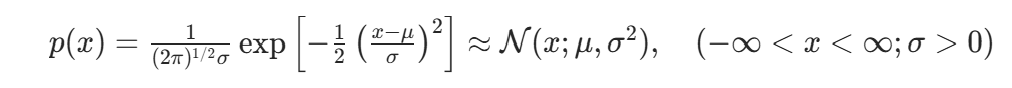
那么它是服从正态分布或高斯分布的。上式的一个等价标记是
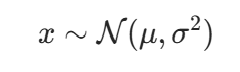
表示随机变量x服从均值为μ、方差为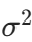 的正态分布。使用精度参数(精度是方差的倒数)代替方差后,高斯分布的概率密度函数也可以写为
的正态分布。使用精度参数(精度是方差的倒数)代替方差后,高斯分布的概率密度函数也可以写为

很容易证明,对一个高斯随机变量x,期望和方差分别满足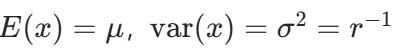 。
。
由下面的联合概率密度函数定义的正态随机变量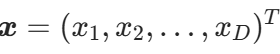 也称多元或向量值高斯随机变量:
也称多元或向量值高斯随机变量:
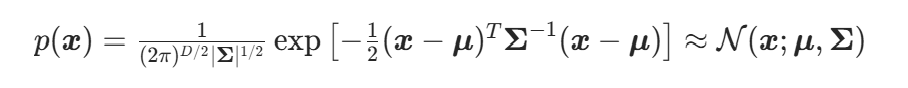
与其等价的表示是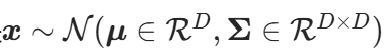 。对于多元高斯随机变量,其均值和协方差矩阵可由
。对于多元高斯随机变量,其均值和协方差矩阵可由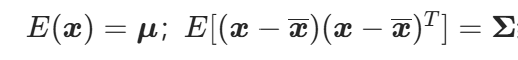 给出。
给出。
高斯分布被广泛应用于包括语音识别在内的很多工程和科学学科中。它的流行不仅来自其具有令人满意的计算特性,而且来自大数定理带来的可以近似很多自然出现的实际问题的能力。
现在我们来讨论一种服从混合高斯模型(Gaussian Mixture Model, GMM)的混合高斯随机变量。一个标量连续随机变量x服从混合高斯分布,如果它的概率密度函数为
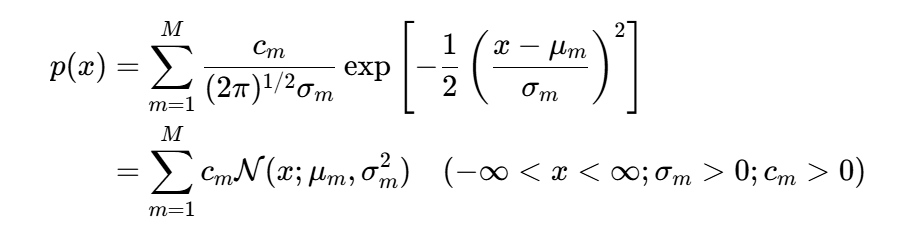
其中混合权重为正实数,则其和为 1: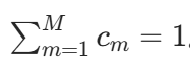 。
。
混合高斯分布最明显的性质是它的多模态性质(M>1)不同于高斯分布的单模态性质(M=1)。这使得混合高斯模型足以描述很多显示出多模态性质的物理数据(包括语音数据),单高斯分布则不适合。数据中的多模态性质可能来自多种潜在因素,每个因素都决定分布中一个特定的混合成分。如果因素被识别出来,那么混合分布就可以被分解成由多个因素独立分布组成的集合。
很容易证明,服从混合高斯概率密度函数的随机变量x的均值是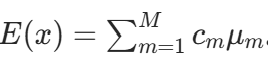 。不同于单模态的高斯分布,这个简单的统计量并不具有什么信息,除非混合高斯分布中所有成分的均值
。不同于单模态的高斯分布,这个简单的统计量并不具有什么信息,除非混合高斯分布中所有成分的均值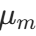 (m=1,...,M)都很接近。
(m=1,...,M)都很接近。
推广到多变量的多元混合高斯分布,其联合概率密度函数可写为
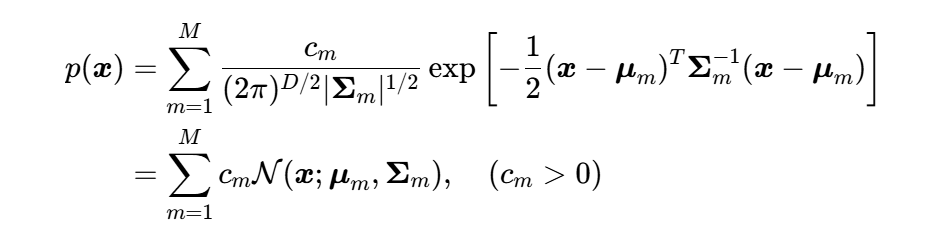
多元混合高斯分布的应用是提升语音识别系统性能的一个关键因素(在深度学习出现之前)。在多数应用中,根据问题的本质,混合成分的数量M被选择为一个先验值。虽然有多种方法尝试去回避这个寻找 "正确" 值的困难问题,但主流仍然是直接选取先验值。
在多元混合高斯分布公式中,如果变量x的维度D很大(比如 40,对于语音识别问题),那么使用全协方差矩阵(非对角)(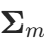 ) 将引入大量参数(大约为
) 将引入大量参数(大约为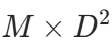 个)。为了减少这个数量,可以使用对角协方差矩阵
