🌟个人主页:第七序章****
🌈专栏系列:C++****


目录
[☀️一、lambda 表达式基础语法](#☀️一、lambda 表达式基础语法)
[⭐mutable 关键字](#⭐mutable 关键字)
[⭐lambda 的实际应用场景](#⭐lambda 的实际应用场景)
[⭐ empalce系列接口](#⭐ empalce系列接口)
❄️前言:
前面我们已经简单的学习了C + + 11(上),今天我们继续来学习C + + 11(中)。
随着 C++11 的引入,现代 C++ 语言在语法层面上变得更加灵活、简洁。其中最受欢迎的新特性之一就是 lambda表达式(Lambda Expression),它让我们可以在函数内部直接定义匿名函数。配合 std::function 包装器 使用,可以大大提高代码的表达力与可维护性。
☀️一、lambda 表达式基础语法
lambda表达式本质上就是一个匿名函数对象,与普通函数不同的是,它可以定义在函数内部;
一般情况下我们是使用auto或者模版参数定义的对象去接受lambda对象。

cpp
int main()
{
// 一个简单的lambda表达式
auto add1 = [](int x, int y)->int {return x + y; };
auto add1 = [](int x, int y){return x + y; };
cout << add1(1, 2) << endl;
// 1、捕捉为空也不能省略
// 2、参数为空可以省略
// 3、返回值可以省略,可以通过返回对象自动推导
// 4、函数体不能省略
auto func1 = []
{
cout << "hello" << endl;
return 0;
};
func1();
int a = 0, b = 1;
auto swap1 = [](int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
};
swap1(a, b);
cout << a << ":" << b << endl;
return 0;
}
cpp
int main()
{
auto add = [](int a, int b) -> int {
return a + b;
};
std::cout << add(2, 3); // 输出:5
}也可以省略 -> int,由编译器自动推导:
cpp
int main()
{
auto add = [](int a, int b){
return a + b;
};
std::cout << add(2, 3); // 输出:5
}这里呢,参数列表,如果不需要传参,可以省略,**()**也可以省略;返回值类型可以省略,让编译器自行推导。
而参数列表和函数体,就算为空,参数列表的**[]和函数体的{}**也不能省略。
⭐捕获列表
- lambda 表达式中默认只能用lambda函数体和参数中的变量,如果想用外层作用域中的变量就需要进行捕捉
- 第一种捕捉方式是在捕捉列表中显示的传值捕捉和传引用捕捉,捕捉的多个变量用逗号分割。x, y, \&z表示x和y值捕捉,z引用捕捉。
- 第二种捕捉方式是在捕捉列表中隐式捕捉,我们在捕捉列表写一个**=表示隐式值捕捉,在捕捉列表写一个&表示隐式引用捕捉,这样我们lambda** 表达式中用了那些变量,编译器就会自动捕捉那些变量。
- 第三种捕捉方式是在捕捉列表中混合使用隐式捕捉和显示捕捉。=, \&x表示其他变量隐式值捕捉,x引用捕捉;\&, x, y表示其他变量引用捕捉,x和y值捕捉。当使用混合捕捉时,第一个元素必须是&或=,并且&混合捕捉时,后面的捕捉变量必须是值捕捉,同理=混合捕捉时,后面的捕捉变量必须是引用捕捉。
- lambda 表达式如果在函数局部域中,他可以捕捉 lambda 位置之前定义的变量,不能捕捉静态 局部变量和全局变量,静态局部变量和全局变量也不需要捕捉, lambda 表达式中可以直接使用。这也意味着 lambda 表达式如果定义在全局位置,捕捉列表必须为空。
- 默认情况下, lambda 捕捉列表是被const修饰的,也就是说传值捕捉的过来的对象不能修改, mutable加在参数列表的后面可以取消其常量性,也就说使用该修饰符后,传值捕捉的对象就可以修改了,但是修改还是形参对象,不会影响实参。使用该修饰符后,参数列表不可省略(即使参数为空)。
cpp
int x = 0;
// 捕捉列表必须为空,因为全局变量不用捕捉就可以用,没有可被捕捉的变量
auto func1 = []()
{
x++;
};
int main()
{
// 只能用当前lambda局部域和捕捉的对象和全局对象
int a = 0, b = 1, c = 2, d = 3;
auto func1 = [a, &b]
{
// 值捕捉的变量不能修改,引用捕捉的变量可以修改
//a++;
b++;
int ret = a + b;
return ret;
};
cout << func1() << endl;
// 隐式值捕捉
// 用了哪些变量就捕捉哪些变量,没有使用d就不会捕捉d
auto func2 = [=]
{
int ret = a + b + c;
return ret;
};
cout << func2() << endl;
