此可视化说明了多代理编排的7种核心模式,每种模式都适用于特定的工作流:
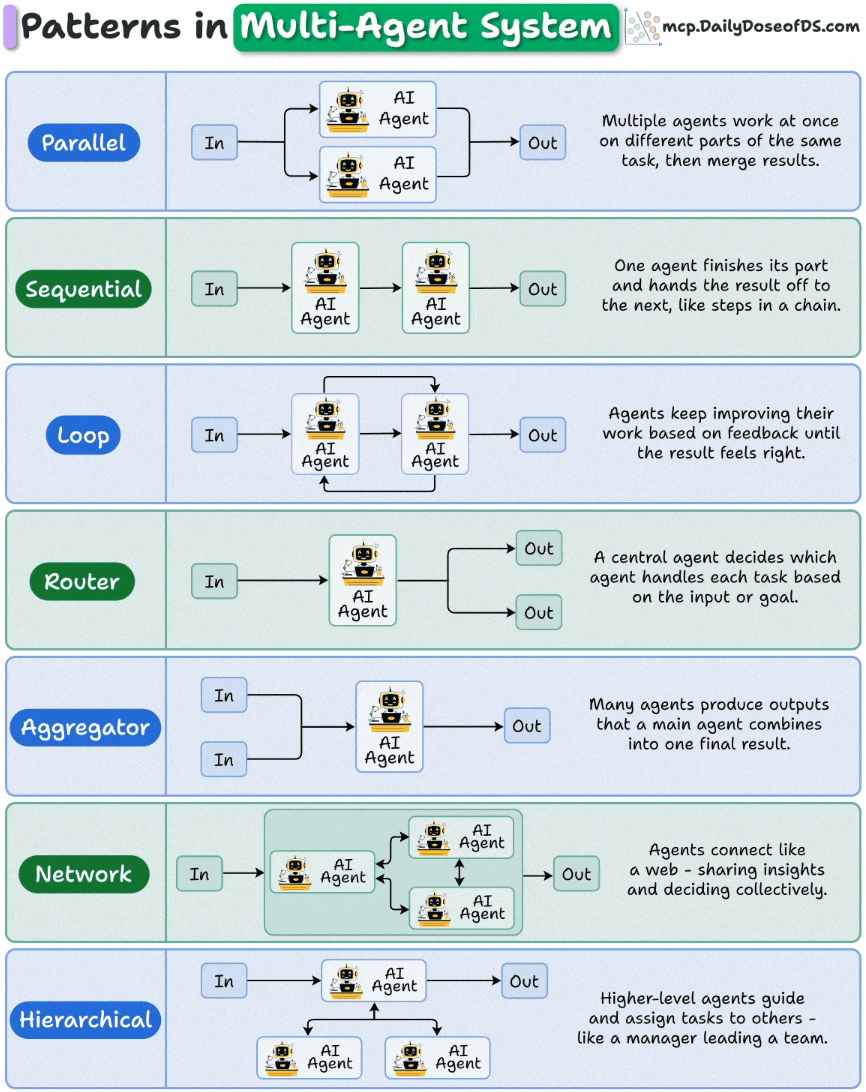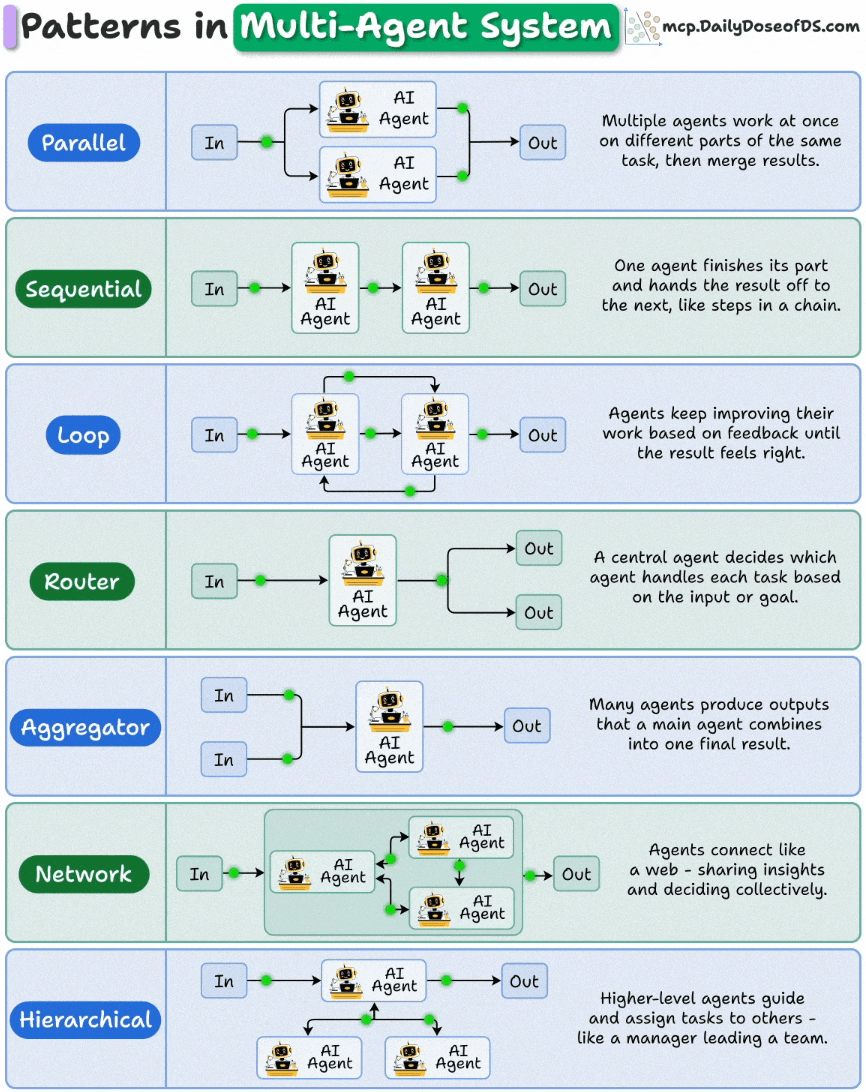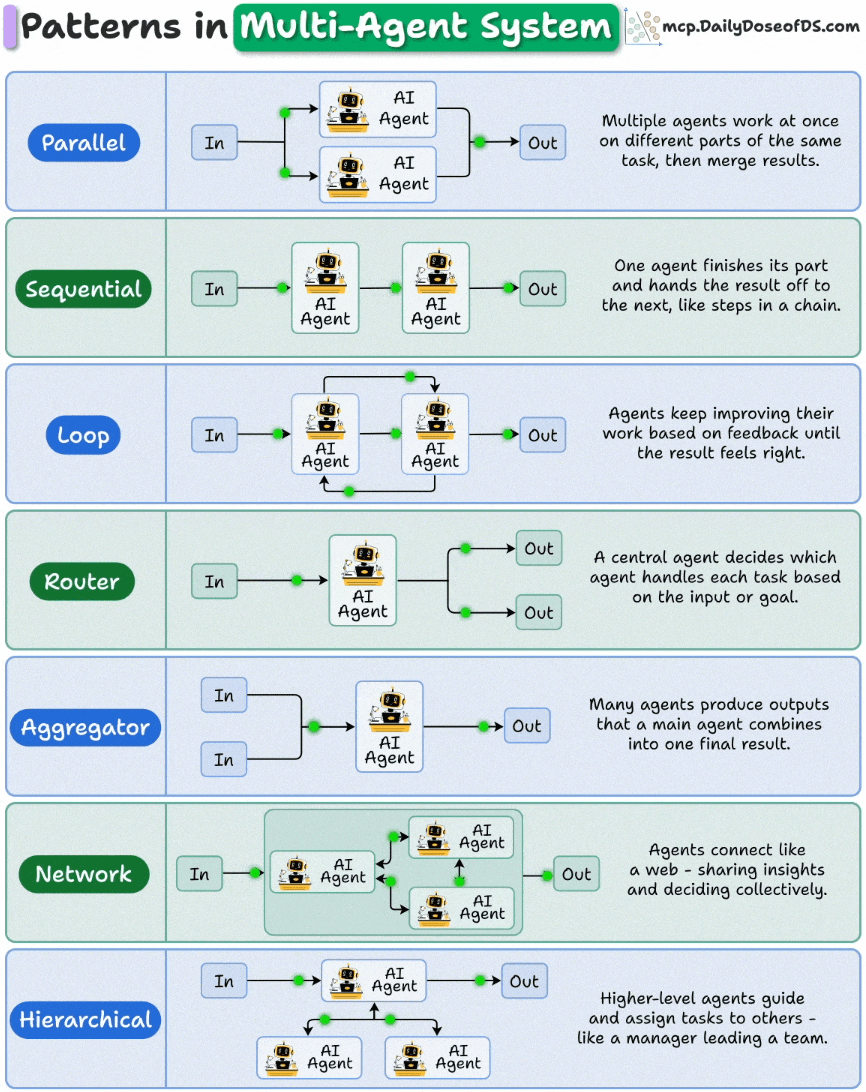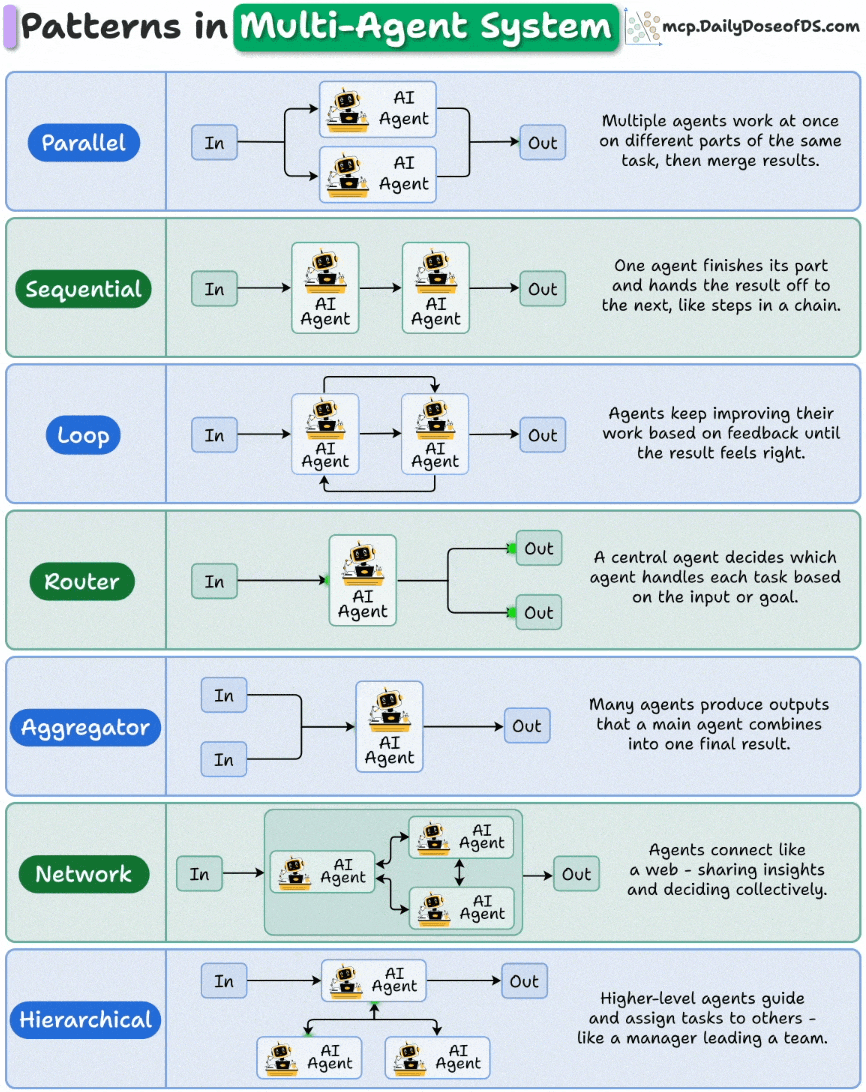
Parallel:
每个代理处理不同的子任务,如数据提取、Web检索和摘要,它们的输出合并为一个结果。
非常适合在文档解析或API编排等高吞吐量管道中减少延迟。
Sequential:
每个代理都一步一步地增加价值,比如一个代理生成代码,另一个代理审查代码,第三个代理部署代码。
您将在工作流自动化、ETL链和多步推理管道中看到这一点。
循环loop:
代理商不断完善自己的产出,直到达到所需的质量。
非常适合校对、生成报告或创造性迭代,系统在最终确定结果之前会再次思考。
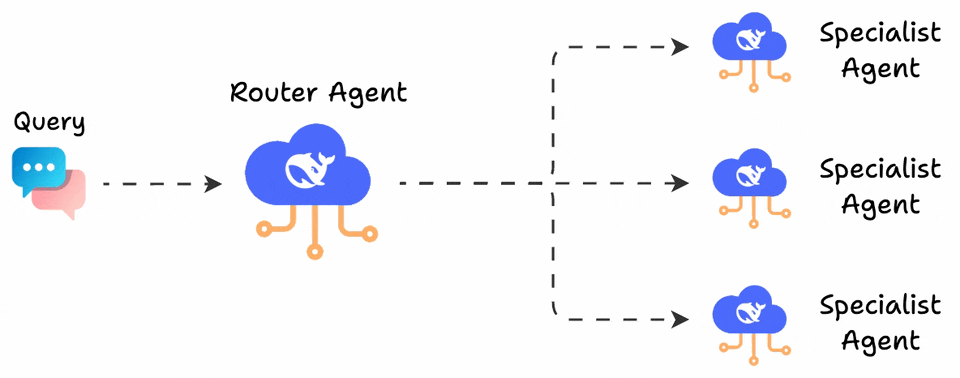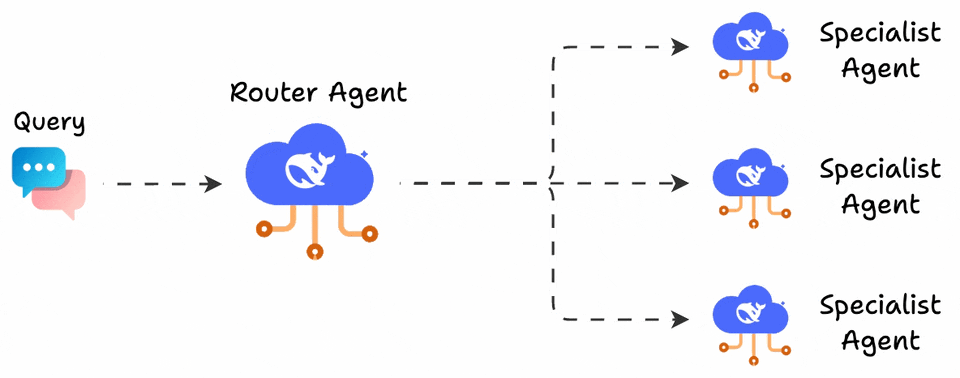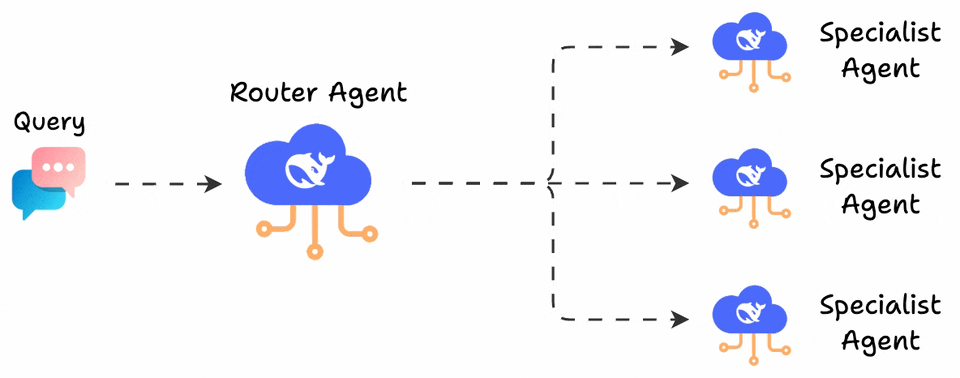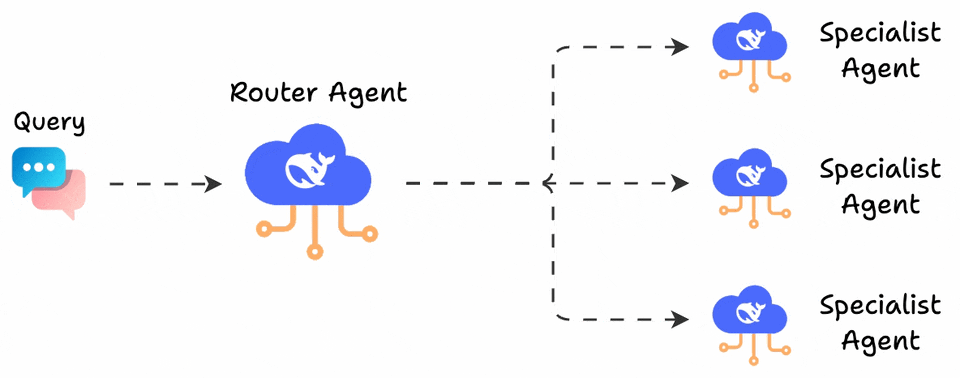
Router:
在这里,控制器代理将任务路由到正确的专家。例如,用户对金融的查询会转到FinAgent,对法律的查询会转移到LawAgent。
它是上下文感知代理路由的基础,正如在新兴的MCP/A2A风格框架中所见。
Aggregator:
许多代理生成部分结果,主代理将这些结果合并为一个最终输出。因此,每个代理人形成一个意见,中央代理人将这些意见汇总成共识。
常见于RAG检索融合、投票系统等。
Network:
这里没有明确的等级制度,代理人只是自由地交谈,动态地共享上下文。
用于仿真、多代理游戏和需要自由形式行为的集体推理系统。
Hierarchi:
高级规划代理将次级任务委派给工人,跟踪他们的进度,并做出最后的决定。这就像一个经理和他们的团队。
选择构建多智能体系统的模式选择时:
- 设计原则:拒绝 "形式优先",聚焦 "效率本质""
- 现实痛点:"搭框架易,建协作难"
- 避免工作重复(如两个智能体同时处理同一任务,浪费资源)
- 本质导向:协作逻辑比 "数量 / 形式" 更重要
初次着手构建对话智能体时,像LangGraph这样的基于图的架构会给人一种直观且熟悉的感觉。路由模式和专门的节点清晰地映射了我们对功能组织的思考方式。这也是这些模式如此受欢迎的原因。
本文将展示基于路由的架构在自然、自由形式的对话中如何存在固有缺陷------源于根本性的架构限制。现在了解这些局限性,能避免你日后发现基于图的系统无法扩展以应对用户实际的对话方式时,不得不进行彻底重写。
下面详细分析主要差异,解释LangGraph的常见模式在对话式人工智能中会带来哪些挑战,并向你说明Parlant为何以及如何以不同方式解决这些问题。
LangGraph是一个通过明确的基于图的编排来构建智能体工作流的框架。它在任务分解、多步骤自动化以及需要精确控制执行流程的场景中表现出色。
