目录
背景知识
先了解一下内存结构,但这个不是必须的。

Definition
递归是一个循环结构,主要用来处理需要循环执行的任务,和For循环类似的代码结构。
简单说就是函数自己能调用自己。
js
fun factorial(n:Int):Int{
if(n <= 1) return n
else return n*factorial(n-1)
}用图理解:

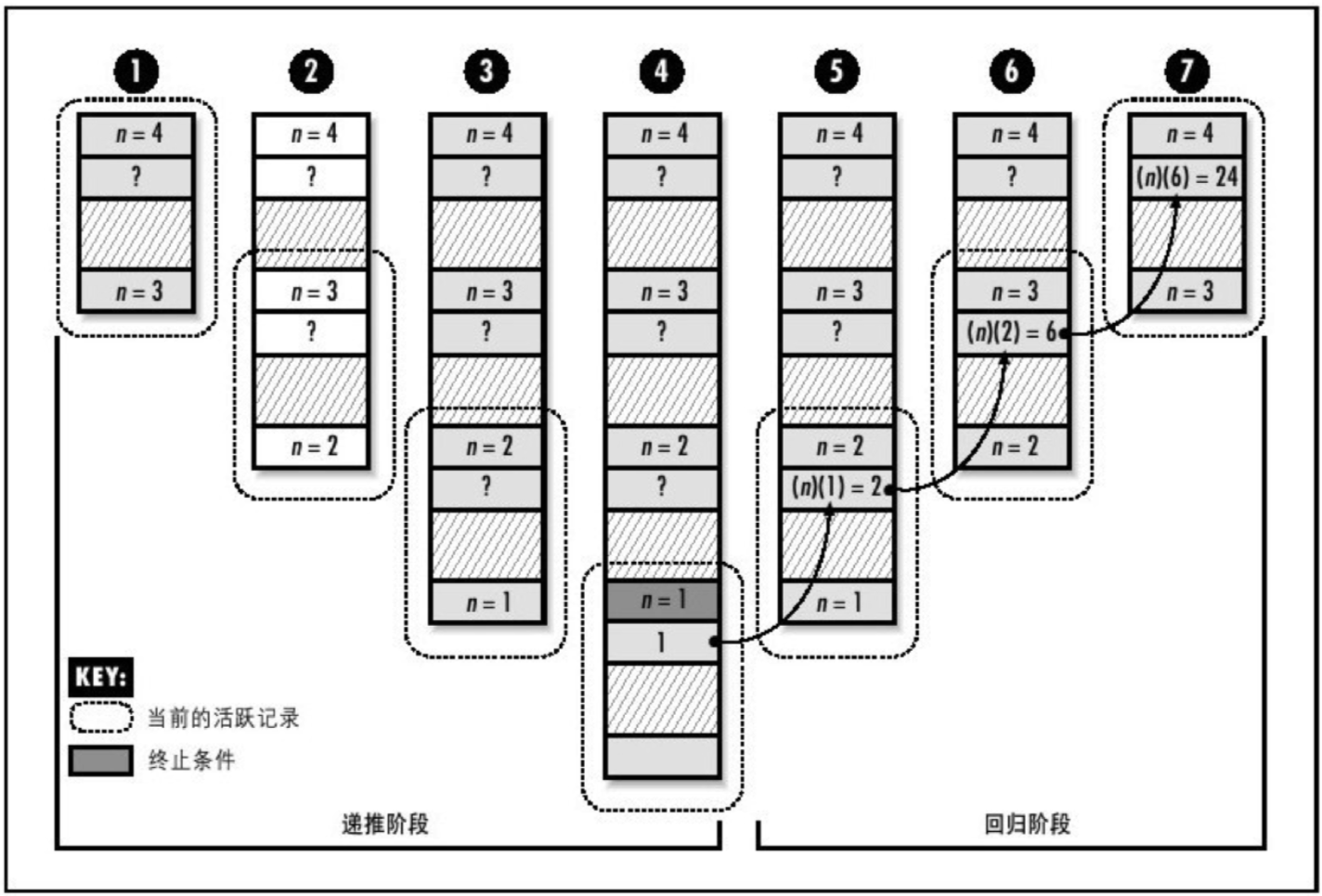
从堆栈的角度理解递归
递归的底层就是利用堆栈和指令结构所实现的功能。

缺点
从使用堆栈的资源角度来说,会比For以及其他循环结构更耗资源。
- 内存开销
- 堆栈:每次函数调用都会在栈上分配新的栈帧,包含参数、返回地址、局部变量等
- 循环:只在当前栈帧内重复执行,不需要额外的栈空间
- 上下文切换成本
- 堆栈(递归):涉及函数调用、返回地址保存、寄存器保存等操作
- 循环:简单的跳转指令,几乎没有上下文切换开销
- 缓存效率
- 堆栈:频繁的函数调用可能导致缓存失效
- 循环:代码局部性更好,缓存命中率更高
和For循环的区别
和For循环的区别有很多,但我主要想讨论他们对解决问题的思考方式上的差别。这个也是我想让大家理解的第二层含义。
如果说递归的第一层含义是:自己调用自己。
那么递归的第二层含义是:上一次的函数输出,可以成为下一次函数的输入。
案例------阶梯问题:
我们以爬楼梯问题为例:有n阶台阶,每次可以爬1或2阶,问有多少种不同的方法爬到楼顶?
这实际上就是求斐波那契数列。
递归终止条件:
当 n=1 时,只有1种方法:爬1阶。
当 n=2 时,有两种方法:一次爬2阶,或者两次各爬1阶。
对于n>2的情况,考虑第一步有两种选择:
第一步爬1阶,那么剩下的n-1阶台阶有 climb_stairs_recursive(n-1) 种方法。
第一步爬2阶,那么剩下的n-2阶台阶有 climb_stairs_recursive(n-2) 种方法。
因此,爬n阶台阶的方法数等于这两种情况的方法数之和,即:
climb_stairs_recursive(n) = climb_stairs_recursive(n-1) + climb_stairs_recursive(n-2)
举个例子:n=3
第一步爬1阶,剩下2阶:有2种方法(爬2阶:一次2阶,或两次1阶)
第一步爬2阶,剩下1阶:有1种方法(爬1阶)
所以总共2+1=3种方法。
同理,n=4:
第一步爬1阶,剩下3阶:3种方法(上面n=3的情况)
第一步爬2阶,剩下2阶:2种方法(n=2的情况)
所以总共3+2=5种。
想要知道4阶有多少种,那么需要先知道3阶有多少种?
那么,想知道3阶有多少种,那么就得知道2阶有多少种?
一直追问到终止条件为止。
python
def climb_stairs_recursive(n):
# 基础情况
if n == 1:
return 1 # 只有1种方法:走1步
if n == 2:
return 2 # 2种方法:1→1 或 2
# 递归关系:f(n) = f(n-1) + f(n-2)
return climb_stairs_recursive(n-1) + climb_stairs_recursive(n-2)为了方便理解,加上了打印参数:
python
def climb_stairs_recursive(n, depth=0):
