摘要:本研究提出了一种基于深度学习的中国交通警察手势识别与指令优先级判定系统,通过特征提取提升了"直行"、"变道"、"左转弯"、"左转弯待转"、"靠边停车"、"右转弯"、"减速慢行"和"停止"指令的识别精度,为交通管理与应急响应提供支持。
作者:Bob(原创)
算法概述
1.Swin Transformer
Swin Transformer由微软公司的研究人员推出,是一种有效结合了 CNN 和 Transformer模型优势的新型架构。它旨在以类似 CNN 的分层方式处理图像,同时利用变换器固有的自我关注机制。这种混合方法使 Swin 变换器能够有效处理各种规模的视觉信息,从而使其在广泛的视觉任务中具有高度的通用性和强大的功能。
Swin Transformer 的核心创新在于其分层结构和基于移位窗口的自我注意力机制。与标准视觉转换器(ViT)在整个图像中应用自我注意力不同,Swin Transformer将图像划分为不重叠的小窗口,在这些窗口内计算自我注意力,从而减少了计算复杂性。此外,Swin Transformer引入了窗口移位技术,使得在连续的Transformer块之间,图像区域能在不同层之间相互影响,从而更好地整合局部与全局上下文信息。
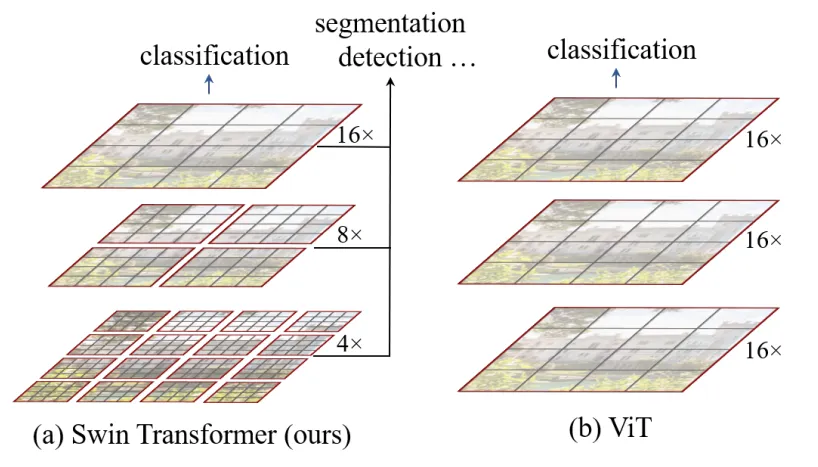
图1 Swin Transformer多层级表示和ViT对比
如图1所示,Swin Transformer从小的patch开始,通过在深层次逐步合并相邻patch的方式构建了一个层级化的表示。通过这些层级特征图,Swin Transformer可以像FPN和U-Net那样进行多尺度密集预测。通过对图像分区(用红色标出)进行非重叠窗口的局部自注意力计算实现了线性的计算复杂度。每个窗口的patch的个数是固定的,因此计算复杂度和图像的大小成线性关系。
相比于之前只能产生单一分辨率特征图和平方复杂度的Transformer模型,Swin Transformer适合作为各种视觉任务的通用主干网络(backbone)。
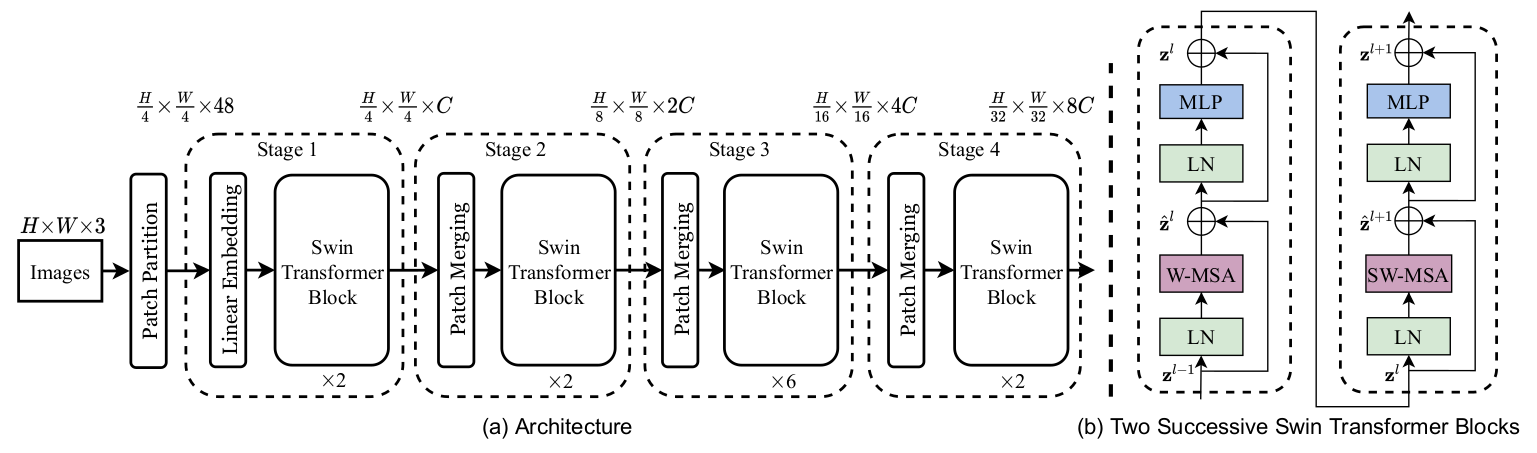
图2:Swin Transformer网络架构
该架构详细展示了 Swin-Transformer 模型如何通过逐层处理和 Patch Merging 实现高效的图像特征提取。