文章目录
- 前言
-
- 一、网络编程:从"协议理解"到"高并发模型"的全链路掌控
-
- [1. TCP/IP协议栈:高并发的"隐藏规则"](#1. TCP/IP协议栈:高并发的“隐藏规则”)
- [2. 高并发网络模型:从"单线程"到"异步IO"的性能跃迁](#2. 高并发网络模型:从“单线程”到“异步IO”的性能跃迁)
- [3. 网络框架封装:屏蔽细节,聚焦业务](#3. 网络框架封装:屏蔽细节,聚焦业务)
- 二、架构设计:从"业务适配"到"高可用"的系统化思维
-
- [1. 架构演进:跟着业务"从小到大"](#1. 架构演进:跟着业务“从小到大”)
- [2. 高可用架构:从"单点容错"到"全链路冗余"](#2. 高可用架构:从“单点容错”到“全链路冗余”)
- [3. 性能优化:从"单点调优"到"链路协同"](#3. 性能优化:从“单点调优”到“链路协同”)
- 三、海量数据处理:从"存不下"到"查得快"的全链路方案
-
- [1. 海量数据存储:按"数据特性"选对存储方案](#1. 海量数据存储:按“数据特性”选对存储方案)
- [2. 海量数据查询:"多级缓存+智能索引"加速](#2. 海量数据查询:“多级缓存+智能索引”加速)
- [3. 数据同步与一致性:平衡"实时性"与"可靠性"](#3. 数据同步与一致性:平衡“实时性”与“可靠性”)
- 总结
前言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在中大型后台Server开发中,网络编程 是数据流转的"血管",架构设计 是系统扩展的"骨架",海量数据处理是业务增长的"基石"。这三大能力能力环环相扣,决定了系统能否支撑百万级用户、千万亿级数据的高并发场景。本文从技术原理、实战方案、落地案例三个维度,深入拆解这三大核心能力。
一、网络编程:从"协议理解"到"高并发模型"的全链路掌控
网络编程是后台服务的"基本功",但绝非简单调用Socket API------它需要对TCP/IP协议栈的深度理解,对高并发模型的精准选型,以及对性能瓶颈的敏锐洞察。
1. TCP/IP协议栈:高并发的"隐藏规则"
TCP协议的细节是解决网络问题的关键,很多线上故障(如连接超时、数据丢失)都源于对协议机制的理解不足。
| 协议核心机制 | 工作原理 | 高并发场景下的问题与解决方案 | 实战工具 |
|---|---|---|---|
| 三次握手 | 客户端发送SYN(初始序号x)→ 服务器回SYN+ACK(序号y,确认x+1)→ 客户端回ACK(确认y+1),完成连接建立 | 问题 :高并发下,服务器半连接队列(存储未完成三次握手的连接)溢出,新连接被丢弃(表现为客户端"connection refused")。 解决 : 1. 调大net.ipv4.tcp_max_syn_backlog(半连接队列大小,默认128→65535); 2. 开启net.ipv4.tcp_syncookies(用cookie代替队列存储,避免队列满); 3. 减少握手耗时(如优化服务器处理速度,避免SYN包堆积)。 |
ss -ltn查看监听队列状态;tcpdump抓包分析SYN/SYN+ACK报文 |
