StarRocks 是一款 高性能、实时分析型数据库(OLAP),由字节跳动开源(2020 年开源,2023 年进入 Apache 孵化器),核心定位是 "实时数仓 + 湖仓一体",专为 PB 级数据的快速查询、多维分析、实时报表等场景设计,广泛应用于互联网、金融、零售、政务等行业。
一、StarRocks 核心特性(为什么受欢迎?)
-
极致查询性能
- 基于 MPP(大规模并行处理)架构,支持多节点分布式计算,单查询可利用集群所有资源并行执行。
- 自研 CBO(代价优化器) + 向量化执行引擎,避免不必要的数据扫描,复杂查询(如多表关联、聚合分析)速度比传统 OLAP 快 5-10 倍。
- 支持 物化视图 和 智能索引(前缀索引、 bitmap 索引、布隆过滤索引),进一步加速高频查询。
-
实时数据摄入与分析
- 支持 秒级数据导入:适配 Kafka、Flink、CDC(Debezium)等实时数据源,数据写入后毫秒级可见,满足实时报表、监控告警等场景。
- 兼容多种导入方式:Batch 导入(HDFS、S3、本地文件)、Stream 导入(Kafka)、CDC 导入(MySQL/PostgreSQL 增量同步)。
-
湖仓一体架构
- 无需数据搬迁,直接查询 HDFS、S3、Iceberg、Hudi、Delta Lake 等数据湖中的数据,实现 "热数据(StarRocks 本地)+ 冷数据(数据湖)" 统一分析。
- 支持联邦查询:跨 StarRocks、MySQL、Elasticsearch、Hive 等多数据源联合查询,打破数据孤岛。
-
高兼容性与易用性
- 完全兼容 MySQL 协议:支持用 MySQL 客户端(如 Navicat、mysql-cli)直接连接,SQL 语法高度兼容 MySQL,降低迁移成本。
- 支持丰富的数据类型:包括 JSON、ARRAY、MAP、BITMAP、HLL(基数统计),满足多维分析场景(如用户画像、留存分析)。
-
高可用与弹性扩展
- 数据多副本存储(默认 3 副本),节点故障自动切换,无数据丢失。
- 支持水平扩展:新增 BE(计算存储节点)即可提升集群算力和存储容量,扩展过程不影响业务。
二、StarRocks 适用场景
- 实时数仓:实时销售报表、用户行为分析、运营监控大屏(如电商实时 GMV 统计、直播数据看板)。
- 多维分析(OLAP):复杂指标计算(如留存率、转化率)、钻取分析(按时间 / 地区 / 产品维度下钻)。
- 数据湖分析:直接查询数据湖中的冷数据,避免数据重复存储(如分析 HDFS 中的历史订单数据)。
- 报表与 BI:对接 Tableau、Power BI、FineBI 等 BI 工具,支持高并发报表查询(如企业内部日报 / 周报生成)。
- 用户画像与精准营销:基于 Bitmap/HLL 数据类型,快速计算用户交集、并集、基数(如 "同时购买 A 和 B 商品的用户数")。
三、国内主流使用厂商(标杆案例)
作为字节跳动开源的 "本土 OLAP 明星",国内众多大厂和中小企业已落地使用:
- 互联网:字节跳动(内部核心数仓引擎)、腾讯、阿里、美团、京东、快手、小红书。
- 金融:工商银行、建设银行、平安银行、华泰证券(实时风控、客户分析)。
- 零售:沃尔玛、永辉超市(实时销售分析、供应链监控)。
- 政务:多地政务云数据中台(如城市运行监控、民生数据统计)。
四、核心技术架构
StarRocks 集群由 3 类角色组成,架构简洁清晰:
| 角色 | 功能职责 | 核心作用 |
|---|---|---|
| FE(Frontend) | 接收查询请求、SQL 解析优化、元数据管理、集群调度 | 集群 "大脑",负责协调和调度 |
| BE(Backend) | 数据存储、执行查询计划(扫描、聚合、关联) | 集群 "算力 + 存储节点",实际干活 |
| CN(Compute Node) | 仅负责计算,不存储数据(可选角色) | 弹性扩展算力,适配临时高并发 |
- 数据存储:采用列式存储,按列压缩(支持 LZ4、ZSTD 等算法),大幅降低存储成本,提升查询效率。
- 执行流程:SQL 经 FE 解析优化后,生成分布式执行计划,下发给多个 BE 并行执行,最终汇总结果返回给用户。
五、与同类产品对比(优势在哪?)