个)。为了减少这个数量,可以使用对角协方差矩阵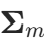 。当M很大时,也可以限制所有的协方差矩阵为相同矩阵,对所有的混合成分m,将参数绑定在一起。另一个使用对角协方差矩阵的优势是极大地降低了混合高斯分布所需的计算量。将全协方差矩阵近似为对角协方差矩阵看似对数据向量使用了各个维度不相关的假设,但其实是一种误导。因为混合高斯模型具有多个高斯成分,虽然每个成分都使用了对角协方差矩阵,但总体上至少可以有效地描述由一个使用全协方差矩阵的单高斯模型所描述的向量维度相关性。
。当M很大时,也可以限制所有的协方差矩阵为相同矩阵,对所有的混合成分m,将参数绑定在一起。另一个使用对角协方差矩阵的优势是极大地降低了混合高斯分布所需的计算量。将全协方差矩阵近似为对角协方差矩阵看似对数据向量使用了各个维度不相关的假设,但其实是一种误导。因为混合高斯模型具有多个高斯成分,虽然每个成分都使用了对角协方差矩阵,但总体上至少可以有效地描述由一个使用全协方差矩阵的单高斯模型所描述的向量维度相关性。
四、参数估计
前文讨论的混合高斯分布包含了一系列参数变量。对于多元混合高斯分布的公式,参数变量包含了 。参数估计问题又被称为学习问题,目标是根据符合混合高斯分布的数据来确定模型参数的取值。
。参数估计问题又被称为学习问题,目标是根据符合混合高斯分布的数据来确定模型参数的取值。
通常来说,混合高斯模型及其相关的参数变量估计是一个不完整数据的参数估计问题。为了进一步说明这个问题,可假设每个数据点与混合高斯分布中的某个单高斯成分具有一种 "所属关系"。一开始,这种所属关系是未知的。那么参数变量估计的任务就是通过 "学习" 得到这些 "所属关系",进而通过具有所属关系的数据点来估计每个高斯成分的参数。
下面将主要讨论混合高斯分布的参数变量估计问题中的最大似然准则估计方法,而期望最大化(Expectation Maximization,EM)算法就是这一类方法的一个典型代表。EM 算法是在给定确定数量的混合分布成分的情况下,估计各个分布参数的最通用的方法。它是一个两阶段的迭代算法:期望计算阶段(E 步骤)和最大化阶段(M 步骤)。本节将针对混合高斯分布进行讨论。在此情况下,EM 算法得到的参数估计公式为
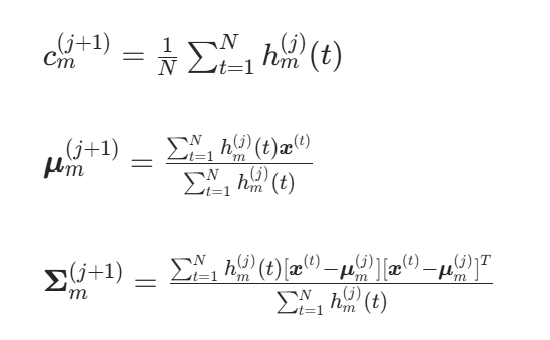
从 E 步骤中计算得到的后验概率(又称所属关系可信程度)如下:
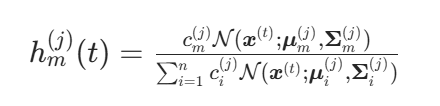
这是基于当前迭代轮数(由公式中的上标j表示),针对某个高斯成分m,用给定的观察值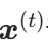 计算得到的后验概率,t=1,...,N(这里N是采样率)。给定这些后验概率值后,每个高斯成分的先验概率、均值和协方差都可以根据公式计算,这些公式本质上是整个采样数据的加权平均的均值和协方差。
计算得到的后验概率,t=1,...,N(这里N是采样率)。给定这些后验概率值后,每个高斯成分的先验概率、均值和协方差都可以根据公式计算,这些公式本质上是整个采样数据的加权平均的均值和协方差。
通过推导可以得出,每个 EM 迭代并不会减少似然度,而这是其他大部分梯度迭代最大化方法所不具备的属性。其次,EM 算法天然地引入了对概率向量的限制条件,以便应对足够大的采样数下的协方差定义和迭代。这是一个重要的优点,因为采用显式条件限制方法将引入额外的计算消耗,用于检查和维持合适的数值,EM 算法则不需要。从理论上说,EM 算法是一种一阶迭代算法,会缓慢地收敛到固定的解。虽然针对参数值的收敛本身并不快,但是似然度的收敛还是非常快的。而 EM 算法的另一个缺点是它每次都会达到局部最大值,而且它对参数的初始值很敏感。虽然这些问题可以通过在多个初始值下评估 EM 算法来解决,但是这将引入额外的计算消耗。另一种比较流行的方法是通过单高斯成分来做初始估计,在每次迭代完成后都将一个高斯成分分割成多份,得到混合高斯模型。