| 拥塞控制 | 慢启动(cwnd指数增长)→ 拥塞避免(cwnd线性增长)→ 快速重传/恢复(丢包后调整),避免网络拥塞 | 问题 :微服务间调用在弱网环境下吞吐量低(频繁触发拥塞控制,cwnd被压小)。 解决 : 1. 更换拥塞算法(如BBR替代CUBIC,更适合长肥管道网络); 2. 应用层实现"批量发送"(减少小包数量,降低拥塞触发概率); 3. 对非核心数据(如日志)采用UDP传输(牺牲可靠性换吞吐量)。 | ss -ti查看连接拥塞算法;tc模拟网络延迟/丢包进行测试 |
| 滑动窗口与流量控制 | 接收方通过Window Size告知发送方可发送的字节数,避免接收缓冲区溢出 | 问题 :服务端处理慢(如数据库卡慢),接收窗口变为0,发送方停止发送,导致连接"假死"。 解决 : 1. 服务端优化处理速度(如异步处理、增加线程池); 2. 发送方开启"零窗口探测"(net.ipv4.tcp_keepalive_time=60s,定期探测窗口是否恢复); 3. 应用层设置超时(如10s无响应则断开重连)。 |
`netstat -an |
| 粘包/拆包 | TCP是字节流协议,无消息边界,可能将多个数据包合并(粘包)或拆分(拆包) | 解决 : 1. 定长包头(如4字节大端表示包体长度,接收方先读长度再读数据); 2. 分隔符(如用0x00作为文本协议结束符,需注意转义); 3. 协议编码(如Protobuf自带长度字段,序列化时自动处理)。 |
用hexdump分析二进制流;自定义协议调试工具(打印包头/包体) |
2. 高并发网络模型:从"单线程"到"异步IO"的性能跃迁
网络模型直接决定服务的并发承载能力,不同场景需匹配不同模型,盲目选择会导致性能浪费。
| 网络模型 | 核心逻辑 | 性能瓶颈 | 适用场景 | 实战实现(以Golang为例) |
|---|---|---|---|---|
| 阻塞IO(BIO) | 1个线程处理1个连接,读写阻塞 | 线程数有限(默认线程栈1MB,最多万级线程),并发量<1万 | 低并发工具(如内部脚本) | net.Listen+goroutine(每个连接起一个goroutine,简单但不适合高并发) |
| IO多路复用(epoll/kqueue) | 单线程通过内核监听多个IO事件,就绪后处理(Reactor模型) | 单线程处理事件分发,CPU密集时会阻塞 | 高并发网络服务(如API网关、消息队列) | 基于syscall.EpollCreate实现: 1. epoll监听读/写事件; 2. 就绪事件分发到线程池处理业务; 3. 用ET模式(边缘触发)减少事件触发次数。 |
| 异步IO(AIO) | 内核完成IO后主动通知应用(Proactor模型) | 内核实现复杂,跨平台兼容性差(Linux AIO支持有限) | 高IO密集型服务(如分布式存储) | 结合libaio库: 1. 提交异步读请求; 2. 注册回调函数; 3. 内核完成后触发回调处理数据。 |
实战案例:某高并发网关(支撑50万并发连接)
- 采用"epoll ET模式+线程池"架构:主线程(1个)负责epoll_wait监听连接事件,8个工作线程处理业务(解码、路由、编码);
- 连接管理:用哈希表存储
fd→连接对象,每30s扫描一次超时连接(300s无数据则关闭); - 性能优化:
- 读写缓冲区预分配(避免频繁malloc);
- 批量接收数据(
readv一次读取多个缓冲区); - 禁用Nagle算法(