每个阶段的 Swin Transformer Block 通过不同的自注意力机制(如 W-MSA 和 SW-MSA)逐步提升图像理解的深度。通过多层次的处理和特征合并,该模型在处理大规模图像数据时表现出色,特别适合于图像分类和目标检测等任务。
Swin Transformer解决了以往基于 CNN 和 Transformer的模型的几个局限性。首先,它的分层设计可以高效处理多种分辨率的图像,有助于完成需要同时了解精细细节和整体结构的任务,如物体检测和语义分割。其次,通过将自我关注机制定位到窗口并采用移位窗口,Swin Transformer 大幅降低了计算要求,使其更易于扩展到大型图像和数据集。最后,它的架构通过将局部特征无缝集成到更广泛的上下文中,实现了更好的特征学习,从而提高了各种视觉任务的性能。
系统设计
本系统基于深度学习实现中国交通警察手势识别与指令优先级判定,涵盖直行、变道、左转弯、左转弯待转、靠边停车、右转弯、减速慢行和停止等指令。通过"数据输入---模型推理---结果展示"流程,实现指令优先级精准识别,提升交通管理效率。
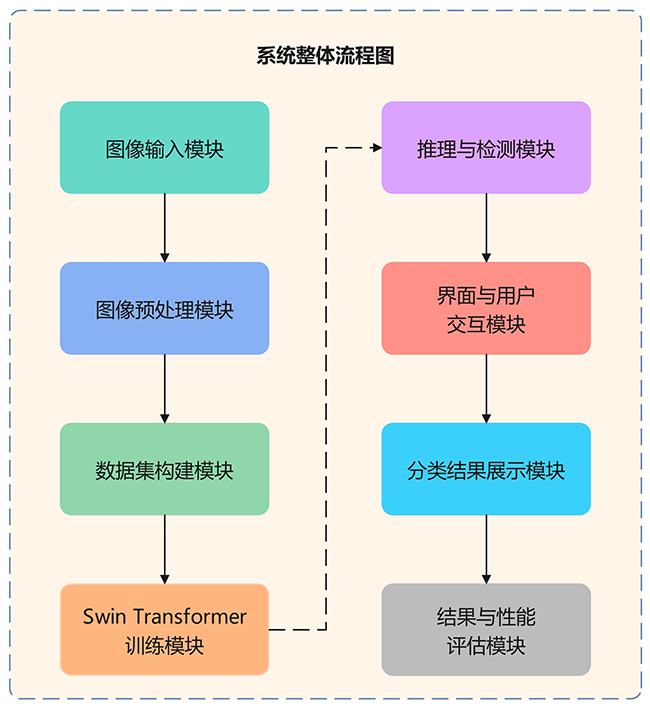
图3 系统整体流程图
数据集构建
1.数据来源