除了前面讨论的优化最大似然准则的 EM 算法,其他旨在优化鉴别性估计准则的方法也被提出来估计高斯或混合高斯模型的参数。这些方法也可以被用于更一般的统计模型,如高斯隐马尔可夫模型(Gaussian HMM)等。
五、采用混合高斯分布对语音特征建模
原始语音数据经过短时傅里叶变换形式或者取倒谱后会成为特征序列,在忽略时序信息的条件下,前文讨论的混合高斯分布就非常适合拟合这样的语音特征。也就是说,可以以帧(frame)为单位,用混合高斯模型(GMM)对语音特征进行建模。模型或可计算模型通常指对真实物理过程的数学抽象形式(例如人类语音处理)。为了方便数学上的计算,这些模型往往有一些必要的简化与近似。为了将这种数学抽象和算法应用于计算机及实际的工程应用(例如语音分析与识别)中,这种计算上的易处理性是非常重要的。
不仅仅在语音识别领域,GMM 还被广泛用于对其他领域的数据建模并进行统计分类。GMM 因其拟合任意复杂的、多种形式的分布能力而广为人知。基于 GMM 的分类方法被广泛应用于说话人识别、语音特征降噪与语音识别中。在说话人识别中,可以用 GMM 直接对所有说话人的语音特征分布建模,得到通用背景模型(Universal Background Model, UBM)。在语音特征降噪或噪声跟踪中,可以采用类似的做法,用 GMM 拟合一个先验分布。在语音识别中,GMM 被整合在 HMM 中,用来拟合基于状态的输出分布。
如果把语音顺序信息考虑进去,GMM 便不再是一个好模型,因为它不包含任何顺序信息。隐马尔可夫模型(Hidden Markov Model, HMM)是更加通用的模型,它可以对时序信息进行建模。然而,当给定 HMM 的一个状态后,若要对属于该状态的语音特征向量的概率分布进行建模,则 GMM 仍不失为一个好的模型。
使用 GMM 对 HMM 每个状态的语音特征分布进行建模,有许多明显的优势。只要混合的高斯分布数量足够多,GMM 就可以拟合任意精度的概率分布,并且可以通过 EM 算法很容易地拟合数据。还有很多关于限制 GMM 复杂度的研究,一方面为了加快 GMM 的计算速度,另一方面希望能够找到模型复杂度与训练数据量间的最佳权衡,其中包括参数绑定、半绑定 GMM 与子空间 GMM。
通过 EM 算法的优化,可以使 GMM 参数在训练数据上生成语音观察特征的概率最大化。在此基础上,若通过鉴别性训练,则基于 GMM-HMM 的语音识别系统的识别准确率可以得到显著提升。当所使用的鉴别性训练目标函数与音素错误率、字错误率或句子错误率密切相关时,这种提升更加显著。此外,通过在输入语音特征中加入由神经网络生成的联合特征或瓶颈特征,语音识别率同样可以得到提升,我们将在后面的章节讨论这个话题。在过去的很多年间,在语音特征的建模和语音识别中的声学模型的建模中,GMM 一直有非常成功的应用(直到 2010 年至 2011 年间,深层神经网络取得了更加准确的识别效果)。
尽管 GMM 有着众多优势,但它也有一个严重的不足。那就是 GMM 不能有效地对呈非线性或近似非线性的数据进行建模。举例来说,对一系列呈球面的点阵建模,如果选择合适的模型,则只需要很少的参数,但对 GMM 来讲,却需要非常多的对角高斯分布或相当多的全协方差高斯分布。众所周知,语音是由调节动态系统中相对少的参数来产生的,这意味着隐藏在语音特征下的真正结构的复杂度,比直接描述现有特征(一个短时傅里叶窗就包含数百个系数)的模型要小得多。因而,我们期待有其他更好的模型,能够更好地捕获语音特性,使其作为语音声学模型的能力比 GMM 更好。特别是,比起 GMM,这种模型要能更加有效地挖掘隐藏在长窗宽语音帧中的信息。
