前言
在之前的学习中,了解了数据库/表的相关操作,数据类型以及表的约束;这些都是用来定义表结构的。
现在来学习表数据的相关操作:增删改查
表数据的相关操作,无非就是:Create(创建), Retrieve(读取),Update(更新),Delete(删除)
一、Create
插入数据,insert:
sql
insert into tb_name (字段名列表) values (数据列表);其中into可以省略;字段名也可以省略,如果省略字段名,就是全列插入。
1. 单行数据
现在创建一张学生表,其中存在字段:id、sn和name
sql
create table t1(
id int primary key auto_increment,
sn int not null unique key comment '学号',
name varchar(10) not null
);在使用insert插入数据时,可以指定列插入,也可以全列插入。
sql
insert into t1 values(1,1001,'星辰'); --- 省略字段名列表, 全列插入
insert into t1 (sn,name) values (1002,'晚安'); --- 指定列插入2. 多行数据
使用insert可以插入单行数据,也可以一次插入多行数据,只需要在values后跟多个数据列表即可(使用,隔开)。
sql
insert into t1 values (3,1003,'帅哥'),(4,1004,'美女'); --- 全列多行插入
insert into t1 (sn,name) values (1005,'国色'), (1006,'天香'); --- 指定列多行插入3. 插入/更新
在一张表中,可以由于主键 或者唯一键对应的值已经存在导致插入失败;
此时我们可以更新数据:
sql
on duplicate key updata 字段=数据, 字段=数据...只需要在使用insert插入数据时,后跟上面语句即可。
sql
insert into t1 values (1,1001,'小廉') on duplicate key update id=101,sn=1111,name='小廉';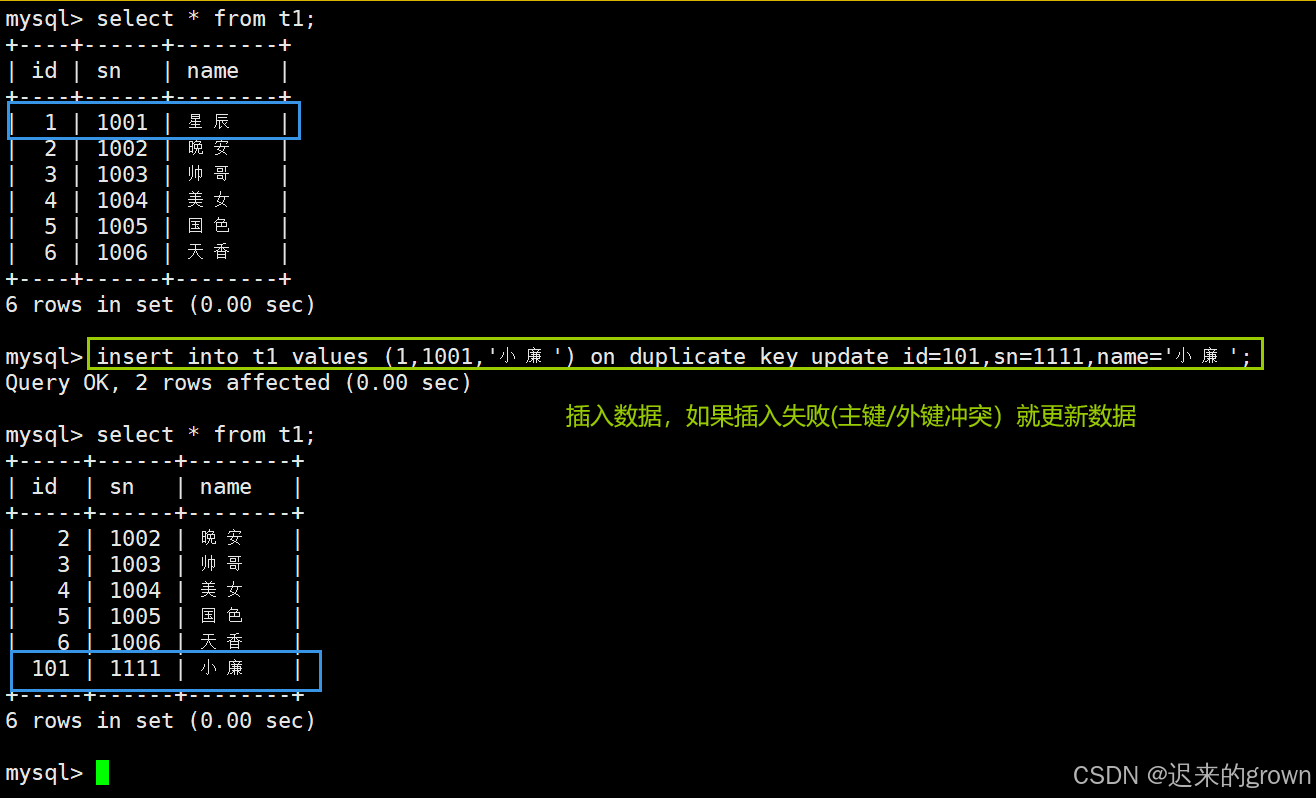
4. 替换
替换和上述的插入/更新功能类似,都可以完成数据插入或者更新的操作,但是替换replace是删除后再插入而不是更新。
- 主键/唯一键没有冲突就直接插入;
- 主键/唯一键存在冲突,则删除后再插入。
replace使用语法和insert相同:
sql
replace into t1 (字段列表) values (数据列表);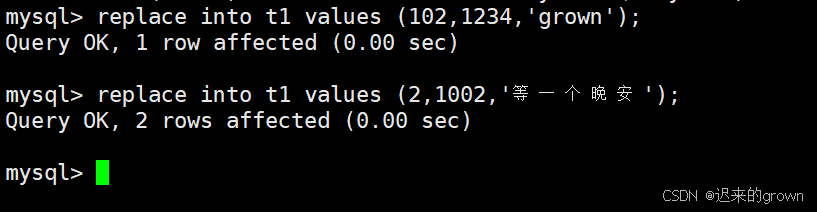
这里我们可以根据返回信息判断数据插入情况:
sql
