二.Python 语言高阶加强
一.闭包
在 Python 中,闭包(Closure) 是一种特殊的嵌套函数结构:当一个 内部函数 引用了 外部函数中定义的非全局变量 ,并且外部函数返回了这个内部函数时,就形成了闭包。闭包的核心特点是:内部函数保留了对外部函数变量环境的引用,即使外部函数已经执行完毕,这些变量也不会被销毁。
1.闭包的基本结构
闭包的构成需要满足 3 个条件:
- 存在 嵌套函数(内部函数定义在外部函数内部);
- 内部函数引用了 外部函数中定义的非全局变量(即 "自由变量");
- 外部函数 返回了内部函数(而非调用内部函数)。
示例:最简单的闭包
python
def outer_func(x):
# 外部函数定义变量x
def inner_func(y):
# 内部函数引用外部函数的变量x
return x + y
# 外部函数返回内部函数(不调用)
return inner_func
# 调用外部函数,得到内部函数对象(此时outer_func已执行完毕,但x=10被保留)
closure = outer_func(10)
# 调用内部函数,仍能访问外部函数的x=10
print(closure(5)) # 输出15(10+5)
print(closure(3)) # 输出13(10+3)在这个例子中:
outer_func是外部函数,定义了变量x;inner_func是内部函数,引用了x并返回x+y;outer_func返回inner_func,形成闭包closure;- 即使
outer_func执行完毕,closure仍能访问x=10(变量被 "保留")
2.闭包的核心:保留变量环境
闭包的关键在于 "保留外部函数的变量环境"。普通函数调用结束后,其内部变量会被垃圾回收机制销毁;但闭包中,由于内部函数引用了外部变量,这些变量会被 "绑定" 到内部函数中,持续存在。
可以通过函数的 __closure__ 属性查看闭包保留的变量(返回一个元组,元素是保存变量的单元格对象):
python
print(closure.__closure__) # 输出:(<cell at 0x000001...: int object at 0x...>,)
# 查看保留的变量值
print(closure.__closure__[0].cell_contents) # 输出:10(即外部函数的x=10)3.闭包的典型应用场景
01.保存状态("记忆" 功能)
闭包可以用来保存函数的执行状态,避免使用全局变量。例如实现一个计数器:
python
def make_counter():
count = 0 # 外部函数的变量,被闭包保留
def counter():
nonlocal count # 声明count不是局部变量(需修改外部变量时必须用nonlocal)
count += 1
return count
return counter
# 创建两个独立的计数器(各自保留自己的count)
counter1 = make_counter()
counter2 = make_counter()
print(counter1()) # 1(counter1的count=1)
print(counter1()) # 2(counter1的count=2)
print(counter2()) # 1(counter2的count=1,与counter1独立)- 这里
counter1和counter2是两个独立的闭包,各自保留自己的count变量,互不干扰。
02.数据封装与隐藏
闭包可以隐藏内部变量,只通过返回的函数暴露操作接口,实现类似 "私有变量" 的效果。例如:
python
def make_person(name):
# 隐藏的变量:name和age
age = 0
def get_info():
return f"姓名:{name},年龄:{age}"
def set_age(new_age):
nonlocal age
if new_age > 0:
age = new_age
# 返回操作接口(函数)
return get_info, set_age
# 获取操作函数
get_info, set_age = make_person("Alice")
# 通过接口操作,无法直接访问name和age
set_age(25)
print(get_info()) # 姓名:Alice,年龄:25
set_age(-5) # 无效(内部有校验)
print(get_info()) # 姓名:Alice,年龄:25(age未变)- 这里
name和age无法被直接修改,只能通过set_age接口操作,实现了数据的封装和保护
03.装饰器的基础
Python 的 装饰器(Decorator) 本质上是闭包的一种高级应用。装饰器通过闭包在不修改原函数代码的前提下,动态增强函数功能(如日志、计时、权限校验等)。
简单装饰器示例:
python
def log_decorator(func):
# 外部函数接收被装饰的函数
def wrapper(*args, **kwargs):
# 内部函数增强原函数功能(打印日志)
print(f"调用函数:{func.__name__},参数:{args}, {kwargs}")
result = func(*args, **kwargs) # 调用原函数
return result
return wrapper # 返回增强后的函数
# 用装饰器增强add函数
@log_decorator
def add(a, b):
return a + b
add(3, 5) # 输出:调用函数:add,参数:(3, 5), {}- 这里
log_decorator是一个闭包,wrapper引用了外部的func(被装饰的函数),并返回wrapper作为增强后的函数。
4.注意事项
01.nonlocal 关键字
若内部函数需要 修改 外部函数的变量,必须用 nonlocal 声明(否则会被视为内部函数的局部变量,导致报错)。例如前面的计数器例子,若去掉 nonlocal count,执行 count += 1 会报错(UnboundLocalError)。
二.装饰器
在 Python 中,装饰器(Decorator) 是一种特殊的函数(或类),它的核心作用是:在不修改原函数代码的前提下,动态地为函数(或类)添加额外功能 (如日志记录、性能计时、权限校验等)。装饰器本质上是 "闭包" 的高级应用,体现了 "开放 - 封闭" 原则(对扩展开放,对修改封闭)
1.基本原理
装饰器的工作流程可以概括为:
- 接收一个 被装饰的函数 作为参数;
- 定义一个 包装函数(wrapper),在这个函数中增强原函数的功能(比如在调用原函数前后添加额外逻辑);
- 返回这个包装函数,替代原函数。
2.装饰器的写法
01.装饰器的一般写法(闭包写法)
python
def my_decorator(func):
def wrapper():
print("函数执行前")
func()
print("函数执行后")
return wrapper
def say_hello():
print("Hello!")
# 正确:传递函数对象,不是函数调用的结果
decorator = my_decorator(say_hello) # 注意:没有括号!有括号表示立即调用函数,而不是传递函数
decorator()
# 输出:
# 函数执行前
# Hello!
# 函数执行后02.装饰器语法糖
python
def my_decorator(func):
def wrapper():
print("函数执行前")
func()
print("函数执行后")
return wrapper
@my_decorator # 使用装饰器语法糖
def say_hello():
print("Hello!")
say_hello() # 直接调用,装饰器会自动生效
# 输出:
# 函数执行前
# Hello!
# 函数执行后3.基本用法
01.最简单的装饰器(无参数)
以 "日志记录" 为例,实现一个装饰器,在函数调用前后打印日志
python
# 定义装饰器(本质是一个函数,接收被装饰的函数作为参数)
def log_decorator(func):
# 定义包装函数(增强原函数功能)
def wrapper():
print(f"开始调用函数:{func.__name__}") # 调用前的逻辑
func() # 调用原函数
print(f"函数 {func.__name__} 调用结束\n") # 调用后的逻辑
return wrapper # 返回包装函数
# 使用装饰器:用@符号将装饰器应用到目标函数(语法糖)
@log_decorator # 作用相当于say_hello = log_decorator(say_hello)
def say_hello():
print("Hello, 装饰器!")