六、音频文件MP3
本文使用Python代码随机生成,也可以自行准备音频文件。注意:后文的混合高斯模型(GMM)的Python代码所在的文件与所有音频文件在同一目录中。
python
import numpy as np
import random
import os
from pydub import AudioSegment # 用于MP3编码
def generate_random_voice(
duration=1.0,
sample_rate=16000,
is_voiced_prob=0.7,
min_pitch=80,
max_pitch=300,
noise_level=0.1
):
"""
生成模拟语音波形(含浊音/清音特性,为MP3编码提供原始音频数据)
:param duration: 音频时长(秒)
:param sample_rate: 采样率(语音标准16kHz)
:param is_voiced_prob: 浊音(元音)占比(0-1,值越高元音越多)
:return: 归一化的语音波形数组(numpy.ndarray)、采样率(int)
"""
# 生成时间轴(采样点)
t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False)
signal = np.zeros_like(t)
frame_length = int(0.01 * sample_rate) # 10ms/帧(符合语音短时平稳特性)
n_frames = len(t) // frame_length
for i in range(n_frames):
start = i * frame_length
end = start + frame_length
frame_t = t[start:end]
# 随机生成浊音(元音,周期性正弦波)或清音(辅音,白噪声)
if random.random() < is_voiced_prob:
# 浊音:带1-4次谐波的正弦波(模拟真实语音频谱)
pitch = random.uniform(min_pitch, max_pitch) # 基频(控制音调)
pitch_slope = random.uniform(-0.1, 0.1) * pitch # 基频微小波动(模拟声调)
instantaneous_pitch = pitch + pitch_slope * (i / n_frames)
harmonics = np.zeros_like(frame_t)
for h in range(1, 5):
amp = 0.5 / h # 谐波振幅随次数衰减(符合人耳听觉特性)
harmonics += amp * np.sin(2 * np.pi * h * instantaneous_pitch * frame_t)
frame_signal = harmonics
else:
# 清音:白噪声(模拟辅音的无规则振动)
frame_signal = np.random.normal(0, 1, size=len(frame_t)) * 0.3
# 随机音量波动(模拟自然语音的音量变化)
frame_amp = random.uniform(0.3, 1.0)
signal[start:end] = frame_signal * frame_amp
# 添加背景噪声并归一化(避免音频失真,统一音量范围)
noise = np.random.normal(0, noise_level, size=len(signal))
signal += noise
signal = signal / np.max(np.abs(signal)) # 归一化到[-1, 1]
return signal, sample_rate