TCP_NODELAY=1,减少小包延迟)。
3. 网络框架封装:屏蔽细节,聚焦业务
中大型项目需封装通用网络框架,解决"重复造轮子"问题,核心模块如下:
| 框架模块 | 核心功能 | 关键设计 | 性能考量 |
|---|---|---|---|
| 协议编解码 | 处理粘包/拆包、数据序列化 | 1. 协议格式:魔数(2B)+版本(1B)+长度(4B)+数据(nB)(魔数用于校验合法性); 2. 序列化:Protobuf(二进制,效率高)vs JSON(文本,易调试),根据场景选择。 |
解码逻辑用汇编优化(如Golang的encoding/binary比手写解析快30%) |
| 连接池管理 | 复用服务间长连接,减少握手开销 | 1. 池化策略:最小空闲连接=5,最大连接=50,超时回收=300s; 2. 健康检查:每60s发送Ping包,失败则标记连接不可用。 | 连接池用互斥锁+条件变量实现,避免并发竞争导致性能下降 |
| 超时控制 | 防止请求无限阻塞 | 1. 全局超时:所有请求默认3s超时; 2. 细粒度超时:重要请求(如支付)设置5s,非重要请求(如日志)设置1s; 3. 实现:用最小堆管理超时事件,每次epoll_wait设置超时时间=最近到期事件。 | 超时检查在IO线程执行,避免额外线程开销 |
二、架构设计:从"业务适配"到"高可用"的系统化思维
架构设计不是"炫技",而是"解决业务问题"------需根据用户量、数据量、业务复杂度选择合适的架构,并通过服务治理保障高可用。
1. 架构演进:跟着业务"从小到大"
架构演进的核心是"按需扩展",过早引入复杂架构会增加维护成本。
| 业务阶段 | 核心指标(用户量/数据量) | 架构方案 | 痛点与解决方案 | 技术栈 |
|---|---|---|---|---|
| 初创期 | 用户<10万,数据<100GB | 单体架构(All in One) | 痛点:代码耦合,迭代冲突。 解决:按模块划分目录(user/order/pay),用分层架构(API→Service→DAO)。 | Spring Boot + MySQL + Redis(缓存) |
| 增长期 | 用户10万-100万,数据100GB-1TB | 垂直拆分(按业务拆服务) | 痛点:服务间调用频繁(如订单服务查用户信息),接口不一致。 解决:定义统一API规范(如RESTful),用API网关(如Spring Cloud Gateway)管理路由。 | 用户服务/订单服务 + MySQL主从 + Redis集群 |
| 成熟期 | 用户100万-1亿,数据1TB-10TB | 微服务架构(服务解耦+独立部署) | 痛点:服务治理复杂(注册/发现/熔断),分布式事务难保证。 解决: 1. 服务治理:Nacos(注册中心)+ Sentinel(熔断); 2. 分布式事务:非核心用最终一致性(Kafka异步通知),核心用TCC。 | Spring Cloud Alibaba + Sharding-JDBC(分库分表) + Elasticsearch(检索) |
| 超大规模期 | 用户>1亿,数据>10TB | 云原生架构(容器化+动态扩缩容) | 痛点:运维成本高,资源利用率低。 解决: 1. 容器化:Docker打包,K8s编排; 2. 服务网格:Istio管理服务通信(流量控制/监控)。 | K8s + Istio + TiDB(分布式数据库) + MinIO(对象存储) |
