常见命令
redis的key的过期策略是怎么实现的(经典面试题)
一个redis中可能同时存在很多很多的key。这些key中可能有很大一部分都有过期时间。此时,redis服务器怎么知道大写key已经过期要删除,哪些key还没过期?
如果直接遍历所有的key,显然是行不通的,效率非常低~~
redis整体策略是:
1、定期删除
2、惰性删除
1、定期删除
每次抽取一部分键值对,进行验证过期时间。(这样抽查的方式能够保证这个抽取检查的过程,足够快!!)而且这里对于定期删除的时间是有明确的要求的,一般是快到删除的时间再进行检查,而且一次不能抽取过多的key。因为redis是单线程的程序,主要的任务是处理每个命令的任务,如果扫描过期key消耗的时间太多了,就可能导致正常处理请求命令就被阻塞了(产生了类似于执行key*这样的效果)。
2、惰性删除
假设这个key已经到过期时间了,但是暂时还没删它,key还存在,紧接着,后面又一次访问,正好用到了这个key,于是这次访问就会让redis服务器出发删除key的操作,同时返回一个nil。
虽然有了上述两种策略结合,但是整体的兄啊过一般。仍然可能会有很多的过期的key被残留了,没有及时删除掉~~因此,redis为了对上述进行补充,还提供了一系列的内存淘汰策略,这个我们后面再讲。
对于网络上的一些说法:
定时删除:redis使用为每个key创建定时器的方式来实现过期key的删除
1、redis并没有采取定时定时器的方式来实现过期key的删除。
2、如果有多个key过期,也可以通过一个定时器来高效/节省CPU的前提下来处理多个key~~
那为啥redis没有采取这种定时器的方式来实现过期key的删除呢?
很难考证为啥?个人的猜测,基于定时器实现,就势必要引入多线程了。redis早期版本就是奠定了单线程的基调~~引入了多线程就打破了作者的初衷~~
定时器的实现
定时器:在某个时间到达之后,执行指定的任务。
1、基于优先级队列实现
正常的队列都是先进先出,而优先级队列则是按照指定的优先级,优先级高的先出。
而优先级都是我们程序猿自定义的~在redis过期key的场景中,就可以设置为:过期时间越早,优先级越高。
现在假定有很多key都设置了过期时间,就可以把这些key加入到一个优先级队列中,指定优先级规则是过期时间早的,先出队列。
队首元素就是最早要过期的key,此时定时器只要分配一个线程,让这个线程去检查队首元素,看是否过期即可!如果队首元素还没过期,那么后续元素一定没过期!
此时扫描线程不需要遍历所有的key只盯住这一个队首元素即可!!另外在扫描线程检查队首元素过期时间的时候,也不能检查得太频繁~~
此时的做法就是可以根据当前时刻和队首元素设置一个过期时间,设置一个等待~~当时间差不多到了,系统再唤醒这个线程。
此时扫描线程就不需要高频扫描队首元素了,把CPU的开销也节省下来了。
那万一在线程休眠的时候,来了一个新的任务,更早执行,咋办呢?
