note
- HunyuanVideo-1.5,支持文本生成视频和图片生成视频。支持分辨率1080p,模型大小8.3B。架构上集成DiffusionTransformer(DiT)和3D因果VAE,实现空间维度16×和时间维度4×的压缩率。使用SSTA(选择性滑动块注意力)机制有效剪枝冗余的时空kv块,在720p10秒视频合成中相比FlashAttention-3实现1.87×加速。
文章目录
- note
- 一、研究背景
- 二、HunyuanVideo模型
- 三、实验设计
- 四、结果与分析
- 五、论文评价
- 六、相关问题
-
- [问题1:HunyuanVideo 1.5的稀疏注意力优化(SSTA)机制是如何设计的?](#问题1:HunyuanVideo 1.5的稀疏注意力优化(SSTA)机制是如何设计的?)
- [问题2:HunyuanVideo 1.5在视频超分辨率增强方面采取了哪些措施?](#问题2:HunyuanVideo 1.5在视频超分辨率增强方面采取了哪些措施?)
- [问题3:HunyuanVideo 1.5在多模态理解方面有哪些创新?](#问题3:HunyuanVideo 1.5在多模态理解方面有哪些创新?)
一、研究背景
- 研究问题:这篇文章要解决的问题是如何在保持高效推理的同时,生成高质量的视频。现有的最先进的视频生成模型大多是闭源的,限制了开源社区的创新和访问。
- 研究难点:该问题的研究难点包括:如何在减少参数数量的同时保持高性能;如何有效地进行视频超分辨率以增强视觉质量;如何在长视频序列中减少计算开销并加速推理。
- 相关工作:在闭源领域,Kling2.5、Veo3.1和Sora2等模型达到了最先进的性能。在开源领域,HunyuanVideo、StepVideo和Wan2.2等模型是主要竞争者,但它们在生成质量和推理效率方面仍有不足。
二、HunyuanVideo模型
解决视频生成中的高效推理和高视觉质量问题:
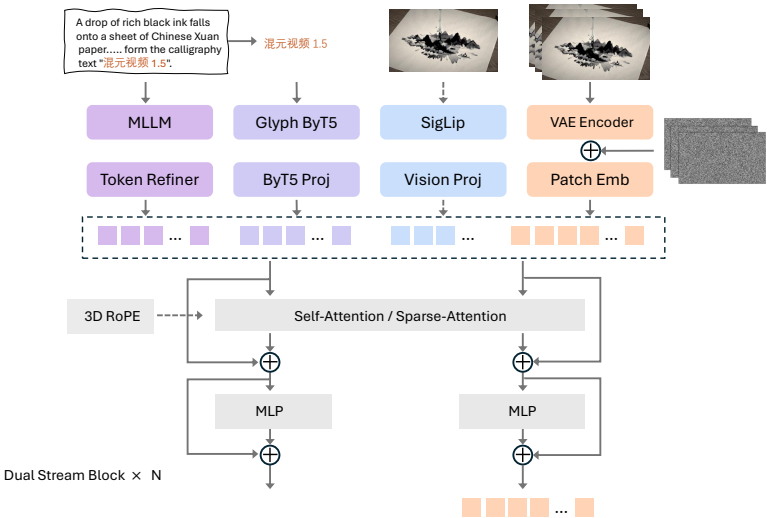
1、轻量级高性能架构:提出了一个高效的架构,集成了一个83亿参数的扩散变压器(DiT)和一个3D因果VAE,实现了空间维度上的16倍压缩和时间轴上的4倍压缩。
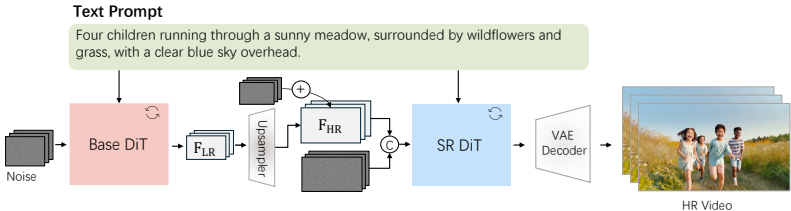
2、视频超分辨率增强:开发了一个高效的几步超分辨率网络,将输出放大到1080p,增强了细节并纠正了失真。
3、稀疏注意力优化:引入了一种新的SSTA(选择性滑动块注意力)机制,动态剪枝冗余的时空令牌,显著减少了长视频序列的计算开销并加速了推理。
4、增强的多模态理解:框架使用了一个大型多模态模型进行精确的双语(中文-英文)理解,结合了ByT5进行专门的字形编码,以增强视频中文本生成的准确性。
5、端到端训练优化:展示了Muon优化器在视频生成模型训练中显著加速收敛,同时多阶段渐进训练策略从预训练到后训练阶段增强了运动连贯性、美学质量和对人类偏好的对齐。
三、实验设计
1、数据准备:训练数据集包括图像和视频数据。图像数据从超过100亿张中筛选出50亿张进行预训练,视频数据则通过分割和过滤机制生成了超过1000万小时的高质量视频片段。
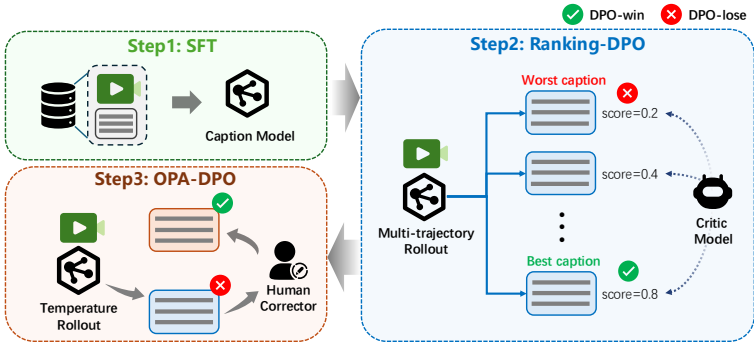
2、字幕生成:开发了三个专门的字幕模型:图像字幕、视频字幕和图像到视频的指示字幕,以生成精确和全面的描述。
3、预训练:通过逐步增加空间分辨率、时间长度和帧率,结合混合任务训练,系统地发展核心生成能力。
4、后训练:包括继续预训练(CPT)、监督微调(SFT)和人类反馈对齐(RLHF),进一步提高了生成质量和任务特定性能。
四、结果与分析
1、评分评估:在文本到视频生成任务中,HunyuanVideo 1.5在多个维度上表现出色,特别是在指令跟随、视觉质量和结构稳定性方面。