// 隐式引用捕捉
// 用了哪些变量就捕捉哪些变量
auto func3 = [&]
{
a++;
c++;
d++;
};
func3();
cout << a << " " << b << " " << c << " " << d << endl;
// 混合捕捉1
auto func4 = [&, a, b]
{
//a++;
//b++;
c++;
d++;
return a + b + c + d;
};
func4();
cout << a << " " << b << " " << c << " " << d << endl;
// 混合捕捉2
auto func5 = [=, &a, &b]
{
a++;
b++;
/*c++;
d++;*/
return a + b + c + d;
};
func5();
cout << a << " " << b << " " << c << " " << d << endl;
// 局部的静态和全局变量不能捕捉,也不需要捕捉
static int m = 0;
auto func6 = []
{
int ret = x + m;
return ret;
};
// 传值捕捉本质是一种拷贝,并且被const修饰了
// mutable相当于去掉const属性,可以修改了
// 但是修改了不会影响外面被捕捉的值,因为是一种拷贝
auto func7 = [=]()mutable
{
a++;
b++;
c++;
d++;
return a + b + c + d;
};
cout << func7() << endl;
cout << a << " " << b << " " << c << " " << d << endl;
return 0;
}捕获列表决定了Lambda 表达式****如何访问其所在作用域的变量。
| 捕获方式 | 语法 | 说明 |
|---|---|---|
| 值捕捉 | [x] | 捕获变量 x 的当前值(拷贝) |
| 引用捕捉 | [&x] | 捕获变量 x 的引用 |
| 隐式值捕捉 | [=] | lambda 使用了哪些变量,编译器就会对哪些变量进行值捕捉 |
| 隐式引用捕捉 | [&] | lambda 使用了哪些变量,编译器就会对哪些变量进行引用捕捉 |
| 混合捕捉 | [=, &y] | 除 y 外的所有变量为值捕获,y 为引用捕获 |
| 混合捕捉 | [&, x] | 除 x 外的所有变量为引用捕捉,x 为值捕捉 |
cpp
int main()
{
int x = 10, y = 20;
auto f1 = [=]() { return x + y; }; // 值捕获
auto f2 = [&]() { x += y; }; // 引用捕获,修改外部变量
auto f3 = [x, &y]() { y += x; }; // 混合捕获
return 0;
}这里lambda表达式如果在函数局部域中,它可以捕捉lambda位置之前定义的变量,但是不能捕捉静态局部变量和全局变量(静态局部变量和全局变量也不需要捕捉,lambda表达式中也可以直接使用)。
如果lambda定义在全局,那捕捉列表必须为空
值捕获的变量在 Lambda中是"只读"的,不能修改,除非加上mutable。
⭐mutable 关键字
默认情况下,lambda捕捉列表的值是被**const修饰的,值捕获的变量不能在 Lambda 中被修改 。要想修改值捕获的副本,可以使用mutable**:
cpp
int main()
{
int a = 5;
auto f = [a]() mutable {
a += 10; // 修改的是a的拷贝,不影响外部 a
cout << a << endl;
};
f(); // 15
std::cout << a << endl; // 5
return 0;
}⭐lambda 的实际应用场景
与 STL 算法结合
cpp
std::vector<int> vec = {1, 2, 3, 4, 5};
std::for_each(vec.begin(), vec.end(), [](int x) {
std::cout << x << " ";
});条件查找
cpp
auto it = std::find_if(vec.begin(), vec.end(), [](int x) {
return x > 3;
});
if (it != vec.end()) std::cout << *it; // 输出 4排序自定义规则
cpp
std::sort(vec.begin(), vec.end(), [](int a, int b) {
return a > b; // 降序
});- 在学习 lambda 表达式之前,我们的使用的可调用对象只有函数指针和仿函数对象,函数指针的 类型定义起来比较麻烦,仿函数要定义一个类,相对会比较麻烦。使用 lambda 去定义可调用对 象,既简单又方便。
- lambda 在很多其他地方用起来也很好用。比如线程中定义线程的执行函数逻辑,智能指针中定 制删除器等, lambda 的应用还是很广泛的,以后我们会不断接触到
cpp
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
// ...