可以在新任务添加的时候,唤醒一下刚才的线程~~ 重新检查一下队首元素,再根据时间差距重新调整阻塞时间即可~~
基于优先级队列实现定时器在多线程章节是实现过的,有想了解更多的可以参考这篇博客:多线程代码案例-3 定时器-CSDN博客
2、基于时间轮实现的定时器
这种时间轮把时间划分成很多小段(划分的粒度,看实际需求)。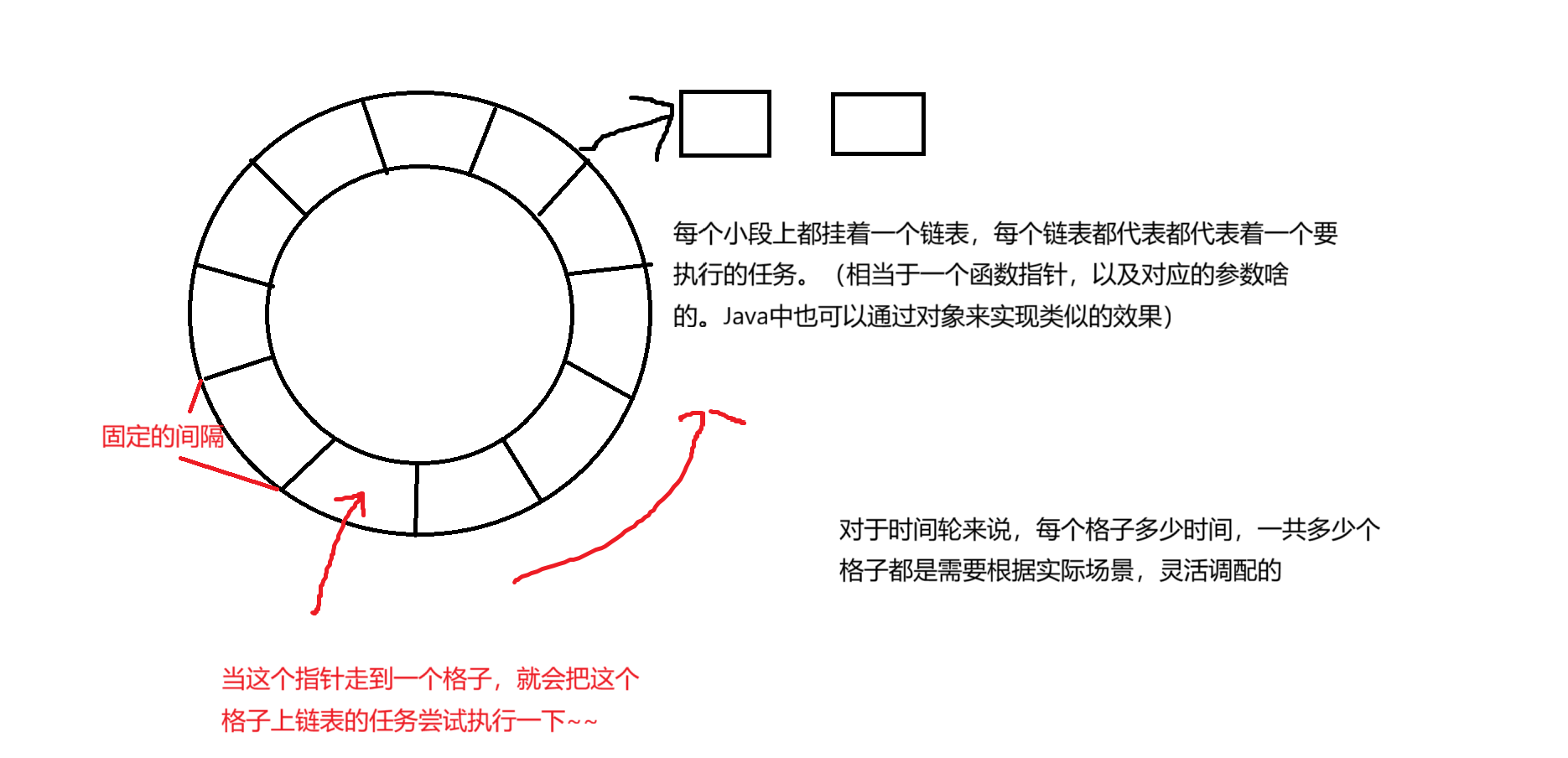
注意:redis是没有通过定时器的方式来实现key的删除的,因此redis并没有采用上面的两种方案来实现定时器。但是我们需要了解这两种方案,它们都是属于高效的定时器的实现方式,很多场景都可能会用到。
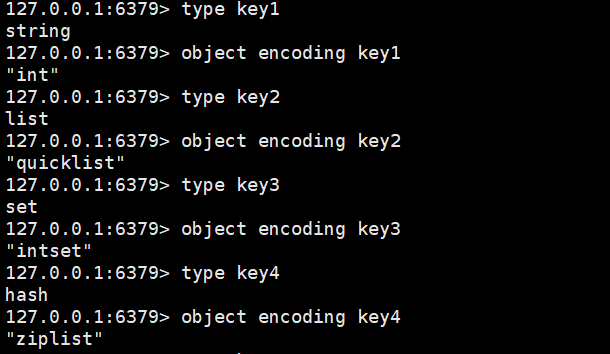
基本类型和编码方式
type
返回key对应的数据类型。
这里的类型是指value的类型,因为在redis中,所有的key都是String类型,而key对应得value可能会存在多种类型~~
当键不存在时:

字符串类型:
列表类型:
堆类型:

哈希类型:

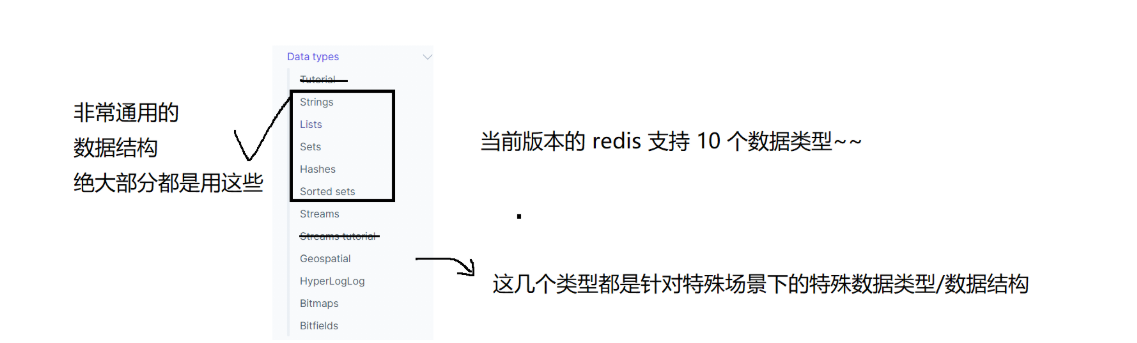
官方文档类型给出的完整类型如下:

注意:这里type查询key对应的value类型时间复杂度也是O(1)。在redis中,上述类型操作方式差别很大,使用的命令也是完全不同的。
常用全局命令小结
keys:用来查看匹配规则的key
exists:用来判定指定key是否存在
del:删除指定的key
expire:给key设置过期时间
ttl:查询key的过期时间
type:查询key对应的value的类型
上述的内容讲的都是无论value是什么类型都可以使用的命令(全局命令),后面我们就围绕着每个数据结构来介绍相关命令了。
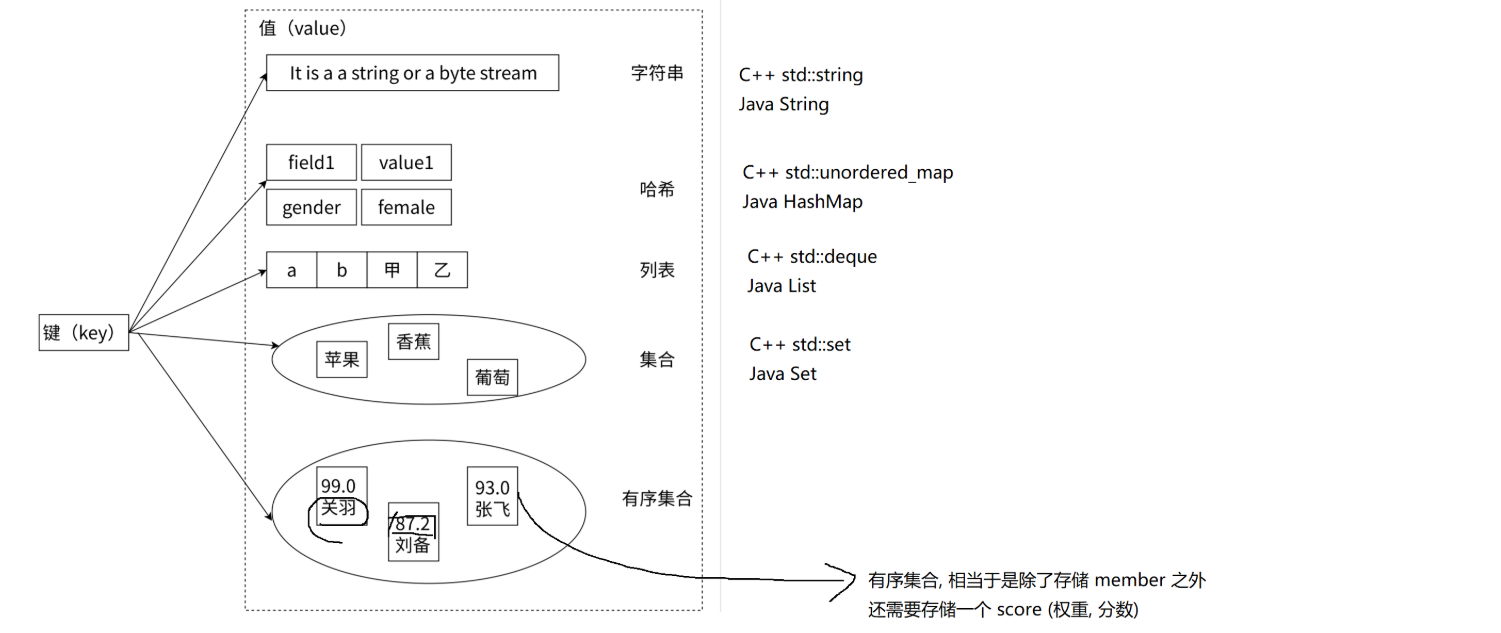
基本数据类型
首先,先认识下redis中value的数据类型。
但Redis底层在实现上述数据结构的时候,会在源码层面,针对上述数据结构进行特定的优化(编码方式不同),来到节省时间/节省空间的目的。