Parlant 是一款专为面向客户的自然对话设计的人工智能对齐引擎。它旨在处理用户不遵循脚本的自由形式对话:用户可以自由切换话题,并期望能同时在多个语境下获得连贯的回应。
它们解决不同的问题。实际上,它们可以协同工作------LangGraph 可以作为一个低级别的编排框架,由 Parlant 智能体的工具触发,用于复杂的检索、行动工作流或专门的推理任务。
理解LangGraph的方法
LangGraph 将智能体应用表示为图,其中节点是计算步骤(大语言模型调用、工具调用),边定义控制流。这种架构在工作流自动化和任务编排方面功能强大。
常见的LangGraph模式
使用LangGraph构建智能体时,最受欢迎的模式包括:
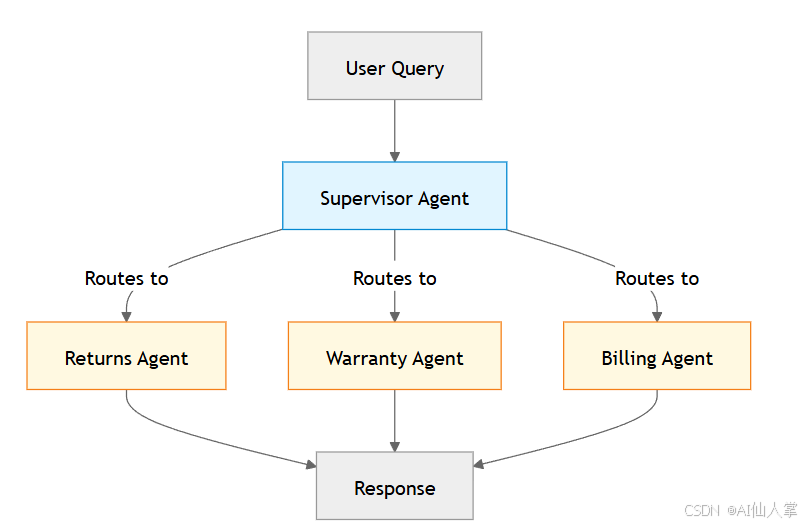
1. 主管(路由器)模式
一个中央协调器( supervisor )会根据查询类型将请求路由到专门的智能体。每个专门的智能体都有自己针对特定领域优化的系统提示词。
python
# Simplified LangGraph supervisor pattern
from langgraph.graph import StateGraph
# Define specialized agents
returns_agent = create_agent("You are an expert in returns...")
warranty_agent = create_agent("You are an expert in warranties...")
billing_agent = create_agent("You are an expert in billing...")