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{
}
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3}, { "菠萝", 1.5, 4 } };
// 类似这样的场景,我们实现仿函数对象或者函数指针支持商品中
// 不同项的比较,相对还是比较麻烦的,那么这里lambda就很好用了
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price;
});
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
});
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate < g2._evaluate;
});
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate > g2._evaluate;
});
return 0;
}⭐lambda的原理
lambda的原理和范围for非常相似,编译之后从汇编的角度来看,我们就要发现根本就没有lambda和**
范围for**;范围for的底层是迭代器,而**
lambda的底层是仿函数对象**,简单来说我们写了一个lambda,编译器就会生成一对应的仿函数。而仿函数的类名是编译器按照一定的规则生产的,保证不同的lambda生成的仿函数不同。
- **
lambda的参数/返回值/函数体就是仿函数operator()**的参数/返回类型/函数体- lambda捕捉列表的本质是生成的仿函数的成员变量。
简单来说就是捕捉列表的量都是lambda类构造函数的实参;
这样就很好解释**值捕捉和引用捕捉**了:
- 值捕捉:lambda生成的仿函数的成员就是对捕捉变量的值拷贝。
- 引用捕捉:lambda生成的仿函数的成员就是对捕捉变量的引用。
而也支持隐式捕捉,这个就是编译器看需要用哪些对象,就传哪些对象(用多少捕捉多少)。
cpp
class Rate
{
public:
Rate(double rate)
: _rate(rate)
{
}
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
double rate = 0.49;
// lambda
auto r2 = [rate](double money, int year) {
return money * rate * year;
};
// 函数对象
Rate r1(rate);
r1(10000, 2);
r2(10000, 2);
auto func1 = [] {
cout << "hello world" << endl;
};
func1();
return 0;
}
// lambda
auto r2 = [rate](double money, int year) {
return money * rate * year;
};
// 捕捉列表的rate,可以看到作为lambda_1类构造函数的参数传递了,这样要拿去初始化成员变量
// 下面operator()中才能使用
00D8295C lea eax, [rate]
00D8295F push eax
00D82960 lea ecx, [r2]
00D82963 call `main'::`2': : <lambda_1>::<lambda_1> (0D81F80h)
// 函数对象
Rate r1(rate);
00D82968 sub esp, 8
00D8296B movsd xmm0, mmword ptr[rate]
00D82970 movsd mmword ptr[esp], xmm0
00D82975 lea ecx, [r1]
00D82978 call Rate::Rate(0D81438h)
r1(10000, 2);
00D8297D push 2
00D8297F sub esp, 8
00D82982 movsd xmm0, mmword ptr[__real@40c3880000000000(0D89B50h)]
00D8298A movsd mmword ptr[esp], xmm0
00D8298F lea ecx, [r1]
00D82992 call Rate::operator() (0D81212h)
// 汇编层可以看到r2 lambda对象调用本质还是调用operator(),类型是lambda_1,这个类型名
// 的规则是编译器自己定制的,保证不同的lambda不冲突
r2(10000, 2);
00D82999 push 2
00D8299B sub esp, 8
00D8299E movsd xmm0, mmword ptr[__real@40c3880000000000(0D89B50h)]
00D829A6 movsd mmword ptr[esp], xmm0
00D829AB lea ecx, [r2]
00D829AE call `main'::`2': : <lambda_1>::operator() (0D824C0h)
cpp
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
// ...
