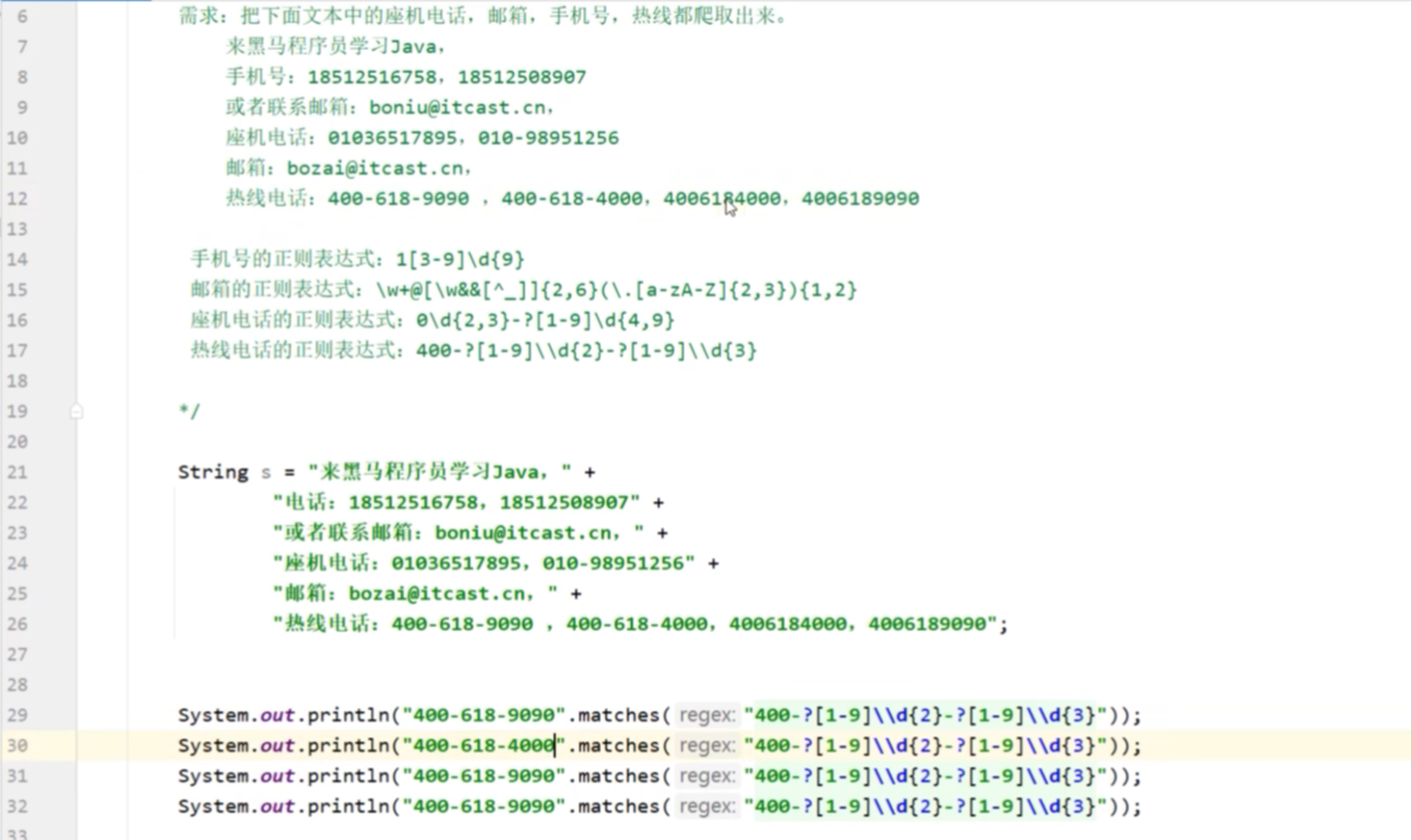
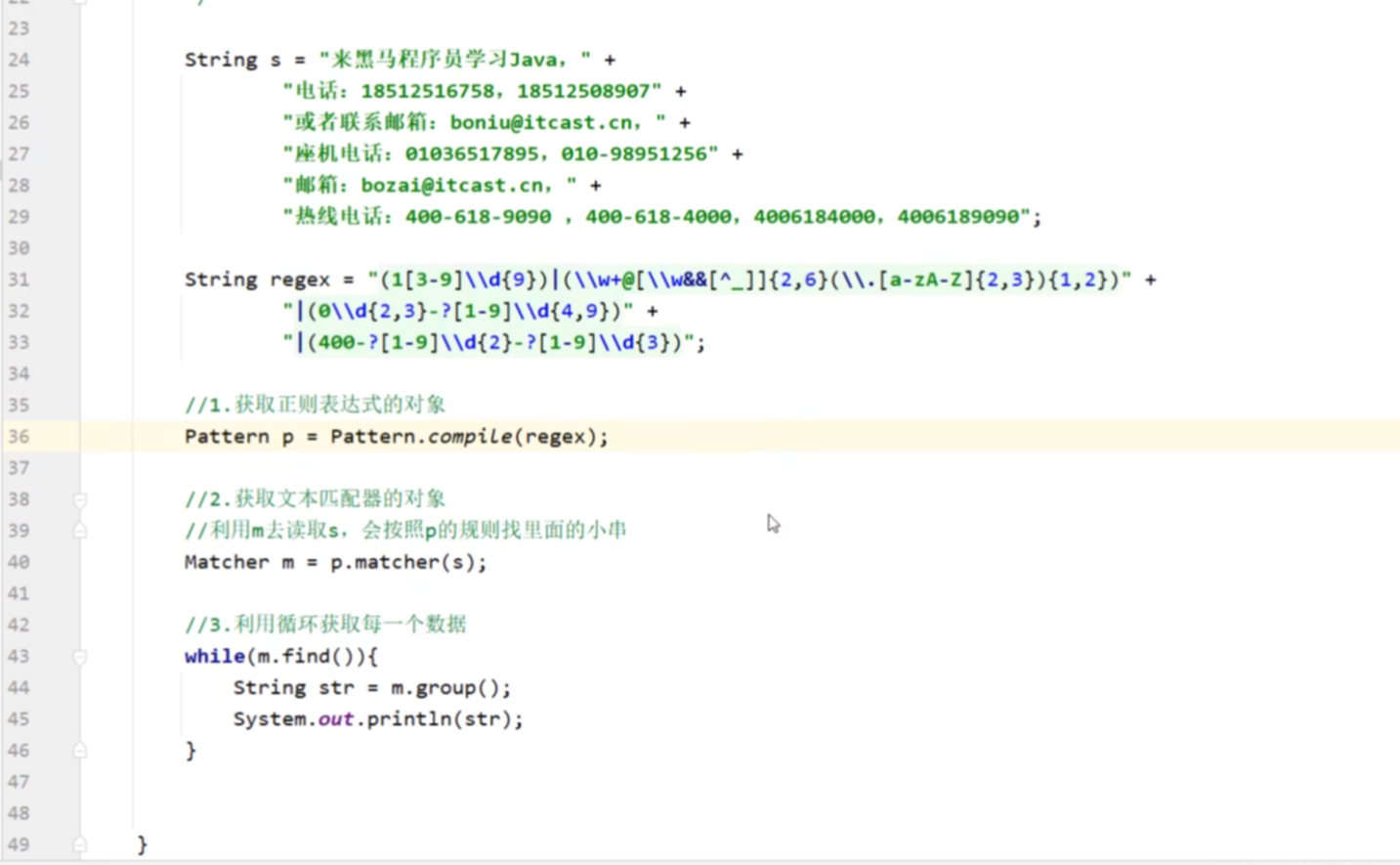
一、利用正则表达式进行爬虫