也就是说,redis承诺,现在我这里有个hash表,你进行查询,插入,删除,修改操作,保证你的时间复杂的是O(1),但是,这个背后的实现不一定是一个标准的hash类,可能再特定的场景下,使用别的数据结构实现,但是仍然保证时间复杂度符合承诺!!!
数据结构:redis承诺给你的,也可以理解成数据类型
编码方式:redis内部底层实现。
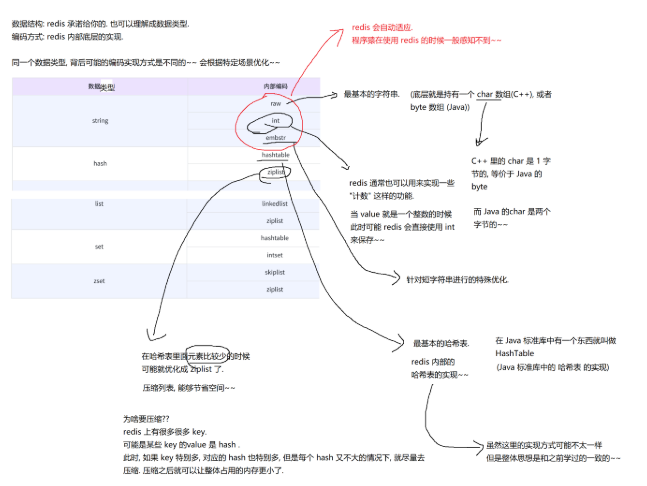
编码方式
String
String的编码可能会分为三种类型:
1、raw:最基本的字符串(底层类似于Java中的byte数组)。
2、int:当value是一个整数的时候,此时可能redis会直接使用int来保存。redis可以用来实现类似于计数的功能
3、embstr:针对短字符串做出的优化。
hash
1、hashtable:最基本的哈希表,redis内部的哈希表实现可能和java中学习的实现方式不一样,但是整体思想和之前学过的是一致的。
2、ziplist:在哈希表里面的元素比较少时,有可能就优化成ziplist(压缩列表,能够节省空间)了。
为啥要压缩?