本数据集包含中国交警手势图像,涵盖多个交警指令,包括直行、变道、左转弯、左转弯待转、靠边停车、右转弯、减速慢行和停止。数据源来自公开的交通管理系统图像,适用于交通手势识别与智能交通系统研究。

表1 数据集基本信息

图4 数据集图片
2.分类格式
该格式用于图像分类任务,广泛应用于包括Swin Transformer在内的深度学习模型训练。数据集中的图像将根据类别进行分类,以确保数据与模型的高效匹配,从而提升分类精度和推理效率。
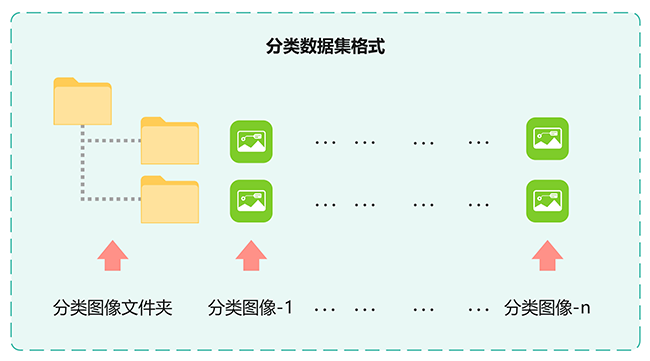
图5 分类数据集格式
3.数据集划分
本研究使用的分类图像数据集仅包含按类别整理的图像文件,该数据集适用于图像分类任务,用于模型的训练与验证。

图5 数据集划分:测试集和训练集
模型训练
Swin Transformer是一种常用于图像分类的深度学习模型。其训练过程包括超参数设置、模型训练及结果可视化。通过分层结构与移位窗口自注意力机制,模型能高效提取局部与全局特征,提升分类精度与效率。在大规模数据集上,Swin Transformer表现出优异的分类性能与计算效率。
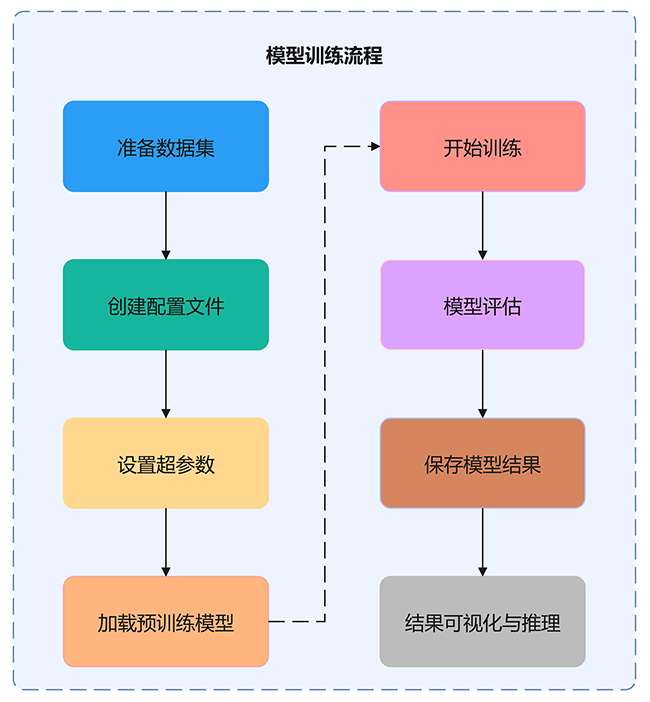
