AsyPPO: 轻量级mini-critics如何提升大语言模型推理能力
大型语言模型强化学习训练面临计算瓶颈,传统对称actor-critic架构导致critic模型参数量巨大,训练成本高昂。本文介绍的Asymmetric Proximal Policy Optimization (AsyPPO)算法通过创新的非对称架构设计,使用轻量级mini-critics组合实现高效价值估计,在保持性能的同时显著降低计算开销。实验表明,该方法在多个数学推理基准上平均提升超过3%准确率,训练内存占用减少20%,每步训练时间缩短约20秒。
论文标题: Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
来源: arXiv:2510.01656v3 cs.LG + http://arxiv.org/abs/2510.01656
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景:
在大型语言模型强化学习训练中,传统PPO算法采用的对称actor-critic架构面临严峻挑战。由于LLM参数规模巨大,与actor同等规模的critic模型导致计算开销呈指数级增长,训练成本难以承受。此外,在稀疏奖励和长推理轨迹场景下,大规模critic训练往往效果不佳且易于过拟合。为应对这些挑战,当前主流方法如GRPO等选择放弃critic,转而使用平均优势基线进行粗粒度估计,但这牺牲了稳健状态价值估计带来的训练稳定性优势。如何在保持计算效率的同时恢复critic的关键作用,成为RL4LLM领域亟待解决的核心问题。
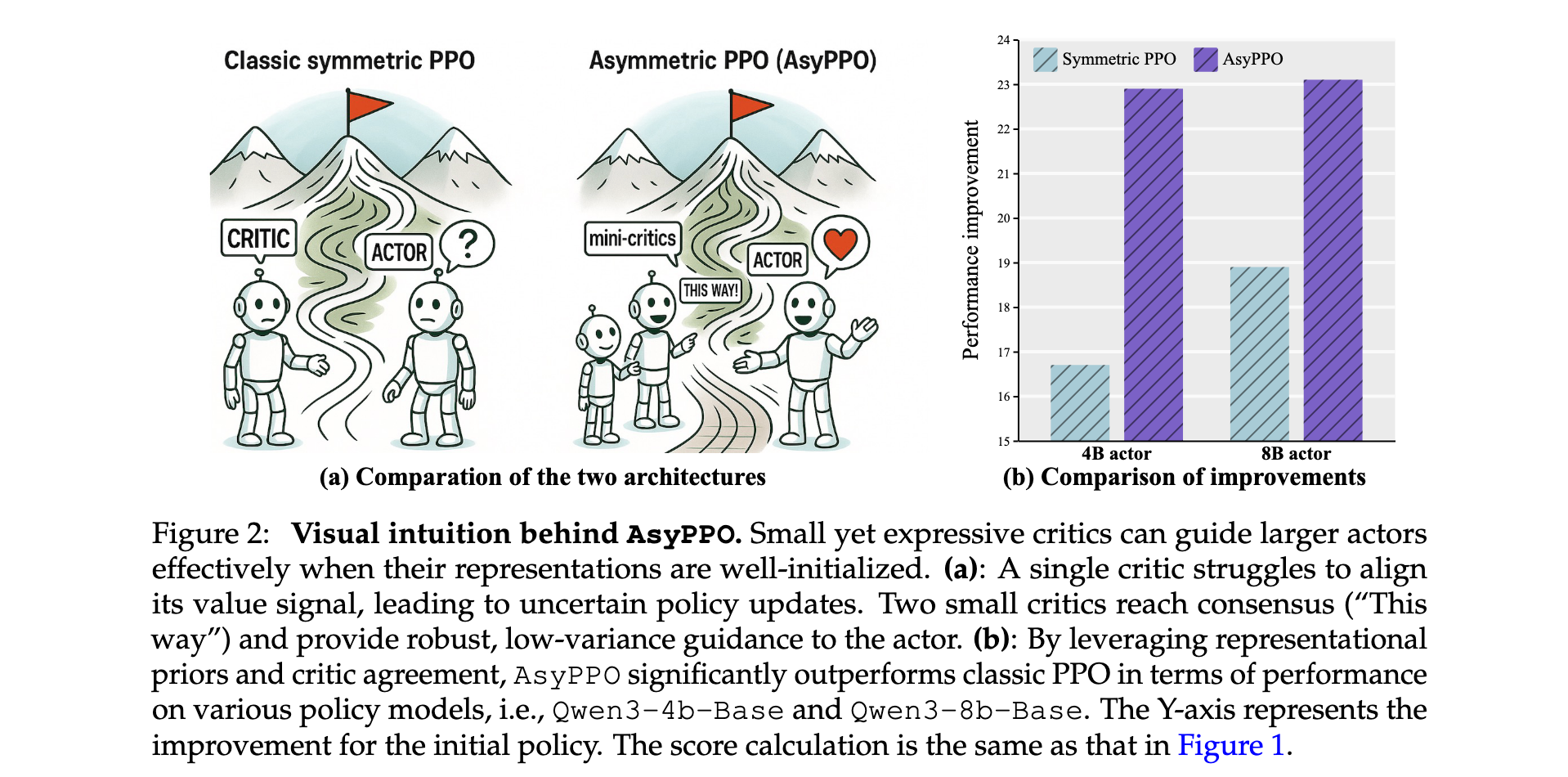
研究问题:
- 计算效率瓶颈:传统对称PPO架构中critic模型参数量与actor相当,在LLM规模下导致训练内存和时间开销巨大