2、GSB评估:在文本到视频生成任务中,HunyuanVideo 1.5在大多数评估指标上优于竞争对手,特别是在图像一致性、视觉质量和结构稳定性方面。
五、论文评价
1、优点与创新
- 轻量级高性能架构:提出了一种高效的架构,集成了83亿参数的扩散变压器(DiT)和3D因果VAE,实现了空间维度上的16倍压缩比和时间轴上的4倍压缩比。
- 视频超分辨率增强:开发了一种高效的少步超分辨率网络,将输出提升到1080p,增强了细节并修正了失真,从而提高了整体视觉纹理。
- 稀疏注意力优化:引入了一种新颖的选择性和SSTA(选择性滑动块注意力),动态剪枝冗余的时空令牌,显著减少了长视频序列的计算开销并加速了推理。
- 增强的多模态理解:框架利用了一个大型多模态模型进行精确的双语(中文-英文)理解,结合了ByT5进行专门的字形编码,以增强视频中文本生成的准确性。此外,为图像和视频生成了详细的双语字幕。
- 端到端训练优化:展示了Muon优化器在视频生成模型训练中显著加速收敛,同时多阶段渐进训练策略从预训练到后训练阶段增强了运动连贯性、美学质量以及与人类偏好的对齐,从而能够生产专业级内容。
2、不足与反思
- 计算资源需求:尽管模型在推理速度和GPU内存要求方面表现出色,但在实际部署时仍需考虑更高效的硬件配置和优化技术,以确保在大规模应用中的可行性。
- 长视频序列的处理:虽然稀疏注意力机制在长视频序列上表现良好,但在极长视频(如超过几百帧)的处理上仍有改进空间,可能需要进一步优化算法或采用更高级的硬件加速技术。
- 模型的通用性和适应性:尽管模型在多个任务和分辨率上表现出色,但在特定领域或特定类型的数据上可能仍需进一步的定制和优化,以提高其在这些场景下的性能。
六、相关问题
问题1:HunyuanVideo 1.5的稀疏注意力优化(SSTA)机制是如何设计的?
稀疏注意力优化(SSTA)机制旨在减少长视频序列的计算开销并加速推理。其关键步骤包括:
3D块划分:将查询(Q)、键(K)和值(V)张量划分为固定大小的块。
选择性掩码生成:通过自适应池化操作生成选择性掩码,掩码表示每个块的相似性和冗余性。
滑动瓦片注意力掩码生成:对于每个块对,如果一个块在另一个块的局部窗口内,则生成1,否则生成0。
块稀疏注意力:结合选择性掩码和滑动瓦片注意力掩码,执行块稀疏注意力计算。
这些步骤共同作用,动态剪枝冗余的时空令牌,显著减少了计算复杂度,同时保持了模型的生成质量。
问题2:HunyuanVideo 1.5在视频超分辨率增强方面采取了哪些措施?
HunyuanVideo 1.5采用了以下措施进行视频超分辨率增强:
- 初始化权重:使用预训练的文本到视频(T2V)视频模型初始化视频超分辨率模型的权重。
- 数据集构建:收集包含100万高质量视频片段的数据集,这些片段涵盖广泛的场景和分辨率。
- 输入准备:将低分辨率的潜在空间和噪声沿通道维度拼接作为输入。
- 训练过程:在潜在空间中进行超分辨率,通过通道拼接方式注入低分辨率潜在空间,并使用单独训练的潜在上采样模块对齐低分辨率和高分辨率潜在空间。
这些措施通过增强细粒度的视觉细节和纹理,显著提高了视频的视觉质量、运动稳定性和整体时间连贯性。
问题3:HunyuanVideo 1.5在多模态理解方面有哪些创新?
HunyuanVideo 1.5在多模态理解方面的创新包括:
- 大型多模态模型:使用一个大型多模态模型进行精确的双语(中文-英文)理解,结合了ByT5进行专门的字形编码。
- 文本编码:采用双通道文本编码器,结合Qwen2.5-VL和ByT5,分别用于场景描述、角色动作和特定要求的深入理解以及跨语言文本的准确渲染。
- 图像到视频的指示字幕:开发了一个新的模块,生成描述初始帧到视频中时间演变或变化的文本,详细描述了前景和背景环境的变化。
这些创新通过增强文本生成准确性、提升双语理解能力和生成高质量的视频字幕,显著提高了视频生成的整体质量和用户体验。