redis上有很多很多的key
可能是某些key的value是hash
此时,如果key特别多,对应的hash也特别多,但是每个hash又不大的情况下,就尽量去压缩。压缩之后就可以让整体占用的内存更小了
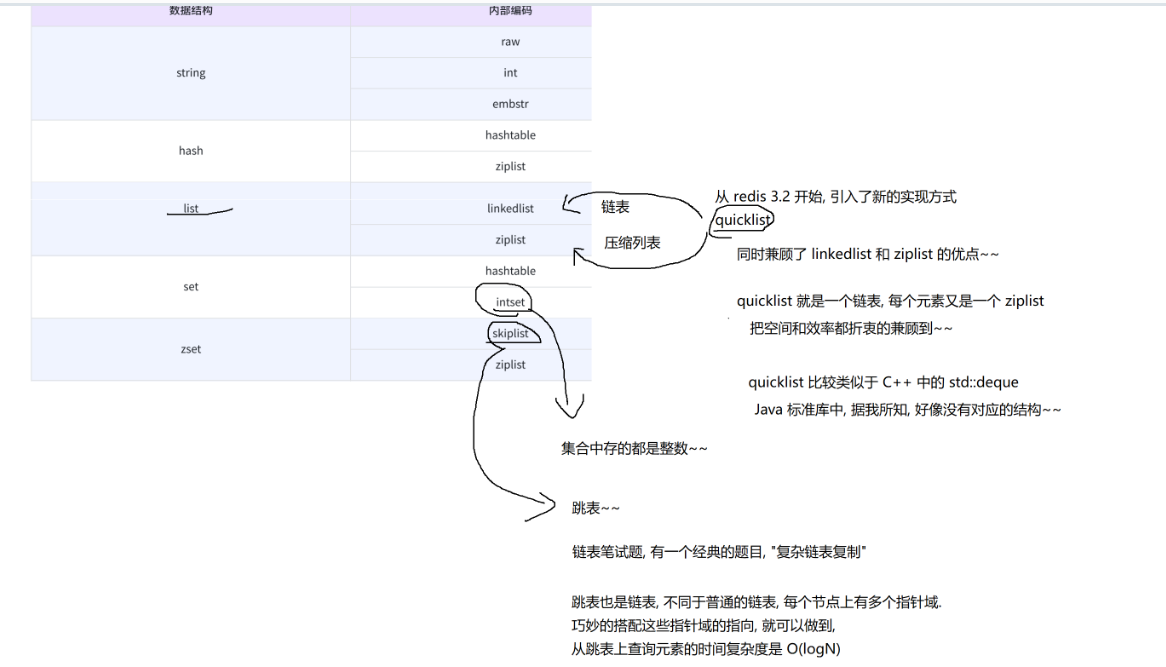
list
1、linkedlist:普通链表
2、ziplist:压缩列表
从redis3.2开始,引入了新的实现方式:quicklist。同时兼顾了linkedlist和ziplist的优点~~quicklist本身是一个链表,每个元素又是一个ziplist,把空间和效率都折衷的兼顾到。
set
1、hashtable:哈希表。
2、intset:集合中存的都是整数。
zset
1、skiplist:跳表。类似于我们之前讲链表笔试题上面那道经典的题目:"随机链表复制",跳表也是链表,不同于普通的链表,每个节点有多个指针域。巧妙地搭配这些指针域地指向,就可以做到,从跳表上查询元素的时间复杂度是O(logN)。
随机链表复制题目链接:138. 随机链表的复制 - 力扣(LeetCode)
题目详解:Map&Set 4 面试题汇总 _map面试题-CSDN博客
2、ziplist:压缩列表。
总结
上面我们已经讲过了redis会根据存储的值的多少来改变编码方式,那么我们需不需要记得长度为多少时改变内部的编码方式呢?
不用。这里我们只需要记住思想,不记数字。
原因:
1、数字都是可配置的。
2、这个数字是怎么来的,需要我们考证清楚~~
相比于知道数字,更重要的是知道数字是怎么得到的,就可以根据所处的实际场景,重新得到这样的数字。
object encoding
使用object encoding可以用来查看key对应value的实际编码方式。