| 产品 | 核心差异 | 适合场景 |
|---|---|---|
| StarRocks | 实时性强、湖仓一体、MySQL 兼容、易用性高 | 实时分析、湖仓统一查询 |
| ClickHouse | 单表查询性能极强,写入性能弱于 StarRocks | 单表海量数据快速查询(如日志分析) |
| Apache Doris | 架构类似 StarRocks,生态成熟度... |
(1)横向对比总表(核心维度浓缩版)
| 产品类型 | 产品名称 | 核心架构 | 核心优势 | 核心短板 | 极致场景 | 部署成本 | 国内适配度 |
|---|---|---|---|---|---|---|---|
| 开源实时 OLAP | StarRocks | MPP + 湖仓一体 + 计算存储分离(CN 节点) | 实时性强(秒级导入 + 毫秒查询)、复杂多表 Join 优、MySQL 兼容、湖仓协同成熟 | 单表查询性能略逊 ClickHouse | 实时数仓、BI 高并发报表、湖仓统一分析 | 低(开源免费) | 极佳(大厂落地 + 中文社区) |
| 开源实时 OLAP | ClickHouse | 列式存储 + 单节点并行计算 | 单表查询性能天花板(日志 / 监控数据极速查询)、存储压缩高效 | 多表 Join 弱、实时导入稳定性一般、并发低 | 日志分析、单表海量数据聚合(如监控指标) | 低(开源免费) | 中(社区偏外文) |
| 开源离线 OLAP | Apache Doris | MPP 架构(与 StarRocks 同源) | 离线场景适配好、资源占用可控、生态成熟 | 实时性 / 湖仓协同弱于 StarRocks | 传统离线数仓、企业内部 T+1 报表 | 低(开源免费) | 中(社区活跃度略逊) |
| 传统离线数仓 | Hive+Impala/Spark SQL | 批处理架构 + Hadoop 生态 | 生态极成熟、海量数据批量处理、存储成本低 | 实时性差(T+1 延迟)、并发能力弱 | 离线 ETL、历史数据批量分析、老系统迁移 | 中(需 Hadoop 集群) | 极佳(运维人才多) |
| 云原生数仓 | Snowflake | 计算 / 存储 / 元数据分离 | Serverless 运维、弹性伸缩极致、多租户隔离 | 成本高(按使用计费)、国内延迟高 | 跨国企业全域数仓、无运维团队场景 | 高(商业付费) | 中(合规成本高) |