# 调用被装饰后的函数
say_hello() # 实际调用的是 wrapper()
# 输出:
"""
开始调用函数:say_hello
Hello, 装饰器!
函数 say_hello 调用结束
"""@log_decorator是语法糖,等价于say_hello = log_decorator(say_hello),即把原函数say_hello传给装饰器,再用返回的wrapper函数替代它。- 调用
say_hello()时,实际执行的是wrapper(),从而在不修改say_hello代码的情况下添加了日志功能。
02.处理带参数的函数
如果被装饰的函数有参数,装饰器的 wrapper 函数需要 通过 *args 和 **kwargs 接收并传递参数,确保通用性
python
def log_decorator(func):
# wrapper接收任意参数,并传递给原函数
def wrapper(*args, **kwargs):
print(f"开始调用 {func.__name__},参数:{args}, {kwargs}")
result = func(*args, **kwargs) # 传递参数给原函数,并接收返回值
print(f"{func.__name__} 调用结束,返回值:{result}\n")
return result # 返回原函数的结果
return wrapper
@log_decorator
def add(a, b):
return a + b
@log_decorator
def greet(name, message="你好"):
return f"{message}, {name}!"
# 调用测试
add(3, 5) # 位置参数
greet("Alice", message="欢迎") # 混合参数
# 输出:
"""
开始调用 add,参数:(3, 5), {}
add 调用结束,返回值:8
开始调用 greet,参数:('Alice',), {'message': '欢迎'}
greet 调用结束,返回值:欢迎, Alice!
"""*args:接收任意数量的位置参数,打包成元组**kwargs:接收任意数量的关键字参数,打包成字典func(*args, **kwargs):将打包的参数解包传递给原函数
03.带参数的装饰器
如果装饰器本身需要参数(比如日志级别、超时时间等),需要在原有装饰器外再套一层 "参数接收函数",返回一个新的装饰器。
例如,实现一个可指定日志级别的装饰器:
python
# 外层函数:接收装饰器的参数(如日志级别)
def log_decorator(level="INFO"):
# 中层函数:接收被装饰的函数(真正的装饰器)
def decorator(func):
# 内层函数:包装逻辑
def wrapper(*args, **kwargs):
print(f"[{level}] 开始调用 {func.__name__}")
result = func(*args, **kwargs)
print(f"[{level}] {func.__name__} 调用结束")
return result
return wrapper
return decorator
# 使用带参数的装饰器:@装饰器名(参数)
@log_decorator(level="DEBUG")
def multiply(a, b):
return a * b
@log_decorator(level="WARNING")
def divide(a, b):
return a / b
# 调用测试
multiply(4, 5)
divide(10, 2)
# 输出:
"""
[DEBUG] 开始调用 multiply
[DEBUG] multiply 调用结束
[WARNING] 开始调用 divide
[WARNING] divide 调用结束
"""@log_decorator(level="DEBUG")等价于multiply = log_decorator(level="DEBUG")(multiply):先调用外层函数得到装饰器decorator,再用它装饰multiply。
04.保留原函数的元信息
装饰器会默认覆盖原函数的元信息(如 __name__、__doc__ 等),例如
python
def decorator(func):
def wrapper():
func()
return wrapper
@decorator
def test():
"""这是test函数的文档字符串"""
pass
print(test.__name__) # 输出:wrapper(被覆盖)
print(test.__doc__) # 输出:None(被覆盖)解决方法 :使用 functools.wraps 装饰 wrapper,保留原函数的元信息
python
import functools
def decorator(func):
@functools.wraps(func) # 保留原函数元信息
def wrapper():
func()
return wrapper
@decorator
def test():
"""这是test函数的文档字符串"""
pass
print(test.__name__) # 输出:test(正确保留)
print(test.__doc__) # 输出:这是test函数的文档字符串(正确保留)三.设计模式
在 Python 中,设计模式是解决特定场景问题的成熟方案,可分为 创建型 、结构型 和 行为型 三大类
最常见、最经典的设计模式,就是我们所学习的面向对象了。
除了面向对象外,在编程中也有很多既定的套路可以方便开发,我们称之为设计模式:
- 创建型:单例、工厂(分为简单工厂、抽象工厂、工厂方法)、建造者/生成器、原型
- 结构型:适配器、桥接、组合、装饰器、外观、享元、代理
- 行为型:策略、责任链、命令、中介者、模板方法、迭代器、访问者、观察者、解释器、备忘录、状态
!QUOTE 参考网址
常用设计模式有哪些?