架构设计原则:
- 服务拆分:按"领域边界"拆分(如"订单"领域包含订单创建、支付、物流),避免"按功能分层"(如所有查询放一个服务);
- 接口设计:"宽进严出"------输入参数兼容(预留扩展字段),输出参数严格(避免前端依赖冗余字段);
- 容错设计:"假设任何服务都会挂",核心服务需有降级方案(如支付服务挂了,订单服务返回"稍后支付")。
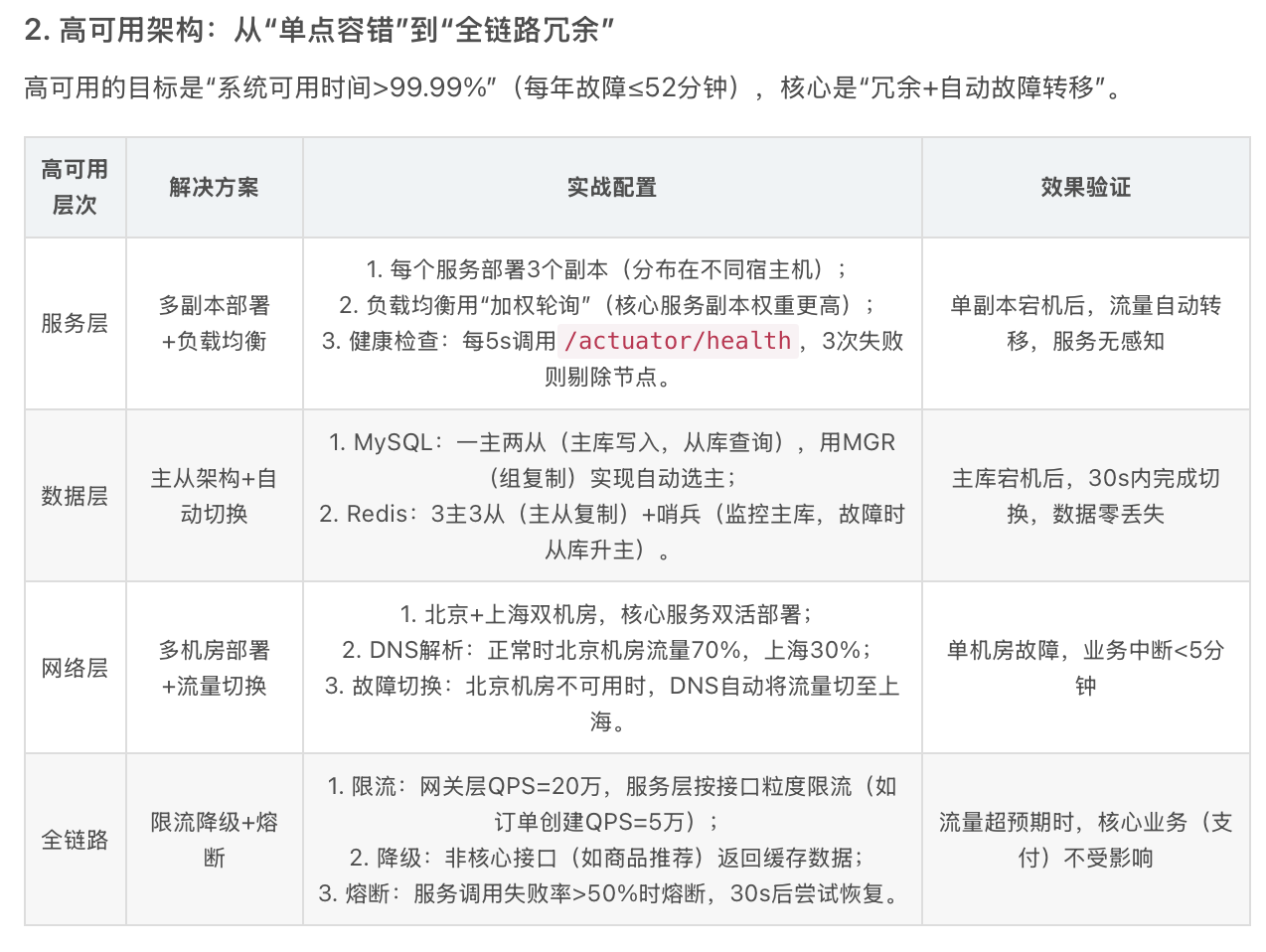
2. 高可用架构:从"单点容错"到"全链路冗余"
高可用的目标是"系统可用时间>99.99%"(每年故障≤52分钟),核心是"冗余+自动故障转移"。
| 高可用层次 | 解决方案 | 实战配置 | 效果验证 |
|---|---|---|---|
| 服务层 | 多副本部署+负载均衡 | 1. 每个服务部署3个副本(分布在不同宿主机); 2. 负载均衡用"加权轮询"(核心服务副本权重更高); 3. 健康检查:每5s调用/actuator/health,3次失败则剔除节点。 |
单副本宕机后,流量自动转移,服务无感知 |
| 数据层 | 主从架构+自动切换 | 1. MySQL:一主两从(主库写入,从库查询),用MGR(组复制)实现自动选主; 2. Redis:3主3从(主从复制)+哨兵(监控主库,故障时从库升主)。 | 主库宕机后,30s内完成切换,数据零丢失 |
| 网络层 | 多机房部署+流量切换 | 1. 北京+上海双机房,核心服务双活部署; 2. DNS解析:正常时北京机房流量70%,上海30%; 3. 故障切换:北京机房不可用时,DNS自动将流量切至上海。 | 单机房故障,业务中断<5分钟 |
| 全链路 | 限流降级+熔断 | 1. 限流:网关层QPS=20万,服务层按接口粒度限流(如订单创建QPS=5万); 2. 降级:非核心接口(如商品推荐)返回缓存数据; 3. 熔断:服务调用失败率>50%时熔断,30s后尝试恢复。 | 流量超预期时,核心业务(支付)不受影响 |
3. 性能优化:从"单点调优"到"链路协同"
性能优化需全链路排查,避免"优化某点却引发另一点瓶颈"。
| 瓶颈点 | 优化方案 | 技术工具 | 效果提升 |
|---|---|---|---|
| 网络延迟 | 1. 协议优化:用gRPC(HTTP/2)替代HTTP/1.1(多路复用,减少连接开销); 2. 数据压缩:gzip压缩文本数据(压缩率50%-70%); 3. 长连接复用:服务间保持TCP长连接(设置Connection: keep-alive)。 |
tcpdump抓包分析协议交互;curl -w测接口延迟 |
服务间调用延迟降低40% |
| 数据库慢查询 | 1. 索引优化:针对where/order by字段建联合索引(如user_id+create_time); 2. 分库分表:按用户ID哈希分16库,每库32表(单表数据<500万); 3. 读写分离:主库写入,从库承担80%查询流量。 |
explain分析SQL执行计划;pt-query-digest统计慢查询 |
数据库QPS提升10倍,查询耗时从1s→50ms |