-- Query OK, 1 row affected (0.00 sec) ---> 表中没有冲突数据,数据被插入
-- Query OK, 2 rows affected (0.00 sec) ---> 表中有冲突数据,删除后重新插入二、Retrieve
在了解查询语句之前,先构造一张表,并填充一些数据(期末成绩表):
sql
create table exam_result(
id int unsigned primary key auto_increment,
name varchar(10) not null comment '学生姓名',
chinese float default 0.0 comment '语文成绩',
math float default 0.0 comment '数学成绩',
english float default 0.0 comment '英语成绩'
);
insert into exam_result(name,chinese,math,english) values
('张星辰', 67, 98, 56),
('孙晚安', 87, 78, 77),
('李帅哥', 88, 98, 90),
('侯美女', 82, 84, 67),
('赵天香', 55, 85, 45),
('孙明', 70, 73, 78),
('王大帅', 75, 65, 30);1. select基本查询
全列查询:
sql
select * from tb_name;通常情况下,不推荐使用*进行全列查询:
- 查询的列越多,需要传输的数据量越大;
- 可能会影响索引的使用。
sql
select * from exam_result; --- 查询 exam_result 中所有数据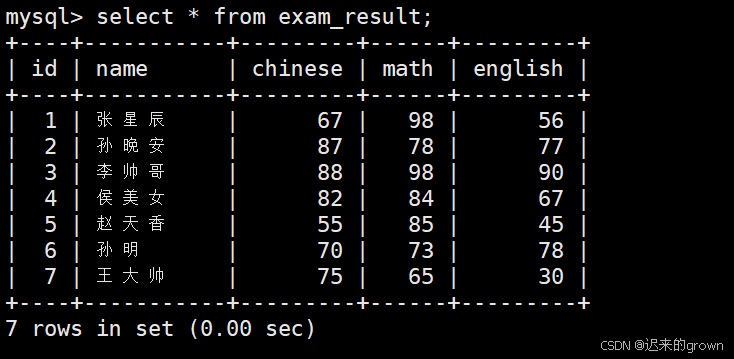
指定列查询:
select后跟指定列(查询多列,就使用,隔开),就可以查询表中指定列的数据。(可以不按照定义表时的列顺序)
sql
select name,english from exam_result;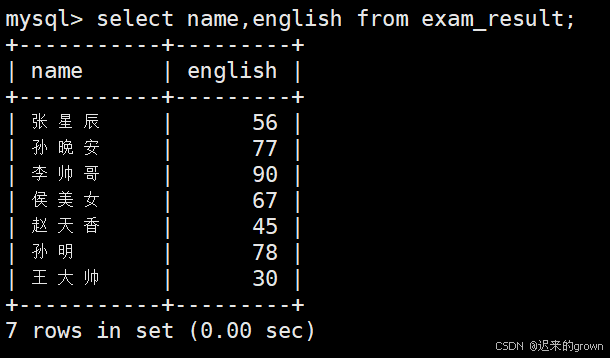
查询字段是表达式:
例如,现在要查询每一个学生的总分,就可以查询chinese + math + english表达式。
此外,在表达式后也可以跟上别名(给当前表达式起个名字)
sql
select name chinese+math+english from exam_result; --- 查询姓名,chinese+math+english
select name chinese+math+english 总分 from exam_result; --- 查询姓名,总分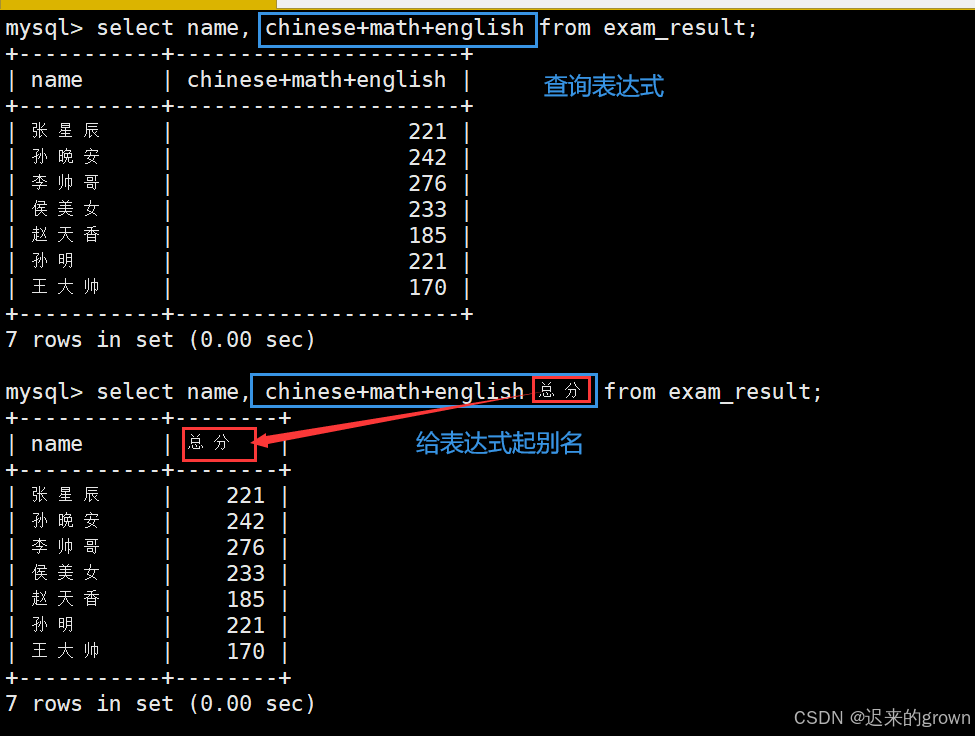
结果去重:
表中数据,可能存在某一字段的数据相同;(例如,exam_result表中数学成绩存在相同的)