# Supervisor routes to the right agent
def supervisor_node(state):
# LLM decides which agent should handle this
next_agent = supervisor_llm.invoke(state["messages"])
return {"next": next_agent}
workflow = StateGraph()
workflow.add_node("supervisor", supervisor_node)
workflow.add_node("returns_agent", returns_agent)
workflow.add_node("warranty_agent", warranty_agent)
workflow.add_node("billing_agent", billing_agent)
workflow.add_conditional_edges("supervisor", route_to_agent)2. 多智能体Network
智能体以多对多的模式进行通信,每个智能体可根据需要调用其他智能体。这提供了灵活性,但需要精心设计的协调逻辑。

python
# Multi-agent network pattern
from langgraph.graph import StateGraph
# Each agent can invoke others
def research_agent(state):
result = research_llm.invoke(state["messages"])
if needs_writing_help(result):
# Agent decides to call writing agent
return {"next": "writing_agent", "data": result}
return {"messages": result}
def writing_agent(state):
result = writing_llm.invoke(state["messages"])
if needs_fact_check(result):
# Agent decides to call research agent
return {"next": "research_agent", "data": result}
return {"messages": result}
# Build network with many-to-many connections
workflow = StateGraph()
workflow.add_node("research_agent", research_agent)
workflow.add_node("writing_agent", writing_agent)
workflow.add_node("editing_agent", editing_agent)
workflow.add_node("review_agent", review_agent)
# Each agent can transition to multiple others
workflow.add_conditional_edges("research_agent", route_from_research)
workflow.add_conditional_edges("writing_agent", route_from_writing)
workflow.add_conditional_edges("editing_agent", route_from_editing)3. 层级团队
监督智能体管理着自己的专业智能体团队,为复杂的工作流程创建嵌套结构。
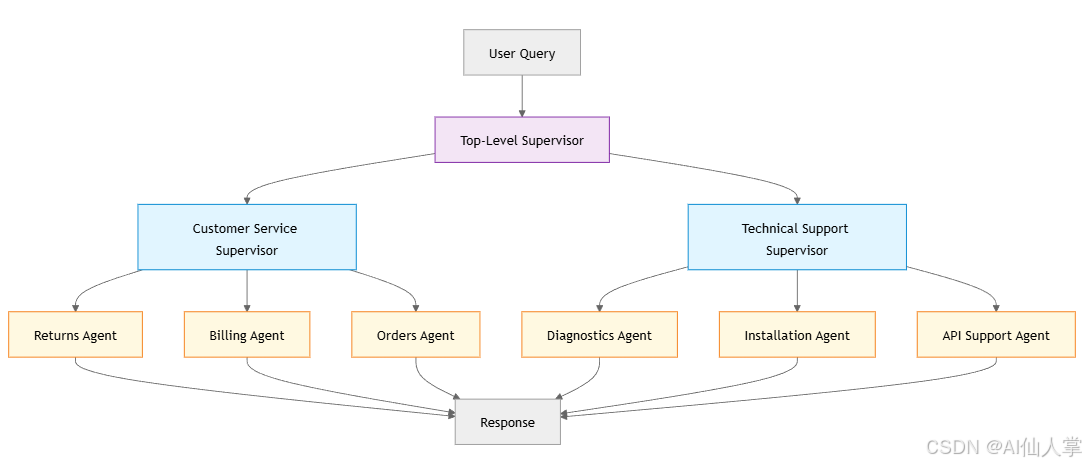
python
# Hierarchical teams pattern
from langgraph.graph import StateGraph
# Top-level supervisor
def main_supervisor(state):
category = categorize_query(state["messages"])
if category == "customer_service":
return {"next": "customer_service_supervisor"}
elif category == "technical":
return {"next": "technical_supervisor"}
# Mid-level supervisors manage specialized teams
def customer_service_supervisor(state):
subcategory = categorize_cs_query(state["messages"])
return {"next": f"{subcategory}_agent"}
def technical_supervisor(state):
subcategory = categorize_tech_query(state["messages"])
return {"next": f"{subcategory}_agent"}
# Build hierarchical structure
workflow = StateGraph()
workflow.add_node("MS", main_supervisor)
workflow.add_node("CSS", customer_service_supervisor)
workflow.add_node("TS", technical_supervisor)
# Add specialized agents under each supervisor
workflow.add_node("RA", returns_agent)
workflow.add_node("BA", billing_agent)
workflow.add_node("DA", diagnostics_agent)
workflow.add_node("ASA", api_support_agent)
workflow.add_conditional_edges("MS", route_to_team)
workflow.add_conditional_edges("CSS", route_to_cs_agent)
workflow.add_conditional_edges("TS", route_to_tech_agent)LangGraph 的优势
LangGraph确实擅长于:
- 工作流自动化与编排
- 将任务分解为专门的子任务
- 非对话式智能体应用程序
- 需要模板控制流的场景
该框架让你能够精确控制执行路径,这正是许多智能体流程(特别是ETL类型的工作流)所需要的。
但挑战也随之而来......

路由模式的问题
这就是对话式人工智能变得有趣的地方。路由器模式(即"主管"),专门节点拥有特定的任务和主题,对于工作流编排非常有效,但当用户进行自然、自由形式的对话时,会带来固有的挑战。
让我为你详细介绍这种架构所带来的问题。
孤立的专业化本质上是有缺陷的
想象一下。一位客户发来消息:
"嘿,我需要退回这台笔记本电脑。另外,你们的更换产品保修期是多久?"
在路由系统中,该消息会被路由到一个专门的智能体。
假设它分配给了退货智能体。这个智能体有一个为退货优化的系统提示词。它对退货政策了如指掌。但保修方面呢?那是保修智能体的领域。
退货处理人员现在面临四个处理保修问题的实际"备选方案",但实际上没有一个是可行的:
选项1:忽略保修问题
"当然,我可以帮您办理退货。您的订单号是多少?"
↪ 糟糕的用户体验。客户明确询问了保修事宜,却未得到任何回应。
一个好的对话框架不应该是这样的。
选项2:承认局限性
"我可以协助办理退货。至于更换产品的保修事宜,我不确定具体细节。"
↪ 这不仅很尴尬,而且从整体智能体的角度来看是不正确的。整体智能体能够处理保修问题------只是路由到了错误的专用节点。这会让用户和开发者都感到沮丧,并导致脱节的用户体验。
这也不是一个好的对话框架应有的表现。
选项3:虚构一个答案
"当然可以!我们的退货政策是30天,所有更换的产品都有5年保修期。"
↪ 危险且极其常见------而且难以用大语言模型来预防。退货智能体并非基于保修信息,但作为大语言模型,它往往会尝试编造答案。那个"5年保修"可能完全是错误的。
这也不是一个好的对话框架应该表现的方式。
选项4:堆叠话题
"让我先帮您处理退货事宜,然后我们再解决您关于保修的问题。"
↪ 这实际上(某种程度上?)是合理的。智能体认可了这两个问题,并提议按顺序处理它们。许多LangGraph的实现正是这样做的。
但即便是选项4,也并非一个良好的对话框架应有的表现。它仍然存在一个根本性的设计缺陷,因为这往往会导致糟糕的用户体验。
当你的人工智能用户体验不佳时,许多用户在处理重要事务时会对其产生不信任,进而放弃使用你的人工智能代理,转而选择他们更熟悉的人工代理服务。这会让你白白损失收益,也会降低客户满意度。
让我们来看看这会如何导致摩擦。
第一个常见问题:交织的主题
许多自然对话并非以"两个独立的问题"形式呈现。从后端分类的角度来看,"话题"在整个互动过程中自然地相互交织。强行进行人为分割会显得很机械。想想看:
"我买这台笔记本电脑是为了做生意,但它坏了。我可以把它退回去,并为更换的电脑拿到税务发票吗?"
退货流程和营业税文件问题并非用户堆砌的两个独立话题,它们之间存在着紧密的联系:
- 税额发票取决于退货是否得到处理
- 企业客户可能有不同的退货政策
- 更换时机影响文件的出具时间
强迫智能体说"让我先处理您的退货,然后我们再讨论发票事宜"会产生不必要的摩擦,并引发本可避免的疑问和反对意见。
在自然对话中,你会期望这两个方面被一同提及:
"当然可以,我们可以处理这次退货。关于您的换货,我会确保您收到一张正规的税务发票。让我调出您的账户信息------这家企业是用同一个邮箱注册的吗?"
这正是一个设计良好的对话框架应该实现的目标,而这也正是Parlant的设计目标之一。
第二个常见问题:重复出现的话题
自然对话中另一个频繁出现的模式是:话题不会只出现一次就消失。用户会在不同话题间切换,然后又回到之前的话题。而且一旦多个话题进入对话,它们往往会在剩下的讨论中保持相关性------至少在某种程度上是这样。
试想以下对话流程:
顾客:"我想退回上周买的这台笔记本电脑。"
智能体(退货业务):"我可以帮您处理。您能提供一下订单号吗?"
