
SVDLUT: 基于SVD优化的3DLUT(2025 ICCV)
- 专题介绍
- 一、研究背景
- 二、SVDLUT方法
-
- [2.1 3DLUT的低维分解](#2.1 3DLUT的低维分解)
- [2.2 奇异值分解(SVD)降参](#2.2 奇异值分解(SVD)降参)
- [2.3 缓存高效的空间特征融合](#2.3 缓存高效的空间特征融合)
- [2.4 损失函数](#2.4 损失函数)
- 三、实验结果
- 四、总结
本文将围绕《SVDLUT: Lightweight and Fast Real-time Image Enhancement via Decomposition of the Spatial-aware Lookup Tables》展开完整解析。本文提出一种名为SVDLUT的轻量级快速实时图像增强方法,针对现有 3D 查找表(3D LUT)方法缺乏空间信息、空间感知 3D LUT 方法参数多且高分辨率图像推理时间长的问题,通过将 3D LUT 分解为低维 2D LUT 的线性组合并结合奇异值分解(SVD) ,实现参数数量减少 88%;同时设计缓存高效的空间特征融合结构,减少高分辨率图像推理时的内存数据交换,在 FiveK 和 PPR10K 等基准数据集上验证,该方法在保持空间感知能力和增强性能(如 FiveK 数据集 480p 分辨率下 PSNR 达 25.76dB)的同时,模型尺寸仅 160.5K(约为 SABLUT 的 1/3、SA-3DLUT 的 1/28),4K 分辨率推理时间仅 1.38ms,优于现有主流方法。参考资料如下:
1. 论文地址
2. 代码地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理 的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
【8】Tiny-LUT
【9】3D-LUT
【10】4D-LUT
【11】AdaInt-LUT
【12】Sep-LUT
【13】CLUT
【14】ICELUT
【15】AutoLUT
【16】SA-3DLUT
【17】SABLUT
一、研究背景
该篇文章优化的是SABLUT,SABLUT为了补充空间信息,增加了大量的3DLUT查找过程,引入大量额外参数,导致高分辨率图像推理时间显著增加(如 SABLUT 处理 4K 图像需 3.64ms),形成 "性能 - 效率" 权衡难题。本文是为了进一步对效率问题进行优化。
二、SVDLUT方法
SVDLUT最大的创新点在于其将3DLUT的查找过程使用SVD转换为了2DLUT的多次查找求和,减小了参数量和计算量。流程如图所示:
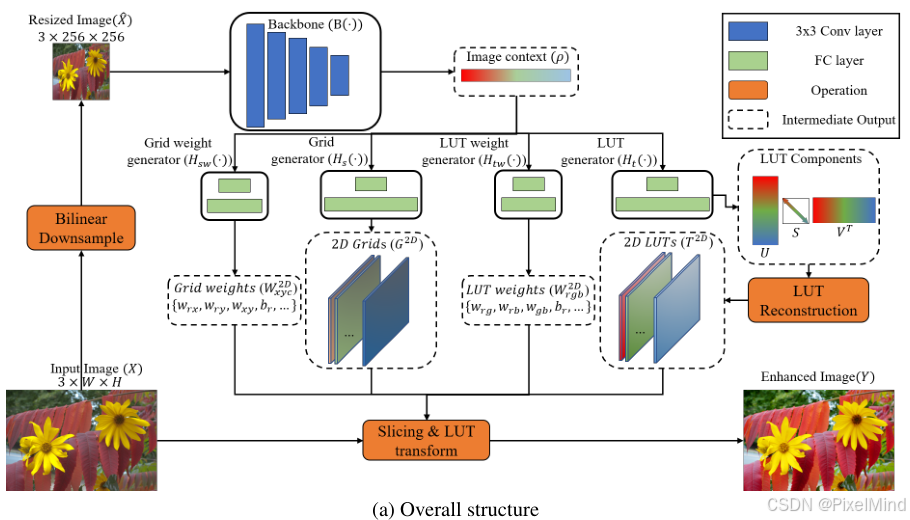
类比SABLUT方法上是相似的,都存在双边grid的插值和颜色的LUT插值操作,不过因为查找维度变小了,因此作者额外引入了 G r i d w e i g h t s Grid \ weights Grid weights以及 L U T w e i g h t s LUT \ weights LUT weights用于对多个2DLUT的插值结果进行加权求和,从而完成与3DLUT相似的功能。
接下来本文将详细描述其如何完成3D到2D的转换,并实现类似的功能。
2.1 3DLUT的低维分解
现有 3D LUT / 双边网格存在严重参数冗余,作者通过实验验证这一现象。
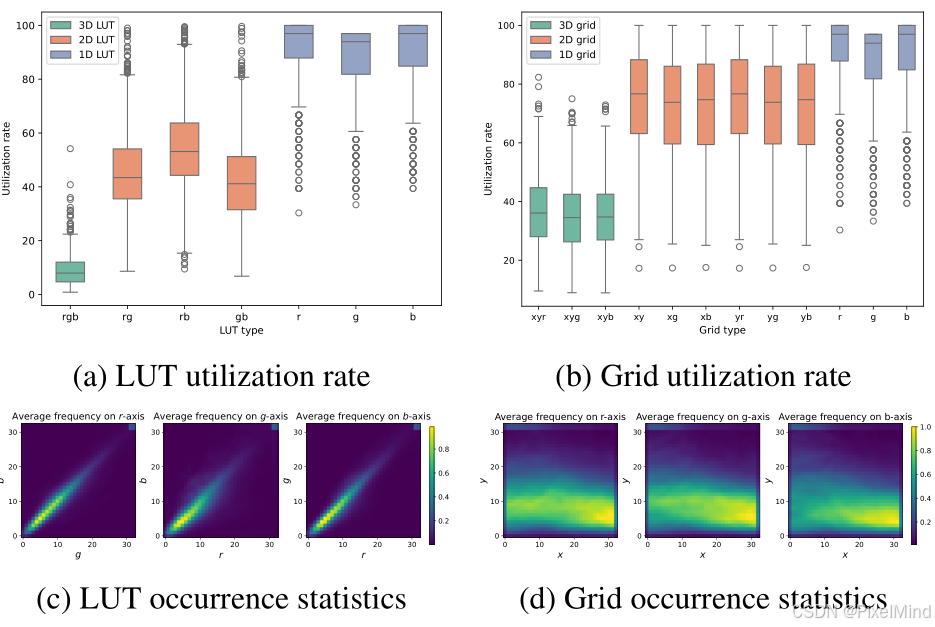