1.创建型模式
这类模式提供创建对象的机制, 能够提升已有代码的灵活性和可复用性
01.单例模式(Singleton)
核心:确保一个类仅创建一个实例,全局可访问。
适用场景:配置管理器、日志对象、数据库连接池等(避免资源重复占用)。
示例:
通过重写 __new__ 方法控制实例创建
python
class Singleton:
_instance = None # 存储唯一实例, 类变量(不是实例变量)
def __new__(cls, *args, **kwargs):
if not cls._instance: # 如果还没有实例
cls._instance = super().__new__(cls, *args, **kwargs) # 创建新实例
return cls._instance # 返回存储的实例
# 测试:无论创建多少对象,都是同一个实例
s1 = Singleton()
s2 = Singleton()
print(s1 is s2) # 输出:True02.工厂模式
核心:通过工厂类统一创建对象,隐藏具体实现细节。
分类:
- 简单工厂(单一工厂类)
- 工厂方法(子类决定创建逻辑)
- 抽象工厂(创建一系列关联对象)
简单工厂模式
又叫做 静态工厂方法(Static Factory Method)
示例
python
class Circle:
def draw(self):
print("画圆形")
class Rectangle:
def draw(self):
print("画矩形")
class ShapeFactory:
@staticmethod # 表示create_shape 是静态方法,不需要创建工厂实例就能使用
def create_shape(shape_type):
if shape_type == "circle":
return Circle()
elif shape_type == "rectangle":
return Rectangle()
else:
raise ValueError("未知图形类型")
# 使用:无需关心具体类,通过工厂创建
shape = ShapeFactory.create_shape("circle")
shape.draw() # 输出:画圆形工厂方法模式(Factory Method)
核心概念:定义一个创建对象的接口,但让子类决定实例化哪个类。工厂方法让类的实例化推迟到子类。
示例
python
from abc import ABC, abstractmethod
# 产品接口
class Shape(ABC):
@abstractmethod
def draw(self):
pass
# 具体产品
class Circle(Shape):
def draw(self):
print("画圆形")
class Rectangle(Shape):
def draw(self):
print("画矩形")
class Triangle(Shape):
def draw(self):
print("画三角形")
# 抽象创建者
class ShapeFactory(ABC):
@abstractmethod
def create_shape(self) -> Shape:
pass
# 可以包含一些默认操作
def render_shape(self):
shape = self.create_shape()
shape.draw()
return shape
# 具体创建者
class CircleFactory(ShapeFactory):
def create_shape(self) -> Shape:
return Circle()
class RectangleFactory(ShapeFactory):
def create_shape(self) -> Shape:
return Rectangle()
class TriangleFactory(ShapeFactory):
def create_shape(self) -> Shape:
return Triangle()
# 使用
def main():
# 创建圆形
circle_factory = CircleFactory()
circle = circle_factory.create_shape()
circle.draw() # 输出:画圆形
# 或者使用默认操作
rectangle_factory = RectangleFactory()
rectangle_factory.render_shape() # 输出:画矩形
if __name__ == "__main__":
main()抽象工厂模式(Abstract Factory)
核心概念:提供一个接口,用于创建相关或依赖对象的家族,而不需要明确指定具体类
示例
python
from abc import ABC, abstractmethod
# ========== 抽象产品接口 ==========
class Shape(ABC):
@abstractmethod
def draw(self):
pass
class Color(ABC):
@abstractmethod
def fill(self):
pass
# ========== 具体产品 - 形状 ==========
class Circle(Shape):
def draw(self):
print("画圆形")
class Rectangle(Shape):
def draw(self):
print("画矩形")
class Triangle(Shape):
def draw(self):
print("画三角形")
# ========== 具体产品 - 颜色 ==========
class Red(Color):
def fill(self):
print("填充红色")
class Blue(Color):
def fill(self):
print("填充蓝色")
class Green(Color):
def fill(self):
print("填充绿色")
# ========== 抽象工厂 ==========
class AbstractFactory(ABC):
@abstractmethod
def create_shape(self) -> Shape:
pass
@abstractmethod
def create_color(self) -> Color:
pass
# 可以包含一些组合操作
def render_component(self):
shape = self.create_shape()
color = self.create_color()
shape.draw()
color.fill()
return shape, color
# ========== 具体工厂 - 红色圆形系列 ==========
class RedCircleFactory(AbstractFactory):
def create_shape(self) -> Shape:
return Circle()
def create_color(self) -> Color:
return Red()
# ========== 具体工厂 - 蓝色矩形系列 ==========
class BlueRectangleFactory(AbstractFactory):
def create_shape(self) -> Shape:
return Rectangle()
def create_color(self) -> Color:
return Blue()
# ========== 具体工厂 - 绿色三角形系列 ==========
class GreenTriangleFactory(AbstractFactory):
def create_shape(self) -> Shape:
return Triangle()
def create_color(self) -> Color:
return Green()
# ========== 客户端代码 ==========
class GraphicsApplication:
def __init__(self, factory: AbstractFactory):
self.factory = factory
self.shape = None
self.color = None
def create_graphics(self):
self.shape = self.factory.create_shape()
self.color = self.factory.create_color()
def render(self):
print("=== 开始渲染图形 ===")
self.shape.draw()
self.color.fill()
print("=== 渲染完成 ===\n")
# 使用示例
def main():
# 创建红色圆形
print("创建红色圆形:")
red_circle_factory = RedCircleFactory()
app1 = GraphicsApplication(red_circle_factory)
app1.create_graphics()
app1.render()
# 创建蓝色矩形
print("创建蓝色矩形:")
blue_rect_factory = BlueRectangleFactory()
app2 = GraphicsApplication(blue_rect_factory)
app2.create_graphics()
app2.render()
# 创建绿色三角形
print("创建绿色三角形:")
green_triangle_factory = GreenTriangleFactory()
app3 = GraphicsApplication(green_triangle_factory)
app3.create_graphics()
app3.render()
# 直接使用工厂的默认操作
print("直接使用工厂方法:")
red_circle_factory.render_component()
if __name__ == "__main__":