顾客:"好的,我来买一个,稍等。对了,你们有新款现货吗?就是那款电池更好的。"
智能体(库存):"是的,我们有带扩展电池的XPS 15现货。需要我为您预留一台吗?"
顾客:"是的,太好了。那如果我把这个退回去,换那个新型号,我需要补差价吗,还是可以直接换?"
现在的对话需要同时涉及退货流程以及库存/定价信息。客户并非在问两个独立的问题------他们想了解退货和新购买之间的关系。
在路由器系统中,这条消息会被路由到一个专门的智能体。如果它被发送到退货智能体,该智能体可以处理退货部分,但不了解当前的库存定价。或者,它可能会被路由到账单智能体,该智能体可以讨论定价问题,但不了解退货相关事宜。
挑战在于,一旦两个话题都被引入,对话的其余部分很可能需要以某种形式提及这两个话题。
用户不会想着*"现在我处于退货模式"或者"现在我处于库存模式"。*他们会从整体上考虑自己的情况,而这种情况同时涉及这两个领域。
此后的每条消息都将由一个专门的节点处理,该节点对于其他相关主题是脱节的。对话的完整性和连贯性恰恰在最需要保持连贯的时候出现了断裂。
一个能够理解自然对话的对话式AI框架应该支持无缝的上下文切换和多主题感知,而这正是Parlant在设计时特意要实现的目标之一。
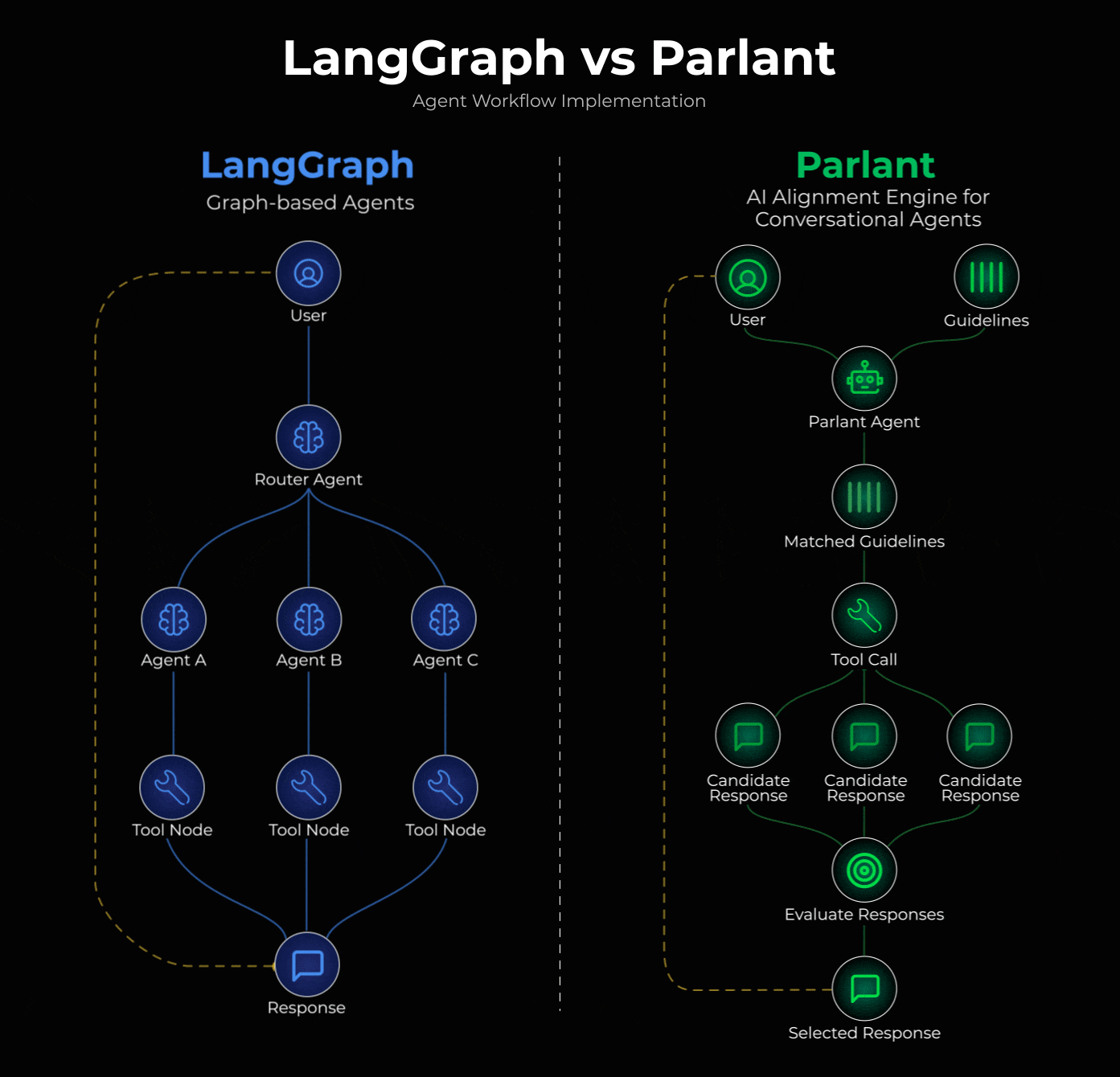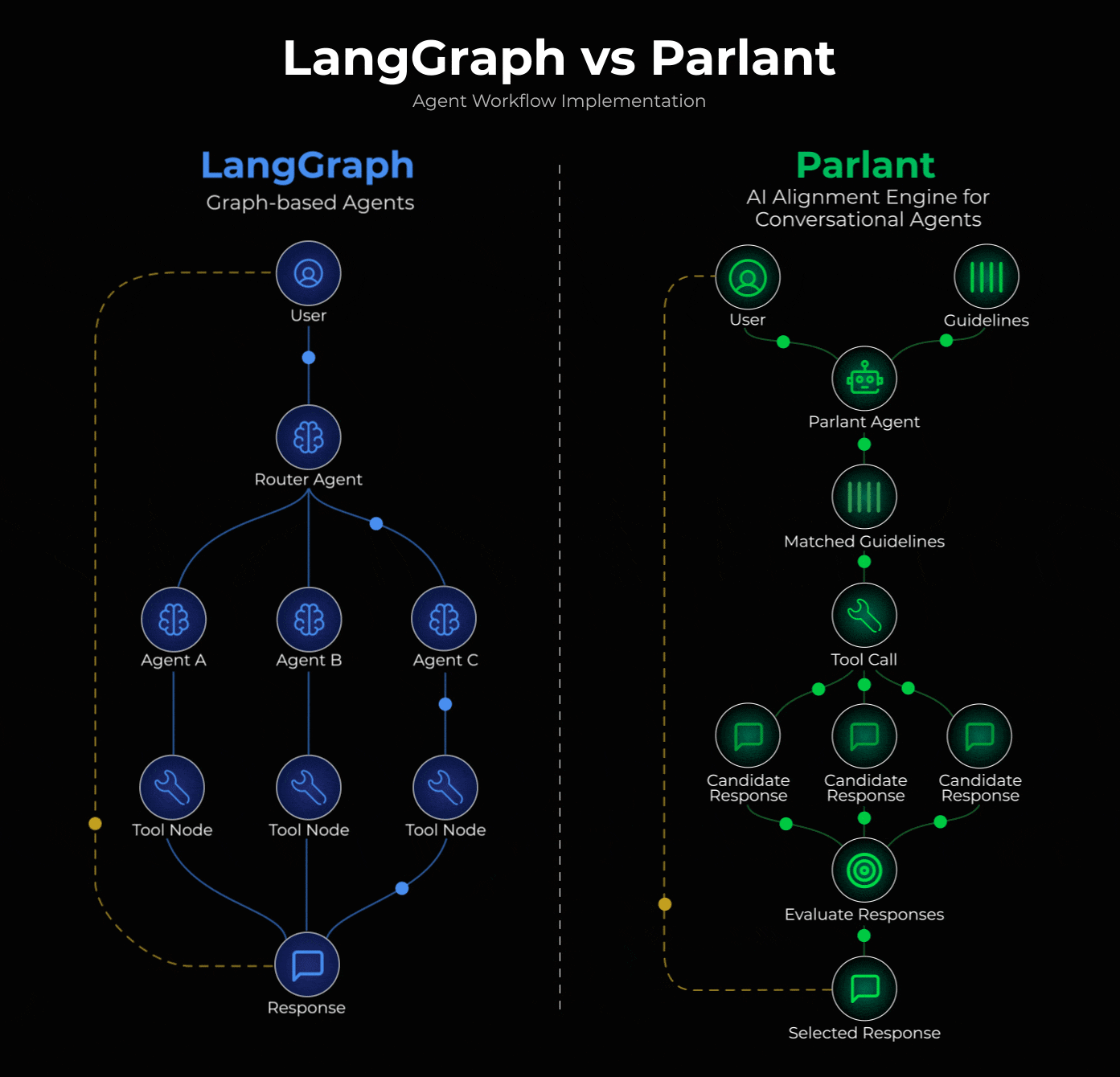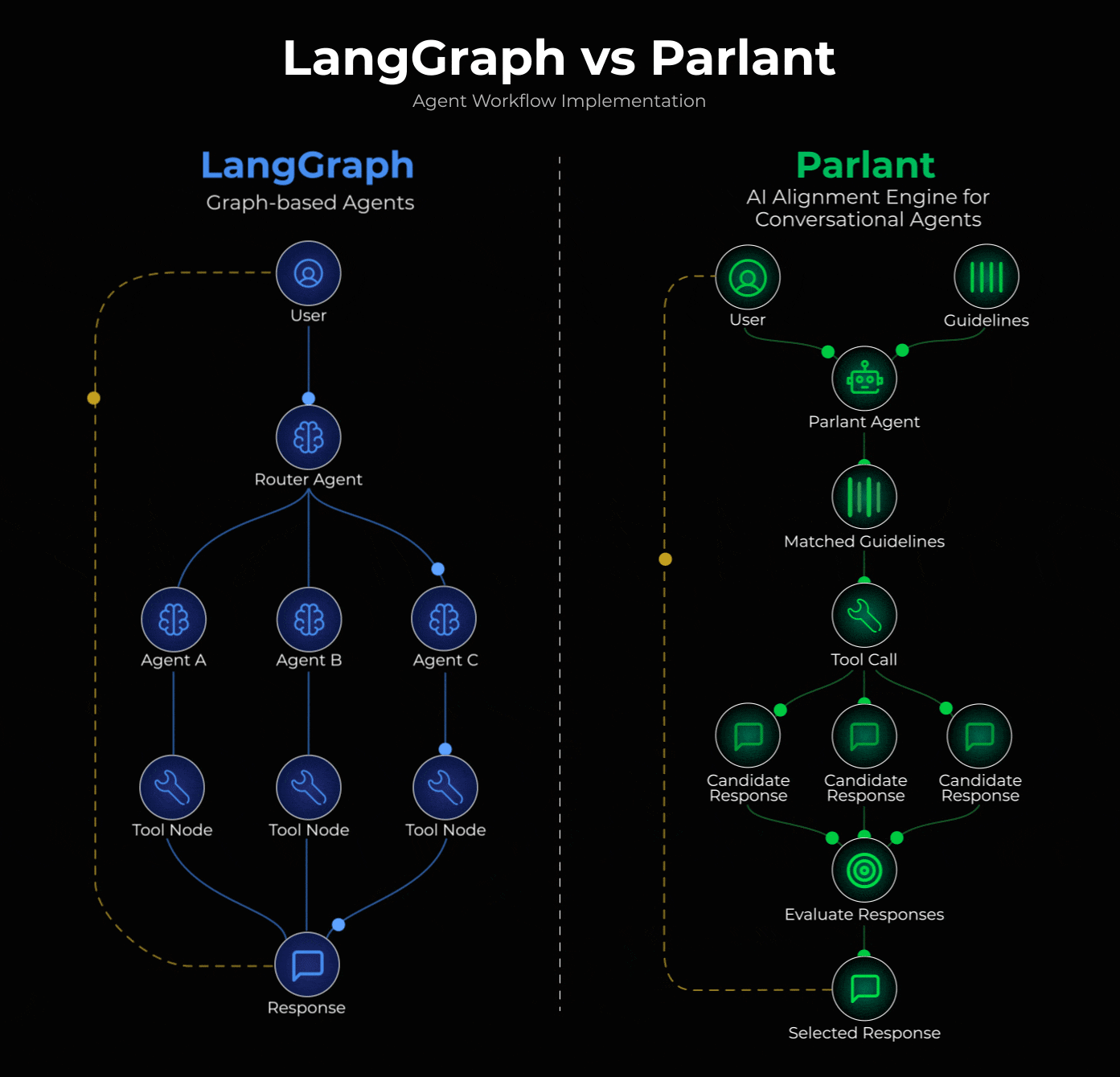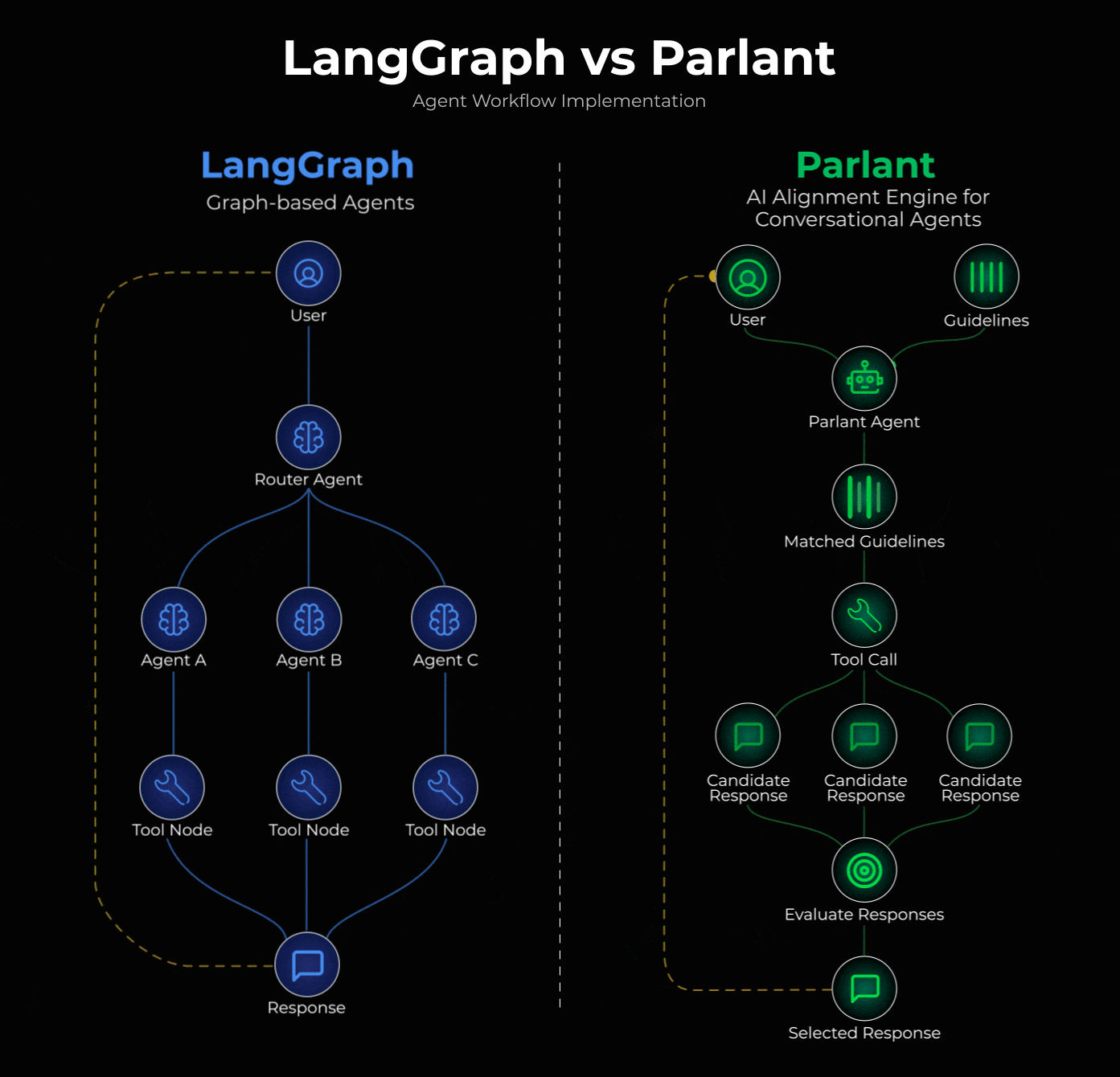
阐述核心设计问题
当你将对话路由到专门处理主题X的节点时,该节点本质上并不擅长处理主题Y。
真实的对话不会受领域边界的限制。用户会在单条消息中混合多个话题,在不同话题间跳转,并期望得到能够整合多种语境的连贯回应。而路由/专用节点架构会迫使你选择某一领域的基础信息,却要以牺牲其他领域的信息为代价。
Parlant如何处理自由形式对话
我们创建Parlant是源于对机械AI对话中这些长期存在的问题的清晰认识,以及由此产生的挫败感。
因此,我们决定采用一种从根本上不同的方法,这种方法针对自然对话进行了优化:即动态组装全面的上下文,而非人为分割的路径选择。
动态指南匹配
Parlant 使用的推理技术(称为 ARQ)专门构建以获得对代理的精确控制。
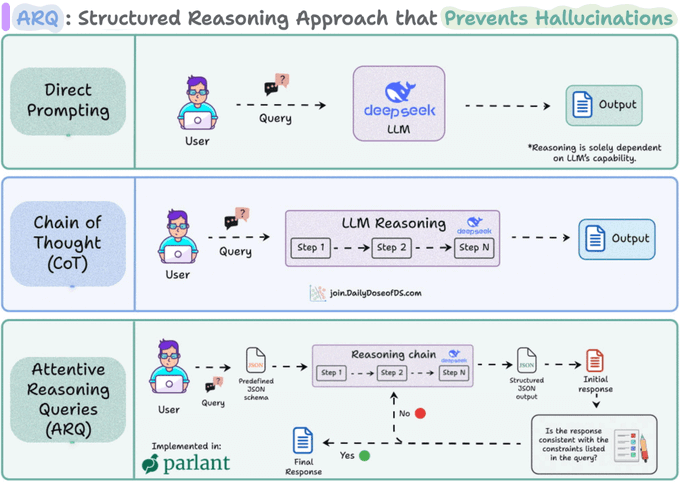
Parlant不会将消息路由到专门的节点,而是会评估你的所有指导原则和其他上下文信息,并只为每个对话轮次(即每个用户可见的大语言模型请求)加载相关的内容。
python
# Parlant approach - no routing, just conditional guidelines
await agent.create_guideline(
condition="The customer wants to return an item",
action="First acknowledge their concern, explain our 30-day return policy, "
"and ask for their order number"
)
await agent.create_guideline(
condition="The customer asks about warranty on replacements",
action="Explain that all replacement items come with our standard warranty, "
"which covers manufacturing defects for 1 year from the replacement date"
)
await agent.create_guideline(