图6 模型训练流程图
1.配置文件与超参数设置
以下是关于Swin Transformer模型训练过程中的配置文件和超参数设置,并通过配置文件以及相关参数进行训练设置。

表2 Swin Transformer模型训练超参数设置
2.模型性能评估
在 Swin Transformer模型的训练过程中,模型性能评估是衡量其在图像分类任务中表现的重要环节,能够全面反映模型在分类精度和泛化能力方面的表现。科学而准确的评估不仅有助于揭示模型的优势与不足,还能为后续的改进与优化提供可靠依据。
(1)训练与验证准确率和损失曲线
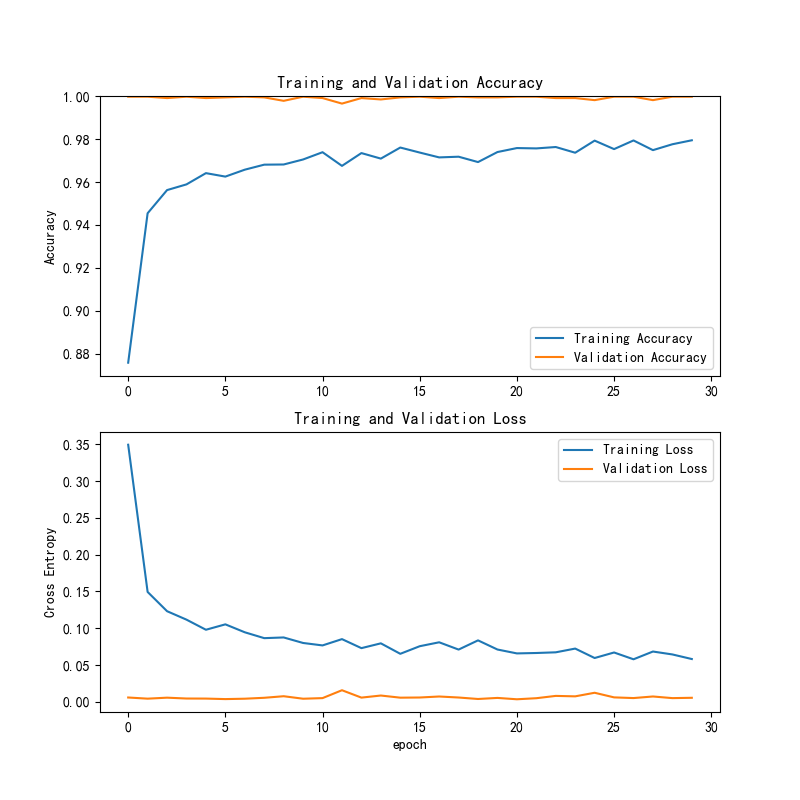
图7 Swin Transformer训练与验证准确率和损失曲线
训练精度和验证精度逐渐稳定且保持较高水平,验证精度紧随其后,表明模型具备良好的泛化能力,未发生过拟合。训练损失快速下降并趋于平稳,验证损失维持在较低水平,显示出模型训练有效,且无明显误差或过拟合。
(2)混淆矩阵热力图
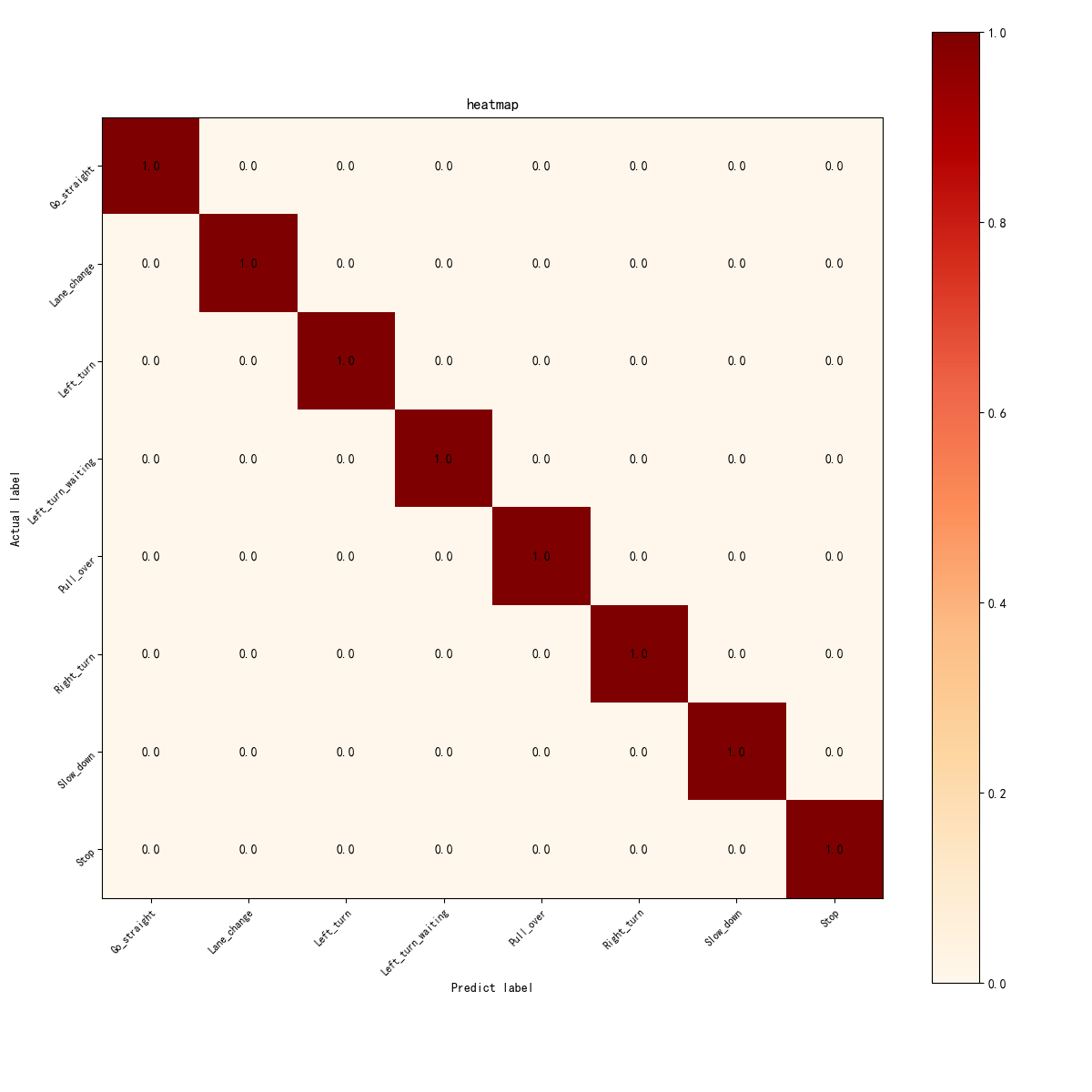
图8 Swin Transformer混淆矩阵热力图