main()三种工厂模式对比
| 模式 | 特点 | 适用场景 |
|---|---|---|
| 简单工厂 | 一个工厂类创建所有产品 | 产品种类少,创建逻辑简单 |
| 工厂方法 | 每个产品对应一个工厂类 | 产品种类多,需要扩展性强 |
| 抽象工厂 | 创建产品族,保证产品兼容性 | 需要创建相关产品家族 |
03.建造者/生成器模式(Builder)
04.原型模式(Prototype)
2.结构型模式
这类模式介绍如何将对象和类组装成较大的结构, 并同时保持结构的灵活和高效
01.适配器模式(Adapter)
02.桥接模式(Bridge)
03.组合模式(Composite)
04.装饰器模式(Decorator)
05.外观模式(Facade)
06.享元模式(Flyweight)
07.代理模式(Proxy)
3.行为型模式
这类模式负责对象间的高效沟通和职责委派
01.策略模式(Strategy)
02.责任链模式(Chain of Responsibility)
03.命令模式(Command)
04.中介者模式(Mediator)
05.模板方法模式( Template Method)
06.迭代器模式(Iterator)
07.访问者模式(Visitor)
08.观察者模式(Observer)
09.解释器模式(Interpreter)
10.备忘录模式(Memento)
11.状态模式(State)
四.多线程
进程和线程
1.基本概念
- 进程 (Process):就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程 ID 方便系统管理
- 线程 (Thread):线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
操作系统中可以运行多个进程,即 多任务运行 。
一个进程内可以运行多个线程,即 多线程运行。
现代操作系统比如 Mac OS ×, UNIX, Linux, Windows 等,都是支持"多任务"的操作系统。
2.详细比喻
厨房比喻
- 进程 = 整个厨房(有独立的食材区、厨具、工作人员)
- 线程 = 厨房里的厨师(共享厨房资源,但各自做不同的菜)
工厂比喻
- 进程 = 整个工厂(有独立的厂房、原料仓库、生产线)
- 线程 = 工厂里的工人(共享工厂资源,在各自工位上工作)
3.注意事项
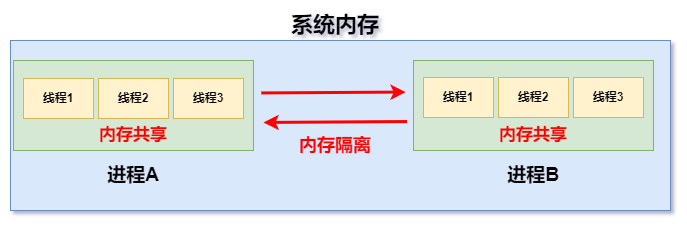
-
进程之间是内存隔离的 ,即 不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所。
-
线程之间是内存共享的 ,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的。这就好比,公司员工之间是共享公司的办公场所。
4.并行执行
并行执行的意思指的是同一时间做不同的工作
进程之间就是并行执行的 ,操作系统可以同时运行好多程序,这些程序都在并行执行,可以称为 多任务并行执行
除了进程外,线程其实也是可以并行执行 的。
也就是比如一个 Python 程序,其实是完全可以做到:
- 一个线程在输出:你好
- 一个线程在输出:Hello
像这样一个程序在同一时间做两件乃至多件不同的事情 ,我们就称之为:多线程并行执行
多线程编程
Python 的多线程基于 threading 模块实现 ,threading 是 Python 内置的多线程模块,提供了创建和管理线程的接口。
1.适用场景
- 适合:网络请求、文件读写、数据库操作等 I/O 密集型任务。
- 不适合:大规模计算、数据处理等 CPU 密集型任务(建议用多进程
multiprocessing)
2.创建线程的两种方式
01.直接使用 threading.Thread
通过传入 target(要执行的函数)和 args(函数参数)创建线程
语法
python
import threading
# 1. 定义一个在线程中要运行的函数
def my_task(arg1, arg2):
print(f"线程正在运行,参数是: {arg1}, {arg2}")
# 模拟耗时操作
import time
time.sleep(2)
print("线程结束")
# 2. 创建线程对象
# target: 指定要运行的函数
# args: 传递给函数的参数(必须是元组)
# kwargs: 传递给函数的关键字参数(字典)
t = threading.Thread(target=my_task, args=("Hello", "World"), kwargs={})
# 3. 启动线程
# 注意:start() 是启动,不是 run()。
# start() 会让新的线程开始执行 target 函数。
t.start()
# 4. 等待线程结束 (可选)
# 主线程会阻塞在这里,直到线程 t 执行完毕。
t.join()
print("主线程结束")threading.Thread(): 构造函数,创建线程对象。target: 线程要执行的目标函数。args: 传给目标函数的参数,是一个 元组 。如果只有一个参数,要写成(arg1,)。start(): 启动 线程。调用后,解释器会创建新的线程,并在其中执行target函数。join([timeout]): 等待 线程结束。timeout是可选的超时时间(秒)。如果不调用join,主线程不会等待子线程结束。
02.继承 threading.Thread 类并重写 run() 方法
重写 run() 方法(线程启动后会自动执行 run())
语法
python
import threading
# 1. 自定义一个类,继承自 threading.Thread
class MyThread(threading.Thread):
def __init__(self, arg1, arg2):
# 必须调用父类的初始化方法
super().__init__()
self.arg1 = arg1
self.arg2 = arg2
# 2. 必须重写 run() 方法
# run() 方法就是线程启动后真正执行的代码
def run(self):
print(f"线程正在运行,参数是: {self.arg1}, {self.arg2}")
import time
time.sleep(2)
print("线程结束")
# 3. 创建自定义线程类的实例
t = MyThread("Hello", "Class")
# 4. 启动线程
# 注意:仍然是调用 start(),它会自动去调用你重写的 run() 方法。
# 千万不要直接调用 t.run()!那样它会在主线程中运行,而不是新线程。
t.start()
# 5. 等待线程结束
t.join()
print("主线程结束")- 继承
threading.Thread。 - 重写
run()方法,这里放你的业务逻辑。 - 实例化你的类,并调用
start()来启动。start()方法内部会调用你重写的run()
3.线程的核心操作
start():启动线程(触发run()方法执行)。join(timeout=None):主线程等待该线程结束(timeout为最长等待时间,单位秒)。daemon:设置为守护线程(t.daemon = True),主线程结束时守护线程会被强制终止(默认非守护线程,主线程会等待其结束)。name:线程名称(可通过threading.current_thread().name获取当前线程名称)。
4.线程同步
当多个线程需要访问和修改同一个共享资源时,会发生数据竞争,导致结果不可预测。锁用于确保一次只有一个线程可以执行特定的代码块(临界区)
01.Lock(互斥锁)
最常用的同步工具,确保同一时刻只有一个线程执行临界区代码:
python
import threading
# 共享资源
counter = 0
# 创建一个锁对象
lock = threading.Lock()
def increment():
global counter
for _ in range(100000):
# 在修改共享资源前获取锁
lock.acquire()
try:
counter += 1 # 临界区
finally:
# 无论如何,最后都要释放锁
lock.release()
# 创建多个线程
threads = []
for i in range(5):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print(f"最终的计数器值: {counter}") # 应该是 500000使用 with 语句(推荐):
Lock 对象支持上下文管理器协议,使用 with 语句可以自动获取和释放锁,更安全、更简洁
python
# ❌ 传统写法:容易漏掉 release()
def increment():
global counter
for _ in range(100000):
# 在修改共享资源前获取锁
lock.acquire()
try:
counter += 1 # 临界区
finally:
# 无论如何,最后都要释放锁
lock.release()
# ✅ with 写法:一行搞定,异常也不怕
def increment():
global counter
for _ in range(100000):
with lock: # 自动 acquire 和 release
counter += 102.其他同步工具
RLock(可重入锁):允许同一线程多次获取锁(避免自身死锁)。Semaphore(信号量):限制同时访问资源的线程数量(如控制并发连接数)。Event(事件):通过set()/clear()控制线程的等待 / 唤醒(如 "主线程通知子线程开始工作")。Condition(条件变量):更灵活的同步,线程可等待特定条件满足后再执行。
5.守护线程 (Daemon Thread)
守护线程是一种在后台运行的线程,它的生命周期依赖于主线程。当所有非守护线程(包括主线程)结束时,无论守护线程是否完成,程序都会退出
语法
python
def daemon_task():
import time
while True:
print("守护线程在后台运行...")