| 云原生数仓 | 阿里云 MaxCompute | 云原生批流一体 | 国内延迟低、阿里云生态无缝对接、合规适配好 | 开源生态兼容性弱、定制化能力有限 | 国内企业云原生数仓、批量 + 近实时分析 | 中高(商业付费) | 极佳(国内合规) |
(2)、核心维度横向 PK(选型关键)
1. 实时性 PK(谁能承接 "秒级响应" 需求)
| 产品 | 导入延迟 | 查询延迟 | 适用实时场景 |
|---|---|---|---|
| StarRocks | 秒级(Kafka/CDC) | 毫秒级 | 实时 GMV、直播看板、实时风控 |
| ClickHouse | 秒级(TOS 引擎) | 毫秒级(单表) | 实时日志分析、监控告警 |
| Apache Doris | 秒级 - 分钟级 | 毫秒 - 秒级 | 准实时报表、非核心实时场景 |
| Hive+Impala/Spark SQL | 小时 - T+1 级 | 分钟级 | 无实时需求,仅离线分析 |
| Snowflake | 分钟级 | 秒级 | 近实时分析、跨国协同场景 |
2. 查询能力 PK(谁能搞定 "复杂场景")
| 产品 | 多表 Join | 多维聚合 | 联邦查询 | 高并发支持 |
|---|---|---|---|---|
| StarRocks | 强(CBO 优化器) | 强 | 支持(跨湖 / 跨库) | 高(万级 QPS) |
| ClickHouse | 弱(无跨节点优化) | 强(单表) | 弱 | 低(千级 QPS) |
| Apache Doris | 中强 | 中强 | 支持 | 中(千级 QPS) |
| Hive+Impala/Spark SQL | 中(延迟高) | 中 | 支持(Hadoop 生态内) | 极低(百级 QPS) |
| Snowflake | 强 | 强 | 支持 | 极高(百万级 QPS) |
3. 存储成本 PK(谁能 "省钱存海量数据")
| 产品 | 存储架构 | 冷数据成本 | 总体成本优势 |
|---|---|---|---|
| StarRocks | 湖仓一体(热存本地 + 冷存湖) | 低(复用数据湖) | 比 ClickHouse 低 30%+,比云数仓低 50%+ |
| ClickHouse | 全量本地存储 | 中(列式压缩) | 单表场景成本可控,海量冷数据成本高 |
| Apache Doris | 本地存储 + 部分湖仓支持 | 中 | 离线场景成本与 StarRocks 相当 |