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{
}
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3}, { "菠萝", 1.5, 4 } };
// 类似这样的场景,我们实现仿函数对象或者函数指针支持商品中
// 不同项的比较,相对还是比较麻烦的,那么这里lambda就很好用了
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price;
});
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
});
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate < g2._evaluate;
});
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate > g2._evaluate;
});
return 0;
}☀️二、可变参数模版
⭐基本语法:
C++11支持可变参数模版,简单来说就是支持可变数量参数的函数模版或者类模版;可变数目的参数被称为**
参数包,存在两种参数包:模版参数包(表示0个或者多个模版参数),函数参数包**(表示0个或者多个函数参数)。
cpp
// 示例1
template<class ...Args> // 模版参数包
void func(Args ...args) // 函数参数包
{}
// 示例2
template<class ...Args> // 模版参数包
void func(Args& ...args) // 函数参数包
{}
// 示例3
template<class ...Args> // 模版参数包
void func(Args&& ...args) // 函数参数包
{}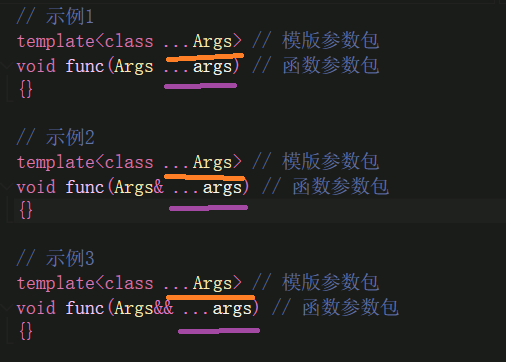
- 我们使用
...来指出一个模版参数或者函数参数,表示一个参数包;
- 在模版参数列表在,**class...或者typename...**指出接下来的参数表示
0个或者多个类型列表; - 在函数参数列表中,类型名后跟
...指出接下来表示0个或者多个形参对象列表; - 函数参数包可以使用**
左值引用或右指引用**表示,每一个参数实例化时依然遵循引用折叠的规则。
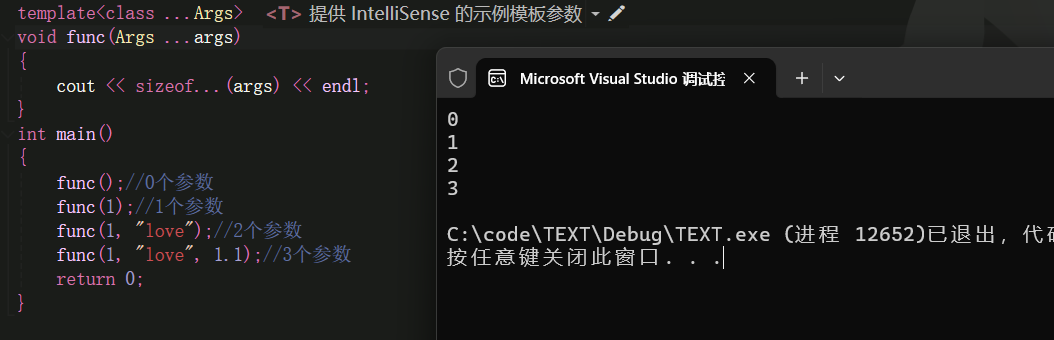
这里我们可以使用**sizeof...()**来计算参数包里面有多少个参数。
cpp
template<class ...Args>
void func(Args ...args)
{
cout << sizeof...(args) << endl;
}
int main()
{
func();//0个参数
func(1);//1个参数
func(1, "love");//2个参数
func(1, "love", 1.1);//3个参数
return 0;
}
⭐原理:
这里可变模版参数的原理和模版类似,本质上还是编译器去实例化对应类型和个数的多个函数。
就以上述代码来说,编译器实际上是根据我们传参的类型实例化出来了多个函数:
cpp
void func();
void func(int&& a);
void func(int&& a, string&& b);
void func(int&& a, string&& b, double c);这里我们如果实现下列普通函数模版,也能到达目的:
cpp
void func();
template <class T1>
void func(T1&& a);
template <class T1, class T2>
void func(T1&& a, T2&& b);
template <class T1, class T2, class T3>
void func(T1&& a, T2&& b, T3&& c);但是这样未必有些太麻烦了,如果我们还要传递4、5、6个甚至更多参数的,那还要一个个去实现。
而有了可变参数模板,我们只需要实现一个,就可以达到普通函数模板多个的效果。
这里我们可以简单的理解成,可变参数函数模板先实例化出多个普通函数模板,在这进一步实例化出具体类型的函数。
当然编译器并不会这样去做,而是直接实例化出参数类型个个数对应的函数。
⭐包扩展:
- 对于一个参数包,我们能够使用**sizeof...()**去计算它的个数,除此之外,唯一能做的就是扩展它了。
那如何扩展呢?