condition="The customer needs a tax invoice for a business purchase",
action="Let them know we'll include a proper tax invoice with their order documentation"
)
await agent.create_guideline(
condition="The customer asks about store hours",
action="Tell them we're open Monday-Friday 9-8, Saturday 10-6, and Sunday 12-5"
)注意这里的不同之处:没有路由决策。当客户说"我需要为我的公司退回这台笔记本电脑,并获得更换产品的税务发票"时,Parlant的指南匹配器会评估所有指南,并确定其中三条与上下文相关:
- 退货指南(客户想要退货)
- 税务发票指南(企业采购场景)
- 保修指南(提及更换)
它们会同时加载到大型语言模型的上下文中。智能体生成的回应会动态地以所有这些内容为依据:
"我很乐意为您处理退货事宜,并确保您能拿到合适的凭证。我来调取一下您的订单------您能提供一下订单号吗?拿到订单号后,我就会为您办理退货,同时确保您收到的换货会附带一张税务发票,供您留存业务记录。确认一下,这家企业是用与该订单相同的邮箱注册的吗?"
因此,Parlant智能体不会在不同领域之间做出选择,而是会按需整合所有相关的基础背景信息。
为什么这对会话连贯性有效
在现实世界中,客户对话往往会打破你在教科书中学到的那种结构化对话的想象。
帕兰特的方法解决了我们之前发现的问题:
无人工分隔:由于智能体可同时获取所有相关指南,因此能够自然地处理相互交织的主题。
无生硬串联:当两个主题都有简短答案时,智能体可以自然地将它们一起阐述。
无上下文碎片化:智能体之间不存在交接问题,因为根本没有独立的智能体。只有一个智能体,其上下文是动态且持续组合的。
一致的基础:智能体基于所有与语境相关的信息,而非仅局限于某一领域的专业知识。这是Parlant能在面向客户的场景中如此无缝高效地保持合规性并避免幻觉的重要原因之一。
parlant如何保持准确性的可扩展性
当然,如果你只是加载所有相关指南,大语言模型的上下文就会变得臃肿。这就好比把所有东西都塞进一个巨大的系统提示词里,会导致"指令诅咒"------过多的同时性指令会降低性能(更别说具有讽刺意味的是,由于标记数量增加,你最终会为这种下降的性能支付更多费用)。
这正是Parlant架构发挥主要作用的地方。该框架在加载上下文之前,会使用出人意料地复杂且细致的指南匹配来准确判断相关性。

LangGraph在对话式人工智能中的适用场景
我想明确一点:LangGraph并非对所有对话式人工智能都不适用。如果你的使用场景合适,用它能比用Parlant取得更好的效果。
当满足以下条件时,LangGraph 适用于对话智能体:
对话范围较窄且流程简洁:你正在通过特定流程(如入职引导、数据收集或结构化故障排除流程)采访用户,在此过程中,用户必须从提供的选项中选择回应,而非自由作答。
用户遵循引导路径:这种交互模式严格要求用户按固定顺序回答问题,而非自由交谈。
有限的对话自由度:不期望用户在对话过程中突然提出意外问题、自主切换话题或同时引用多个语境。
清晰的状态转换:对话具有定义明确的阶段,在这些阶段中,"路由"到下一步是合理的。
诚然,这些都是合理的使用场景,在这些场景中,LangGraph可能会产生出色的结果,且其计算开销远低于Parlant所投入的(Parlant的投入是为了在真实的对话环境中最大限度地提高准确性和用户体验)。
关键区别在于交互模型。如果期望用户始终遵循严格的流程,LangGraph的路由功能会表现出色,并且不太可能出现繁琐的设计问题和操作故障。
如果您的用户在自然且自由地交谈,挑战就会在这时出现。而这正是Parlant的优势所在,因为它就是为这种使用场景精心设计的。
将LangGraph和Parlant一起使用