def generate_mp3_with_voice(
output_path,
duration=1.0,
is_voiced_prob=0.7
):
"""
生成随机语音MP3文件(调用pydub编码,依赖ffmpeg的LAME组件)
:param output_path: MP3输出路径(绝对路径或相对路径)
:param duration: 音频时长(秒)
:param is_voiced_prob: 浊音占比(用于区分"yes"/"no"等不同类别语音特征)
"""
# 1. 生成原始语音波形
audio_signal, sample_rate = generate_random_voice(
duration=duration,
is_voiced_prob=is_voiced_prob
)
# 2. 转换为pydub支持的16位PCM格式(MP3编码需该格式)
audio_int16 = (audio_signal * 32767).astype(np.int16) # 16位PCM范围:[-32768, 32767]
audio_segment = AudioSegment(
audio_int16.tobytes(),
frame_rate=sample_rate,
sample_width=2, # 16位=2字节
channels=1 # 单声道(语音处理标准,减少冗余计算)
)
# 3. 导出为MP3(处理编码异常)
try:
audio_segment.export(output_path, format="mp3")
# 验证MP3是否生成成功
if os.path.exists(output_path) and os.path.getsize(output_path) > 0:
print(f"✅ MP3生成成功 | 路径:{output_path} | 大小:{os.path.getsize(output_path)/1024:.1f}KB")
else:
print(f"❌ MP3生成失败 | 路径:{output_path}(文件为空或未创建)")
except Exception as e:
print(f"❌ MP3编码失败 | 错误信息:{str(e)}")
print("💡 解决建议:确保已安装ffmpeg(含LAME编码器),参考:https://ffmpeg.org/download.html")
# 若单独运行此文件,可生成默认的3个MP3(用于测试)
if __name__ == "__main__":
print("🚀 单独运行MP3生成工具")
print("=" * 50)
# 生成"yes"类训练MP3(短时长+多浊音)
generate_mp3_with_voice("yes_train.mp3", duration=0.8, is_voiced_prob=0.8)
# 生成"no"类训练MP3(稍长时长+少浊音)
generate_mp3_with_voice("no_train_0.mp3", duration=1.0, is_voiced_prob=0.6)
# 生成测试MP3
generate_mp3_with_voice("test.mp3", duration=0.9)
print("=" * 50)
print("📌 生成完成!MP3文件已保存到当前目录")
七、混合高斯模型(GMM)的Python代码完整实现
python
import numpy as np
import os
import librosa
from scipy.stats import multivariate_normal
# -------------------------- GMM模型(语音特征建模核心) --------------------------
class GMM:
def __init__(self, n_components, max_iter=100, tol=1e-4):
self.n_components = n_components # 高斯成分数量(平衡效果与速度)
self.max_iter = max_iter # EM算法最大迭代次数
self.tol = tol # 收敛阈值(似然度变化小于此值则停止)
self.c = None # 混合权重:[n_components]
self.mu = None # 均值矩阵:[n_components, n_features]
self.sigma = None # 对角协方差矩阵:[n_components, n_features]
def _init_params(self, X):
"""初始化GMM参数(权重、均值、协方差)"""
n_samples, n_features = X.shape
self.c = np.ones(self.n_components) / self.n_components # 均匀初始权重
idx = np.random.choice(n_samples, self.n_components, replace=False) # 随机选初始均值
self.mu = X[idx]
self.sigma = np.tile(np.var(X, axis=0), (self.n_components, 1)) + 1e-6 # 初始协方差
def _e_step(self, X):
"""E步:计算样本属于各高斯成分的后验概率"""
n_samples = X.shape[0]
# 计算每个成分的概率密度
pdfs = np.array([
multivariate_normal.pdf(X, mean=self.mu[m], cov=np.diag(self.sigma[m]))
for m in range(self.n_components)
])
# 后验概率 = (权重×密度)/ 总密度(加1e-10避免分母为0)
h = (self.c[:, np.newaxis] * pdfs) / (np.sum(self.c[:, np.newaxis] * pdfs, axis=0) + 1e-10)
return h
def _m_step(self, X, h):
"""M步:更新GMM参数"""
n_samples, n_features = X.shape
sum_h = np.sum(h, axis=1) # 每个成分的总权重
# 更新混合权重
c_new = sum_h / n_samples
# 更新均值(加权平均)
mu_new = np.array([
np.sum(h[m, :, np.newaxis] * X, axis=0) / sum_h[m]
for m in range(self.n_components)
])
# 更新对角协方差(加权方差,加1e-6避免零方差)
sigma_new = np.array([
np.sum(h[m, :, np.newaxis] * (X - mu_new[m]) ** 2, axis=0) / sum_h[m] + 1e-6
for m in range(self.n_components)
])
return c_new, mu_new, sigma_new
def fit(self, X):
"""训练GMM(EM算法迭代)"""
self._init_params(X)
log_likelihood_prev = -np.inf # 初始似然度(负无穷)
for _ in range(self.max_iter):
h = self._e_step(X) # E步