- 价值估计准确性:单个轻量级critic在稀疏奖励和长推理轨迹场景下价值估计偏差较大,难以提供有效指导
- 样本利用效率:现有方法缺乏有效的样本质量评估机制,导致低信息样本造成的过拟合和无意义探索
主要贡献:
- 轻量级非对称架构:提出基于mini-critics集合的非对称actor-critic设计,通过多个轻量级critic组合实现稳健价值估计,显著降低计算开销(峰值内存减少20%,训练时间每步缩短约20秒)
- 数据分割策略:创新性地采用prompt级非重叠数据分割技术,确保每个critic学习差异化轨迹,增强ensemble多样性同时保持感知同步性
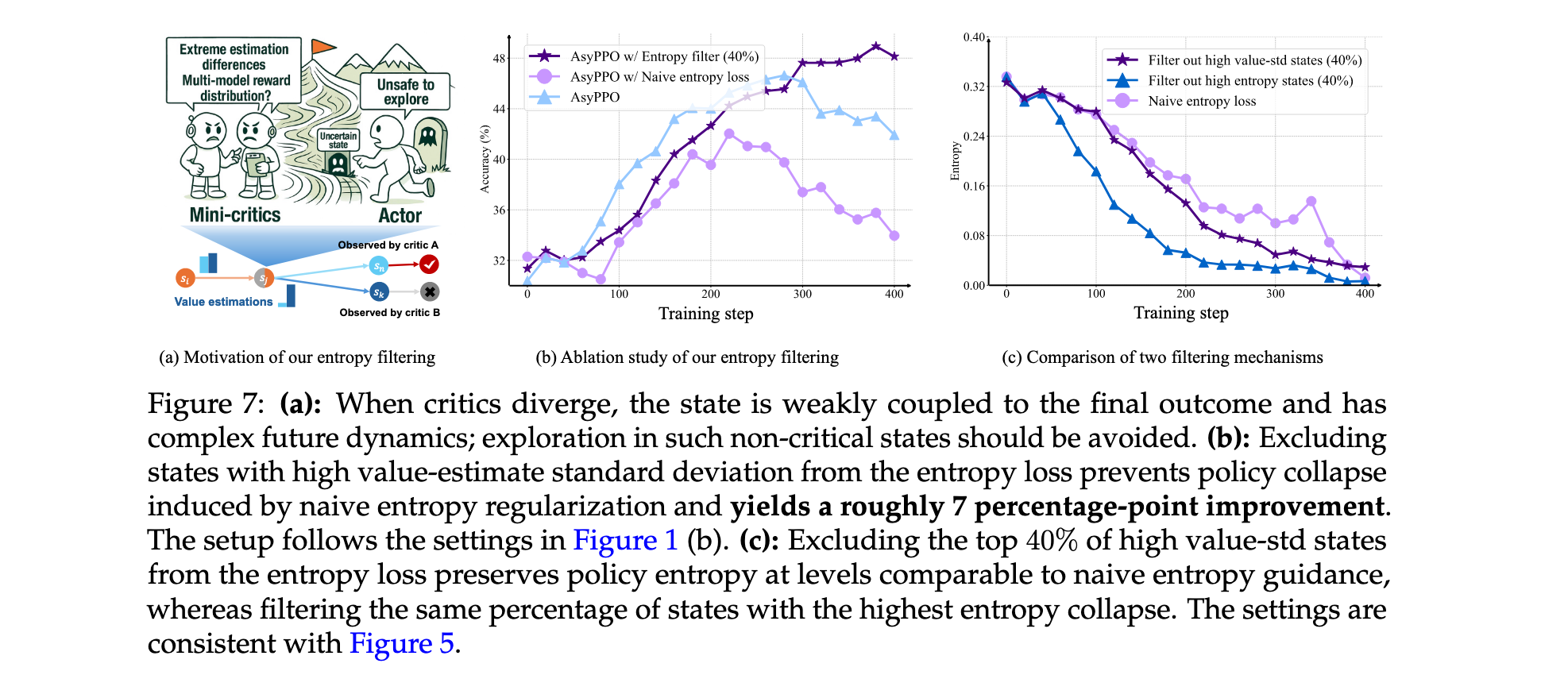
- 不确定性感知优化:利用critic间价值估计差异作为信号,提出advantage masking和entropy filtering机制,提升样本效率和探索安全性
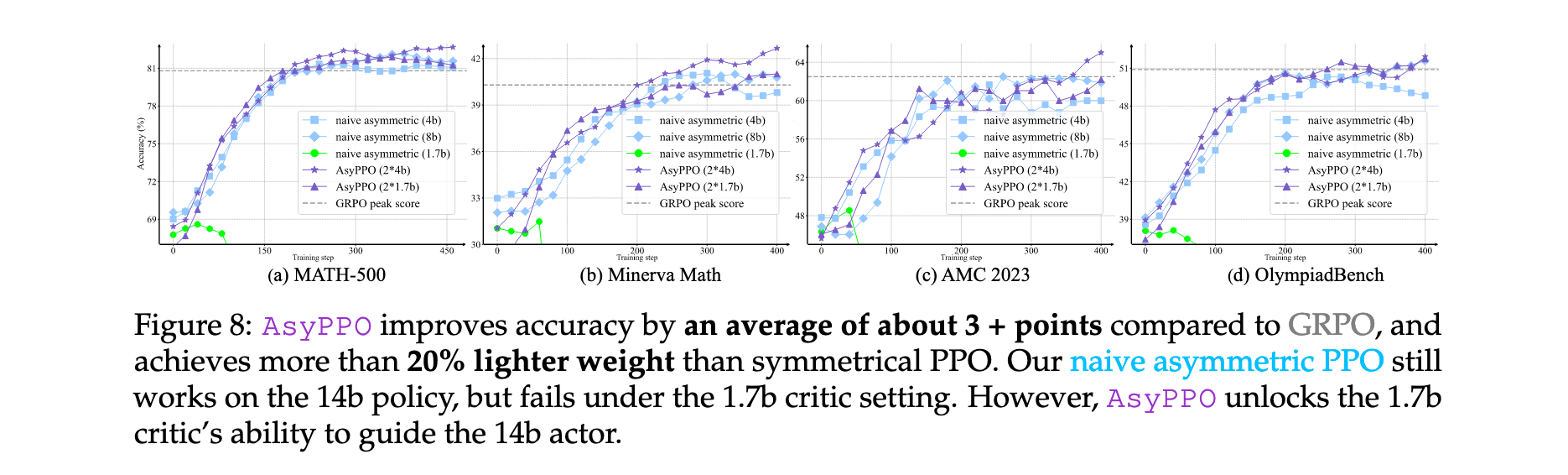
- 性能显著提升:在仅使用5,000个开源样本训练后,在Qwen3-4b-Base上取得超过6%的性能提升,在Qwen3-8b-Base和Qwen3-14b-Base上实现约3%的提升
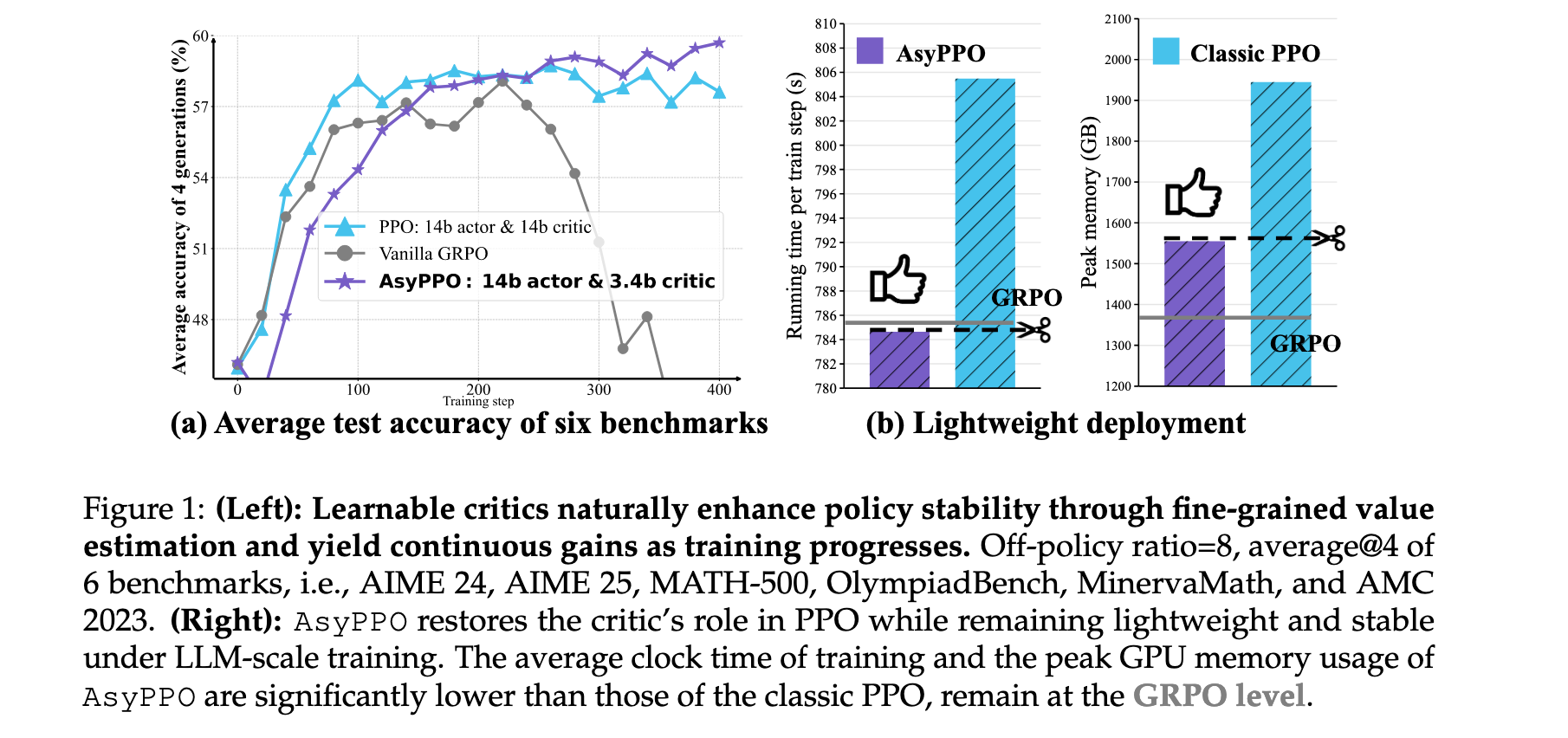
方法论精要
AsyPPO算法的核心思想是通过架构创新解决RL4LLM中的计算效率与价值估计质量之间的矛盾。该方法包含三个关键组件:轻量级mini-critics集合、非重叠数据分割策略和不确定性感知的policy优化目标。
轻量级非对称架构设计
传统PPO采用对称actor-critic架构,critic与actor规模相当,这在LLM场景下造成巨大计算负担。AsyPPO突破性地采用非对称设计,使用多个轻量级mini-critics指导大规模actor。研究发现,得益于预训练模型提供的丰富表示能力,小规模critic(如Qwen3-0.6b-Base)能够为大规模actor(如Qwen3-8b-Base)提供有意义的指导。然而,单个mini-critic由于表达能力有限,在稀疏奖励和长推理轨迹场景下价值估计准确性不足。
