大语言模型(LLM)在处理长文档时,普遍面临"计算开销随文本长度平方级增长"的瓶颈。为破解这一难题,视觉压缩 成为了一条富有前景的新路径------不再单纯依赖文本Token,而是将文本转换为图像,利用视觉编码器进行高效压缩。
本文将深入对比两种以视觉压缩为核心思路的模型:DeepSeek-OCR(专注于文档识别)与 Glyph(专注于通用长文本理解),探讨它们如何以不同的方式革新LLM处理长文本的能力。
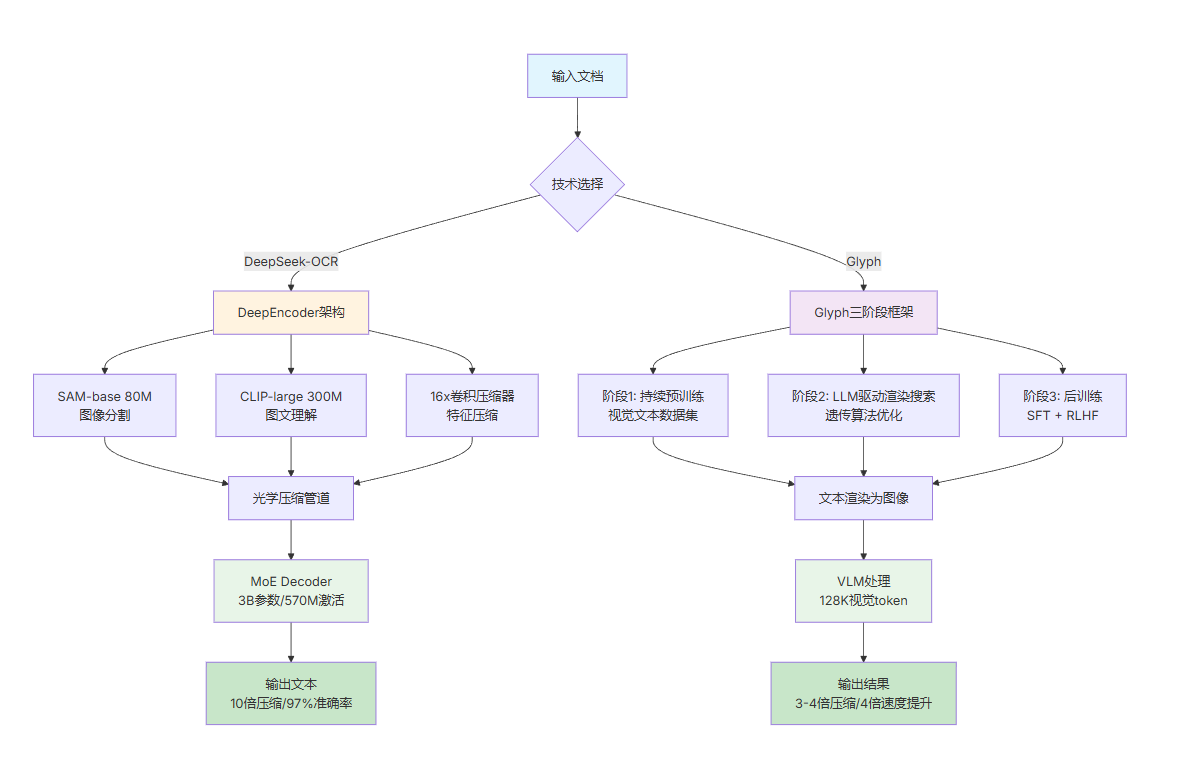
一、DeepSeek-OCR:以视觉压缩革新OCR
1. 核心目标与创新范式
解决LLM处理长文本时"计算开销随序列长度平方级增长"的问题,提出 "上下文光学压缩"(Contexts Optical Compression) 范式:
将长文本渲染为图像 → 用视觉编码器压缩为少量"视觉token" → 再由语言模型"解压"还原为原始文本,实现"以图载文、少token传多信息"。
2. 技术核心架构
模型由两部分组成,兼顾压缩效率与精度:
- DeepEncoder(视觉编码器):结合SAM(局部感知)与CLIP(全局知识),加入16×卷积压缩模块(将4096个patch token压至256个),支持多分辨率输入(含"高达模式"动态拼接),激活内存低,适合高分辨率文档。
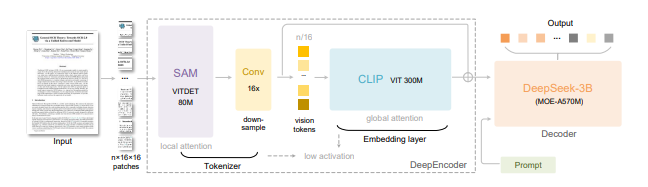
- DeepSeek-3B-MoE(解码器):采用混合专家(Mixture-of-Experts)架构,激活参数仅570M,能高效从视觉token中重建文本,平衡语言能力与推理成本。
3. 关键性能表现
- 压缩与精度 :压缩比≤10×时OCR精度达97%,压缩至20×时精度仍约60%;在OmniDocBench基准上,100个视觉token可超越GOT-OCR2.0 (256个token),800个token超越MinerU2.0(7000+token)。

