目录
[五、它们如何在优化中协作(以 Adam 为例)](#五、它们如何在优化中协作(以 Adam 为例))
Adam优化器是深度学习框架Pytorch中常用的一个优化器,其主要包含了参数,梯度,一阶动量,二阶动量这四个部分。
一、参数(weights)
-
是什么: 模型中需要学习的核心数值,比如神经网络层的权重矩阵、偏置项等。
-
作用: 决定模型的行为。训练的目标就是不断更新这些参数,让模型输出更接近目标值。
-
例子:
pythonW = torch.nn.Linear(512, 512).weight这就是一个权重矩阵(参数)。
二、梯度(gradients)
-
是什么: 参数对损失函数的偏导数,表示"如果我改动这个参数,损失会往哪个方向变"。
-
作用: 告诉优化器如何调整参数以减小损失。
-
生成方式: 通过反向传播(backpropagation)自动计算。
简单理解:
梯度是"路标"------告诉优化器应该往哪个方向走(减小损失)。
例子:
python
loss.backward()
print(W.grad) # 这里的grad就是梯度三、一阶动量(m,Momentum)
-
是什么: 梯度的"指数滑动平均"(Exponential Moving Average)。
-
作用: 平滑梯度更新,让参数更新方向更稳定,不会抖动。
-
公式:
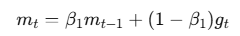
其中 ( g_t ) 是当前梯度,(\beta_1) 通常取 0.9。
直观理解:
想象优化器是一辆车,梯度是"当前推力",而一阶动量是"惯性"。
你不希望车每一步都完全按梯度走,而是沿着长期平均方向继续前进。
四、二阶动量(v,Variance)
-
是什么: 梯度平方的指数滑动平均,衡量梯度的"变化幅度"。
-
作用: 控制学习率的自适应调整,让更新在不同维度上自动放缓或加速。
-
公式:
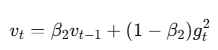
其中 (\beta_2) 通常取 0.999。
直观理解:
v 表示"梯度震荡的能量"。
如果某个参数的梯度变化太剧烈,优化器会自动降低它的学习率,避免发散。
五、它们如何在优化中协作(以 Adam 为例)
Adam 优化器结合了一阶和二阶动量,更新公式如下:
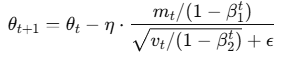
-
(\theta_t):模型参数(weights)
-
(m_t):一阶动量(平滑的方向)
-
(v_t):二阶动量(平滑的幅度)
-
(\eta):学习率
这意味着 Adam 更新时不仅考虑了当前梯度,还考虑了历史趋势 (m)和不确定性(v)。