- 当扩展一个参数包时,我们还需要提供一个用来扩展每一个元素的模式(扩展包简单来说就是将包中元素一个个取出来),这里对每一个元素应用模式,获得扩展之后的列表。
- 通过在模版的右边放一个
...来触发扩展操作。
cpp
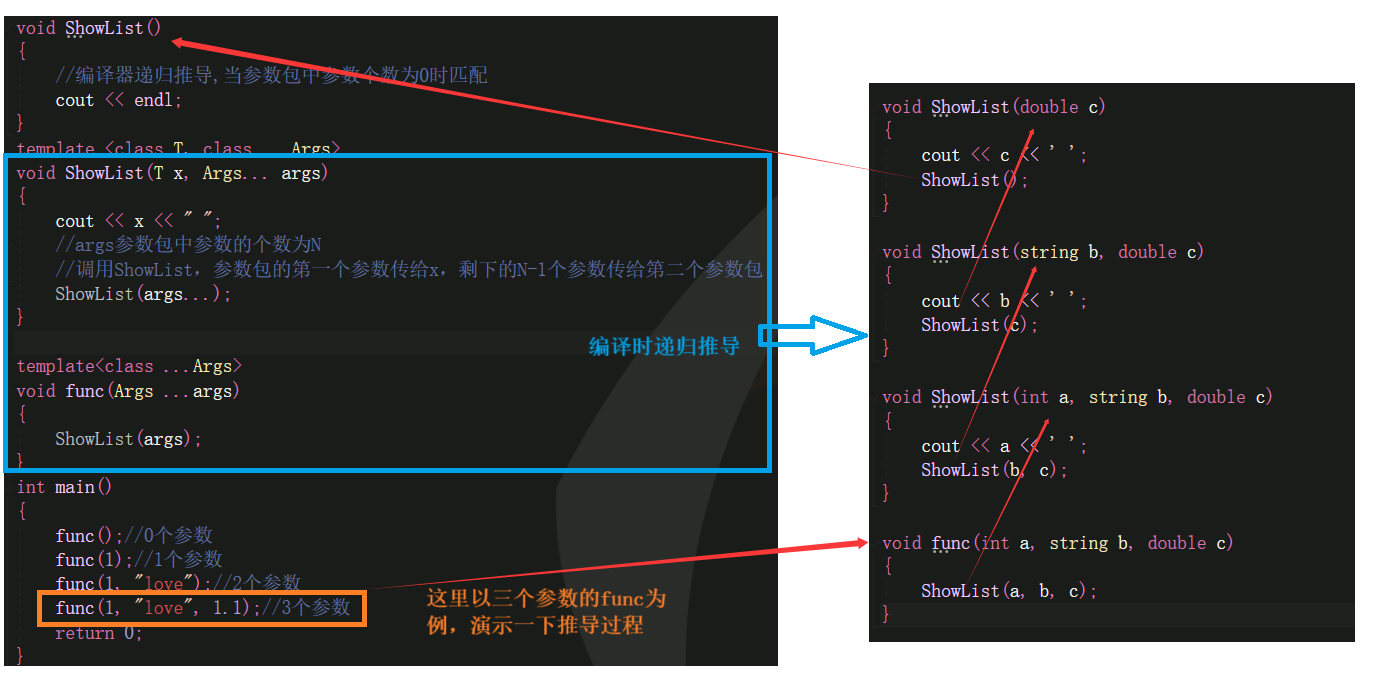
void ShowList()
{
//编译器递归推导,当参数包中参数个数为0时匹配
cout << endl;
}
template <class T, class ...Args>
void ShowList(T x, Args... args)
{
cout << x << " ";
//args参数包中参数的个数为N
//调用ShowList,参数包的第一个参数传给x,剩下的N-1个参数传给第二个参数包
ShowList(args...);
}
template<class ...Args>
void func(Args ...args)
{
ShowList(args);
}
int main()
{
func();//0个参数
func(1);//1个参数
func(1, "love");//2个参数
func(1, "love", 1.1);//3个参数
return 0;
}
这里,也可以这样去扩展包
cpp
template <class T>
const T& GetArg(const T& x)
{
cout << x << " ";
return x;
}
template <class ...Args>
void Arguments(Args... args)
{}
template <class ...Args>
void func(Args... args)
{
// 注意GetArg必须返回获得到的对象,这样才能组成参数包给Arguments
Arguments(GetArg(args)...);
}这里本质上,编译器将上述模版函数扩展实例化为下面这样
cpp
void func(int x, string y, double z)
{
Arguments(GetArg(x), GetArg(y), GetArg(z));
}在更多的情况下,是直接将包向下传递,直接匹配参数列表。
⭐ empalce系列接口
- template void emplace_back (Args&&... args);
- template iterator emplace (const_iterator position, Args&&... args);
- C++11以后STL容器新增了empalce系列的接口,empalce系列的接口均为模板可变参数 ,功能上兼容push和 insert 系列,但是empalce还支持新玩法,假设容器为container,empalce还支持直接插入构造T对象的参数,这样有些场景会更高效一些,可以直接在容器空间上构造T对象。
- emplace_back总体而言是更高效,推荐 以后使用emplace系列替代insert和push系列
- 第二个程序中我们模拟实现了list的emplace和emplace_back接口,这里把参数包不段往下传递, 最终在结点的构造中直接去匹配容器存储的数据类型T的构造,所以达到了前面说的empalce支持直接插入构造T对象的参数,这样有些场景会更高效一些,可以直接在容器空间上构造T对象。
- 传递参数包过程中,如果是Args&&... args的参数包,要用完美转发参数包,方式如下 std::forward(args)...,否则编译时包扩展后右值引用变量表达式就变成了左值。
cpp
#include<list>
// emplace_back总体而言是更高效,推荐以后使用emplace系列替代insert和push系列
int main()
{
list<bit::string> lt;
// 传左值,跟push_back一样,走拷贝构造
bit::string s1("111111111111");
lt.emplace_back(s1);
cout << "*********************************" << endl;
// 右值,跟push_back一样,走移动构造
lt.emplace_back(move(s1));
cout << "*********************************" << endl;