在使用select查询时可以带上DISTINCT进行去重操作。
sql
select math from exam_result; --- 查询math列
select distinct math from exam_result; --- 查询math列并去重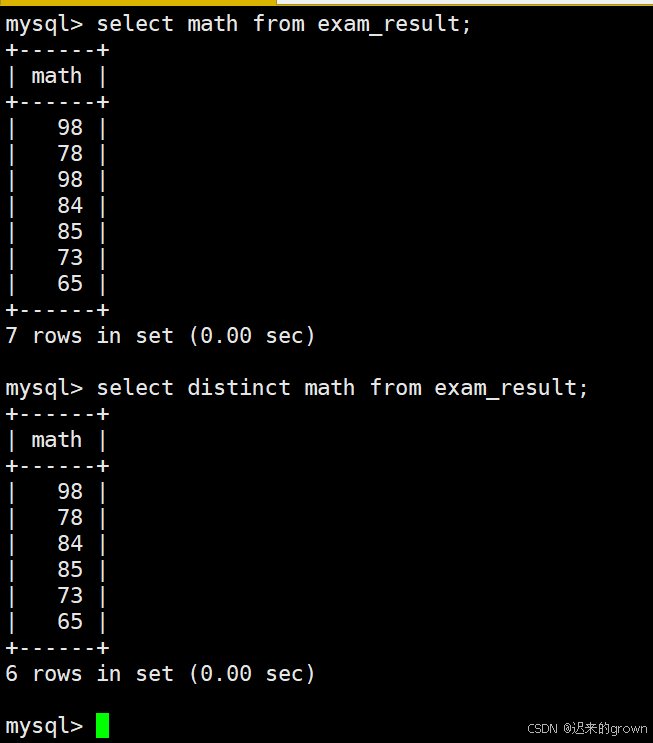
2. where条件
在查询过程中,我们可以在跟上筛选条件,例如:姓名是张星辰的学生的成绩,数学成绩大于80的学生等等。
运算符
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,a0, a1,如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
=:NULL不安全,NULL运算的结果为NULL。<=>:NULL安全,NULL<=>NULL的结果为true。is NULl、is not NULL:判断是NULL、不是NULL
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
在使用select查询时,后面跟上where 筛选条件即可查询指定内容
使用案例
1. 英语成绩小于60的学生及英语成绩
基本查询,筛选条件是:english<60
sql
select name,english from exam_result where english<60;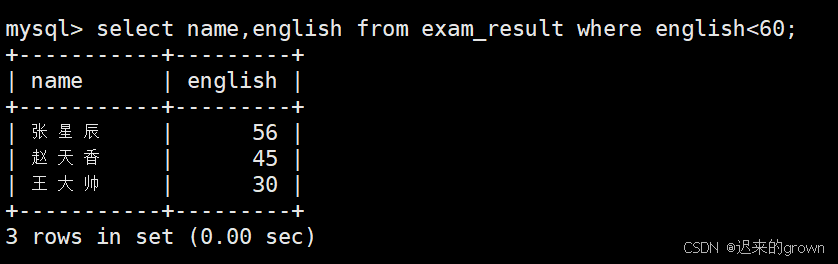
2. 语文成绩在[80,90]之间的同学及语文成绩
使用where条件
这里的筛选条件就是:chinese>=80和chinese<=90,中间使用and连接。
使用between x and y
between and范围匹配[x,y],如果x < value < y就返回true。
sql
select name,chinese from exam_result where chinese>=80 and chinese<=90;
select name,chinese from exam_result where chinese between 80 and 90;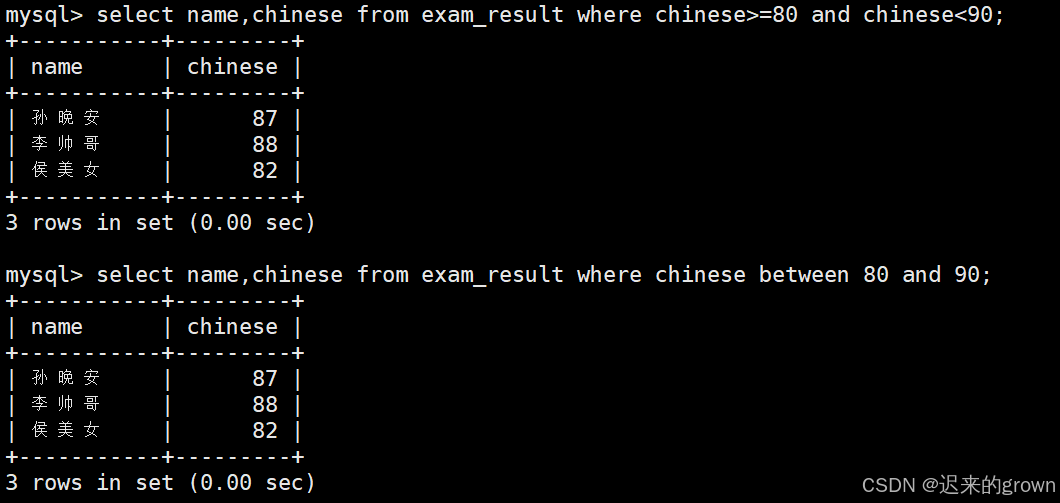
3. 查询数学成绩是58或59或98或99的同学及数学成绩
这里可以使用=判断,中间使用and连接,但这样太麻烦了;
这里就可以使用in(option...),如果数学成绩是(58,59,98,99)中的一个就返回true。
sql
select name,math from exam_result where math in(58,59,98,99);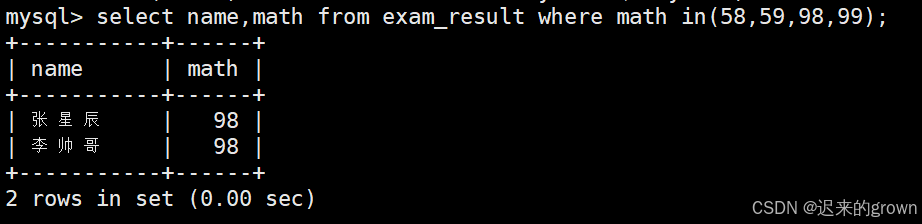
4. 查询姓孙的同学以及孙某同学
这里就要使用like模糊匹配。