self.c, self.mu, self.sigma = self._m_step(X, h) # M步
# 计算当前似然度(判断收敛)
pdfs = np.array([
multivariate_normal.pdf(X, mean=self.mu[m], cov=np.diag(self.sigma[m]))
for m in range(self.n_components)
])
log_likelihood = np.sum(np.log(np.sum(self.c[:, np.newaxis] * pdfs, axis=0) + 1e-10))
if np.abs(log_likelihood - log_likelihood_prev) < self.tol:
break # 收敛,停止迭代
log_likelihood_prev = log_likelihood
def score_samples(self, X):
"""计算样本在GMM下的对数概率(用于分类打分)"""
pdfs = np.array([
multivariate_normal.pdf(X, mean=self.mu[m], cov=np.diag(self.sigma[m]))
for m in range(self.n_components)
])
return np.log(np.sum(self.c[:, np.newaxis] * pdfs, axis=0) + 1e-10)
# -------------------------- MFCC特征提取(语音→数值特征) --------------------------
def extract_mfcc_from_mp3(mp3_path, n_mfcc=13):
"""
从MP3文件提取MFCC特征(语音识别核心特征,模拟人耳听觉特性)
:param mp3_path: MP3文件路径(相对路径/绝对路径)
:param n_mfcc: MFCC特征维度(标准13维)
:return: MFCC特征矩阵:[n_frames, n_mfcc](每行为一帧特征)
"""
# 检查文件是否存在(提前报错,避免后续流程中断)
if not os.path.exists(mp3_path):
raise FileNotFoundError(f"❌ 找不到MP3文件!请确认路径正确:{mp3_path}")
# 加载MP3并提取MFCC(librosa自动调用ffmpeg解码,强制16kHz采样率)
y, sr = librosa.load(mp3_path, sr=16000)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc).T # 转置为[帧数, 特征数]
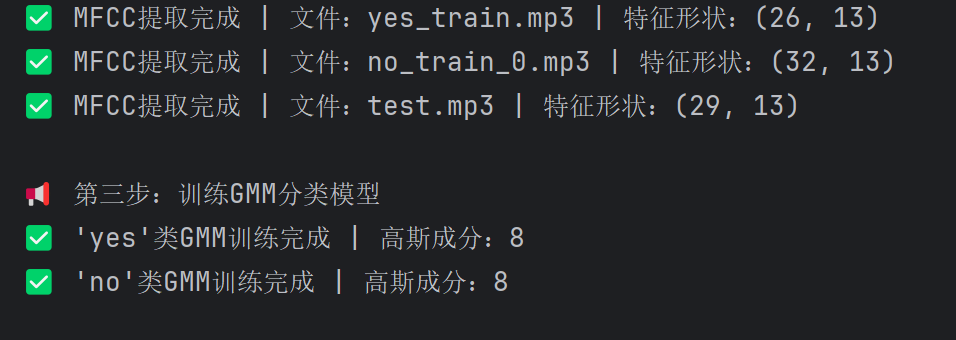
print(f"✅ MFCC提取完成 | 文件:{os.path.basename(mp3_path)} | 特征形状:{mfcc.shape}")
return mfcc
# -------------------------- 主流程(访问已有MP3→提取特征→训练→分类) --------------------------
def main():
print("🚀 GMM语音识别流程启动(仅访问已有MP3文件)")
print("=" * 60)
# 1. 配置已有MP3文件路径(核心修改:仅指定文件路径,不生成)
# 若文件不在代码目录,需改为绝对路径(如:"C:/Users/徐宏宇/Desktop/yes_train.mp3")
mp3_files = {
"yes_train": "yes_train.mp3", # 已有的"yes"类训练MP3
"no_train": "no_train_0.mp3", # 已有的"no"类训练MP3