为解决这一限制,AsyPPO引入critic ensemble机制。但与传统ensemble不同,直接使用多个相同初始化的critic效果有限,因为它们往往产生几乎相同的价值估计,缺乏必要的多样性。实验表明,两个critics是效果与效率的最佳平衡点,能够在提供可靠价值校正的同时保持较低的计算开销。
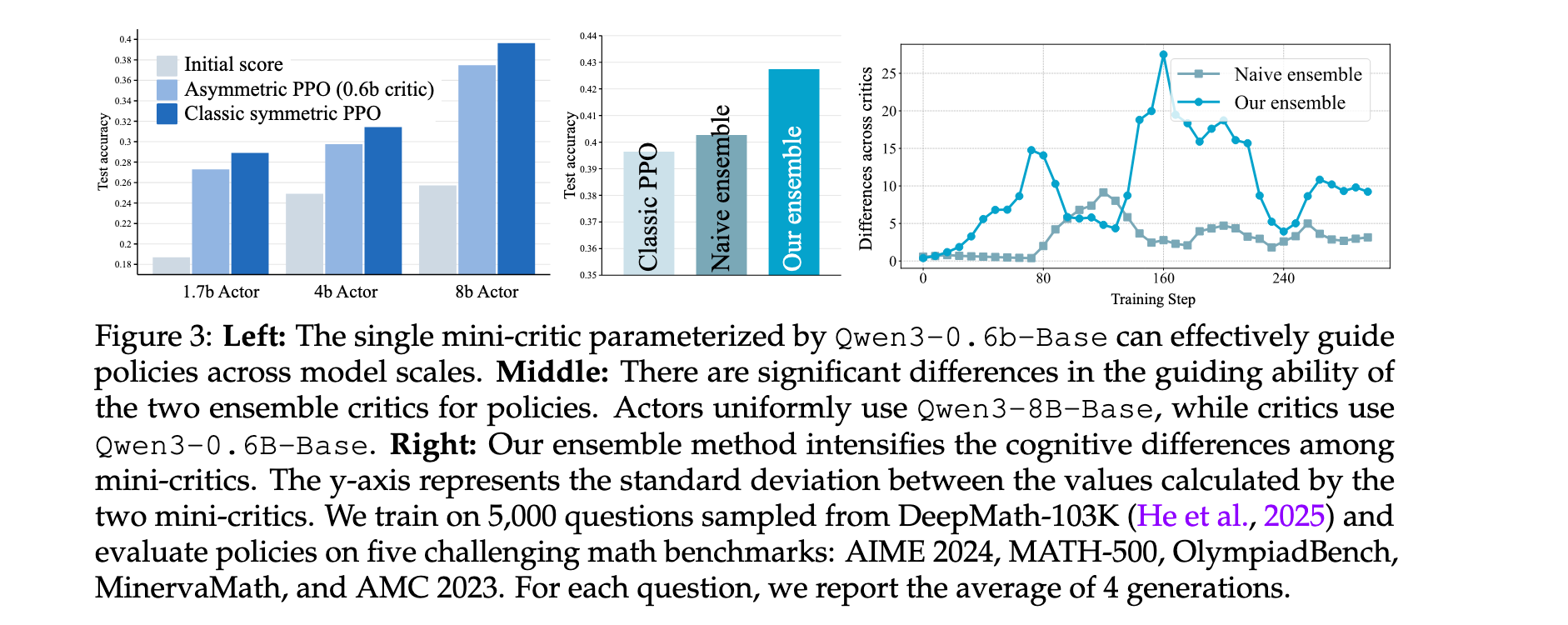
非重叠数据分割策略
为增强mini-critics之间的多样性,AsyPPO提出创新的prompt级非重叠数据分割技术。具体而言,对于每个prompt,均匀提取响应序列分配给不同critic,确保每个critic在每个问题中都能看到完整的推理轨迹片段,同时接收差异化的奖励信号和观测数据。
这种设计的关键优势在于维持了critics之间的感知同步性,避免了随机数据分割可能导致的问题类型不平衡和过拟合风险。形式化地,对于M个mini-critics,训练目标定义为:
L c r i t i c ( ϕ ) = ∑ m = 1 M L c r i t i c ( m ) ( ϕ m ) = ∑ m = 1 M E ( s t , R t ) ∼ D m ( V ( s t ; ϕ m ) − R t ) 2 L_{critic}(\phi) = \sum_{m=1}^{M} L^{(m)}{critic}(\phi^m) = \sum{m=1}^{M} \mathbb{E}_{(s_t,R_t) \sim \mathcal{D}^m} \left (V(s_t; \\phi\^m) - R_t)\^2 \\right Lcritic(ϕ)=∑m=1MLcritic(m)(ϕm)=∑m=1ME(st,Rt)∼Dm(V(st;ϕm)−Rt)2