查询姓孙的同学,也就是姓名是孙%(%表示任意多个字符)
查询孙某同学,也就是姓名是孙_(_表示任意一个字符)
sql
select name,math from exam_result where name like '孙%';
select name,math from exam_result where name like '孙_';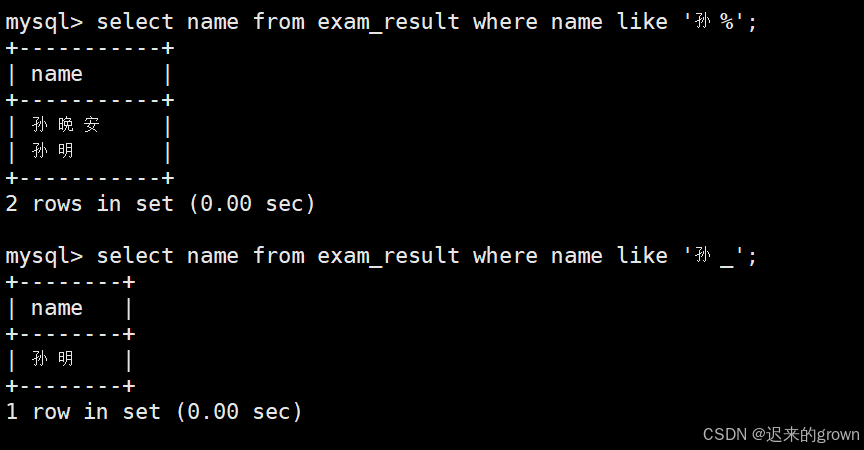
5. 语文成绩高于英语成绩的学生
where后跟筛选条件,>, >=, <, <=这些运算符两边也可以都是字段名。
sql
select name,chinese,english from exam_result where chinese>english;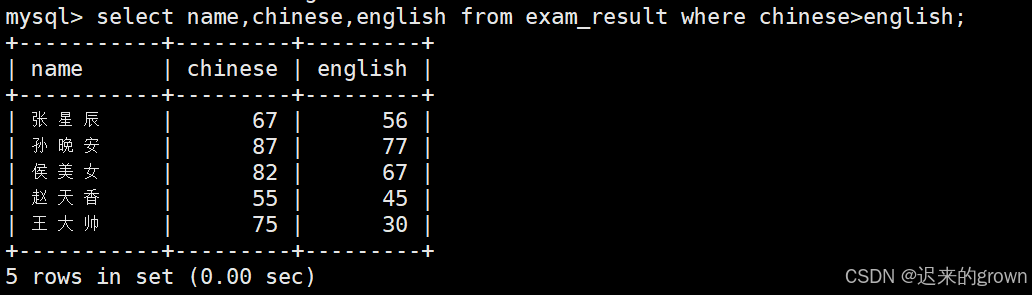
6. 总分在200分以下的学生
筛选条件:chinese+math+english <200。
注意:这里在where条件中使用表达式,不能使用别名。
sql
select name,chinese+math+english 总分 from exam_result where chinese+math+english<200;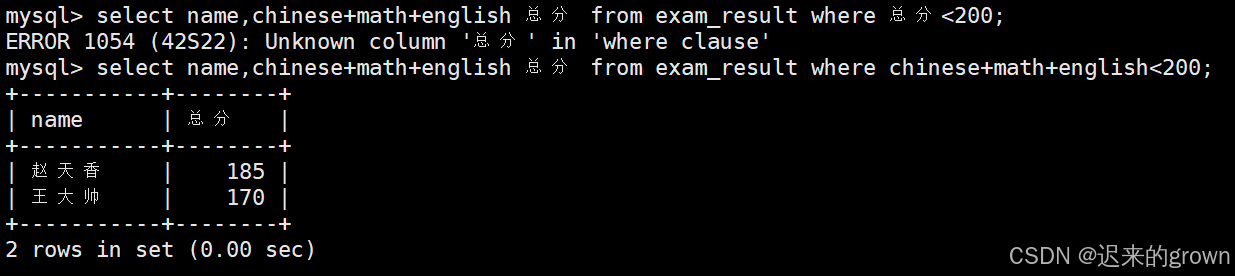
7. 语文成绩 > 80 且不姓孙的学生
筛选条件:chinese>80、name not like '孙%';
两个条件要都满足,中间使用and连接
sql
select name,chinese from exam_result where chinese>80 and name not like '孙%';
**8. 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80 **
筛选条件:name like '孙_'、chinese+math+english>200 and chinese<math and english>80;
两个筛选条件满足一个即可,使用or连接。
sql
select name, chinese, math, english, chinese + math + english 总分 from exam_result
where name like '孙_' or (chinese+math+english>200 and chinese>math and english>80);
NULL相关查询
is NULL判断是否为NULL
is not NULL判断是否不为NULL
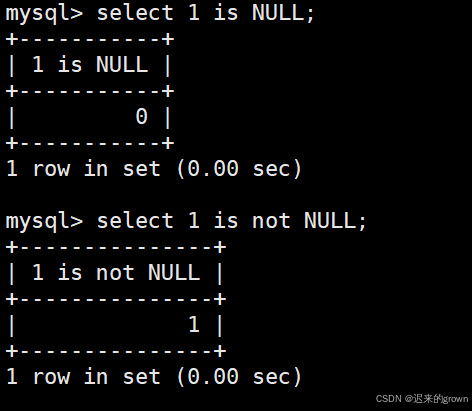
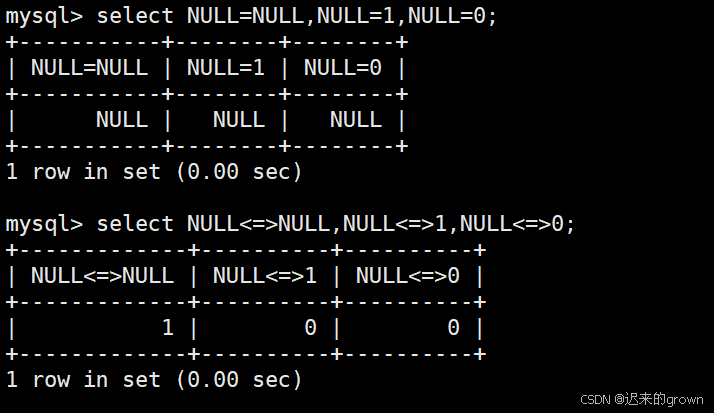
=是NULL不安全的:NULL=NULL、NULL=1、NULL=0结果都为NULL;