// 直接把构造string参数包往下传,直接用string参数包构造string
// 这里达到的效果是push_back做不到的
lt.emplace_back("111111111111");
cout << "*********************************" << endl;
list<pair<bit::string, int>> lt1;
// 跟push_back一样
// 构造pair + 拷贝/移动构造pair到list的节点中data上
pair<bit::string, int> kv("苹果", 1);
lt1.emplace_back(kv);
cout << "*********************************" << endl;
// 跟push_back一样
lt1.emplace_back(move(kv));
cout << "*********************************" << endl;
////////////////////////////////////////////////////////////////////
// 直接把构造pair参数包往下传,直接用pair参数包构造pair
// 这里达到的效果是push_back做不到的
lt1.emplace_back("苹果", 1);//这里的参数包推出来的是const char* 和int,而不是pair,然后用pair参数包构造pair
cout << "*********************************" << endl;
//对于push_back不能直接像上面那样写,要加上{ }
//lt1.push_back("苹果", 1);
lt1.push_back({"苹果", 1});
return 0;
}稍稍对上面的代码解释一下:

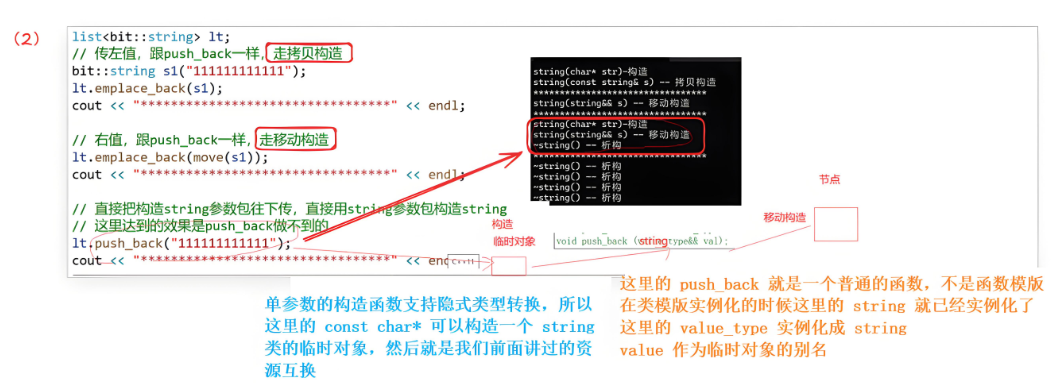
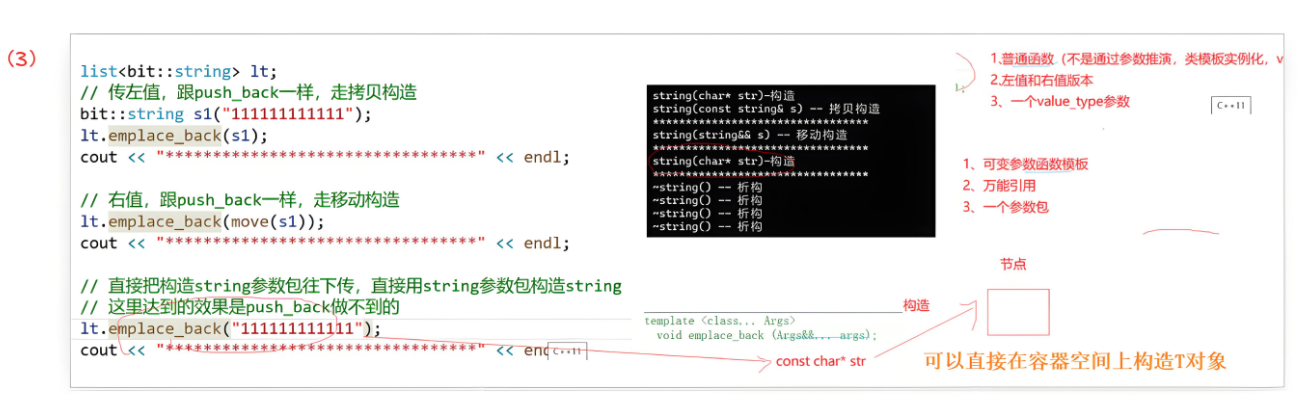
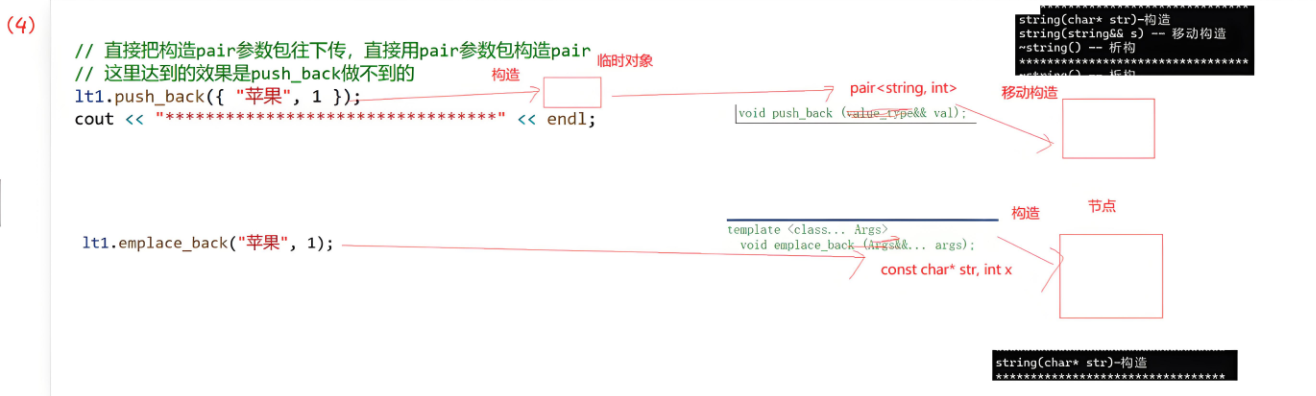
总结:对于多参数的,push_back只能走**{ }括起来的隐式类型转换,而emplace_back**可以直接将多参数传给参数包,用参数包直接构造。
cpp
// List.h
namespace bit
{
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _data;
ListNode(T&& data)
:_next(nullptr)
, _prev(nullptr)
, _data(move(data))
{}
template <class... Args>
ListNode(Args&&... args)
: _next(nullptr)
, _prev(nullptr)
, _data(std::forward<Args>(args)...)
{}
};
template<class T, class Ref, class Ptr>
struct ListIterator
{
typedef ListNode<T> Node;
typedef ListIterator<T, Ref, Ptr> Self;
Node* _node;
ListIterator(Node* node)
:_node(node)
{
}
// ++it;
Self& operator++()
{
_node = _node->_next;
return *this;
}
Self& operator--()
{
_node = _node->_prev;
return *this;
}
Ref operator*()
{
return _node->_data;
}
bool operator!=(const Self& it)
{
return _node != it._node;
}
};
template<class T>
class list
{
typedef ListNode<T> Node;
public:
typedef ListIterator<T, T&, T*> iterator;