有趣的是:这些框架并非相互竞争,而是互补的。
LangGraph 可以作为 Parlant 中一个底层的编排工具。我来给你展示一个实际示例:
python
# A Parlant tool that uses LangGraph internally for complex retrieval
@p.tool
async def find_relevant_documentation(
context: p.ToolContext,
query: str
) -> p.ToolResult:
# LangGraph orchestrates the multi-step retrieval workflow
result = await langgraph_workflow.invoke({
"query": query,
"customer": p.Customer.current,
})
return p.ToolResult(
data=result["synthesized_answer"],
canned_response_fields={
"documentation": result["source_links"],
},
)
# The tool is used within a Parlant guideline
await agent.create_guideline(
condition="The customer asks about a technical feature or API",
action="Look up the info and provide an explanation if possible",
tools=[find_relevant_documentation],
)在这种模式下:
- Parlant负责处理和合成对话流程、动态上下文管理以及自然对话。
- LangGraph 处理复杂的内部知识库工作流(检索、重排序、合成)
这结合了两者的优势:
- Parlant 确保对话连贯、引导得当且自然流畅。
- LangGraph为智能体处理提供强大的工作流编排能力
架构差异
从最高层面来看,核心区别如下:
LangGraph:基于显式图的控制流
LangGraph 将你的应用程序表示为具有明确节点和边的图。你可以定义路由逻辑、指定转换并控制执行流程。这非常适用于:
- 工作流自动化
- 任务分解
- 具有清晰阶段的多步骤流程
- 需要对执行顺序进行精确控制的场景
当你清楚从输入中能期待什么时,这会非常好用------但对于原始的对话内容来说,情况并非如此。
Parlant:动态语境整合
这正是Parlant能帮你管控合同,并清晰高效地处理那些复杂对话部分的地方。
Parlant 将你的应用程序呈现为自然对话中的一组条件性指南和流程。
它没有在专门的节点之间进行路由,而是为每个回合动态整合相关上下文。这在以下方面表现出色:
- 自由形式的对话式人工智能
- 用户不遵循脚本的自然对话
- 话题以不可预测的方式交织的场景
- 合规性至关重要的面向客户的应用程序
两种方法都是有效的。正确的选择取决于你的交互模型。
如何选择使用哪种方法
以下是一份实用指南:
当你需要明确的编排和对执行的精确控制时,请使用LangGraph:例如多步骤任务、数据处理管道以及顺序至关重要的智能体工作流等工作流自动化;将复杂问题分解为协调子任务的任务分解,或针对非对话型工作负载的多智能体协作;有限的、有引导的对话流程,如结构化入职、逐步数据收集或故障排除向导。
在构建自由形式、面向客户的智能体时,请使用Parlant,这类智能体中用户可以自然对话,无需遵循固定脚本,例如客服聊天机器人、销售与咨询助手,或任何需要全面且一致的领域适配的场景。当对话涉及多个话题、存在打断情况且需要自然的一来一往交流时;在合规要求严格的场景中,即关键业务交互中必须保证行为合规且避免未经授权的表述时;以及在多语境对话中,即用户同时提及多个话题、问题相互交织而非彼此独立,且智能体必须给出连贯的跨话题回应时,Parlant的优势尤为突出。