<=>是NULL安全的,NULL<=>NULL结果为1,NULL<=>1、NULL<=>0结果都为0。
3. 排序
ORDER BY :对查询的数据进行排序,默认是升序的。
ASC:升序(默认)DESC:降序
使用案例
1. 学生及数学成绩,按照数学成绩升序显示
按照数学成绩升序,排序子句就是:order by math asc(默认就是升序,可以省略asc)
sql
select name,math from exam_result order by math asc;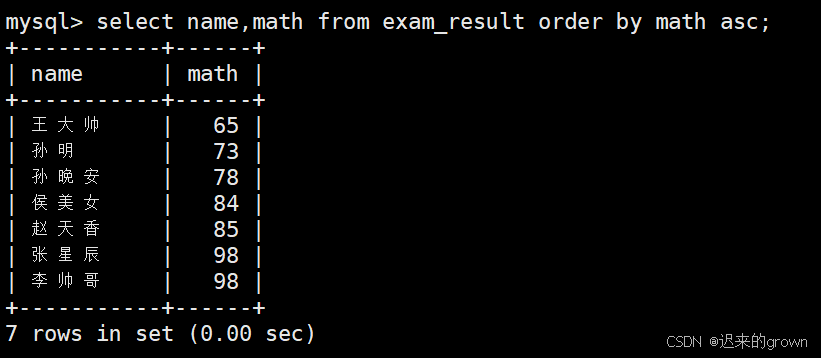
2. 学生各门成绩,依次按 数学降序,英语降序,语文升序的方式显示
这里依次按照数学降序、英语降序、语文升序的意思就是:
数学成绩相同时,按照英语成绩降序排序;
数学和英语成绩都相同时,按照语文成绩升序排序。
在order by子句后,依次跟上要排序的字段即可,使用,隔开。
sql
select name,math,english,chinese from exam_result order by math desc,english desc,chinese asc;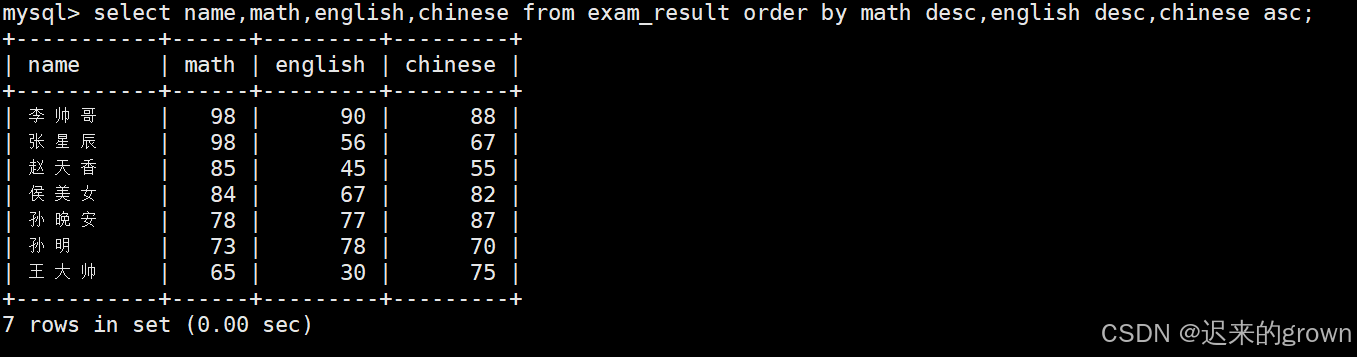
**3. 查询同学及总分,由高到低 **
这里按照总分进行排序时,order by子句中可以使用别名
sql
select name,chinese+math+english 总分 from exam_result order by 总分 desc;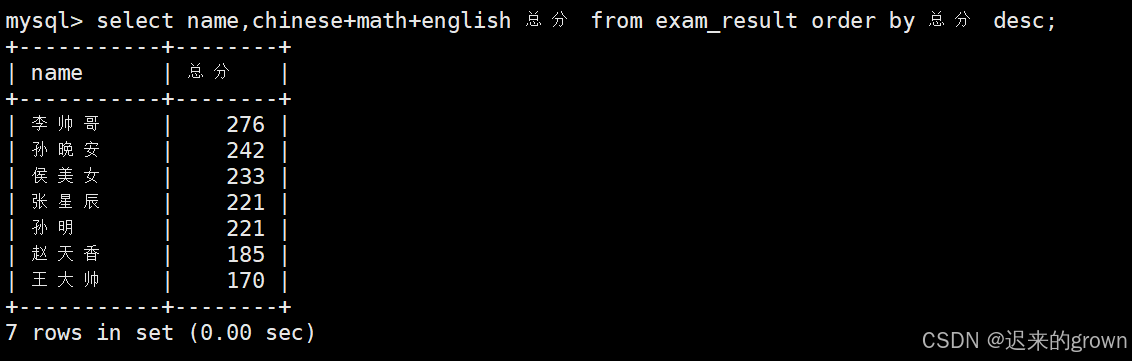
4. 查询姓孙的学生或者姓侯的学生 及数学成绩,按照降序排序
在使用order by子句排序之前,可以带上where条件,先进行筛选,再查询,然后再排序。(筛选不能使用别名,排序可以)
sql
select name,math from exam_result where name like '孙%' or name like '侯%' order by math desc;
4. 分页
limit用法:
sql
起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;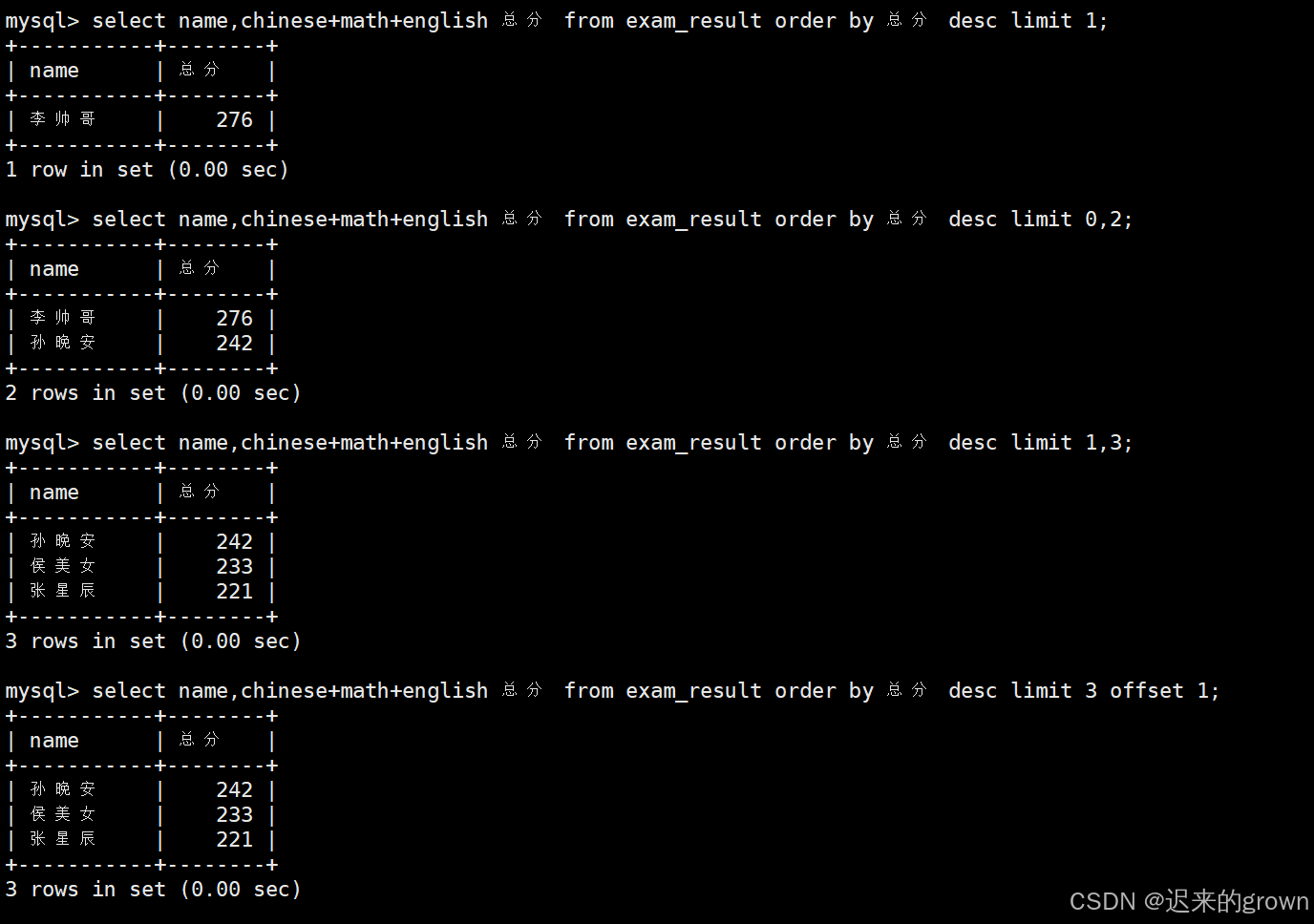
三、Update
sql
UPDATE tb_name set 字段=数据... [where] [order by] [limit ]对查询到的结果进行列值更新
1. 将孙晚安同学的数学成绩变更为 80 分
update在更新数据时,默认是全列更新,所以要更新某一行数据就要使用where条件筛选。
sql
select name,math from exam_result where name='孙晚安';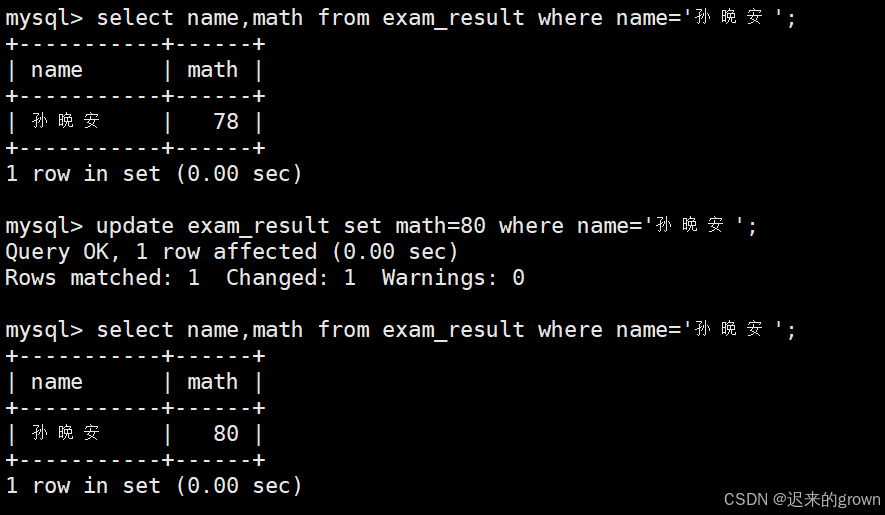