作者在2个数据集上进行了LUT利用率和顶点访问频率统计,有以下两个结论:
- 顶点利用率实验:定义 "利用率 = 实际引用顶点数 / 生成顶点总数 ×100%",结果显示,3D LUT 利用率 < 10%(图a):大量顶点未被访问,参数浪费严重,1D LUT 利用率 100%:但存在 "通道关联缺失" 问题(无法捕捉红 - 绿、红 - 蓝等跨通道关联),性能饱和。
- 顶点访问频率统计:可视化 3D LUT 顶点的访问次数(图 c),发现高频访问集中在对角线顶点,非对角线顶点访问极少,进一步证明 3D 结构的冗余性 ------ 仅需保留核心维度(2D)即可覆盖主要信息。
由上,可以明白作者为何要进行降维。具体降维的方法,针对 3D LUT 与 3D 双边网格,分别提出 2D 分解策略,核心是 "用 3 个 2D 组件的线性组合替代 1 个 3D 组件",并引入权重与偏置调节表达能力。针对于两类不同的LUT:
- 颜色的3DLUT :使用2D LUT的线性组合。公式如下所示:
t r g b c → w r g c ⋅ t r g c + w r b c ⋅ t r b c + w g b c ⋅ t g b c + b c t_{rgb}^{c} \to w_{rg}^{c} \cdot t_{rg}^{c} + w_{rb}^{c} \cdot t_{rb}^{c} + w_{gb}^{c} \cdot t_{gb}^{c} + b^{c} trgbc→wrgc⋅trgc+wrbc⋅trbc+wgbc⋅tgbc+bc
其中, t r g b c t_{rgb}^{c} trgbc代表输出通道 c c c对应的3D LUT,维度为 R D t × D t × D t \mathbb{R}^{D_t \times D_t \times D_t} RDt×Dt×Dt( D t D_t Dt为每轴顶点数), c ∈ { r , g , b } c \in \{r, g, b\} c∈{r,g,b}(红、绿、蓝通道), t r g c , t r b c , t g b c t_{rg}^{c}, t_{rb}^{c}, t_{gb}^{c} trgc,trbc,tgbc代表输出通道 c c c对应的2D LUT,分别对应红-绿、红-蓝、绿-蓝轴,维度均为 R D t × D t \mathbb{R}^{D_t \times D_t} RDt×Dt。 w r g c , w r b c , w g b c w_{rg}^{c}, w_{rb}^{c}, w_{gb}^{c} wrgc,wrbc,wgbc代表2D LUT的线性组合权重(可学习参数),用于调节各2D LUT对3D LUT的贡献度, b c b^{c} bc代表线性组合的偏置项(可学习参数),用于补偿2D LUT组合后的偏移。
对应于具体的插值公式为:
Y ( c , x , y ) = w r g c ⋅ I b i ( X ‾ ( x , y ) , t r g c ) + w r b c ⋅ I b i ( X ‾ ( x , y ) , t r b c ) + w g b c ⋅ I b i ( X ‾ ( x , y ) , t g b c ) + b c \begin{aligned} Y_{(c, x, y)} &= w_{rg}^{c} \cdot I_{bi}\left(\overline{X}{(x, y)}, t{rg}^{c}\right) + \\ &\quad