| 服务CPU高 | 1. 异步化:非核心逻辑(如日志、通知)通过Kafka异步处理; 2. 缓存热点数据:本地缓存(如Caffeine)+ 分布式缓存(Redis); 3. 代码优化:避免大对象频繁创建(用对象池),减少锁竞争(用CAS替代互斥锁)。 | pprof分析CPU热点函数;jstack查看线程状态 |
服务CPU利用率从80%→40% |
三、海量数据处理:从"存不下"到"查得快"的全链路方案
当数据量突破单机上限(如MySQL单表1亿行),需通过"拆分+分布式"解决存储、查询、同步问题。
1. 海量数据存储:按"数据特性"选对存储方案
不同类型数据(结构化/非结构化/时序)的存储需求不同,需"对症下药"。
| 数据类型 | 特点 | 存储挑战 | 解决方案 | 技术选型 |
|---|---|---|---|---|
| 结构化数据(订单/用户) | 有固定Schema,需事务支持 | 单表数据超1亿行,查询/写入变慢 | 分库分表: 1. 水平分片:按用户ID哈希(mod 16分16库),避免数据倾斜; 2. 垂直分片:大表拆小表(如用户表→基本信息表+详情表); 3. 路由规则:通过Sharding-JDBC透明路由(应用层无需改SQL)。 | MySQL + Sharding-JDBC / TiDB(分布式SQL) |
| 非结构化数据(图片/视频) | 无固定格式,体积大(MB-TB级) | 单机存储有限,IO密集 | 对象存储: 1. 数据分片:文件拆分为1MB块,分布式存储; 2. 元数据管理:用MySQL存储文件名→块地址映射; 3. 冗余存储:每个块存3副本,避免单点丢失。 | MinIO(开源)/ 阿里云OSS |
| 时序数据(监控指标/日志) | 按时间生成,写入频繁(每秒百万条),查询多为时间范围 | 写入性能要求高,历史数据查询慢 | 时序数据库: 1. 按时间分区(如每小时一个分区); 2. 列式存储(同一指标数据连续存储,查询效率高); 3. 自动降采样(保存最近1小时原始数据,1小时前按分钟聚合)。 | InfluxDB / TDengine / Prometheus |
| 高并发读写数据(商品库存/计数器) | 读写频繁,一致性要求高(如库存不能超卖) | 单机Redis/QPS有限(约10万),分布式一致性难保证 | 分布式K-V: 1. Redis Cluster:3主3从,分片存储(槽位分配); 2. 原子操作:用Lua脚本实现"查库存+扣减"原子性; 3. 读写分离:主库写入,从库读(最终一致性)。 | Redis Cluster / TiKV |
2. 海量数据查询:"多级缓存+智能索引"加速
查询优化的核心是"减少数据扫描范围",结合缓存、索引、搜索引擎多维度优化。
| 查询场景 | 优化方案 | 技术工具 | 实战案例 |
|---|---|---|---|
| 高频简单查询(如用户信息) | 多级缓存: 1. 本地缓存(Caffeine,TTL=5分钟)→ 2. 分布式缓存(Redis,TTL=1小时)→ 3. 数据库 | Redis(设置maxmemory-policy allkeys-lru) |
用户信息查询QPS=5万,90%命中本地缓存,9%命中Redis,仅1%回源数据库 |