| Hive+Impala/Spark SQL | 数据湖存储(HDFS) | 低 | 冷数据成本最低,但查询效率差 |
| Snowflake | 云对象存储 | 中高(按存储计费) | 无硬件投入,但长期付费成本高 |
(3)、横向选型决策矩阵(快速匹配需求)
| 业务需求 | 首选产品 | 次选产品 | 不推荐产品 |
|---|---|---|---|
| 实时复杂分析(多表 Join+BI 报表) | StarRocks | Apache Doris | ClickHouse、Hive+Impala |
| 纯日志 / 监控数据单表查询 | ClickHouse | StarRocks | Hive+Impala、Snowflake |
| 传统离线数仓(T+1 报表 + 批量 ETL) | Hive+Impala/Spark SQL | Apache Doris | ClickHouse、Snowflake |
| 云原生 + 无运维团队 | Snowflake/MaxCompute | - | 开源产品(需自建运维) |
| 数据合规 + 私有化部署 | StarRocks/Apache Doris | ClickHouse | Snowflake(跨境合规风险) |
| 湖仓一体(热冷数据统一分析) | StarRocks | Apache Doris(需插件) | ClickHouse、Hive+Impala |
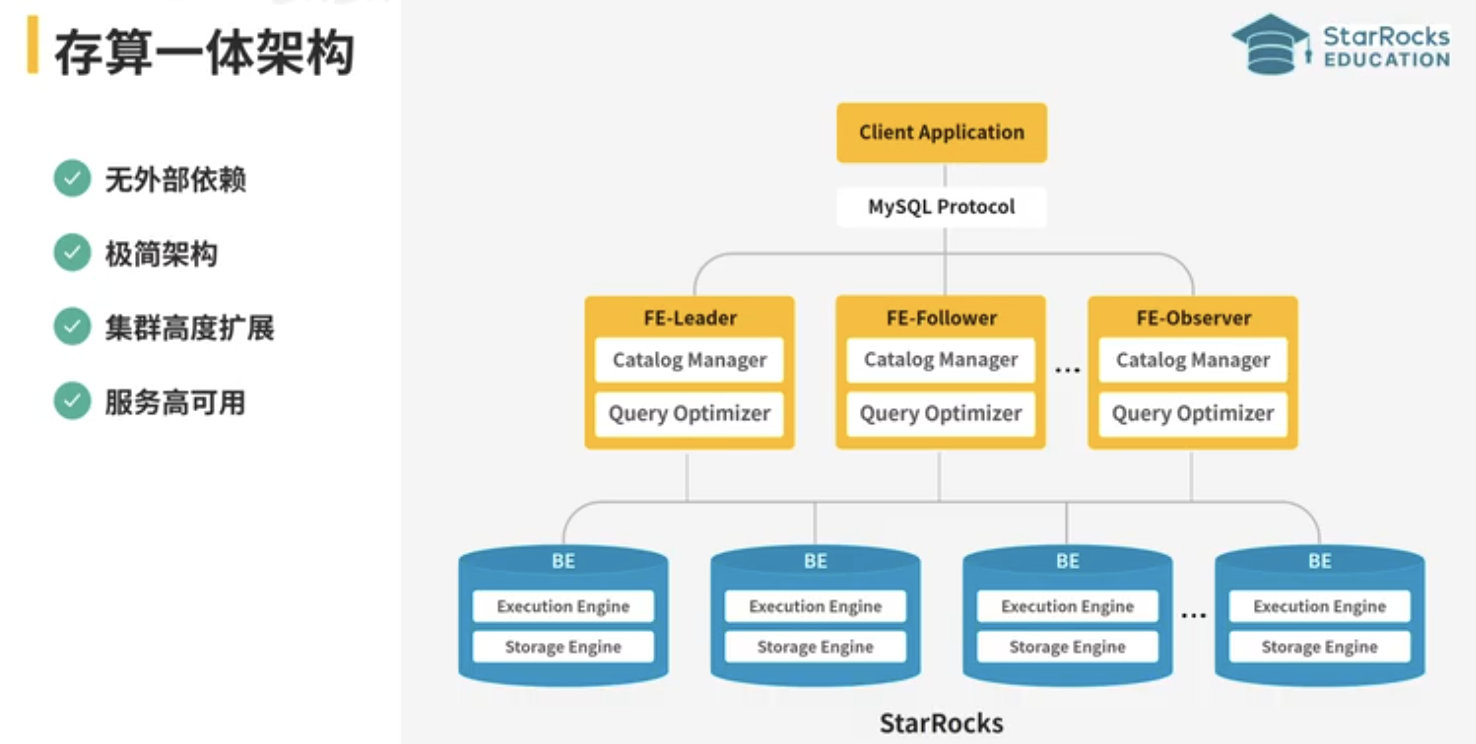
StarRocks 核心架构总览
StarRocks 架构分为 前端层、计算层、存储层 三层,完全兼容 MySQL 协议,支持标准 SQL,无需复杂适配即可接入业务系统。整体架构无状态化设计,计算与存储分离(可选本地存储或对象存储),支持水平扩展和高可用。
核心组件
StarRocks 的架构主要由两种组件构成:
- **前端节点(FE)**:负责元数据管理、客户端连接、查询规划和调度。FE 使用 BDB JE 存储元数据副本,并通过 Raft 协议实现高可用。
- 后端节点(BE 或 CN) :
-
**BE(Backend)**:在存算一体架构中,BE 同时负责数据存储和计算,支持多副本,确保数据可靠性和低延迟查询。
-
**CN(Compute Node)**:在存算分离架构中,CN 专用于计算,数据存储在对象存储或 HDFS 中,实现计算与存储的独立扩展。
[客户端层]:MySQL 客户端、BI 工具、应用程序(通过 JDBC/ODBC 连接)