time.sleep(1)
# 创建线程时设置 daemon=True
t = threading.Thread(target=daemon_task, daemon=True)
t.start()
# 主线程做一些事情
import time
time.sleep(3)
print("主线程结束,程序将立即退出,不会等待守护线程。")- 通过
daemon=True参数或在创建后设置t.daemon = True来定义守护线程。 - 主线程退出时,不会等待守护线程完成。
6.线程间通信:队列 (Queue)
queue.Queue 是线程安全的数据结构,是线程间通信的首选方式。它实现了生产者-消费者模型
语法
python
import threading
import queue
import time
import random
# 创建一个队列
q = queue.Queue()
# 生产者函数
def producer():
for i in range(5):
item = f"产品 {i}"
q.put(item) # 向队列中放入数据
print(f"生产了: {item}")
time.sleep(random.random())
# 消费者函数
def consumer():
while True:
item = q.get() # 从队列中获取数据,如果队列为空则会阻塞
if item is None: # 一个常见的终止信号
break
print(f"消费了: {item}")
q.task_done() # 告诉队列,这个任务已经处理完了
# 创建线程
p = threading.Thread(target=producer)
c = threading.Thread(target=consumer)
c.start()
p.start()
# 等待生产者生产完所有东西
p.join()
# 发送终止信号给消费者
q.put(None)
# 等待消费者结束
c.join()
print("所有任务完成")Queue 常用方法:
q.put(item): 放入项目。q.get(): 取出并移除一个项目。如果队列为空,会阻塞。q.task_done(): 消费者调用,表示一个入队任务已完成。q.join(): 阻塞,直到队列中的所有项目都被处理(即每个put都对应了一个task_done)
7.线程池:ThreadPoolExecutor
频繁创建 / 销毁线程会消耗资源,线程池可复用线程,提升效率。concurrent.futures.ThreadPoolExecutor 是高级接口,简化线程池管理
python
from concurrent.futures import ThreadPoolExecutor
import time
def task(n):
time.sleep(1) # 模拟I/O操作
return n * 2
# 创建线程池(最多5个线程)
with ThreadPoolExecutor(max_workers=5) as executor:
# 提交任务(两种方式)
# 方式1:map批量提交(返回结果顺序与任务顺序一致)
results = executor.map(task, [1, 2, 3, 4, 5])
print(list(results)) # [2,4,6,8,10]
# 方式2:submit单个提交(返回Future对象,可获取结果)
futures = [executor.submit(task, i) for i in range(6, 11)]
for future in futures:
print(future.result()) # 6*2=12, ..., 10*2=208.关键概念解释
1. GIL(全局解释器锁)
python
time.sleep(delay) # 模拟I/O操作(此时GIL会释放)- GIL 是什么: Python 解释器中的一把锁,确保同一时刻只有一个线程执行 Python 字节码
- I/O 操作: 在执行 I/O 操作(sleep、文件读写、网络请求)时,GIL 会被释放,其他线程可以获得执行权
- 影响 :
- 在 I/O 密集型任务中,多线程能有效提升性能
- 在 CPU 密集型任务中,多线程由于 GIL 限制无法真正并行
2. 线程状态转换
text
新建 → 就绪 → 运行 → 阻塞(I/O) → 就绪 → 运行 → 终止
start() 调度执行 sleep() 唤醒 调度执行 完成3. 线程生命周期
- 新建:新创建一个线程对象,但未 start
- 就绪:用 start 方法后,线程对象等待运行,什么时候开始运行取决于调度
- 运行:程处于运行状态
- 阻塞:处于运行状态的线程被堵塞,通俗理解就是被卡住了,可能的原因包括但不限于程序自身调用 sleep 方法阻塞线程运行,或调用了一个阻塞式 I/O 方法,被阻塞的进程会等待何时解除阻塞重新运行
- 终止:函数执行完毕,线程执行完毕或异常退出,线程对象被销毁并释放内存
4.主线程和子线程
我们讲的多线程实际上指的就是只在主线程中运行多个子线程,而主线程就是我们的 Python 编译器执行的线程,所有子线程和主线程都同属于一个进程。在未添加子线程的情况下,默认就只有一个主线程在运行,他会将我们写的代码从开头到结尾执行一遍,后文中我们也会提到一些主线程与子线程的关系。
9.总结
| 概念 | 语法/类 | 说明 |
|---|---|---|
| 创建线程 | threading.Thread(target=func, args=()) |
函数式创建 |
继承 Thread 类,重写 run() 方法 |
面向对象式创建 | |
| 启动线程 | thread.start() |
创建新线程并运行 |
| 等待线程 | thread.join([timeout]) |
主线程等待子线程结束 |
| 线程锁 | threading.Lock() |
保证线程安全,防止竞争条件 |
| 守护线程 | threading.Thread(daemon=True) |
随主线程结束而强制结束 |
| 线程通信 | queue.Queue() |
线程安全的队列,用于生产者-消费者模型 |
五.网络编程
Python 网络编程是指通过 Python 实现网络中不同设备、程序之间的数据传输与交互,核心涉及 套接字(Socket)编程 、HTTP 通信 、网络协议处理 等
1.套接字(Socket)
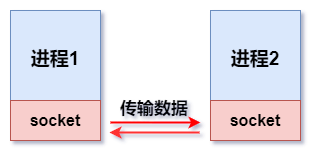
套接字是网络编程的基石,用于描述 IP 地址和端口,是进程间通信的端点 。Python 通过内置的 socket 模块提供套接字操作,支持 TCP 和 UDP 两种主流传输协议。
Socket 负责进程之间的网络数据传输,好比数据的搬运工
客户端和服务端
2 个进程之间通过 Socket 进行相互通讯,就必须有 服务端和客户端:
- Socket 服务端 :等待其它进程的连接,可接受发来的消息、可以回复消息
- Socket 客户端 :主动连接服务端,可以发送消息、可以接收回复
基本语法
01.导入 socket 模块
python
import socket02. 创建套接字
python
# 基本语法
socket.socket(family, type, proto)
# 常用创建方式
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)参数说明:
family:地址族socket.AF_INET:IPv4(最常用)socket.AF_INET6:IPv6socket.AF_UNIX:Unix 域套接字
type:套接字类型socket.SOCK_STREAM:TCP 流式套接字socket.SOCK_DGRAM:UDP 数据报套接字
proto:协议号(通常为 0,自动选择)
03.服务器端核心方法
-
bind() - 绑定地址
python# 语法 socket.bind(address) # 示例 server_addr = (host, port) # 指定ip和端口 server_addr = ("", 8888) # 监听所有网卡 server_addr = ("127.0.0.1", 8888) # 仅监听本地 server_socket.bind(server_addr) -
listen() - 开始监听
python# 语法 socket.listen([backlog]) # backlog为int整数,表示允许的连接数量,超出的会等待,可以不填,不填会自动设置一个合理值 # 示例 server_socket.listen(5) # 最多5个连接在队列中等待 -
accept() - 接受连接