java
package com.lkbhua.MyApi.Regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Crawler {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历l很多版本,目前企业中用的很多的是Java8和Java11." +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信未来不久Java17也会逐渐登上历史舞台";
// 1、获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d(0,2)");
// 2、获取文本匹配器
Matcher m = p.matcher(str);
// 3、开始匹配
while (m.find()) {
String s1 = m.group();
System.out.println(s1);
}
}
// 底层逻辑
private static void method1(String str) {
// Patten:表示正则表达式
// Matcher:表示文本匹配器,对字符串进行匹配,从头开始读取符合规则的。
// 获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d(0,2)");
// 获取文本匹配器
// m:文本匹配器的对象
// str:要匹配的文本(大串)
// p:规则
Matcher m = p.matcher(str);
// 拿着文本匹配器从头开始读取,寻找是否有满足规则的子串
// 如果没有,方法返回false
// 如果有,方法返回true,在底层还会记录子串的起始索引和结束索引+1
// 0-4
boolean b = m.find();
// 根据find()方法记录的索引进行字符串的截取
// 字符串的截取:
// subString(int start, int end); 包头不包尾
// 会把截取的小串返回
String s1 = m.group();
System.out.println(s1);
}
}
二、有条件的爬取


java
package com.lkbhua.MyApi.Regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Crawler1 {
public static void main(String[] args) {
// 有条件的爬取
String str = "Java自从95年问世以来,经历l很多版本,目前企业中用的很多的是Java8和Java11." +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信未来不久Java17也会逐渐登上历史舞台";
// ?:理解为前面的数据Java
// =:表示在Java后面要跟随的数据
// 但是在获取的时,只获取前半部分
String regx = "Java(?=8|11|17)";
String regx1 = "Java(?:8|11|17)";
// !:表示Java后面不能跟随8|11|17
String regx2 = "Java(?!8|11|17)";
Pattern p = Pattern.compile(regx);
// 获取文本匹配器
Matcher m = p.matcher(str);
while (m.find()) {
String s1 = m.group();
System.out.println(s1);
}
// 为什么只有四个呢?第一个Java后面没有跟随任何内容,所以不符合规则
}
}三、贪婪爬取与非贪婪爬取

java
package com.lkbhua.MyApi.Regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Crawler2 {
public static void main(String[] args) {
// 贪婪爬取
// ab+
// 贪婪爬取:尽可能多的匹配 abbbbbbbbbbbbbbbbbbbbbb
// 懒惰爬取:尽可能少的匹配 ab
// Java中默认的就是贪婪爬取
// 如果我们在数量词+ * 的后面加上问好,那么此时候就是非贪婪爬取
String str = "Java自从95年问世以来,经历l很多版本,abbbbbbbbbbbbbbbbbbbbbaaaaaaaaaaaaaaaaa,目前企业中用的很多的是Java8和Java11." +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信未来不久Java17也会逐渐登上历史舞台";
String regx = "ab+";
Pattern p = Pattern.compile(regx);
Matcher m = p.matcher(str);
while (m.find()) {
String s1 = m.group();
System.out.println(s1);
}
System.out.println("------------------");
String regx1 = "ab+?";
Pattern p1 = Pattern.compile(regx1);
Matcher m1 = p1.matcher(str);
while (m1.find()) {
String s1 = m1.group();
System.out.println(s1);
}
System.out.println("------------------");
}
}声明:
以上均来源于B站@ITheima的教学内容!!!
本人跟着视频内容学习,整理知识引用