2. 将侯美女同学的数学成绩变更为 60 分,语文成绩变更为 70 分
set后跟多个字段,更新多列数据;使用where条件进行筛选。
sql
update exam_result set math=60, chinese=70 where name='侯美女';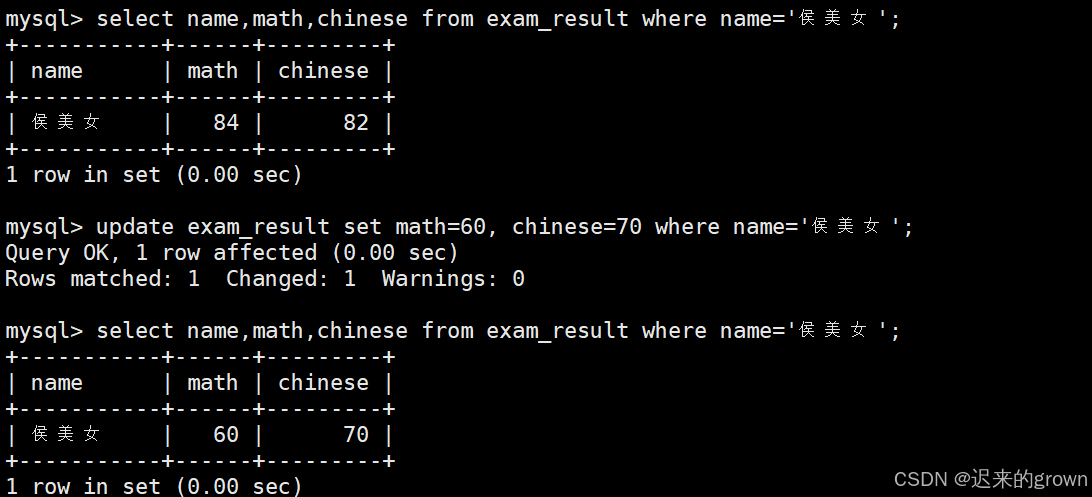
3. 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
要将总成绩倒数前三的3位同学的数学成绩加上30分,首先就要先筛选出来成绩倒数的前三名同学:
sql
select name,chinese+math+english as 总成绩 from exam_result order by 总成绩 asc limit 0,3;筛选的条件就是:order by 总成绩 desc(总成绩升序排序)、再limit 0,3,从第0行开始去前三行。
然后就是更新数据,数学成绩加上30分:math=math+30(SQL语句中不能使用+=)。
sql
update exam_result set math=math+30 order by chinese+math+english asc limit 3;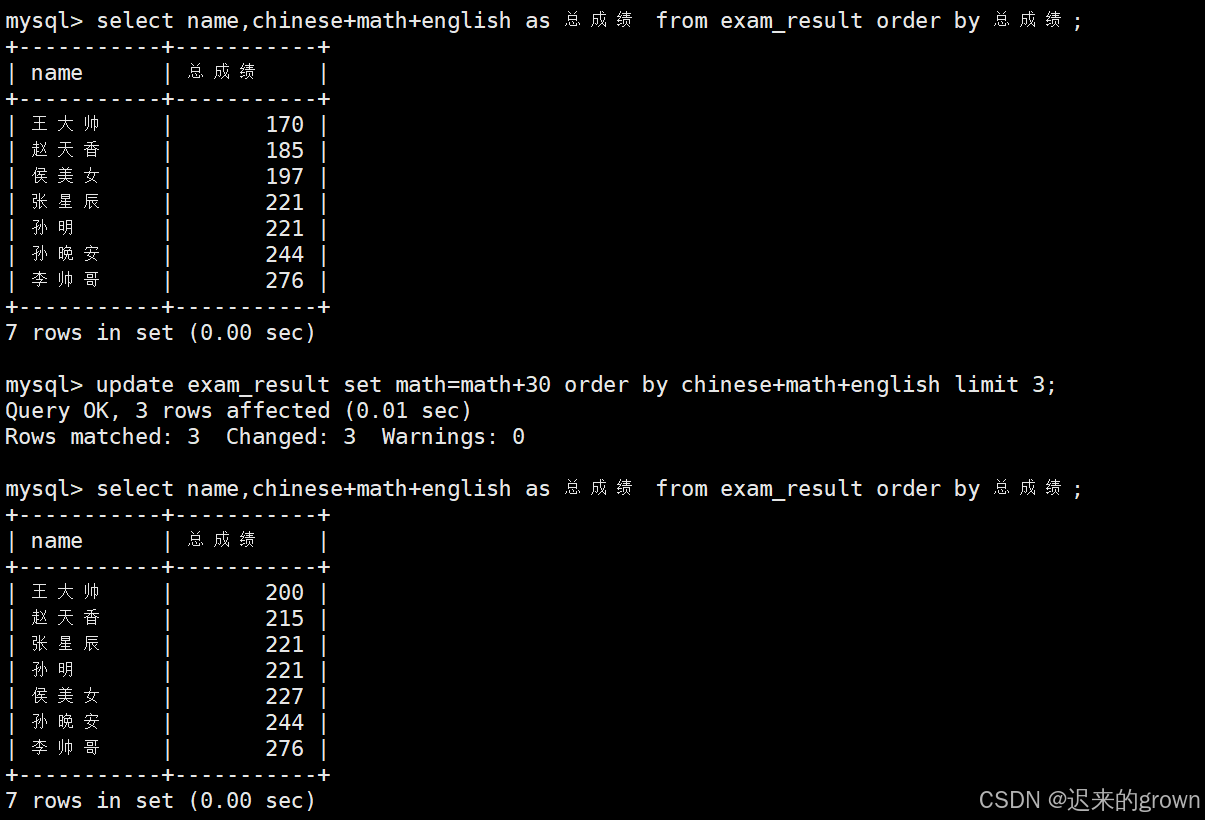
4. 将所有同学的语文成绩更新为原来的 2 倍
这里就直接修改全列数据,没有筛选条件;
update默认就是修改全列数据,谨慎使用
sql
update exam_result set chinese=chinese*2;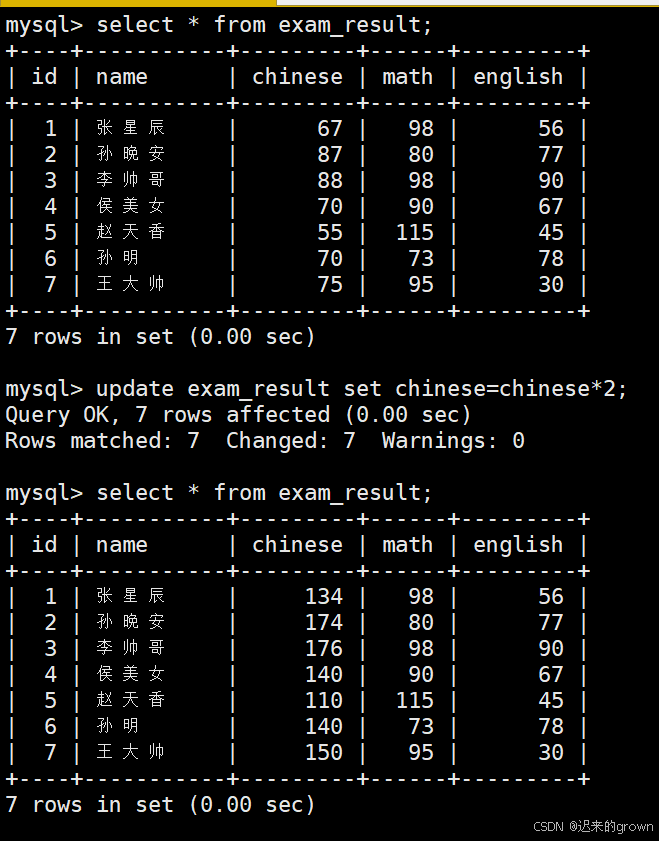
四、Delete
sql
DELETE FROM tb_name [WHERE ] [ORDER BY ] [LIMIT ];delete在删除表中数据时,如果没有筛选条件,默认会删除表中的所有数据。
在使用时就要带上一些列筛选条件。
**删除孙晚安同学的考试成绩 **
sql
delete from exam_result where name='孙晚安';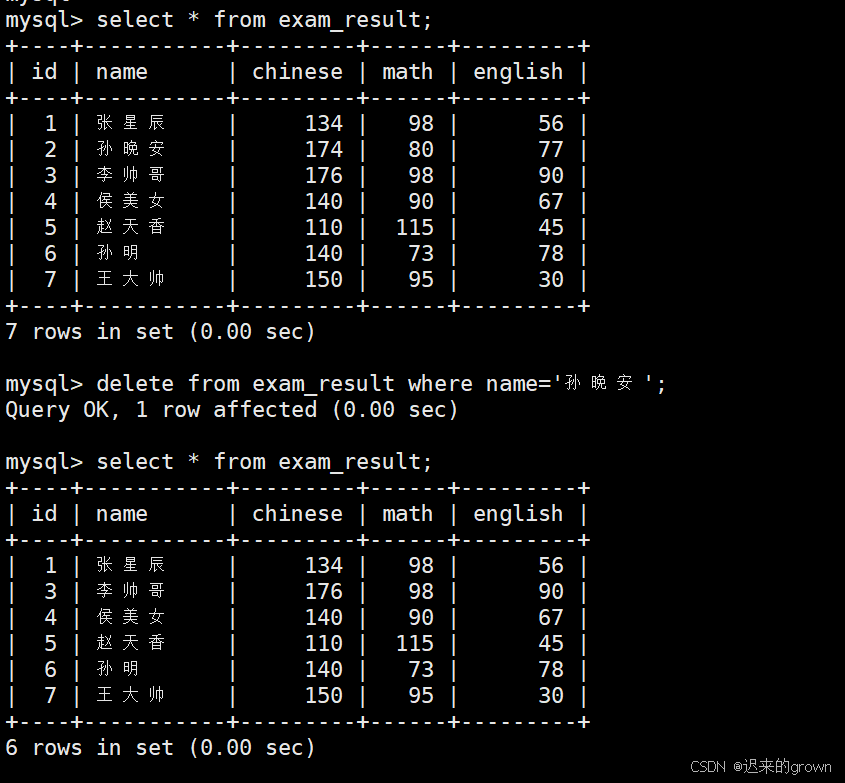
截断表truncate
sql
truncate table tb_name;truncate只能对整表操作,不能像delete一样针对部分数据操作;- 实际上
MYSQL不对数据操作,比deleta更快;但是truncate在删除数据时,不经过事务,无法回滚。 truncate会重置auto_increment项,而delete不会。
五、聚合函数
| 函数 | 说明 |
|---|---|
| COUNT(DISTINCT expr) | 返回查询到的数据的 数量 |