python# 语法 client_socket, client_addr = socket.accept() # accept方法是阻塞方法,如果没有连接,会卡再当前这一行不向下执行代码 # accept返回的是一个二元元组,可以使用上述形式,用两个变量接收二元元组的2个元素 # 示例 client_socket, client_addr = server_socket.accept() # client_socket: 新的客户端套接字 # client_addr: 客户端地址 (ip, port)
04.客户端核心方法
-
connect() - 连接服务器
python# 语法 socket.connect(address) # 示例 server_addr = ("192.168.1.100", 8888) client_socket.connect(server_addr)
05.数据传输方法(客户端和服务端通用)
-
send() - 发送数据
python# 语法 bytes_sent = socket.send(data) # 示例 message = "Hello" bytes_sent = client_socket.send(message.encode('utf-8')) # 使用UTF-8把字符串编码成字节数据 -
recv() - 接收数据
python# 语法 data = socket.recv(bufsize) # recv方法的返回值是字节数组(Bytes),可以通过decode使用UTF-8解码为字符串 # recv方法的传参是buffsize,缓冲区大小,一般设置为1024即可 # 示例 data = client_socket.recv(1024) # 最多接收1024字节 received_message = data.decode('utf-8') # 使用UTF-8把字节数据解码为字符串
06. 关闭连接
python
# 语法
socket.close()
# 示例
client_socket.close()
server_socket.close()07.地址格式
python
# IPv4 地址格式
address = (ip_address, port)
# 示例
local_addr = ("127.0.0.1", 8080) # 本地回环
any_addr = ("", 8080) # 所有接口
specific_addr = ("192.168.1.100", 8080) # 特定IP08.字符串与字节转换
python
# 字符串 → 字节(编码)
text = "Hello World"
byte_data = text.encode('utf-8') # 常用
byte_data = text.encode('ascii') # ASCII编码
# 字节 → 字符串(解码)
byte_data = b"Hello World"
text = byte_data.decode('utf-8')
text = byte_data.decode('ascii')TCP 协议(面向连接,可靠传输)
TCP 需要先建立连接(三次握手),适合数据完整性要求高的场景(如文件传输、登录)。
TCP 服务端示例:
python
import socket
# 1. 创建TCP套接字(IPv4,TCP)
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2. 绑定IP和端口(IP为空表示监听所有网卡,端口选1024以上非特权端口)
server_addr = ("", 8888) # ("127.0.0.1", 8888) 仅本地访问
server_socket.bind(server_addr)
# 3. 监听连接(最大等待队列长度为5)
server_socket.listen(5)
print("服务器启动,等待连接...")
while True:
# 4. 接受客户端连接(阻塞等待)
client_socket, client_addr = server_socket.accept()
print(f"接收到来自 {client_addr} 的连接")
try:
# 5. 接收客户端数据(最多1024字节)
data = client_socket.recv(1024)
if data:
print(f"收到数据:{data.decode('utf-8')}")
# 6. 回复客户端
client_socket.send("收到消息!".encode('utf-8'))
finally:
# 7. 关闭客户端连接
client_socket.close()
# (实际中需手动终止服务器,如Ctrl+C)
# server_socket.close()TCP 客户端示例:
python
import socket
# 1. 创建TCP套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2. 连接服务器
server_addr = ("127.0.0.1", 8888) # 服务器IP和端口
client_socket.connect(server_addr)
try:
# 3. 发送数据
client_socket.send("Hello Server!".encode('utf-8'))
# 4. 接收服务器回复
data = client_socket.recv(1024)
print(f"服务器回复:{data.decode('utf-8')}")
finally:
# 5. 关闭连接
client_socket.close()UDP 协议(无连接,快速传输)
UDP 无需建立连接,直接发送数据报,适合实时性要求高的场景(如视频通话、广播),但可能丢包。
UDP 服务端示例:
python
import socket
# 1. 创建UDP套接字(IPv4,UDP)
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2. 绑定IP和端口
server_addr = ("", 9999)
server_socket.bind(server_addr)
print("UDP服务器启动,等待数据...")
while True:
# 3. 接收数据(返回数据和客户端地址)
data, client_addr = server_socket.recvfrom(1024)
print(f"收到 {client_addr} 的数据:{data.decode('utf-8')}")
# 4. 回复客户端
server_socket.sendto("收到UDP消息!".encode('utf-8'), client_addr)UDP 客户端示例:
python
import socket
# 1. 创建UDP套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_addr = ("127.0.0.1", 9999)
# 2. 直接发送数据(无需连接)
client_socket.sendto("Hello UDP Server!".encode('utf-8'), server_addr)
# 3. 接收回复
data, server_addr = client_socket.recvfrom(1024)
print(f"服务器回复:{data.decode('utf-8')}")
# 4. 关闭套接字
client_socket.close()六.正则表达式
正则表达式(Regular Expression)是一种用于匹配、查找、替换字符串中特定模式的工具,广泛应用于文本处理、数据验证、信息提取等场景。Python 通过内置的 re 模块提供对正则表达式的支持。
简单来说,正则表达式就是使用字符串定义规则,并通过规则去验证字符串是否匹配。
1.基础语法
正则表达式由 普通字符 (如 a、1)和 元字符(具有特殊含义的字符)组成,以下是常用元字符及规则:
01. 普通字符与简单匹配
普通字符(字母、数字、符号)直接匹配自身:
- 正则
"abc"可匹配字符串"abc"、"xabcy"中的"abc"部分 - 大小写敏感(可使用
i修饰符忽略大小写)
02. 元字符(核心规则)
| 元字符 | 含义 | Python 示例 |
|---|---|---|
. |
匹配任意单个字符(除换行符\n) |
re.findall(r"a.c", "abc adc aec") → ['abc', 'adc', 'aec'] |
^ |
匹配字符串开头 | re.findall(r"^abc", "abc def") → ['abc'] |
$ |
匹配字符串结尾 | re.findall(r"def$", "abc def") → ['def'] |
* |
前一个字符 0 次或多次 | re.findall(r"ab*c", "ac abc abbc") → ['ac', 'abc', 'abbc'] |
+ |
前一个字符 1 次或多次 | re.findall(r"ab+c", "abc abbc") → ['abc', 'abbc'] |