混淆矩阵显示所有类别的对角线值为1.00,表明每个手势指令(如直行、变道、左转弯等)都被准确分类。非对角线值为0,说明没有误分类,模型能够完美区分各手势指令。
(3)各类的分类性能评估:准确率、精确率、召回率与F1分数图
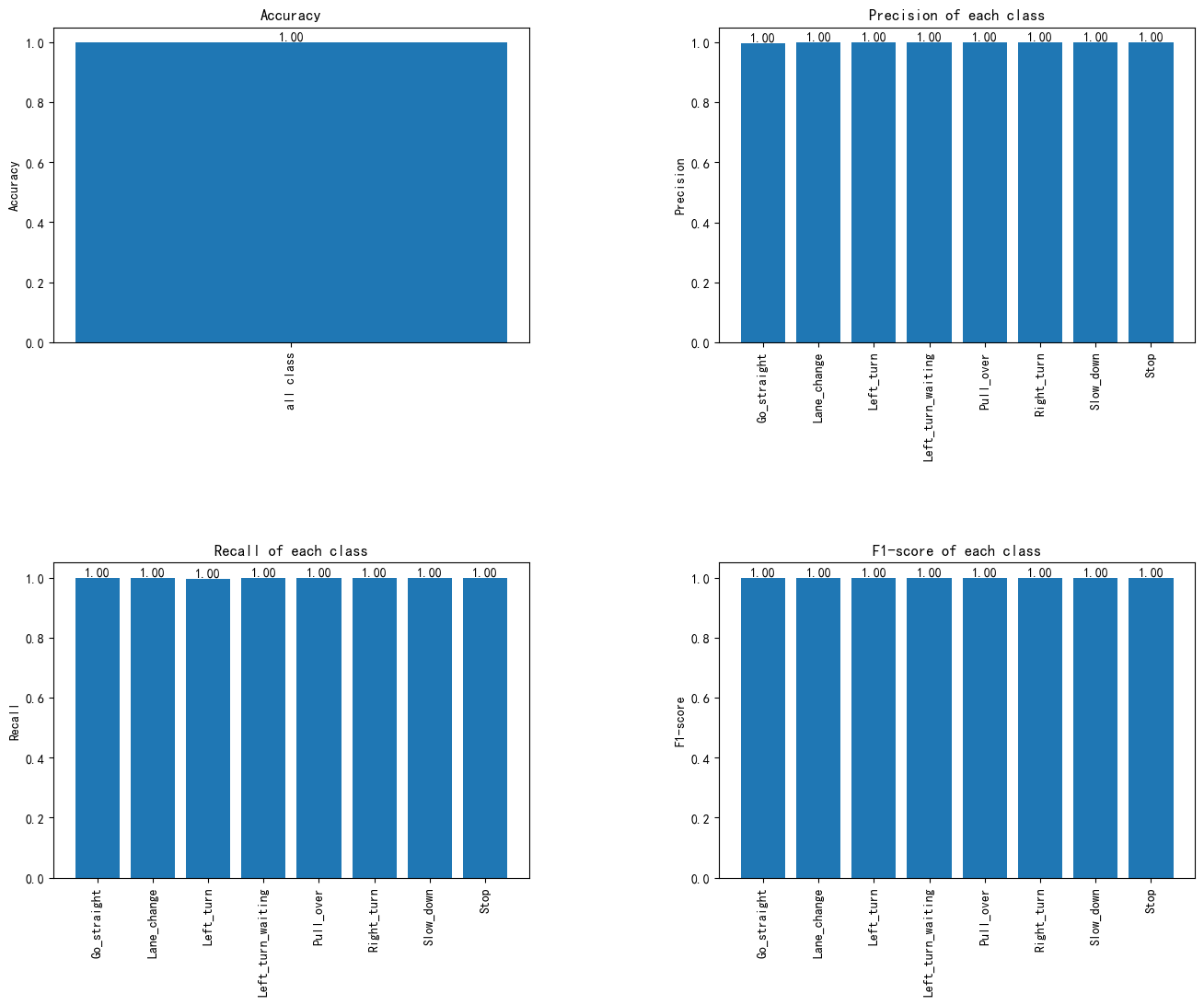
图9 各类的分类性能评估:准确率、精确率、召回率与F1分数图
该系统在所有类别上实现了完美的分类效果,准确率、精确度、召回率和F1分数均为1.00,表明模型在每个类别的识别中没有误分类,能够准确识别所有样本,且在精确度与召回率之间保持了良好的平衡。
(4)训练日志(Training Log)
训练日志记录了Swin Transformer模型在训练过程中的详细信息,包括训练轮次、每轮的损失值、验证准确率以及训练时间等,这些信息帮助评估模型的训练效果和性能。
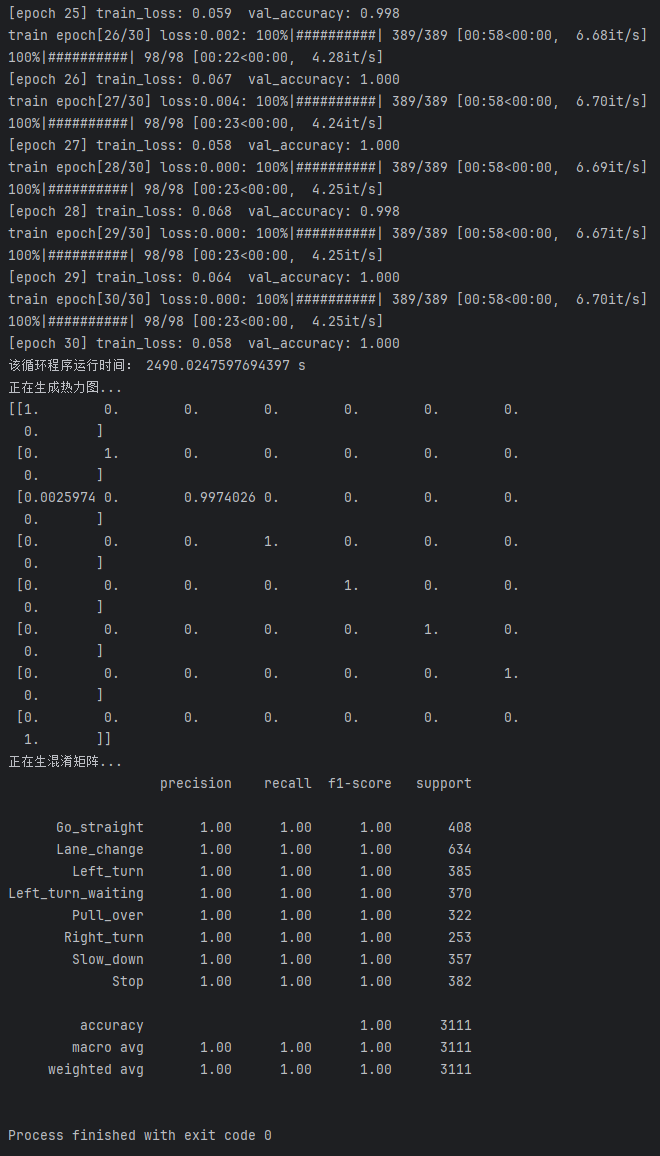
图10 Swin Transformer训练日志
训练轮次30轮,耗时约24.90分钟,训练损失从0.350降至0.058,验证准确率从1.000提升至1.000。