| 复杂条件查询(如商品筛选) | 搜索引擎: 1. 数据同步:MySQL binlog→Canal→Elasticsearch(近实时同步,延迟<1s); 2. 索引设计:商品名称用分词索引,价格/销量用数值索引; 3. 查询优化:用过滤查询(filter)替代普通查询(不计算评分,更快)。 | Elasticsearch(6分片3副本) | 商品筛选(价格>100+销量>1000)耗时从500ms→50ms |
| 实时统计分析(如实时销售额) | 流处理+缓存: 1. 实时计算:订单创建事件→Kafka→Flink→实时累加销售额; 2. 结果存储:Flink将结果写入Redis(Hash类型:date→product→amount); 3. 查询接口:直接查Redis,避免扫表。 |
Flink + Redis | 实时销售额查询QPS=1万,延迟<100ms |
| 历史数据报表(如年度订单分析) | 数据仓库: 1. 数据同步:每日凌晨用Spark将MySQL数据同步到ClickHouse; 2. 分区存储:按年分区,支持分区裁剪; 3. 预计算:提前计算常用指标(如每月订单数),避免重复计算。 | ClickHouse + Spark | 年度订单分析报表生成时间从1小时→5分钟 |
3. 数据同步与一致性:平衡"实时性"与"可靠性"
海量数据分布在多存储节点,同步与一致性是必须解决的问题,需根据业务场景选择方案。
| 一致性要求 | 同步方案 | 适用场景 | 实现细节 |
|---|---|---|---|
| 强一致性(如支付/库存) | 分布式事务: - TCC模式(Try-Confirm-Cancel):Try预扣库存,Confirm确认扣减,Cancel回滚; - 2PC(两阶段提交):适合数据库间强一致(性能较低)。 | 订单创建+扣库存、转账 | 用Seata实现TCC: 1. Try阶段:库存表stock=stock-1, freeze=freeze+1; 2. Confirm阶段:freeze=freeze-1; 3. Cancel阶段:stock=stock+1, freeze=freeze-1。 |
| 最终一致性(如用户积分/日志) | 异步通知: - CDC(变更数据捕获):Debezium监听MySQL binlog,同步到Elasticsearch/Kafka; - 消息队列:业务操作完成后发送消息,消费者异步更新数据。 | 用户消费后积分更新、订单日志同步 | 积分同步: 1. 订单服务创建订单后,发送Kafka消息(user_id+amount); 2. 积分服务消费消息,更新用户积分; 3. 消息重试:失败后重试3次,仍失败则人工介入。 |
| 因果一致性(如社交关系) | 时序同步: - 逻辑时钟:每个操作带版本号(如user_id+seq),确保先关注后发消息的因果关系; - 事件溯源:存储所有事件,按需回放生成最新状态。 |
关注用户后可见其消息、评论回复顺序 | 社交消息: 1. 关注事件seq=100,发消息事件seq=101; 2. 消费时按seq顺序处理,确保关注后才能收到消息。 |
总结
网络编程、架构设计、海量数据处理是中大型后台开发的"三大支柱":
- 网络编程是基础,决定了数据传输的效率与稳定性;
- 架构设计是框架,决定了系统的可扩展性与高可用性;
- 海量数据处理是支撑,决定了系统能否应对业务增长的极限。