当你既需要流畅的对话,又需要复杂的工作流程时,两者都要用:
- 具有复杂检索功能(LangGraph)的对话智能体(Parlant)
- 需要多步骤工具编排的自然对话
- 面向客户的人工智能,配备复杂的后端流程
"我就不能用LangGraph来构建这个吗?"
到这里,你可能会想:"很好,我理解了动态上下文组装方法。那为什么我不能自己用LangGraph来构建这种模式呢?"
答案是:你完全可以做到。LangGraph 的灵活性足以实现像 Parlant 这样的动态指南匹配和上下文组装系统(尽管 Parlant 实际上并非基于它构建)。
没有什么能阻止你去构建它。但是,在你投入其中之前,要考虑到你基本上是在从零开始构建Parlant。
为什么呢?让我分享一个来之不易的教训,讲讲对齐工程为何最终变成了一个出乎意料的复杂难题。
动态语境组合的复杂性
我们开始构建Parlant时,曾以为动态语境组合会很简单:匹配相关指南,将其加载到语境中,任务就完成了。但很快我们就发现,其复杂性远比最初看起来要深得多。
指南匹配的复杂性:
- 语义匹配不仅仅关乎准确性(尽管这本身就是一项巨大的挑战------只需看看Parlant中存在多少专门的指南子匹配器就知道了)
- 你需要处理边缘情况:部分相关的指导方针、相互冲突的条件、不同的时间范围,以及记录已完成和未完成的事项,以避免过度遵循指示。
- 假阳性和假阴性会导致不同的故障模式,在思考智能体设计时需要缓解这些问题(Parlant通过其对话优化的工具调用和预设响应系统解决了这一点)
运行时性能:
简单的实现会产生不可接受的延迟;要缓解这一问题,就需要精心调整的缓存策略以及不同流水线阶段的并行执行------即便在规模相对较小时也是如此。
连贯、整体的架构:
指南需要与工具巧妙地交互。需要跟踪流程状态;预设回复需要与匹配的指南和工具输出相协调,并且变量、词汇表和关系需要纳入语境构建中。
在一个浑然天成的集成闭环中,每个组件都会对其他组件产生微妙的影响。您的开发工作流程也因此变得井然有序。
这就是Parlant所提供的,而要实现这一切确实付出了巨大的努力!
Parlant目前的实现版本凝聚了无数次经过实战检验的迭代、性能优化,以及从实际部署中汲取的经验教训。单是准则匹配系统,就在我们直面这些挑战中诸多令人意想不到的细微差别时,经历了多次架构重写。
如果你正考虑使用LangGraph构建自己的动态上下文组装系统,说实话,我建议你首先:
- 阅读Parlant的功能文档,以了解您将遇到的所有挑战范围
- 考虑妥善解决这些问题所需的工程投入
- 评估你的用例是否有Parlant未满足的独特需求(在这种情况下,重写比在Parlant的GitHub上提交问题或贡献PR更有意义)
Parlant是完全开源的
记住,Parlant 并非黑箱。它是完全开源的,这意味着你可以:
- 精确查看我们是如何解决这些问题的
- 扩展或修改组件以满足您的需求
- 将改进成果回馈给社区
- 依托一支优秀的开发团队多年来经过生产验证的技术成果进行构建!
无论哪种方式,了解那些已经构建完成并经过实战检验的成果,都能为你节省数月的开发时间,帮助你避开我们已经遇到并解决的陷阱------而且我们还将继续为这个新兴的现代对话式人工智能社区解决问题并进行优化。
做出正确选择
人们对Parlant和LangGraph产生混淆是可以理解的:它们都是用于构建大语言模型的强大框架。但要理解两者的区别,关键在于一个问题:
你正在构建什么样的交互?
如果你正在构建工作流、编排流程或引导式流程,那么LangGraph是很棒的选择。
如果你正在构建用户不会遵循固定脚本的自由形式对话式人工智能,那么Parlant就是专门为此设计的。
如果你两者都需要→它们可以完美地协同工作。
很明显,这两种框架在人工智能智能体生态系统中都有其立足之地。根据你的交互模型进行选择,并且在合理的情况下,不要害怕将它们结合使用。