其中 D = ⋃ m = 1 M D m \mathcal{D} = \bigcup_{m=1}^{M} \mathcal{D}^m D=⋃m=1MDm且 D i ∩ D j = ∅ \mathcal{D}^i \cap \mathcal{D}^j = \emptyset Di∩Dj=∅。校正后的优势估计通过ensemble价值的平均计算:
A ˉ t ( γ , λ ) = ∑ l = 0 T − t − 1 ( γ λ ) l δ t + l , δ t = r t + γ V ˉ ( s t + 1 ) − V ˉ ( s t ) ; V ˉ ( s t ) = 1 M ∑ m = 1 M V m ( s t ; ϕ m ) \bar{A}t(\gamma,\lambda) = \sum{l=0}^{T-t-1} (\gamma\lambda)^l \delta_{t+l}, \delta_t = r_t + \gamma\bar{V}(s_{t+1}) - \bar{V}(s_t); \bar{V}(s_t) = \frac{1}{M}\sum_{m=1}^{M} V^m(s_t; \phi^m) Aˉt(γ,λ)=∑l=0T−t−1(γλ)lδt+l,δt=rt+γVˉ(st+1)−Vˉ(st);Vˉ(st)=M1∑m=1MVm(st;ϕm)
不确定性感知的policy优化
AsyPPO的另一个核心创新是利用critics间价值估计的不确定性作为信号来改进policy优化。通过分析critics价值估计的一致性和分歧模式,可以推断状态的信息量和探索成本。
Advantage Masking机制:当critics对某个状态的价值估计高度一致时(标准差低),表明该状态信息量有限,学习潜力较小。AsyPPO识别并屏蔽这些低价值-标准差状态对应的advantage值,减少对低信息样本的过拟合,提高训练稳定性。具体实现为:
J P P O ( θ ) = E 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ I t A ⋅ min ( I S t ⋅ A ˉ t , clip ( I S t , 1 − ϵ , 1 + ϵ ) A ˉ t ) J_{PPO}(\theta) = \mathbb{E} \left \\frac{1}{\|o\|} \\sum_{t=1}\^{\|o\|} I\^A_t \\cdot \\min \\left( IS_t \\cdot \\bar{A}_t, \\text{clip}(IS_t, 1-\\epsilon, 1+\\epsilon) \\bar{A}_t \\right) \\right JPPO(θ)=E∣o∣1∑t=1∣o∣ItA⋅min(ISt⋅Aˉt,clip(ISt,1−ϵ,1+ϵ)Aˉt)
其中 I t A = { 0 , a m p ; if σ t ∈ Low k ( σ ) 1 , a m p ; otherwise I^A_t = \begin{cases} 0, & \text{if } \sigma_t \in \text{Low}k(\sigma) \\ 1, & \text{otherwise} \end{cases} ItA={0,1,amp;if σt∈Lowk(σ)amp;otherwise, σ t = std ( { V ( s t ; ϕ m ) } m = 1 M ) \sigma_t = \text{std}\left( \{V(s_t; \phi^m)\}{m=1}^M \right) σt=std({V(st;ϕm)}m=1M)表示状态 s t s_t st的价值估计标准差。
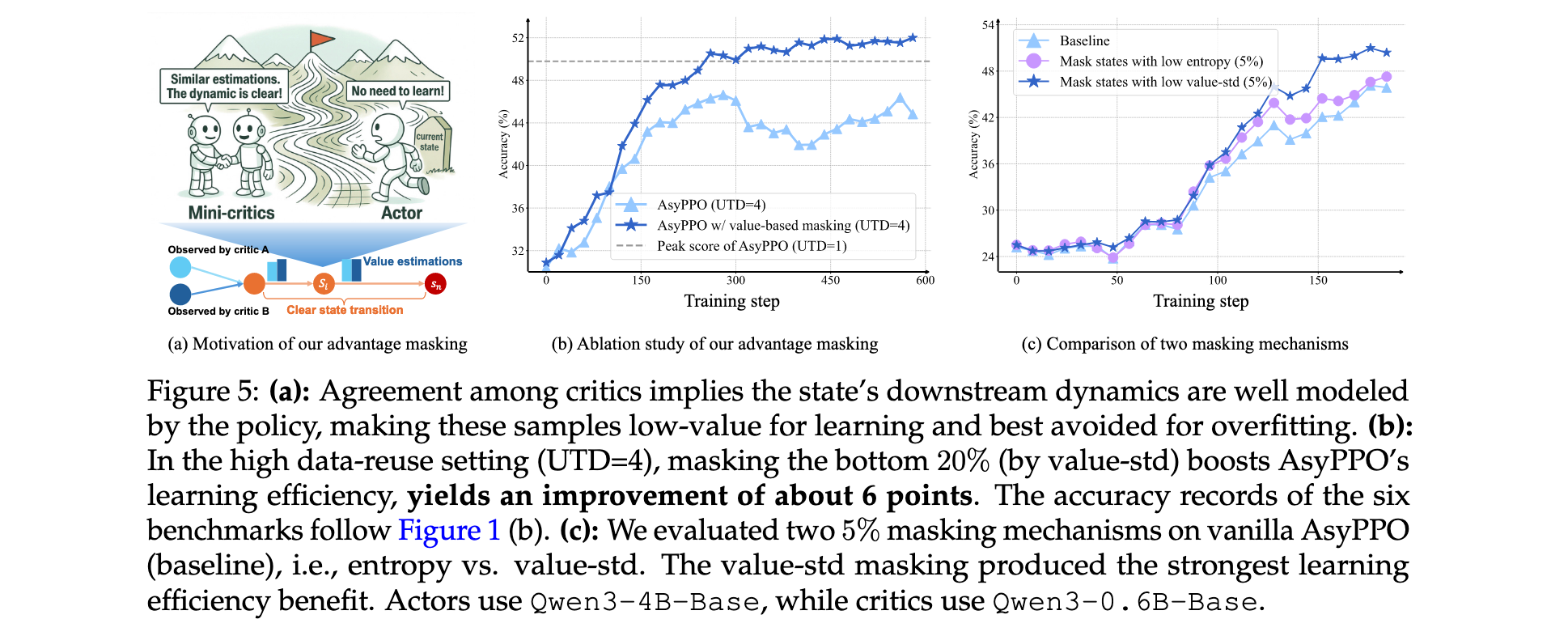