? |
前一个字符 0 次或 1 次 | re.findall(r"ab?c", "ac abc") → ['ac', 'abc'] |
{n} |
前一个字符恰好 n 次 | re.findall(r"a{3}", "aaa aaaa") → ['aaa', 'aaa'] |
{n,} |
前一个字符至少 n 次 | re.findall(r"a{2,}", "a aa aaa") → ['aa', 'aaa'] |
{n,m} |
前一个字符 n 到 m 次 | re.findall(r"a{2,3}", "a aa aaa aaaa") → ['aa', 'aaa', 'aaa'] |
[] |
字符集 | re.findall(r"[aeiou]", "hello") → ['e', 'o'] |
[^] |
否定字符集 | re.findall(r"[^aeiou]", "hello") → ['h', 'l', 'l'] |
| ` | ` | 或 |
() |
分组 | re.findall(r"(ab)+", "ababab") → ['ab'] |
\ |
转义 | re.findall(r"\.", "a.b") → ['.'] |
- 字符串的
r标记,表示当前字符串是原始字符串,即内部的转义字符无效而是普通字符
2. 预定义字符集
| 字符 | 含义 | Python 示例 |
|---|---|---|
\d |
数字 [0-9] |
re.findall(r"\d+", "123 abc") → ['123'] |
\D |
非数字 [^0-9] |
re.findall(r"\D+", "123 abc") → [' abc'] |
\w |
单词字符 [a-zA-Z0-9_] |
re.findall(r"\w+", "hello_world 123!") → ['hello_world', '123'] |
\W |
非单词字符 | re.findall(r"\W+", "hello world!") → [' ', '!'] |
\s |
空白字符 | re.findall(r"\s+", "hello world") → [' '] |
\S |
非空白字符 | re.findall(r"\S+", "hello world") → ['hello', 'world'] |
\b |
单词边界 | re.findall(r"\bhello\b", "hello world") → ['hello'] |
\B |
非单词边界 | re.findall(r"\Bhello\B", "ahellob") → ['hello'] |
3.re 模块函数
re 模块提供了多个函数执行匹配操作,核心如下:
01. re.match(pattern, string, flags=0)
-
功能 :从字符串 开头 匹配模式,若开头不匹配则返回
None。 -
返回值 :匹配成功返回
Match对象(包含匹配信息),否则None。 -
示例
python# 匹配以"hello"开头的字符串 result = re.match(r"hello", "hello world") print(result) # 输出: <re.Match object; span=(0, 5), match='hello'> print(result.group()) # 输出:hello(获取匹配的内容) print(result.span()) # 输出:(0, 5)(匹配的起始和结束索引) # 不匹配的情况(开头不是"hi") result = re.match(r"hi", "hello hi") print(result) # 输出:None
02. re.search(pattern, string, flags=0)
-
功能 :在整个字符串中搜索 第一个 匹配的子串(无需从开头开始)。
-
与
match的区别 :match仅匹配开头,search匹配任意位置的第一个结果。 -
示例
python# 在字符串中搜索"world" result = re.search(r"world", "hello world") print(result.group()) # 输出:world print(result.span()) # 输出:(6, 11)
03. re.findall(pattern, string, flags=0)
-
功能 :查找字符串中 所有 匹配的子串,返回列表(无匹配则返回空列表)。
-
示例
python# 提取所有数字 text = "年龄:25,身高:180cm,体重:70kg" nums = re.findall(r"\d+", text) # \d+匹配1个及以上数字 print(nums) # 输出:['25', '180', '70']
04. re.finditer(pattern, string, flags=0)
-
功能 :类似
findall,但返回 迭代器 (每个元素是Match对象),适合处理大量结果(节省内存)。 -
示例
pythontext = "a1b2c3" iter_result = re.finditer(r"\d", text) # 匹配单个数字 for m in iter_result: print(m.group(), m.span()) # 输出每个数字及其位置 # 输出: # 1 (1, 2) # 2 (3, 4) # 3 (5, 6)
05. re.sub(pattern, repl, string, count=0, flags=0)
-
功能:替换字符串中所有匹配的子串,返回替换后的新字符串。
-
参数 :
repl为替换内容(可为字符串或函数),count指定最大替换次数(0 表示全部)。 -
示例
python# 将所有数字替换为* text = "密码:123456,验证码:789" new_text = re.sub(r"\d", "*", text) print(new_text) # 输出:密码:******,验证码:*** # 用函数处理替换(将数字加1) def add_one(match): num = int(match.group()) return str(num + 1) text = "a1 b3 c5" new_text = re.sub(r"\d", add_one, text) print(new_text) # 输出:a2 b4 c6
06. re.compile(pattern, flags=0)
-
功能 :编译正则表达式为
Pattern对象,可重复使用(提高多次匹配的效率)。 -
示例
python# 编译正则(匹配邮箱) pattern = re.compile(r"\w+@\w+\.\w+") # 简单邮箱规则 # 重复使用编译后的对象 text1 = "我的邮箱是test@example.com" text2 = "联系我:abc123@qq.com" print(pattern.findall(text1)) # 输出:['test@example.com'] print(pattern.findall(text2)) # 输出:['abc123@qq.com']
4. 分组与捕获
捕获分组
-
(pattern)- 创建捕获分组 -
按左括号顺序编号:
\1,\2...(在正则中反向引用)或$1,$2...(在替换中使用) -
示例
pythonimport re # 基础分组 match = re.search(r"(\d{3})-(\d{4})", "电话:010-1234") print(match.groups()) # ('010', '1234') print(match.group(1)) # '010' print(match.group(2)) # '1234' # 重复分组 match = re.search(r"(\w+) \1", "hello hello world") print(match.group()) # 'hello hello'
非捕获分组 (?:pattern)
-
(?:pattern)- 只分组不捕获 -
示例
python# 不捕获分组内容 match = re.search(r"(?:\d{3})-(\d{4})", "010-1234") print(match.groups()) # ('1234',) - 只捕获后半部分
命名分组 (?P<name>pattern)
-
(?P<name>pattern)- Python 语法 -
(?<name>pattern)或(?'name'pattern)- 其他语言 -
引用:
(?P=name)(Python)或\k<name>(其他) -
示例