w_{rb}^{c} \cdot I_{bi}\left(\overline{X}{(x, y)}, t{rb}^{c}\right) + \\ &\quad w_{gb}^{c} \cdot I_{bi}\left(\overline{X}{(x, y)}, t{gb}^{c}\right) + b^{c} \end{aligned} Y(c,x,y)=wrgc⋅Ibi(X(x,y),trgc)+wrbc⋅Ibi(X(x,y),trbc)+wgbc⋅Ibi(X(x,y),tgbc)+bc
其中, Y ( c , x , y ) Y_{(c, x, y)} Y(c,x,y)代表增强后图像在通道 c c c、空间坐标 ( x , y ) (x, y) (x,y)处的像素值,取值范围为 0 , 1 0, 1 0,1, I b i ( ⋅ ) I_{bi}(\cdot) Ibi(⋅)代表双线性插值函数,输入为"插值点(像素值)+ 2D LUT",输出为插值后的增强像素值, X ‾ ( x , y ) \overline{X}_{(x, y)} X(x,y):预处理后输入图像在坐标 ( x , y ) (x, y) (x,y)处的像素值(含空间特征融合后的信息),其他符号与上同理。 - 空间的3D双边网格 :使用2D双边网格线性组合,与上面基本一致,只不过此时空间有2维,因此组合的项数会更多。公式表示如下: g x y c k ′ c k ′ → w x y c k ′ ⋅ g x y c k ′ + w x c k ′ c k ′ ⋅ g x c k ′ c k ′ + w y c k ′ c k ′ ⋅ g y c k ′ c k ′ + b c k ′ g_{xyc_{k}'}^{c_{k}'} \to w_{xy}^{c_{k}'} \cdot g_{xy}^{c_{k}'} + w_{xc_{k}'}^{c_{k}'} \cdot g_{xc_{k}'}^{c_{k}'} + w_{yc_{k}'}^{c_{k}'} \cdot g_{yc_{k}'}^{c_{k}'} + b^{c_{k}'} gxyck′ck′→wxyck′⋅gxyck′+wxck′ck′⋅gxck′ck′+wyck′ck′⋅gyck′ck′+bck′其中, g x y c k ′ c k ′ g_{xyc_{k}'}^{c_{k}'} gxyck′ck′代表3D双边网格,维度为 R W × H × C \mathbb{R}^{W \times H \times C} RW×H×C( W , H W, H W,H为图像宽高, C C C为通道数),用于提供空间感知信息, k k k代表双边网格的索引(表示第 k k k个双边网格), k ′ = m o d ( k , 3 ) k' = \mod(k, 3) k′=mod(k,3)(通道循环映射,确保与RGB通道匹配), g x y c k ′ , g x c k ′ c k ′ , g y c k ′ c k ′ g_{xy}^{c_{k}'}, g_{xc_{k}'}^{c_{k}'}, g_{yc_{k}'}^{c_{k}'} gxyck′,gxck′ck′,gyck′ck′代表2D双边网格,分别对应"空间-空间(x-y)"、"空间-颜色(x- c k ′ c_{k}' ck′)"、"空间-颜色(y- c k ′ c_{k}' ck′)"轴,维度均为 R D s × D s \mathbb{R}^{D_s \times D_s} RDs×Ds( D s D_s Ds为网格顶点数), w x y c k ′ , w x c k ′ c k ′ , w y c k ′ c k ′ w_{xy}^{c_{k}'}, w_{xc_{k}'}^{c_{k}'}, w_{yc_{k}'}^{c_{k}'} wxyck′,wxck′ck′,wyck′ck′代表2D双边网格的线性组合权重(可学习参数), b c k ′ b^{c_{k}'} bck′代表2D双边网格组合的偏置项(可学习参数)。