Entropy Filtering机制:当critics对某个状态的价值估计分歧较大时(标准差高),可能表明该状态与最终结果弱相关,包含大量推理无关的噪声模式。在这些状态下进行持续探索意义不大。AsyPPO从熵正则化中过滤掉高价值标准差状态,促进更有意义的探索:
J P P O ( h e t a ) = E 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ ( I t A ⋅ min ( I S t ⋅ A ˉ t , clip ( I S t , 1 − ϵ , 1 + ϵ ) A ˉ t ) + β ⋅ I t H ⋅ H \[ π θ ( ⋅ ∣ s t ) ) ] J_{PPO}( heta) = \mathbb{E} \left \\frac{1}{\|o\|} \\sum_{t=1}\^{\|o\|} \\left( I\^A_t \\cdot \\min \\left( IS_t \\cdot \\bar{A}_t, \\text{clip}(IS_t, 1-\\epsilon, 1+\\epsilon) \\bar{A}_t \\right) + \\beta \\cdot I\^H_t \\cdot H\[\\pi_\\theta(\\cdot\|s_t) \right) \right] JPPO(heta)=E∣o∣1∑t=1∣o∣(ItA⋅min(ISt⋅Aˉt,clip(ISt,1−ϵ,1+ϵ)Aˉt)+β⋅ItH⋅H\[πθ(⋅∣st))]
其中 I t H = { 0 , a m p ; if σ t ∈ Top h ( σ ) 1 , a m p ; otherwise I^H_t = \begin{cases} 0, & \text{if } \sigma_t \in \text{Top}_h(\sigma) \\ 1, & \text{otherwise} \end{cases} ItH={0,1,amp;if σt∈Toph(σ)amp;otherwise。