pythonmatch = re.search(r"(?P<area>\d{3})-(?P<number>\d{4})", "010-1234") print(match.groupdict()) # {'area': '010', 'number': '1234'} print(match.group('area')) # '010' print(match.group('number')) # '1234' # 引用命名分组 match = re.search(r"(?P<word>\w+) (?P=word)", "hello hello") print(match.group()) # 'hello hello'
5. 贪婪 vs 非贪婪匹配
-
贪婪模式 (默认):元字符
*/+/{n,m}会尽可能匹配更多字符。 -
非贪婪模式 :在元字符后加
?,改为尽可能匹配更少字符。 -
示例
pythontext = "<div>内容1</div><div>内容2</div>" # 贪婪模式:.*会匹配从第一个<div>到最后一个</div>的所有内容 greedy = re.findall(r"<div>.*</div>", text) print(greedy) # 输出:['<div>内容1</div><div>内容2</div>'] # 非贪婪模式:.*?匹配到第一个</div>就停止 non_greedy = re.findall(r"<div>.*?</div>", text) print(non_greedy) # 输出:['<div>内容1</div>', '<div>内容2</div>']
| 模式 | 含义 | 示例 |
|---|---|---|
*, +, ?, {n,m} |
贪婪模式:尽可能多匹配 | a.*b 匹配 "axxxbxxxb" 中的整个字符串 |
*?, +?, ??, {n,m}? |
非贪婪模式:尽可能少匹配 | a.*?b 匹配 "axxxbxxxb" 中的 "axxxb" |
示例:
regex
文本:<div>content1</div><div>content2</div>
正则:<div>.*</div> # 匹配整个字符串
正则:<div>.*?</div> # 只匹配第一个 <div>content1</div>6.模式修饰符(flags 参数)
| 标志 | 含义 | 示例 |
|---|---|---|
re.IGNORECASE / re.I |
忽略大小写 | re.findall(r"abc", "ABC", re.I) → ['ABC'] |
re.MULTILINE / re.M |
多行模式 | re.findall(r"^\d+", "1\n2\n3", re.M) → ['1', '2', '3'] |
re.DOTALL / re.S |
让 . 匹配换行符 |
re.findall(r"a.b", "a\nb", re.S) → ['a\nb'] |
re.VERBOSE / re.X |
忽略空白和注释 | 允许编写带注释的正则 |
re.ASCII / re.A |
让 \w, \b 等只匹配 ASCII |
re.findall(r"\w+", "café", re.A) → ['caf'] |
示例
python
import re
# 多标志组合使用
text = "Hello\nWorld\n123"
pattern = re.compile(r"^[a-z]+", re.I | re.M)
results = pattern.findall(text)
print(results) # ['Hello', 'World']
# 详细模式(带注释)
pattern = re.compile(r"""
\b # 单词边界
[A-Z][a-z]* # 首字母大写,后跟小写字母
\b # 单词边界
""", re.VERBOSE)
results = pattern.findall("Hello World from Python")
print(results) # ['Hello', 'World', 'Python']7. 字符集详解
基本字符集
[abc]- 匹配 a、b 或 c[a-z]- 匹配小写字母 a 到 z[A-Z]- 匹配大写字母 A 到 Z[0-9]- 匹配数字 0 到 9[a-zA-Z]- 匹配所有字母
特殊字符在字符集中
在字符集 [] 中,大多数元字符失去特殊含义:
[.*+?]- 匹配字面意义上的 . * + ?[\\\]]- 匹配 \ 或 ](需要转义)[\[\]]- 匹配 或
8. 零宽断言(预查)
| 断言类型 | 语法 | 含义 | Python 示例 |
|---|---|---|---|
| 正向先行断言 | (?=pattern) |
后面必须跟着 pattern | re.findall(r"\w+(?=元)", "100元 200美元") → ['100'] |
| 负向先行断言 | (?!pattern) |
后面不能跟着 pattern | re.findall(r"\d{3}(?!\d)", "123 1234") → ['123'] |
| 正向后行断言 | (?<=pattern) |
前面必须是 pattern | re.findall(r"(?<=\$)\d+", "$100 ¥200") → ['100'] |
| 负向后行断言 | (?<!pattern) |
前面不能是 pattern | re.findall(r"(?<![-+])\d+", "100 +200 -300") → ['100'] |
示例:
regex
\d+(?=元) # 匹配后面跟着"元"的数字
\d{3}(?!\d) # 匹配3位数字且后面不能是数字
(?<=\$)\d+ # 匹配前面有$的数字
(?<![-+])\d+ # 匹配前面没有+或-的数字七.递归
在 Python 中,递归(Recursion) 是一种函数调用自身的编程技巧。它的核心思想是:将一个复杂问题分解为与原问题结构相似但规模更小的子问题,通过解决子问题最终得到原问题的解。
基本要素
- 基本情况:递归终止的条件
- 递归情况:函数调用自身的部分
- 向基本情况推进:每次递归调用都应该使问题更接近基本情况
注意事项
- 注意退出的条件,否则容易变成无限递归
- 注意返回值的传递,确保从最内层,层层传递到最外层
简单例子
1.计算阶乘
示例
python
def factorial(n):
# 基本情况
if n == 0 or n == 1:
return 1
# 递归情况
else:
return n * factorial(n - 1)
# 测试
print(factorial(5)) # 输出: 120解释
调用栈展开过程:
text
factorial(5)
= 5 * factorial(4)
= 5 * (4 * factorial(3))
= 5 * (4 * (3 * factorial(2)))
= 5 * (4 * (3 * (2 * factorial(1))))
= 5 * (4 * (3 * (2 * 1)))
= 120- 当n=1时,factorial(1) = 1
2.斐波那契数列
示例
python
def fibonacci(n):
# 基本情况
if n <= 1:
return n
# 递归情况
else:
return fibonacci(n - 1) + fibonacci(n - 2)
# 测试
for i in range(6): # [0,1,2,3,4,5]
print(fibonacci(i), end=" ")
# 输出: 0 1 1 2 3 5解释
- n = 0时,输出:0
- n = 1时,输出:1
- n = 2时,输出:1
- n = 3时,输出:2
- n = 4时,输出:3
- n = 5时,输出:5
调用栈展开过程:
python
fibonacci(5)
= fibonacci(4) + fibonacci(3)
= [fibonacci(3) + fibonacci(2)] + [fibonacci(2) + fibonacci(1)]
= [(fibonacci(2) + fibonacci(1)) + (fibonacci(1) + fibonacci(0))] + [(fibonacci(1) + fibonacci(0)) + 1]
= [((fibonacci(1) + fibonacci(0))+ 1) + (1 + 0)] + [(1 + 0) + 1]
= [((1 + 0) + 1) + 1] + 2
= 3 + 2
= 5关键概念对比
| 特性 | 阶乘递归 | 斐波那契递归 |
|---|---|---|
| 基本情况 | n=0 或 n=1 | n=0 或 n=1 |
| 递归调用次数 | 1次 (n-1) | 2次 (n-1 和 n-2) |
| 时间复杂度 | O(n) | O(2^n) - 指数级 |
| 空间复杂度 | O(n) | O(n) |
| 重复计算 | 无 | 大量重复计算 |