训练结果显示,模型在30个训练周期后成功实现了完美的分类效果,训练损失显著下降,表明模型具备强大的分类能力和出色的泛化性能。
该系统硬件配置如下,如果您的电脑配置低于下述规格,模型训练时间及结果可能会与本系统的训练日志存在差异,请注意。

表3 电脑硬件配置
功能展示
本系统基于Swin Transformer模型,实现中国交通警察手势,集成特征提取、分类推理与结果可视化,为中国交通警察手势识别辅助提供支持。
- 系统主界面展示

图11 系统主界面
- 图片检测功能
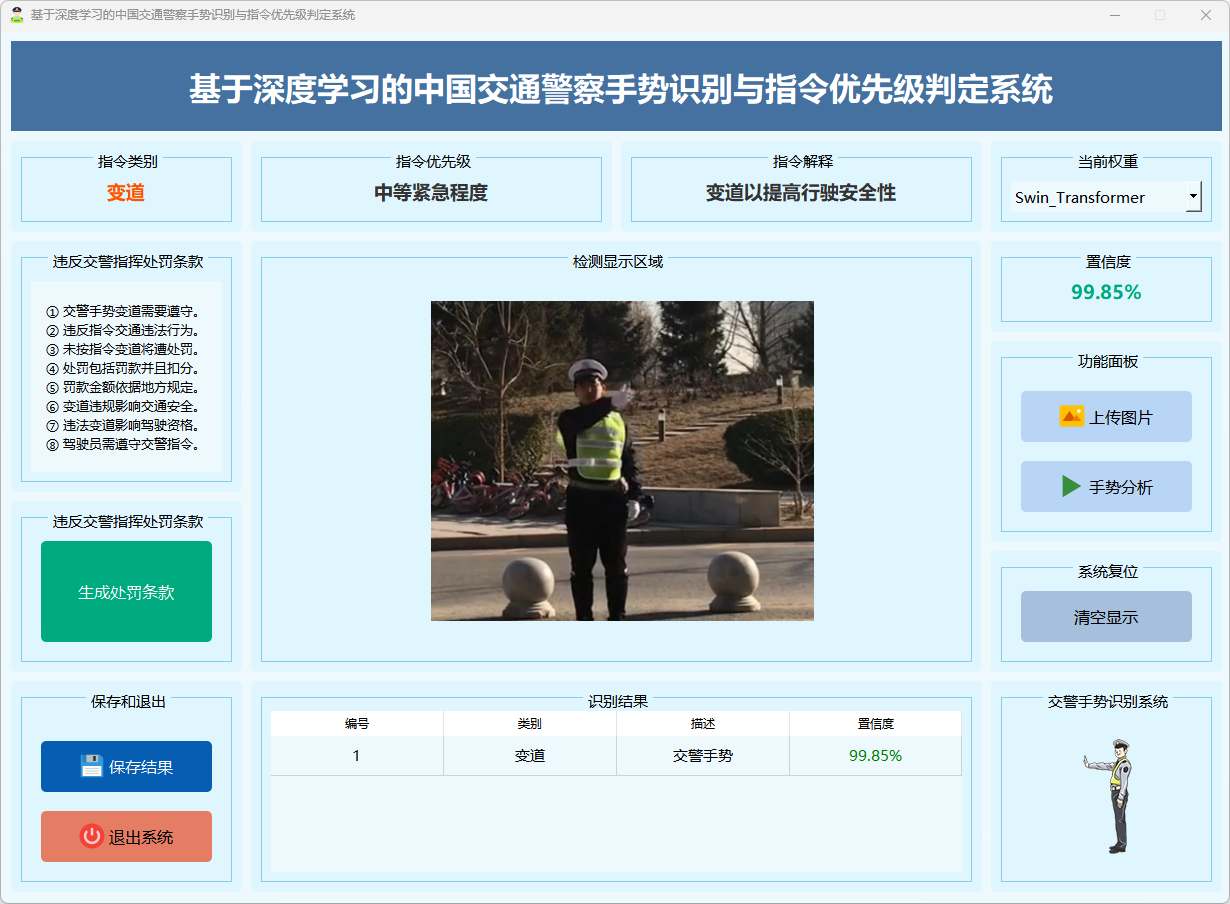
图12 变道
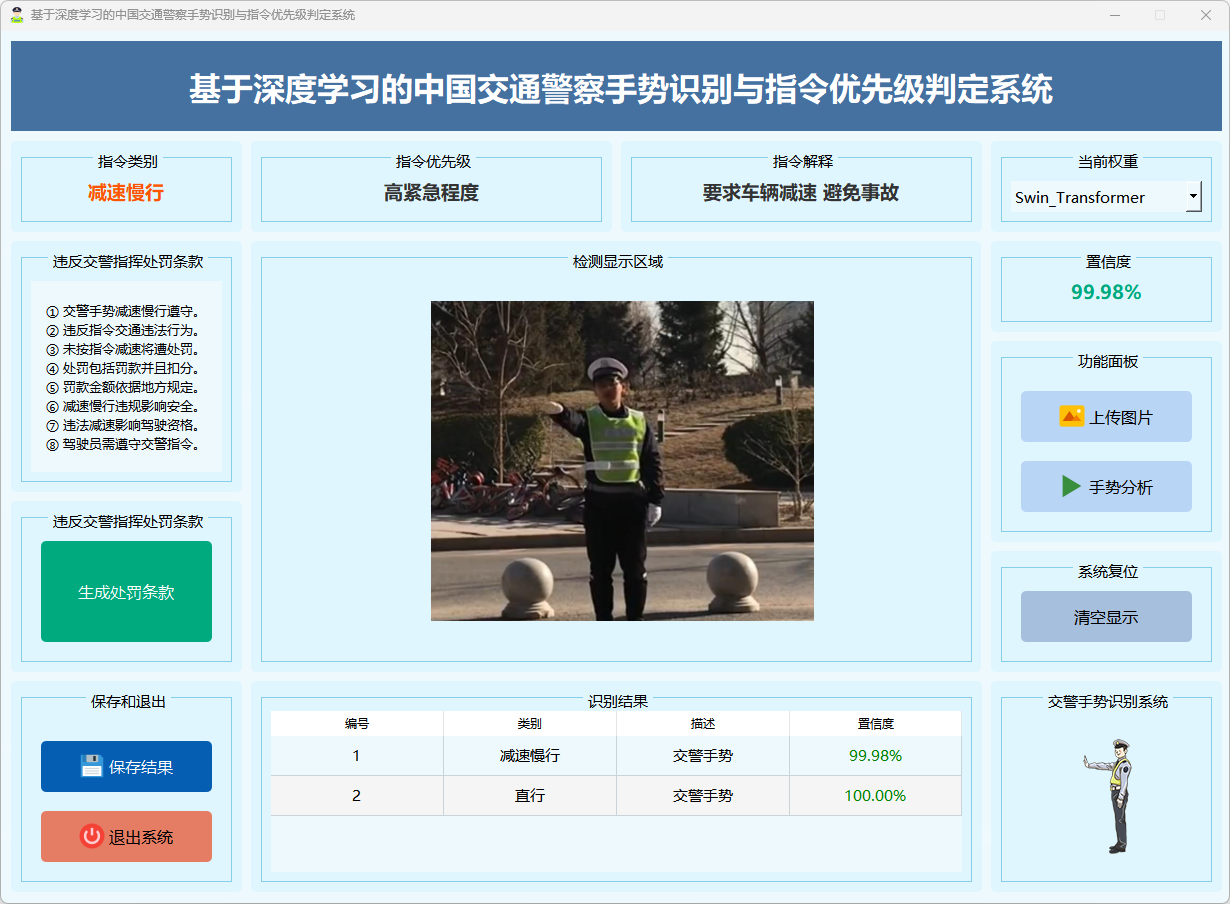
图13 减速慢行
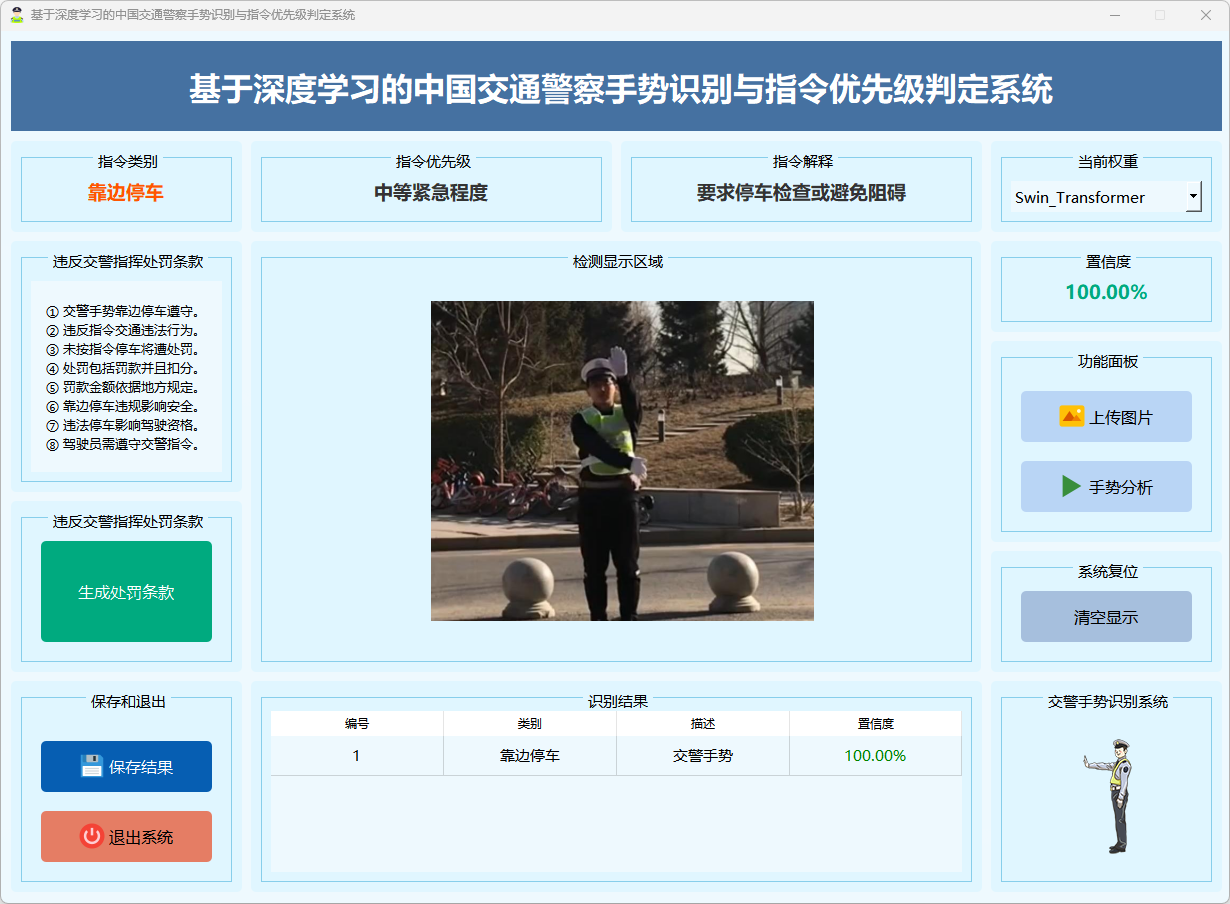
图14 靠边停车
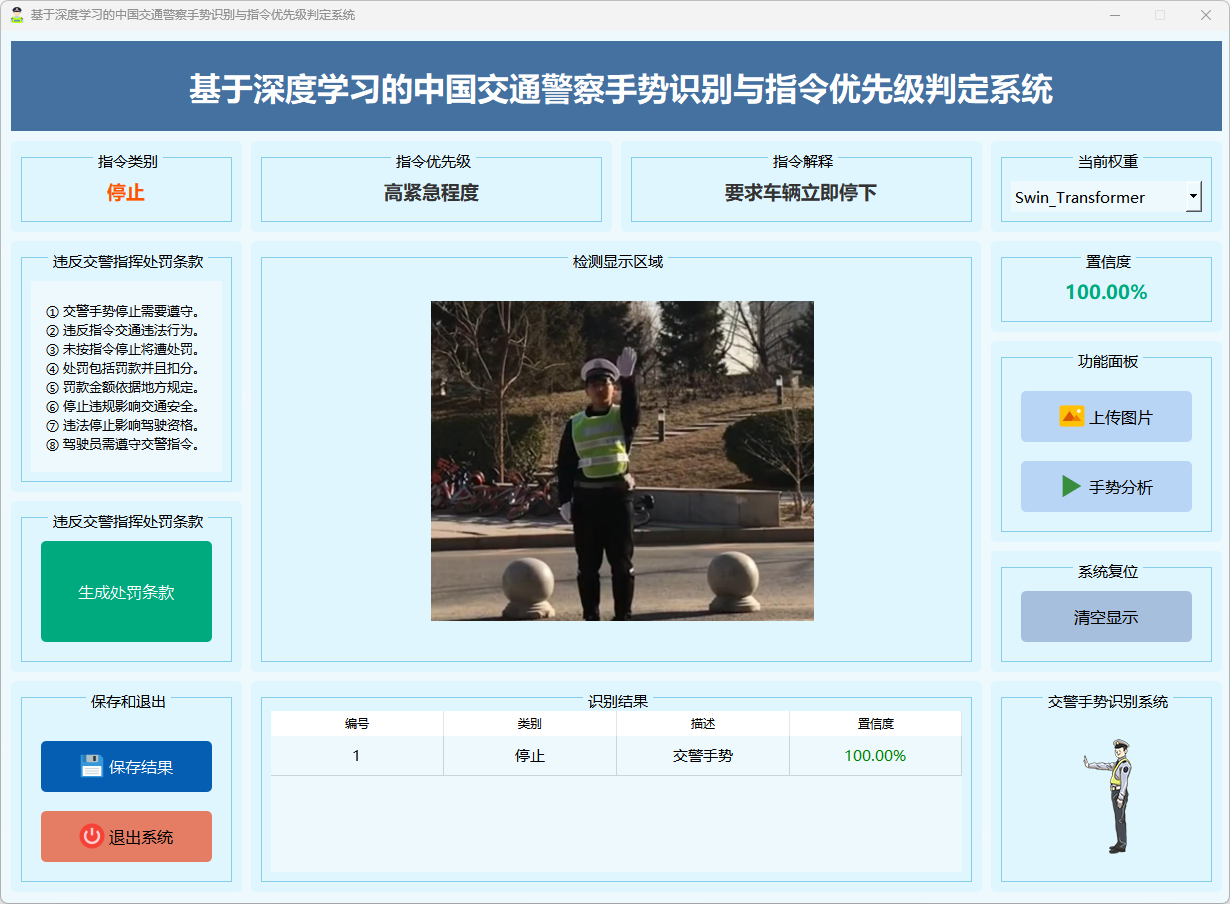
图15 停止
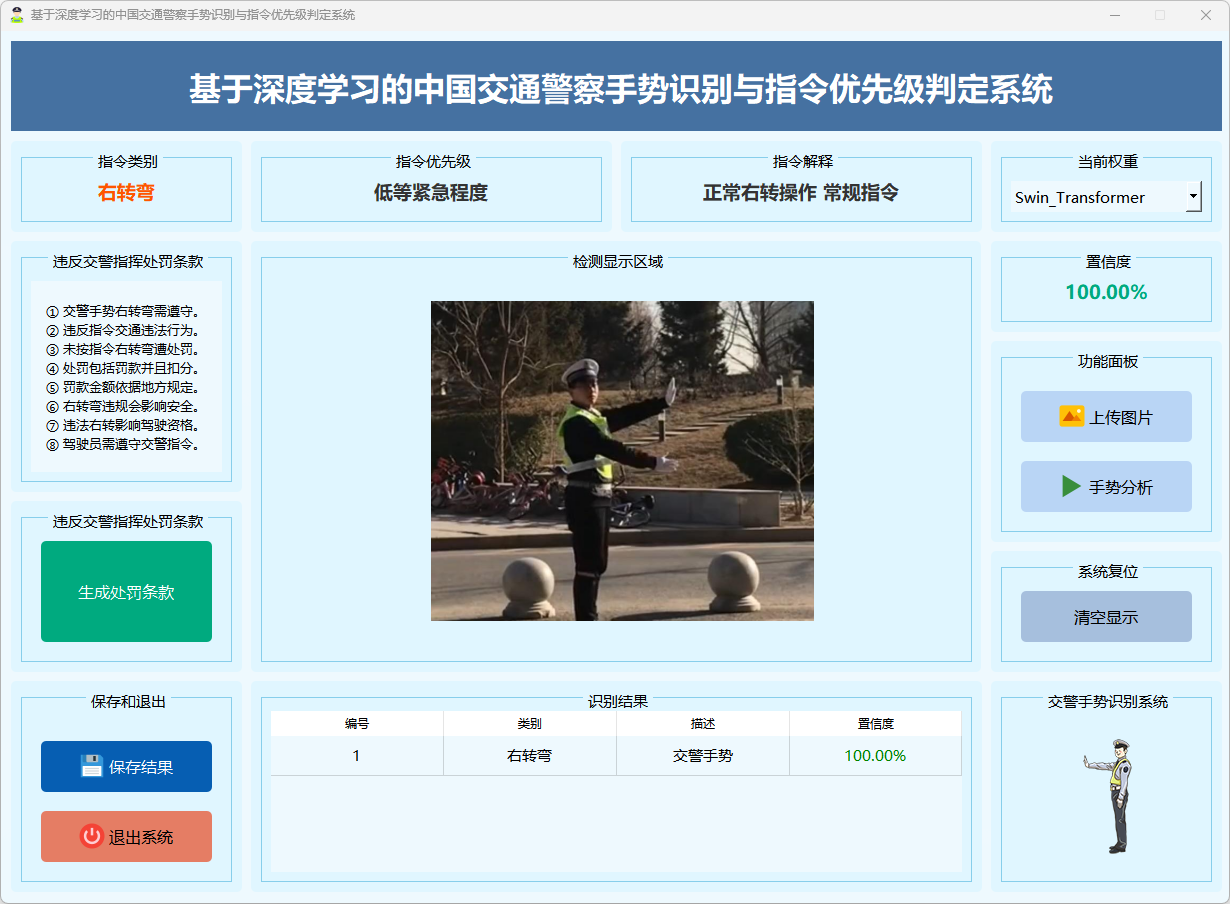
图16 右转弯
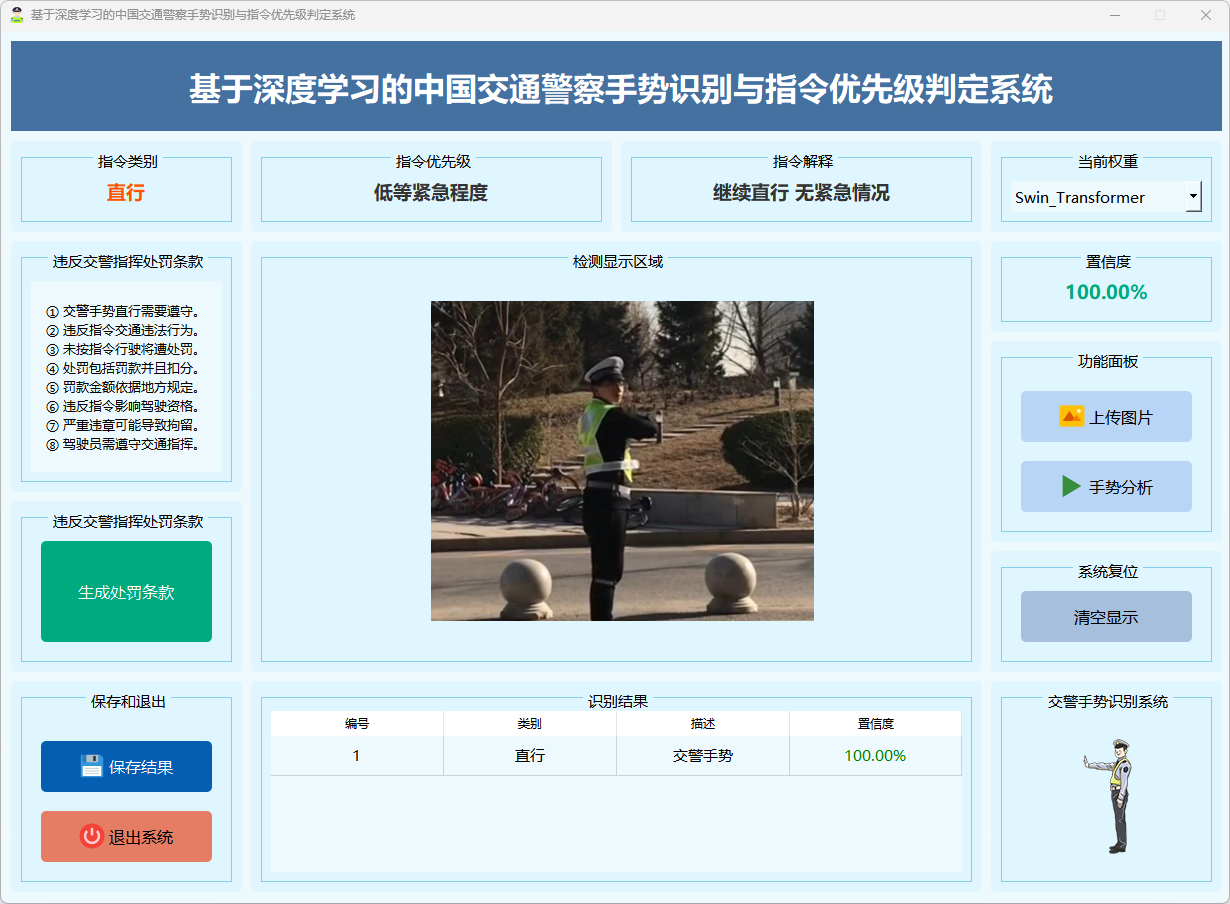
图17 直行