算法流程
AsyPPO的完整训练流程如Algorithm 1所示。对于每个训练步骤,系统首先生成响应序列,然后为每个critic构建训练子集并更新价值函数。接着计算校正后的优势估计和不确定性指标,生成masking和filtering向量。最后使用重构的PPO损失更新policy参数。

实验洞察
AsyPPO在多个数学推理基准上进行了全面评估,包括MATH-500、OlympiadBench、MinervaMath和AMC 2023等挑战性任务。实验设计围绕三个核心研究问题展开:AsyPPO在大规模模型上的泛化能力、对critic规模和数量的敏感性,以及advantage masking和entropy filtering的最佳设置。
大规模模型泛化性能
在Qwen3-14b-Base actor上的实验结果表明,AsyPPO相比基线方法取得显著提升。具体而言,使用两个4b critics的AsyPPO在所有任务上实现最强性能,相比GRPO平均提升约3个百分点。值得注意的是,朴素非对称PPO(单个mini-critic指导大规模actor)存在明显的critic容量阈值:单个Qwen3-1.7b-Base critic无法可靠指导14b actor,尽管它能成功指导8b actor;升级到4b critic则恢复有效学习。相比之下,AsyPPO降低了这一要求,1.7b critics即可提供实质性的推理能力提升。
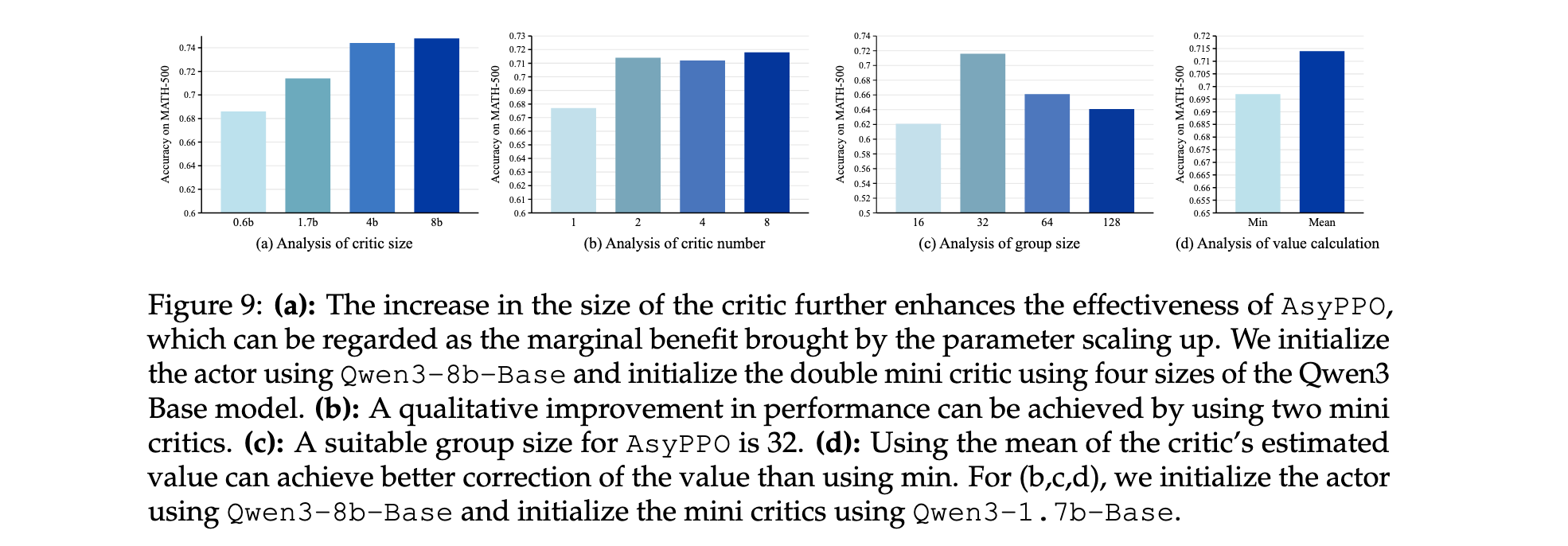
Critic配置敏感性分析