对应于具体的插值公式为: f s ( c k ′ , x , y ) = w x y c k ′ ⋅ I b i ( X ( c k ′ , x , y ) , g x y c k ′ ) + w x c k ′ c k ′ ⋅ I b i ( X ( c k ′ , x , y ) , g x c k ′ c k ′ ) + w y c k ′ c k ′ ⋅ I b i ( X ( c k ′ , x , y ) , g y c k ′ c k ′ ) + b c k ′ \begin{aligned} f_{s\left(c_{k}', x, y\right)} &= w_{xy}^{c_{k}'} \cdot I_{bi}\left(X_{\left(c_{k}', x, y\right)}, g_{xy}^{c_{k}'}\right) + \\ &\quad w_{xc_{k}'}^{c_{k}'} \cdot I_{bi}\left(X_{\left(c_{k}', x, y\right)}, g_{xc_{k}'}^{c_{k}'}\right) + \\ &\quad w_{yc_{k}'}^{c_{k}'} \cdot I_{bi}\left(X_{\left(c_{k}', x, y\right)}, g_{yc_{k}'}^{c_{k}'}\right) + b^{c_{k}'} \end{aligned} fs(ck′,x,y)=wxyck′⋅Ibi(X(ck′,x,y),gxyck′)+wxck′ck′⋅Ibi(X(ck′,x,y),gxck′ck′)+wyck′ck′⋅Ibi(X(ck′,x,y),gyck′ck′)+bck′其中, f s ( c k ′ , x , y ) f_{s\left(c_{k}', x, y\right)} fs(ck′,x,y)代表空间感知图在通道 c k ′ c_{k}' ck′、坐标 ( x , y ) (x, y) (x,y)处的值,维度为 R K × W × H \mathbb{R}^{K \times W \times H} RK×W×H( K K K为双边网格总数), X ( c k ′ , x , y ) X_{\left(c_{k}', x, y\right)} X(ck′,x,y)代表原始输入图像在通道 c k ′ c_{k}' ck′、坐标 ( x , y ) (x, y) (x,y)处的像素值(未预处理的原始值), I b i ( ⋅ ) I_{bi}(\cdot) Ibi(⋅)代表双线性插值函数,用于从2D双边网格中插值得到空间感知值,其他符号含义如上。
从上面可以看到这里我们选择双边网络的数目肯定不能小于3,否则无法循环访问到所有的颜色通道。
作者直接对这个改进进行了测试,发现效果不会发生下降,但参数量能有效减小80%以上,如下所示:
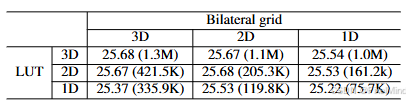