"test": "test.mp3" # 已有的测试MP3
}
gmm_components = 8 # GMM高斯成分数量(8为语音分类常用值)
# 2. 预检查所有MP3文件是否存在(提前规避路径错误)
print("📢 第一步:检查已有MP3文件")
for file_type, file_path in mp3_files.items():
if os.path.exists(file_path):
print(f"✅ {file_type}文件存在:{file_path}")
else:
raise FileNotFoundError(f"❌ {file_type}文件缺失!请确认路径:{file_path}")
print()
# 3. 提取MFCC特征(使用已有MP3文件)
print("📢 第二步:提取MFCC特征")
train_yes = extract_mfcc_from_mp3(mp3_files["yes_train"]) # "yes"类特征
train_no = extract_mfcc_from_mp3(mp3_files["no_train"]) # "no"类特征
test_feature = extract_mfcc_from_mp3(mp3_files["test"]) # 测试特征
print()
# 4. 训练GMM模型
print("📢 第三步:训练GMM分类模型")
gmm_yes = GMM(n_components=gmm_components)
gmm_yes.fit(train_yes)
print(f"✅ 'yes'类GMM训练完成 | 高斯成分:{gmm_components}")
gmm_no = GMM(n_components=gmm_components)
gmm_no.fit(train_no)
print(f"✅ 'no'类GMM训练完成 | 高斯成分:{gmm_components}")
print()
# 5. 测试分类并输出结果
print("📢 第四步:语音分类测试")
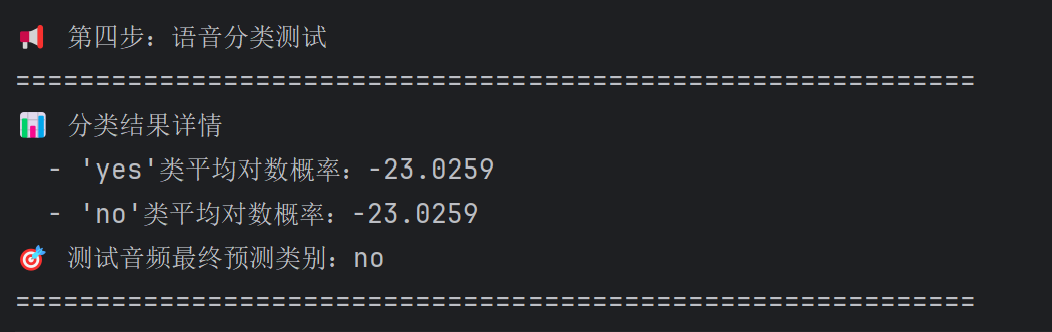
score_yes = np.mean(gmm_yes.score_samples(test_feature)) # "yes"类平均对数概率
score_no = np.mean(gmm_no.score_samples(test_feature)) # "no"类平均对数概率
predict_result = "yes" if score_yes > score_no else "no"
# 打印最终结果
print("=" * 60)
print("📊 分类结果详情")
print(f" - 'yes'类平均对数概率:{score_yes:.4f}")
print(f" - 'no'类平均对数概率:{score_no:.4f}")
print(f"🎯 测试音频最终预测类别:{predict_result}")
print("=" * 60)
if __name__ == "__main__":
main()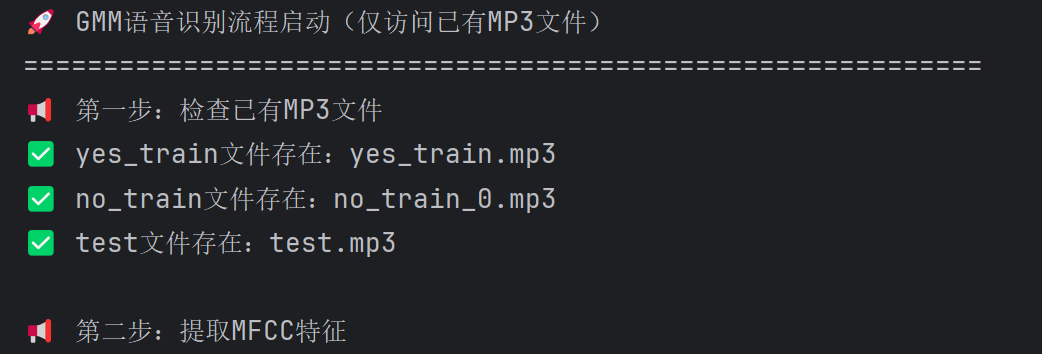
八、总结
本文详细讲解了混合高斯模型(GMM)在语音识别中的应用及其Python实现。首先介绍了随机变量和高斯分布的基本概念,阐述了GMM在多模态数据建模中的优势。接着讲解了参数估计的EM算法,并展示了GMM如何用于语音特征建模。文章提供了完整的Python代码实现,包括音频生成、MFCC特征提取和GMM分类器训练。通过EM算法迭代优化GMM参数,实现了对语音特征的有效建模,最后通过概率比较完成分类任务。GMM曾是语音识别中重要的声学模型,在深度学习兴起前发挥了关键作用。