| SUM(DISTINCT expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG(DISTINCT expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX(DISTINCT expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN(DISTINCT expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
聚合函数通常与分组查询相结合,先分组再进行聚合统计。
1. 统计班级学生个数
使用COUNT聚合函数即可统计数据表中的数据个数;
count可以传递指定列,表示统计指定列中的数据个数,NULL不进行统计;
这里传递*在统计个数时不受NULL的影响。
sql
select count(*) from exam_result;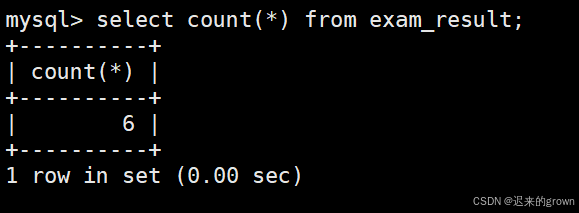
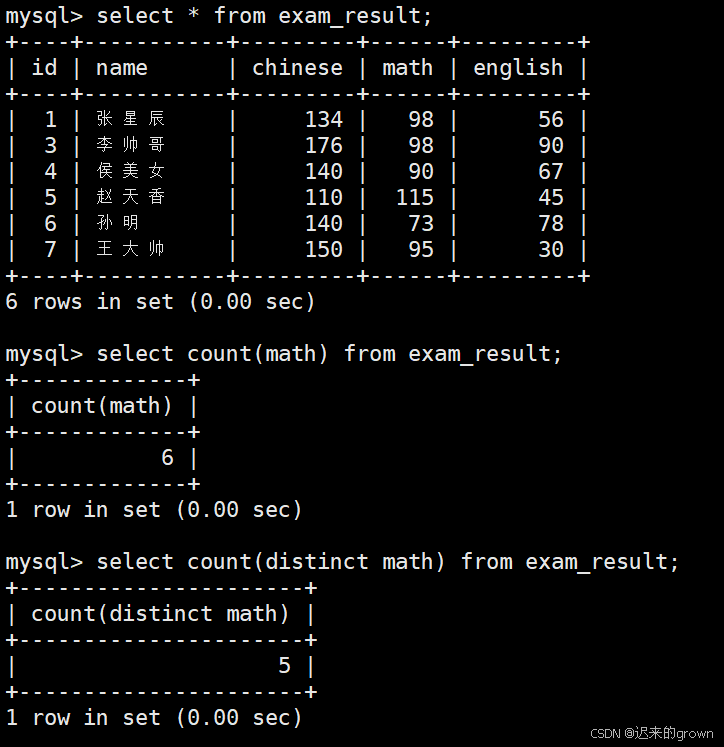
2. 统计数学成绩分数个数
在当前表中,存在6条数据,其中数学成绩存在一条重复的数据;
使用count(math)统计出的个数是6;
使用count (distinct math)统计出的个数是5。(去重)
3. 统计数学成绩总分
使用sum聚合函数统计某一列数据的总和;
此外,也可以进行条件筛选、分组后再进行聚合统计
sql
select sum(math) from exam_result;
select sum(math) from exam_result where math<60;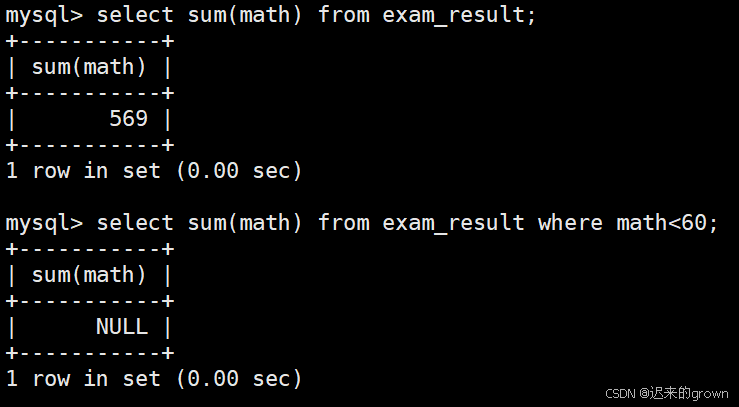
4. 求总分的平均分
avg聚合函数可以用来求平均
这里也可以先进行条件筛选、分组后再进行聚合统计。
sql
select avg(chinese+math+english) as 平均分 from exam_result;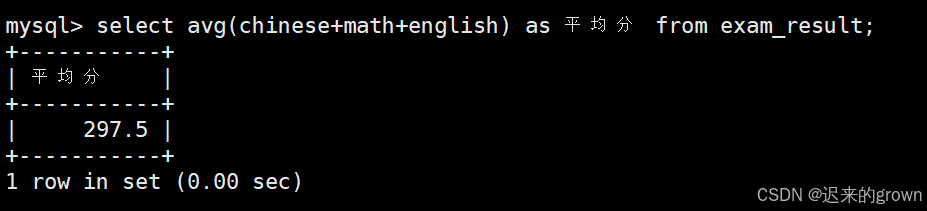
5. 英语成绩的最高分、数学成绩最低分
max聚合函数用来求最大值、min聚合函数用来求最小值
sql
select max(english) from exam_result;
select min(math) from exam_result;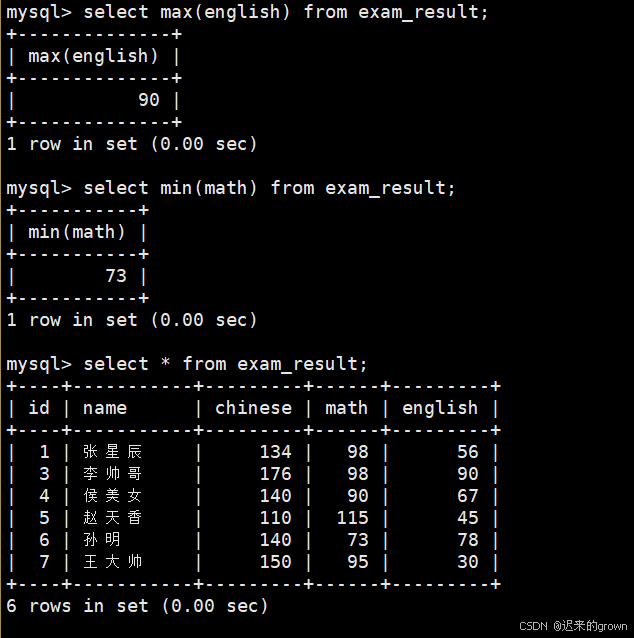
六、分组查询
在select 查询中使用group by子句就可以对指定列进行分组查询。
这里有这样的三张表,里面存储着一些数据。
emp员工表:empno员工编号、ename员工姓名、job工作岗位、mgr上级领导编号、hiredate入职时间、sal薪资、comm奖金、deptno部门编号。dept部门表:deptno部门编号、dname部门名称、loc部门地址。salgrade等级表:grade等级、losal最低薪资、hisal最高薪资。