↓
[前端层]:3 个 FE 节点(1 Leader + 2 Follower,元数据存储在 MySQL 集群)
↓
[计算层]:N 个 BE 节点(存储+计算,3 副本冗余) + M 个 CN 节点(纯计算,弹性扩容)
↓
[存储层]:BE 本地 SSD(热点数据) + 对象存储 OSS/S3(冷数据/归档数据)
↓
[数据源层]:Kafka(实时数据)、MySQL/PostgreSQL(CDC 同步)、HDFS(离线数据)
-
架构模式
- 存算一体架构
BE 节点本地存储数据,计算时无需跨节点传输,适合对查询性能要求极高的场景。该架构通过向量化引擎和 CBO 优化器实现亚秒级响应。
2.存算分离架构
计算与存储解耦,支持弹性扩缩容,适合云原生环境。存储层可兼容对象存储或 HDFS,降低运维成本
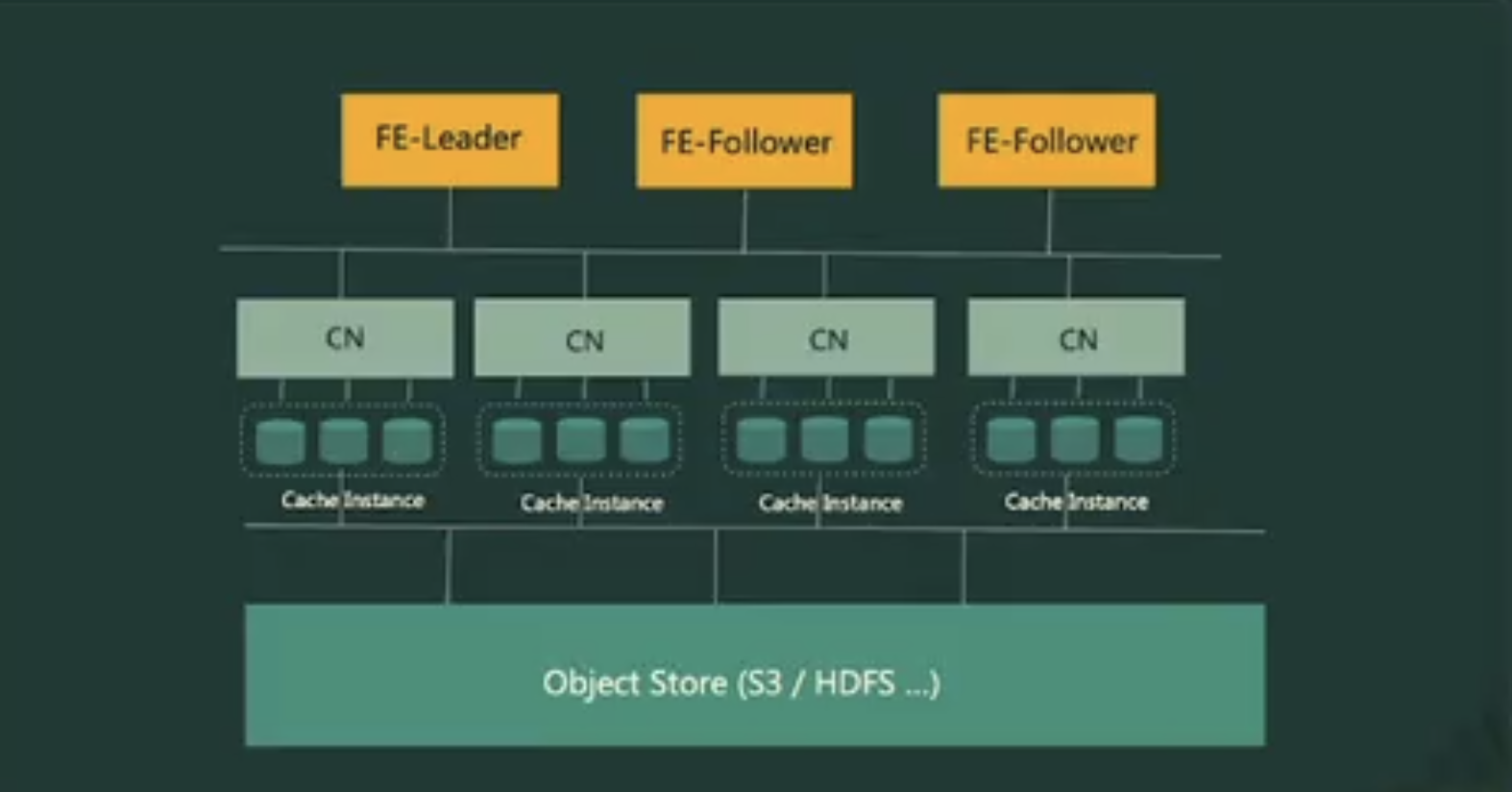
节点
在存算分离架构中,FE 提供的功能与存算一体架构中的相同。
BE 被 CN (计算节点) 取代,存储功能被转移到对象存储或 HDFS。CN 是无状态的计算节点,可以执行除存储数据外所有 BE 的功能。
存储
StarRocks 存算分离集群支持两种存储解决方案:对象存储 (例如,AWS S3、Google GCS、Azure Blob Storage 或 MinIO) 和 HDFS。
在存算分离集群中,数据文件格式与存算一体集群 (存储和计算耦合) 保持一致。数据存储为 Segment 文件,云原生表(专门用于存算分离集群的表)也可以利用存算一体架构中支持的各种索引技术。
缓存
StarRocks 存算分离集群将数据存储与计算分离,使两方都能够独立扩展,从而降低成本并提高系统弹性扩展能力。然而,这种架构会影响查询性能。
为减少架构对于性能的影响,StarRocks 建立了包含内存、本地磁盘和远端存储的多层数据访问系统,以便更好地满足各种业务需求。
对于针对热数据的查询,StarRocks 会先扫描缓存,然后扫描本地磁盘。而针对冷数据的查询,需要先将数据从对象存储中加载到本地缓存中,加速后续查询。通过将热数据缓存在计算单元内,StarRocks 实现了真正的高计算性能和高性价比存储。此外,还通过数据预取策略优化了对冷数据的访问,有效消除了查询的性能限制。
可以在建表时启用缓存。启用缓存后,数据将同时写入本地磁盘和后端对象存储。在查询过程中,CN 节点首先从本地磁盘读取数据。如果未找到数据,将从后端对象存储中检索,并将数据缓存到本地磁盘中。