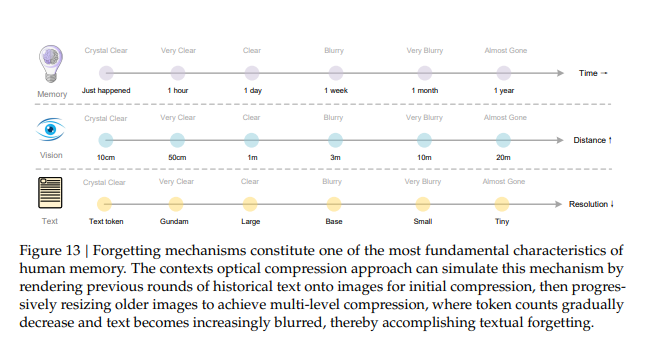
4. 深层意义-LLM 的"记忆机制"提供新思路
提出"视觉压缩模拟人类遗忘机制"的思路:近期对话用高分辨率图像(高保真记忆),久远历史逐步缩小图像(token减少、信息模糊),为构建"无限上下文LLM"提供新路径------用视觉做记忆分层,平衡信息保留与计算成本。
二、Glyph:以视觉-文本压缩突破LLM上下文窗口限制
Glyph 是一个通过视觉-文本压缩来扩展上下文长度的框架。 与扩展基于令牌的上下文窗口不同,Glyph
将长文本序列渲染为图像,并使用视觉-语言模型(VLMs)进行处理。
这种设计将长上下文建模的挑战转化为多模态问题,显著降低了计算和内存成本,同时保留了语义信息。
基座模型:GLM-4.1V-9B-Base
1. 核心目标与创新路径
解决"扩展LLM上下文窗口需巨大资源消耗"的痛点,提出 "视觉化输入扩展上下文" 新范式:不修改模型架构,而是将文本渲染为图像,让模型以"看"的方式理解超长文本。模型能够在有限的 token 数量下接收更丰富的上下文信息,实现高效的文本压缩。
2. 核心框架(三阶段)
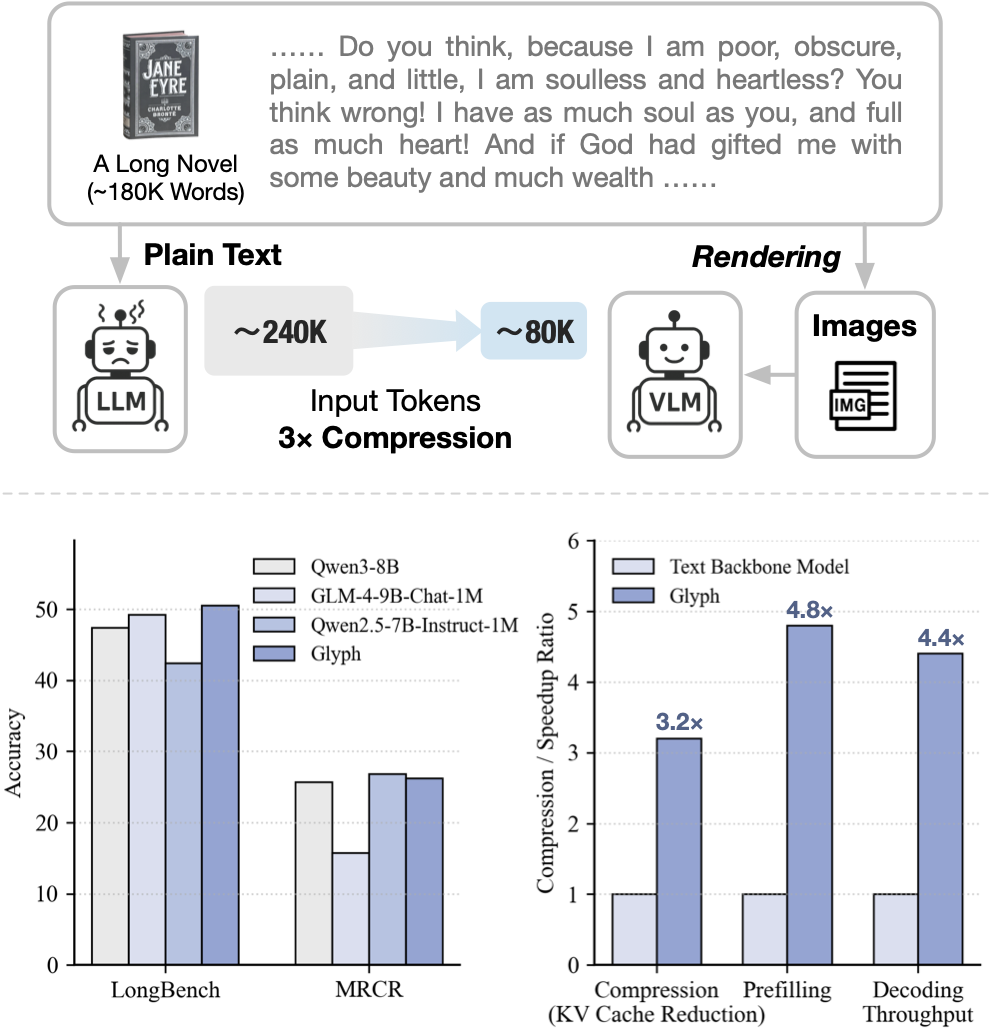
以小说《简·爱》(约24万文本token)为例,传统128K上下文的LLM无法容纳全书,截断处理极易导致需要全局理解问题(如"简离开桑菲尔德后陷入困境时,谁给予了她支持?")回答出错。相比之下,Glyph可将整本书渲染为紧凑的图像(约8万个视觉token),使得128K上下文的VLM能够完整处理整部小说并准确回答此类问题。
- 持续预训练:将长文本渲染为文档、网页、代码等多种视觉风格,构建OCR识别、图文建模、视觉补全等任务,让模型建立视觉-语言跨模态语义对齐能力。
- LLM驱动渲染搜索:用LLM驱动的遗传搜索算法,在验证集上自动评估字体、分辨率、排版等渲染配置的性能,迭代找到"压缩率与理解能力最优平衡"的方案。