1. 查询每个部门的平均薪资、最高薪资、最低薪资
要求每个部门的平均薪资和最高薪资,首先要将emp表按照部门编号分组;group by deptno。
分组之后,再使用聚合函数求平均薪资、最低薪资和最高薪资。(不分组,就默认将整张表当做一个组求的就是所有员工的平均薪资、最低薪资和最高薪资)
sql
select deptno,avg(sal) as 平均薪资,max(sal) as 最高薪资,min(sal) as 最低薪资 from emp group by deptno;
2. 查询平均工资低于2000的部分和它的平均工资
这里要对分组后的结果进行筛选,使用 having对group by结果进行过滤。
having作用上类似于where,都是对结果进行筛选
特性 WHERE HAVING 作用阶段 数据分组前 数据分组后 作用对象 原始表的行 分组后的聚合结果 能否使用聚合函数 不能(如 SUM()、COUNT())可以(如 HAVING COUNT(*) > 1)是否必须配合 GROUP BY 不需要 通常需要(除非整个查询是聚合查询) 执行顺序 在 GROUP BY之前在 GROUP BY之后
sql
select deptno,avg(sal) as 平均薪资 from emp group by deptno having 平均薪资<2000;
补充:执行顺序
这里我们写的mysql语句顺序:
sql
SELECT ... DISTINCT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT n;在执行mysql语句时,并不是按照我们写的顺序执行的。
mysql语句执行顺序:
| 顺序 | 阶段 | 说明 |
|---|---|---|
| 1 | FROM | 确定数据来源表 |
| 2 | JOIN | 连接其他表,生成虚拟表 |
| 3 | ON | 应用连接条件 |
| 4 | WHERE | 过滤原始行(不能含聚合函数) |
| 5 | GROUP BY | 分组 |
| 6 | HAVING | 过滤分组后的结果(可用聚合函数) |
| 7 | SELECT | 选择列,计算表达式 |
| 8 | DISTINCT | 去重 |
| 9 | ORDER BY | 排序(可用别名) |
| 10 | LIMIT | 限制返回行数 |
这里
where要比select先执行,所以在select定义的别名不能在where中使用。而
order by比select后执行,所以在order by中可以使用别名。
本篇文章到这里就结束了,感谢支持
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=2oul0hvapjsws