typedef ListIterator<T, const T&, const T*> const_iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
void empty_init()
{
_head = new Node();
_head->_next = _head;
_head->_prev = _head;
}
list()
{
empty_init();
}
void push_back(const T& x)
{
insert(end(), x);
}
void push_back(T&& x)
{
insert(end(), move(x));
}
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* newnode = new Node(x);
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
iterator insert(iterator pos, T&& x)
{
Node* cur = pos._node;
Node* newnode = new Node(move(x));
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
template <class... Args>
void emplace_back(Args&&... args)
{
insert(end(), std::forward<Args>(args)...);
}
// 原理:本质编译器根据可变参数模板生成对应参数的函数
/*void emplace_back(string& s)
{
insert(end(), std::forward<string>(s));
}
void emplace_back(string&& s)
{
insert(end(), std::forward<string>(s));
}
void emplace_back(const char* s)
{
insert(end(), std::forward<const char*>(s));
}
*/
template <class... Args>
iterator insert(iterator pos, Args&&... args)
{
Node* cur = pos._node;
Node* newnode = new Node(std::forward<Args>(args)...);
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
private:
Node* _head;
};
}
cpp
// Test.cpp
#include"List.h"
// emplace_back总体而言是更高效,推荐以后使用emplace系列替代insert和push系列
int main()
{
bit::list<bit::string> lt;
// 传左值,跟push_back一样,走拷贝构造
bit::string s1("111111111111");
lt.emplace_back(s1);
cout << "*********************************" << endl;
// 右值,跟push_back一样,走移动构造
lt.emplace_back(move(s1));
cout << "*********************************" << endl;
// 直接把构造string参数包往下传,直接用string参数包构造string
// 这里达到的效果是push_back做不到的
lt.emplace_back("111111111111");
cout << "*********************************" << endl;
bit::list<pair<bit::string, int>> lt1;
// 跟push_back一样
// 构造pair + 拷贝/移动构造pair到list的节点中data上
pair<bit::string, int> kv("苹果", 1);
lt1.emplace_back(kv);