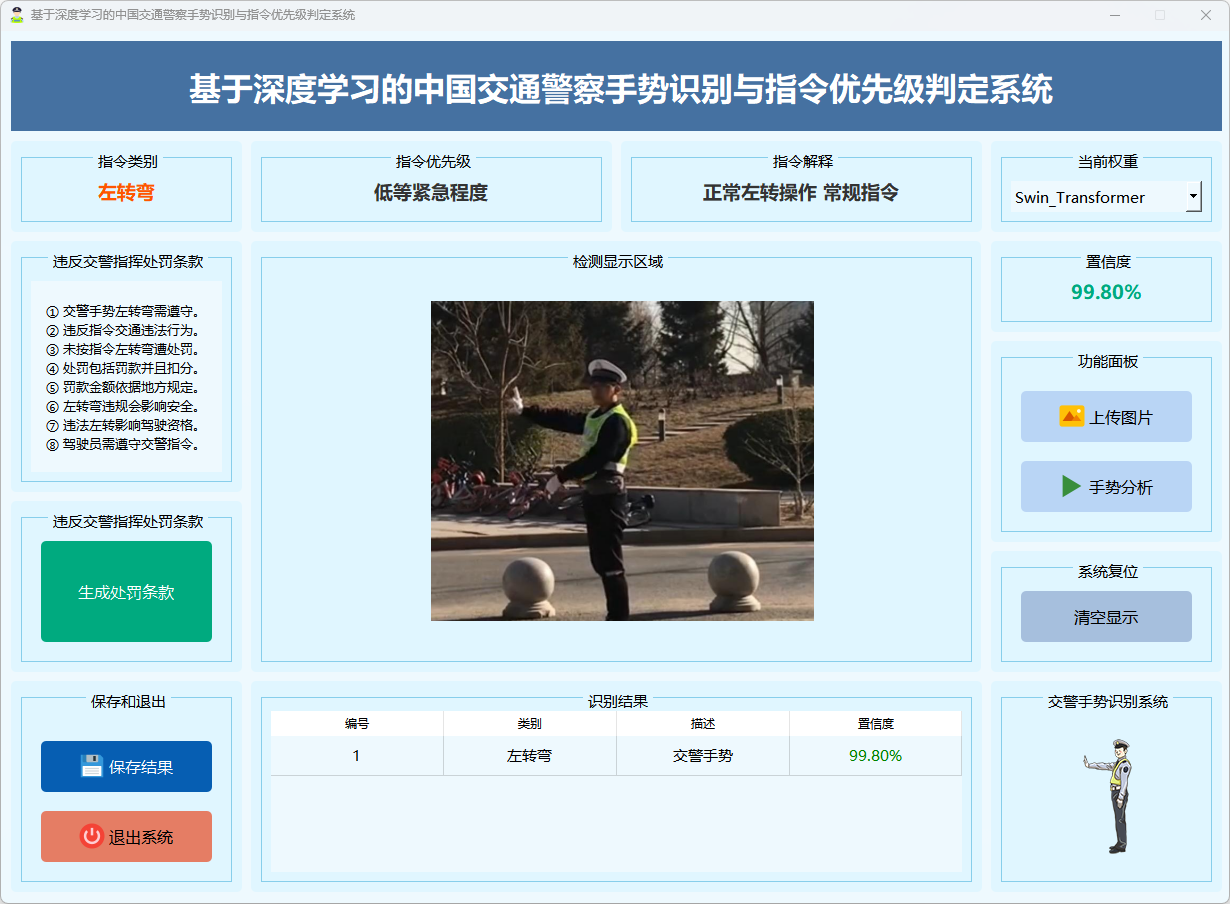
图18 左转弯
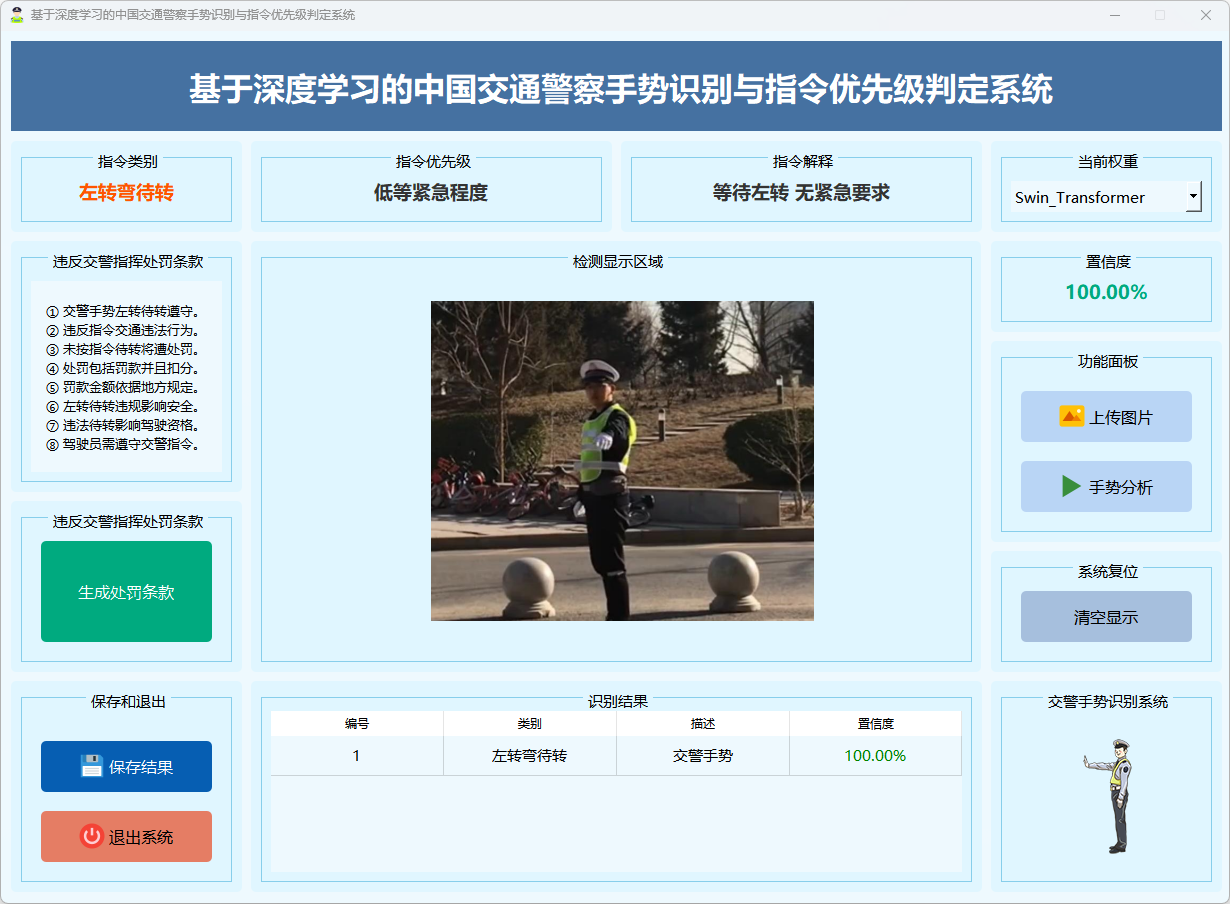
图19 左转弯待转
- 保存结果
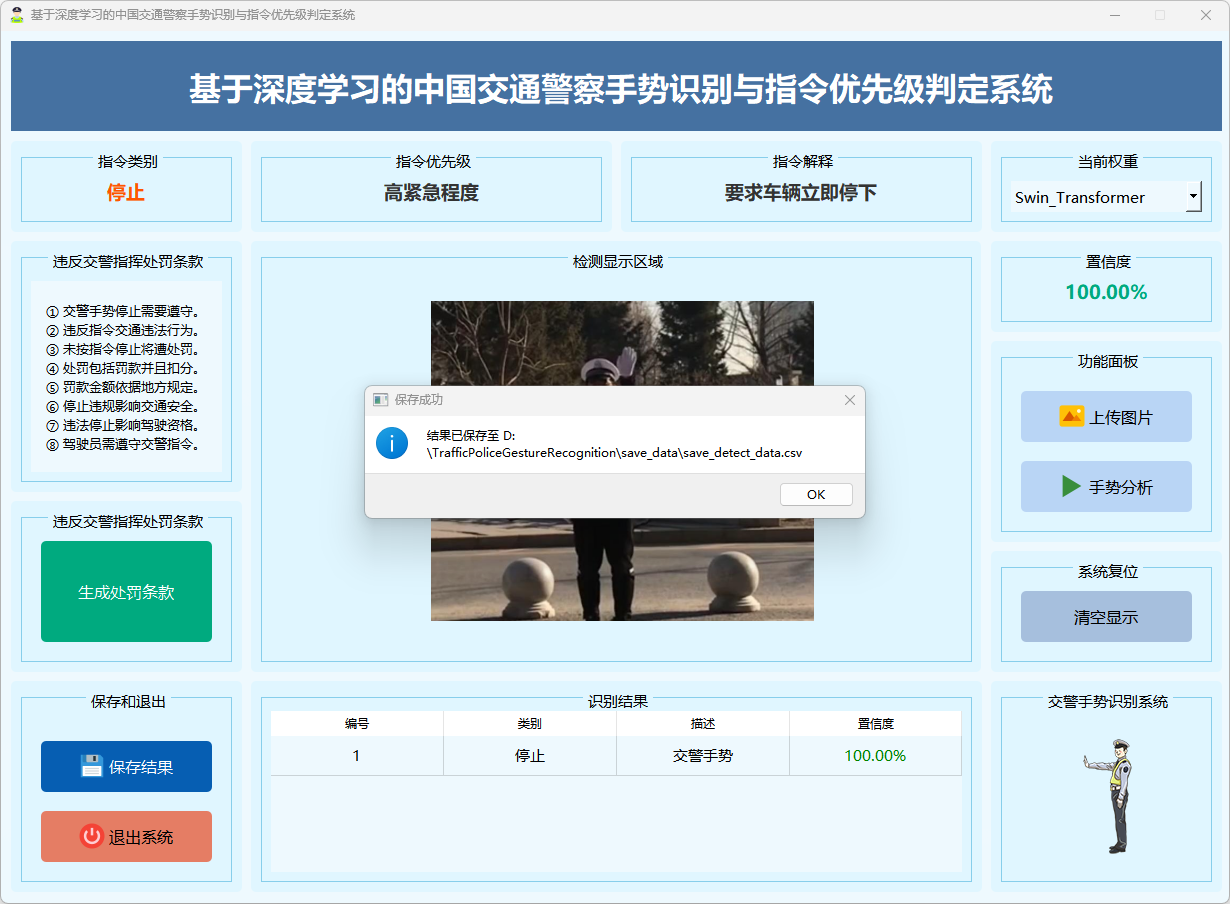
图17 结果保存
- 生成处罚条款报告
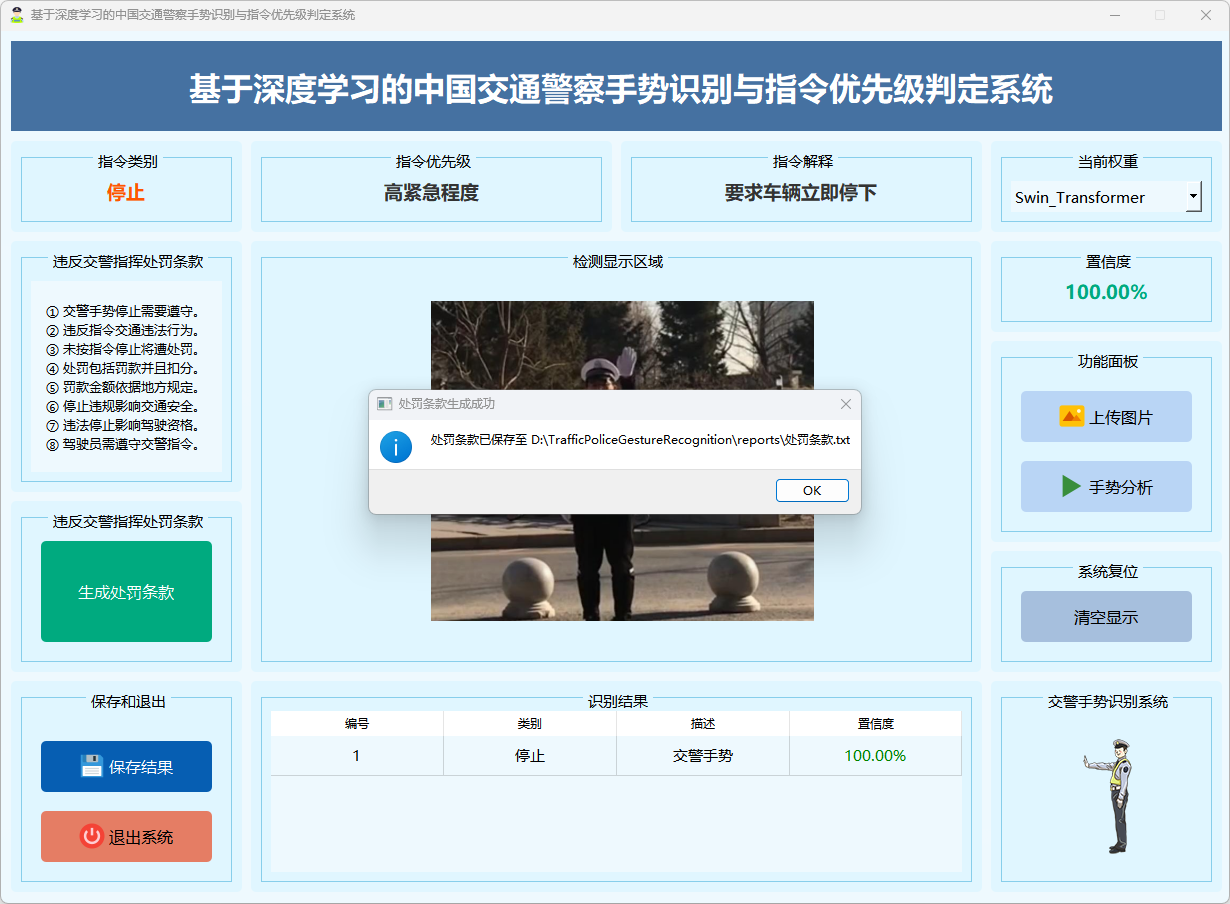
图18 成功处罚条款
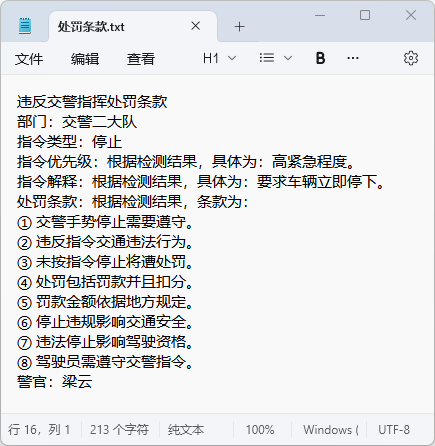
图19 处罚条款
界面设计
本系统的图形用户界面采用PyQt5框架开发,致力于打造直观、高效且流畅的交互体验。通过精心设计的界面布局和模块化架构,系统功能得以清晰呈现,并确保各项操作的高效执行,全面提升用户使用体验。
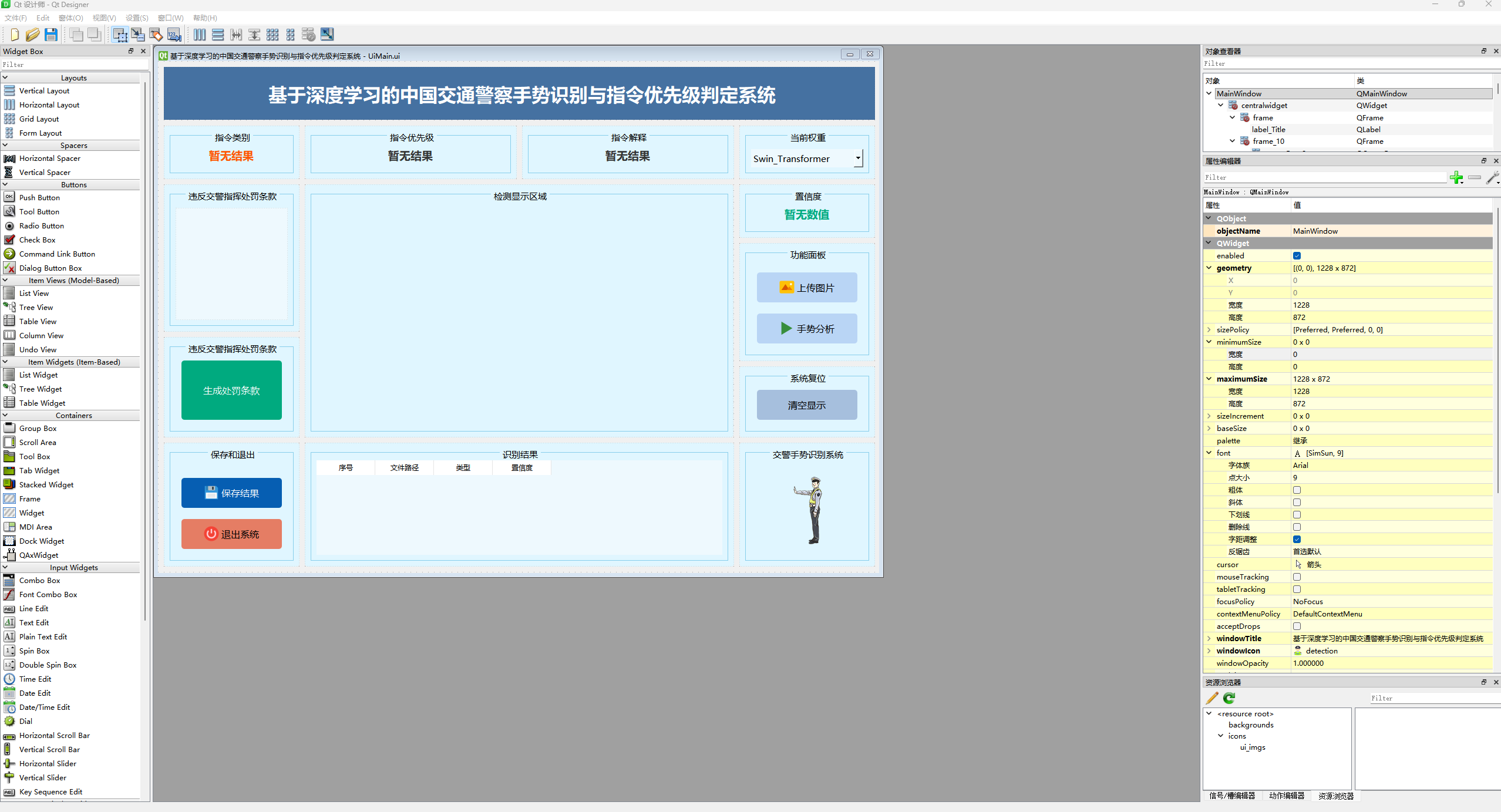
图17 PyQt5主控面板界面
该界面展示了基于PyQt5框架精心设计的系统,界面布局简洁、直观且高度集成。通过巧妙的模块化设计,系统涵盖了多项功能模块,确保用户能够高效、流畅地进行操作与交互,充分体现了系统在医学领域中的智能化与人性化设计。