3D LUT+3D 网格的 PSNR 为 25.68dB,2D LUT+2D 网格的 PSNR 为 25.68dB,性能完全持平;3D 组合的模型尺寸为 1.3M,2D 组合仅为 205.3K,参数减少 84%(1.3M→205.3K),这一结果证明:低维分解可在不损失性能的前提下,大幅降低模型尺寸,解决参数冗余问题。
2.2 奇异值分解(SVD)降参
2D LUT / 网格虽已减少参数,但仍存在冗余 ------2D 结构的矩阵中部分奇异值对应的信息对增强性能影响极小,可通过 SVD 进一步移除冗余参数。作者做了一个实验来验证它,对预训练的 2D LUT / 网格进行 SVD 分解,逐步减少奇异值数量,重构后测试 PSNR,结论如下:
- 2D LUT:保留 8 个奇异值时,PSNR 无明显下降(与全奇异值相比差异 < 0.1dB)。
- 2D 双边网格:即使保留少量奇异值,PSNR 也快速下降(空间信息对冗余更敏感)。
如下图所示:
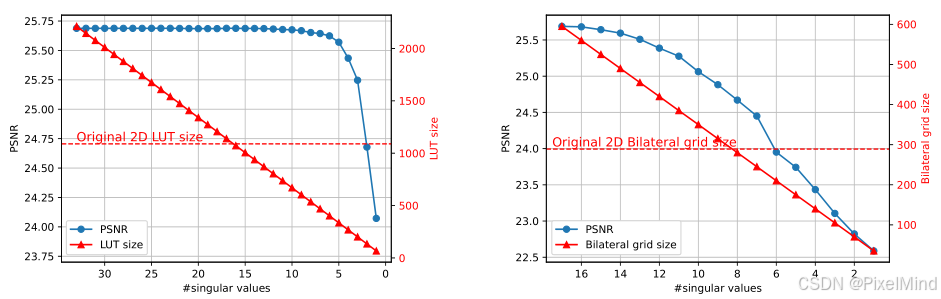
然后作者尝试用网络去模拟SVD过程,结果与上面一致,LUT 的 SVD 分解有效(8 个奇异值足够),网格的 SVD 分解性能损失大。如下图所示:
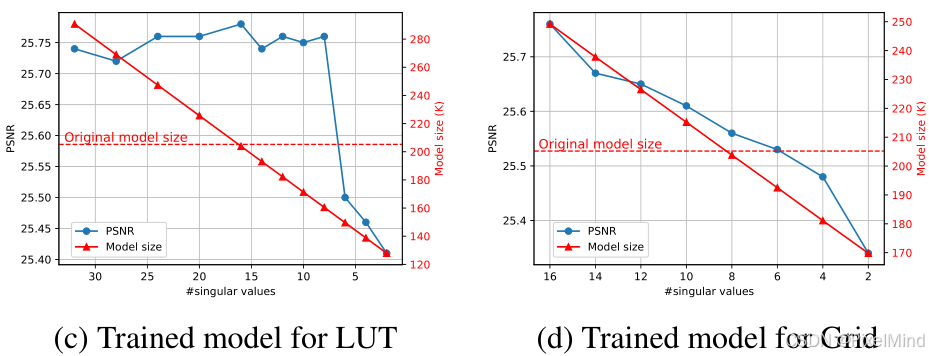
基于实验结论,仅对 2D LUT 应用 SVD,利用如下的分解公式进行分解:
T 2 D = U ⋅ S ⋅ V T , S , U , V T = H t ( ρ ) T^{2D} = U \cdot S \cdot V^{T}, \quad S, U, V^{T} = H_{t}(\rho) T2D=U⋅S⋅VT,S,U,VT=Ht(ρ)
其中, T 2 D T^{2D} T2D代表2D LUT集合,包含 t r g c , t r b c , t g b c t_{rg}^{c}, t_{rb}^{c}, t_{gb}^{c} trgc,trbc,tgbc( c ∈ { r , g , b } c \in \{r, g, b\} c∈{r,g,b}), U U U代表左奇异矩阵,维度为 R D t × N s \mathbb{R}^{D_t \times N_s} RDt×Ns( D t D_t Dt为LUT顶点数, N s = 8 N_s=8 Ns=8为保留的奇异值数量), S S S代表奇异值矩阵,为对角矩阵,维度为 R N s × N s \mathbb{R}^{N_s \times N_s} RNs×Ns,对角线元素为按降序排列的奇异值, V T V^{T} VT代表右奇异矩阵 V V V的转置,维度为 R N s × D t \mathbb{R}^{N_s \times D_t} RNs×Dt, H t ( ⋅ ) H_{t}(\cdot) Ht(⋅)代表LUT组件生成器,输入为上下文特征 ρ \rho ρ,输出为SVD分解后的组件 U , S , V T U, S, V^{T} U,S,VT, ρ \rho ρ代表图像上下文特征。
最后作者只在LUT上用了SVD分解,在Grid上没有使用,因为性能下降明显。
2.3 缓存高效的空间特征融合
传统空间感知 LUT 方法(如 SABLUT、SA-3DLUT)在高分辨率图像(如 4K)上推理慢,核心原因是内存层级数据交换频繁:中间输出需在 "高速内存(如 GPU 缓存)" 与 "低速内存(如显存)" 间频繁交换,占总推理时间的 60% 以上,如下图所示。
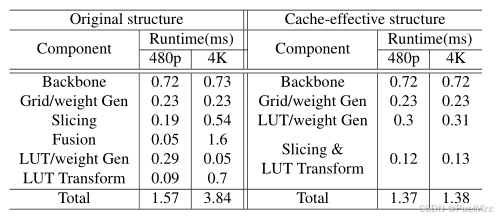