对critic规模和数量的消融研究揭示了重要见解。图9(a)显示了类似缩放定律的趋势:增加critic规模稳步提高policy的峰值分数,建议使用GPU内存允许的最大critic模型以最大化AsyPPO的优化能力。然而,增加critic数量并未带来类似收益:图9(b)显示两个mini-critics足以实现明显的性能跃升。在GRPO组大小(每个prompt的轨迹数)变化实验中,发现32是一个鲁棒的设置。在ensemble价值聚合方面,价值均值优于最小值,表明在RL4LLM中高估并非主导问题。
不确定性机制优化
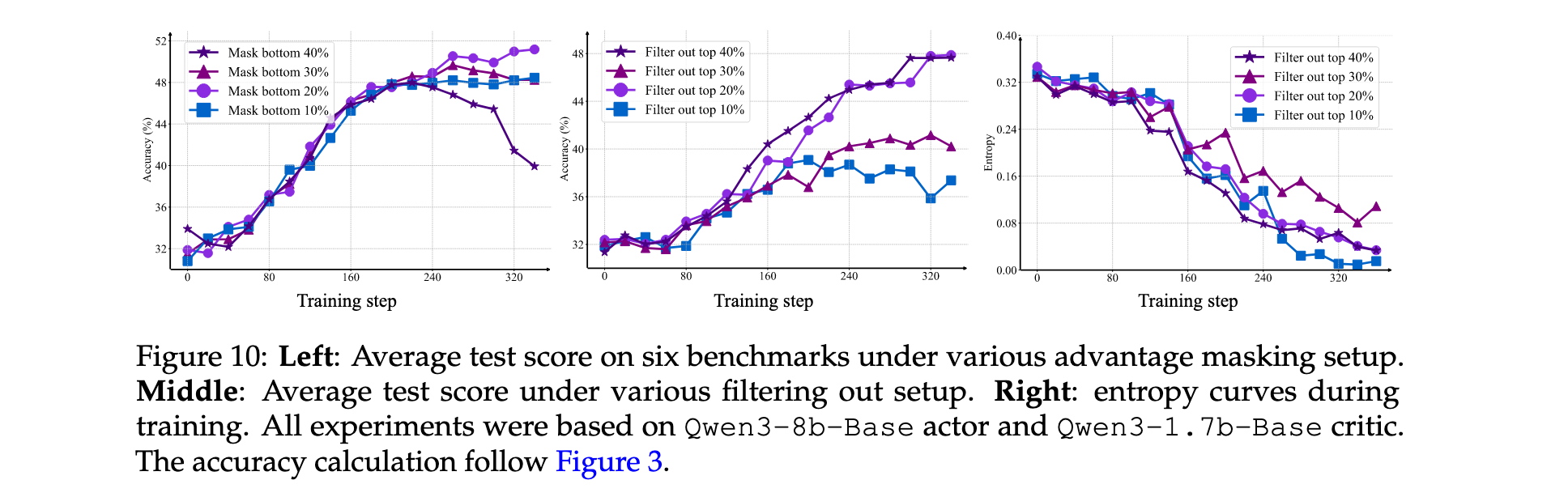
为确定鲁棒的advantage masking百分比,采用Qwen3-8b-Base作为policy和两个Qwen3-1.7b-Base critics的设置。图10(左)显示屏蔽20%的低价值-标准差状态提供最强收益。对于entropy filtering,测试了10%、20%、30%和40%的过滤比例。如图10(中、右)所示,较大的mask会导致熵崩溃,而20%在探索-利用平衡方面表现最佳。
计算效率分析
AsyPPO在保持性能的同时显著提高了计算效率。如图1(b)所示,AsyPPO的峰值GPU内存使用和平均训练时钟时间显著低于经典PPO,保持在GRPO水平。具体而言,非对称架构减少峰值内存20%,每步训练加速约20秒。这种轻量级部署特性使AsyPPO成为实际RL4LLM应用的理想选择。
价值估计质量分析
从语言学角度的统计分析显示,AsyPPO ensemble框架的校正价值显著鼓励policy获取核心推理模式。图4表明,mini-critics能够对涉及关键推理模式的状态提供积极估计,包括验证回溯、反向推理和子目标设定等。这种能力解释了为什么AsyPPO能够在稀疏奖励和长推理轨迹场景下保持稳定学习。
AsyPPO的成功不仅体现在性能提升上,更重要的是为RL4LLM算法设计开辟了新方向。通过架构创新而非纯粹的算法或优化改进,AsyPPO解决了critic瓶颈问题,同时保持了训练稳定性和样本效率。这一方法为未来大规模语言模型强化学习训练提供了实用且高效的解决方案。