cout << "*********************************" << endl;
// 跟push_back一样
lt1.emplace_back(move(kv));
cout << "*********************************" << endl;
////////////////////////////////////////////////////////////////////
//
// 直接把构造pair参数包往下传,直接用pair参数包构造pair
// 这里达到的效果是push_back做不到的
lt1.emplace_back("苹果", 1);
cout << "*********************************" << endl;
return 0;
}☀️三、本文小结
| 核心模块 | 关键知识点 | 语法 / 示例代码 | 核心说明 |
|---|---|---|---|
| Lambda 表达式 | 基础语法结构 | [捕获列表](参数列表) mutable -> 返回类型 {函数体}``auto add = [](int a, int b){return a+b;}; |
1. 捕获列表不可省略(空捕获用[])2. 参数列表、返回类型可省略(返回类型由编译器推导)3. 函数体不可省略 |
| 捕获列表(6 种方式) | 1. 值捕获:[x]2. 引用捕获:[&x]3. 隐式值捕获:[=]4. 隐式引用捕获:[&]5. 混合捕获 1:[=, &y]6. 混合捕获 2:[&, x] |
1. 全局 / 静态变量无需捕获,可直接使用2. 混合捕获时,=/&需放在首位3. 值捕获默认const,需修改加mutable |
|
| mutable 关键字 | int a=5;``auto f = [a]()mutable{a+=10;cout<<a;};``f();//输出15,外部a仍为 5 |
1. 取消值捕获变量的const属性2. 修改的是捕获变量的副本,不影响外部原变量3. 加mutable后参数列表不可省略(空参数用()) |
|
| 实际应用场景 | 1. 结合 STL 算法:sort(vec.begin(), vec.end(), [](int a,int b){return a>b;});2. 条件查找:find_if(vec.begin(), vec.end(), [](int x){return x>3;}); |
替代仿函数和函数指针,简化代码支持自定义排序、过滤等逻辑,灵活性更高 | |
| 底层原理 | 编译器自动生成匿名仿函数类 :- 捕获列表 → 类成员变量- 参数列表 / 函数体 → operator()的参数 / 实现 |
Lambda 本质是仿函数的语法糖,调用时实际执行operator()方法 |
|
| 可变参数模板 | 基础语法结构 | 模板参数包:template<class ...Args>函数参数包:void func(Args ...args) |
1. ...表示 "参数包",可接收 0 个或多个参数2. 用sizeof...(args)获取参数个数 |
| 包扩展(递归方式) | void ShowList(){}//递归终止条件``template<class T, class ...Args>``void ShowList(T x, Args... args){ cout<<x<<" "; ShowList(args...);``} |
1. 通过递归拆解参数包,每次取第一个参数2. 需提供无参的递归终止函数 | |
| emplace 系列接口(STL) | list<pair<string, int>> lt;``lt.emplace_back("苹果", 1);//直接传构造参数 |
1. 相比push_back,可直接在容器内存构造对象,减少拷贝 / 移动开销2. 需配合完美转发std::forward<Args>(args)... |
|
| 完美转发参数包 | template<class ...Args>``void func(Args&&... args){ emplace(args...);``} |
1. 保持参数的左值 / 右值属性2. 避免参数包扩展后右值退化为左值 |
🌻共勉:
以上就是本篇博客的所有内容,如果你觉得这篇博客对你有帮助的话,可以点赞收藏关注支持一波~~🥝