可以看到Cache-effective的结构相对来说耗时基本不变。这个缓存高效结构设计包含以下几步:
- 合并切片与 LUT 变换:传统流程中切片与LUT变换是独立步骤,需分别读取高分辨率输入,优化后将二者合并,复用 LUT 索引等中间计算结果,避免重复读取,减少内存访问次数。
- 移除冗余 1×1 卷积:传统流程用 1×1 卷积融合空间特征和输入,优化后去除这部分因为2D LUT / 网格的加权和已具备 "图像自适应融合" 能力,可直接替代 1×1 卷积,既减少计算量,又避免生成预处理图中间输出。
优化后公式表示如下:
Y ( c , x , y ) = T r a n s f o r m 2 D c ( X ( c , x , y ) , T 2 D ) + ∑ k = 0 K / 3 − 1 S l i c i n g 2 D c c + 3 k ′ ( X ( c , x , y ) , G 2 D ) \begin{aligned} Y_{(c, x, y)} &= Transform_{2D}^{c}\left(X_{(c, x, y)}, T^{2D}\right) + \\ &\quad \sum_{k=0}^{K/3 - 1} Slicing_{2D}^{c_{c+3k}'}\left(X_{(c, x, y)}, G^{2D}\right) \end{aligned} Y(c,x,y)=Transform2Dc(X(c,x,y),T2D)+k=0∑K/3−1Slicing2Dcc+3k′(X(c,x,y),G2D)
其中, T r a n s f o r m 2 D c ( ⋅ ) Transform_{2D}^{c}(\cdot) Transform2Dc(⋅)代表2D LUT变换操作,输入为原始像素值 X ( c , x , y ) X_{(c, x, y)} X(c,x,y)与2D LUT集合 T 2 D T^{2D} T2D,输出为LUT增强后的像素值, S l i c i n g 2 D c c + 3 k ′ ( ⋅ ) Slicing_{2D}^{c_{c+3k}'}(\cdot) Slicing2Dcc+3k′(⋅)代表2D双边网格切片操作,输入为原始像素值 X ( c , x , y ) X_{(c, x, y)} X(c,x,y)与2D双边网格集合 G 2 D G^{2D} G2D,输出为空间特征贡献值, G 2 D G^{2D} G2D代表2D双边网格集合,包含 g x y c k ′ , g x c k ′ c k ′ , g y c k ′ c k ′ g_{xy}^{c_{k}'}, g_{xc_{k}'}^{c_{k}'}, g_{yc_{k}'}^{c_{k}'} gxyck′,gxck′ck′,gyck′ck′, ∑ k = 0 K / 3 − 1 \sum_{k=0}^{K/3 - 1} ∑k=0K/3−1代表求和操作,遍历所有双边网格( K K K为网格总数,按3个一组分配到RGB通道, X ( c , x , y ) X_{(c, x, y)} X(c,x,y)代表原始输入图像在通道 c c c、坐标 ( x , y ) (x, y) (x,y)处的像素值(未预处理), Y ( c , x , y ) Y_{(c, x, y)} Y(c,x,y)代表最终增强后的像素值。
2.4 损失函数