indent = " " * depth # 根据深度缩进,显示调用层次
print(f"{indent}-> climb_stairs({n})")
# 基础情况
if n == 1:
print(f"{indent}<- 返回 1 (基础情况: n=1)")
return 1
if n == 2:
print(f"{indent}<- 返回 2 (基础情况: n=2)")
return 2
# 递归调用
print(f"{indent} 计算 climb_stairs({n - 1}) + climb_stairs({n - 2})")
left = climb_stairs_recursive(n - 1, depth + 1)
right = climb_stairs_recursive(n - 2, depth + 1)
result = left + right
print(f"{indent}<- 返回 {result} = {left} + {right}")
return result
print("计算 climb_stairs(4):")
print(f"最终结果: {climb_stairs_recursive(4)}")
#print:
计算 climb_stairs(4):
-> climb_stairs(4)
计算 climb_stairs(3) + climb_stairs(2)
-> climb_stairs(3)
计算 climb_stairs(2) + climb_stairs(1)
-> climb_stairs(2)
<- 返回 2 (基础情况: n=2)
-> climb_stairs(1)
<- 返回 1 (基础情况: n=1)
<- 返回 3 = 2 + 1
-> climb_stairs(2)
<- 返回 2 (基础情况: n=2)
<- 返回 5 = 3 + 2
最终结果: 5对比for循环的写法:
# 需要在写代码的时候,自己维护状态
def climb_stairs_iterative(n):
if n <= 2:
return n
a, b = 1, 2
for i in range(3, n+1):
a, b = b, a + b
return b在台阶问题(比如爬楼梯,每次可以走1步或2步,问n阶台阶有多少种走法)中,递归和循环都可以实现,但各有优劣。
递归方式的优点:
- 代码直观,易于理解:递归往往能够直接反映问题的数学定义,比如斐波那契数列、爬楼梯问题的递推关系。
- 易于设计和实现:对于复杂问题,递归可以简化设计过程。
但是,在台阶问题中,递归的缺点也很明显:
- 效率低:存在大量重复计算,导致指数级的时间复杂度。
- 栈溢出风险:当n较大时,递归深度过深,会导致栈溢出。
- 而循环(动态规划)方式则通过迭代和保存中间结果,避免了重复计算,时间复杂度为O(n),空间复杂度可以优化到O(1)。
总结
在快速原型阶段,可以使用递归是实现算法,好处是:
- 快速验证算法思路
- 更容易修改和调整逻辑
方便快速实现。
而到了中后期的优化阶段,可以考虑把循环结构改成动态规划(for)循环,以节省内存资源。
还有,
递归的直观性和易于理解是其主要优点,但在性能上不如循环。如果一个问题在初期就很容易用循环想清楚,则没必要使用递归。
Reference
《秒懂算法》 作者:杰伊·温格罗