- 后训练:通过有监督微调(SFT)、强化学习(GRPO算法)优化模型,加入OCR辅助任务强化文字识别能力。
3. 关键实验结果
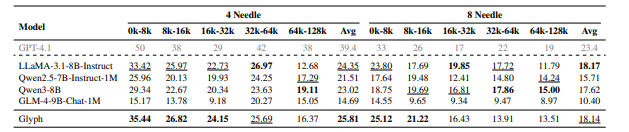
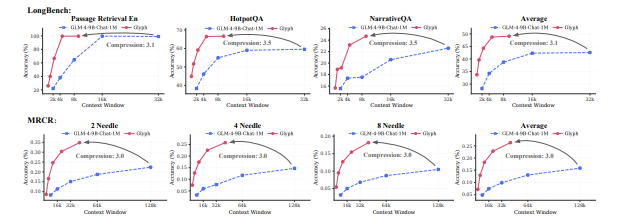
- 压缩与精度 :在LongBench 、MRCR等长文本基准上,实现3-4倍输入压缩率,精度与Qwen3-8B、GLM-4-9B-Chat-1M等主流模型相当。
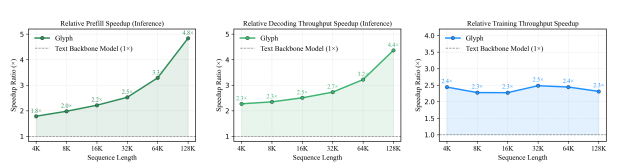
- 效率提升:推理速度提升4倍,训练速度提升2倍,且上下文越长,推理优势越明显;极端场景下(8×压缩比),可利用128K上下文VLM处理百万级token文本任务。
三、两者核心对比小结
- 与传统上下文扩展方法不同:传统靠修改注意力结构或位置编码,Glyph从输入层压缩,
通过视觉-文本压缩实现上下文扩展,如果有望传统靠修改注意力结构或位置编码,将上下文扩展至千万级。 - 与DeepSeek-OCR异同:共同点是均用
视觉token承载文本信息;不同点是DeepSeek-OCR聚焦OCR任务,探索通过视觉压缩下的文本识别能力。Glyph则面向通用长文本任务,验证了视觉模型扩展上下文的可行性,为千万级上下文突破奠定基础。
| 维度 | DeepSeek-OCR | Glyph |
|---|---|---|
| 核心聚焦 | OCR任务(文档解析) | 通用长文本上下文扩展 |
| 核心价值 | 提高OCR效率,探索LLM记忆机制 | 突破LLM上下文窗口限制,提升通用长文本处理效率 |
| 压缩比与精度 | ≤10×压缩精度97%,20×压缩精度60% | 3-4×压缩,精度与主流LLM相当 |
| 额外能力 | 解析图表、多语言OCR | 适配多种文本场景(文档、代码等),支持极端压缩 |