如下所示: L = L m s e + λ c ⋅ L c + λ p ⋅ L p \mathcal{L} = \mathcal{L}{mse} + \lambda{c} \cdot \mathcal{L}{c} + \lambda{p} \cdot \mathcal{L}{p} L=Lmse+λc⋅Lc+λp⋅Lp其中, L \mathcal{L} L为总损失, L m s e \mathcal{L}{mse} Lmse为均方误差损失,计算增强后图像 Y Y Y与Ground Truth的像素级MSE,确保图像保真度, L c \mathcal{L}{c} Lc为CIE94 LAB颜色空间色差损失,计算 Y Y Y与Ground Truth在LAB空间的距离,确保颜色准确性, L p \mathcal{L}{p} Lp为LPIPS感知损失,基于预训练AlexNet计算特征级差异,确保增强图像的感知质量, λ c = 0.005 \lambda_{c} = 0.005 λc=0.005为 L c \mathcal{L}{c} Lc的权重超参数, λ p = 0.05 \lambda{p} = 0.05 λp=0.05: L p \mathcal{L}_{p} Lp的权重超参数。
三、实验结果
首先讲一下消融实验 。实验结果如下图所示,结论如下:
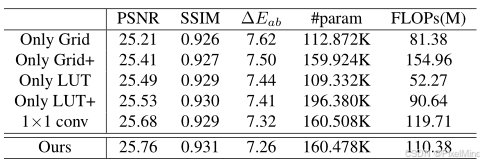
- 单独使用网格(仅 Grid)或 LUT(仅 LUT)时,PSNR 分别为 25.21dB、25.49dB;二者组合(含 1×1 卷积)后 PSNR 提升至 25.68dB,完整 SVDLUT(移除 1×1 卷积)达 25.76dB,证明空间信息(网格)与颜色转换(LUT)需协同才能发挥最佳性能;
- 1×1 卷积冗余且影响效率:含 1×1 卷积的配置虽参数与完整 SVDLUT 接近(160.5K vs 160.478K),但 PSNR 低 0.08dB、FLOPs 高 9.33M,证明 2D 组件的加权和已能替代卷积的融合作用,且更高效;
- 参数匹配不代表性能最优:"仅 Grid+"(参数匹配完整模型)的 PSNR(25.41dB)低于完整 SVDLUT,证明参数数量并非性能关键,合理的结构设计(分解 + 缓存优化)更重要。
接着是定量实验 。
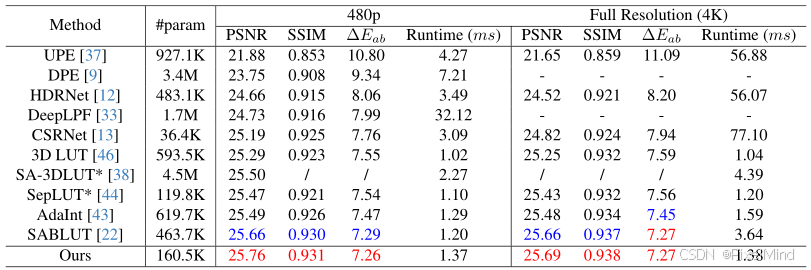
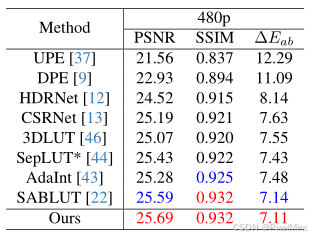
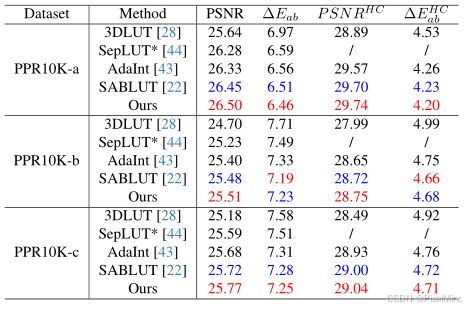
结论:性能最优,效率领先,高分辨率优势显著,在多专家标注下均表现优异。
然后是定性实验 。

整体颜色还原更精准,局部增强能力更强,HDR 动态范围保留更好。
最后做了资源消耗的实验。
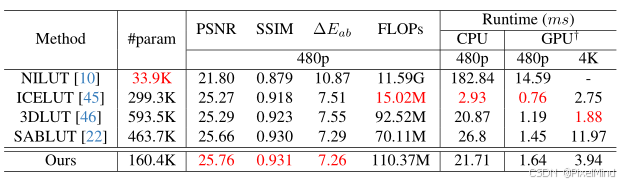
CPU 上效率合理,满足实时性,低成本 GPU 上优势明显,对比其他高效方法更优。
四、总结
SVDLUT 通过 "3D→2D 分解 + SVD 降参 + 缓存高效融合" 的三层优化,在保持空间感知能力与图像增强性能的同时,实现模型轻量化与推理加速,解决了现有空间感知 3D LUT 方法的参数冗余与高分辨率推理慢问题,在多个基准数据集与任务中表现优于主流方法,相较SABLUT来说又进一步的优化了,在CPU和GPU上均可以实时推理,效果也比传统的3DLUT好,因此实用性较高。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。