目录
前言
- 这一篇博客主要讲述Elasticsearch 和 Kibana 的部署,对docker不熟悉的朋友可以看下我的这篇博客,Elasticsearch 是一款强大的开源搜索引擎,一般与可视化工具 Kibana 配合使用,用于日志分析、数据检索等场景。通过 Docker Compose 可以快速搭建一套完整的 Elasticsearch + Kibana 环境。
- 部署前确保Linux宿主机至少2GB内存,Elasticsearch比较吃内存,且已经安装 Docker 和 Docker Compose(建议 Docker 版本 ≥ 20.10,Compose 版本 ≥ 3.8)
部署前准备
-
在正式部署前,我建议先把Elasticsearch和Kibana的docker镜像先拉下来,建议直接从Elasticsearch官网拉取镜像,想部署哪个版本镜像最后直接指定版本就可以,我这次部署的是7.17.20版本,注意Elasticsearch、Kibana和lk分词器的版本要保持一致。执行docker命令
bash# 拉取elasticsearch镜像 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.20 # 拉取Kibana镜像 docker pull docker.elastic.co/kibana/kibana:7.17.20 -
如果因为网络原因,或者配置的国内镜像仓库拉取不下来,直接按照我这篇博客,配置一下阿里的镜像加速器就可以了。
-
从这个网址lk分词器中下载lk分词器,记得版本要保持一致。
-
创建主目录和数据卷目录,用于挂载Elasticsearch容器内的数据目录和插件目录
bash# 创建主目录,进入主目录 mkdir elasticsearch-docker && cd elasticsearch-docker # 创建 Elasticsearch 数据和插件目录 mkdir -p elasticsearch/{data,plugins} -
将下载的Ik分词器 压缩文件解压缩,将解压缩的目录放入 plugins数据卷目录中
-
手动修改宿主机挂载目录的权限,确保容器内用户有权限访问,这步很重要,一定要修改数据卷目录权限
bash# 递归修改数据目录和插件目录的权限 chmod -R 777 ./elasticsearch/data chmod -R 777 ./elasticsearch/plugins -
为了避免 Elasticsearch 在运行时可能遇到的内存映射不足问题,建议提高系统的 vm.max_map_count值,这个配置值表示一个进程可以拥有的虚拟内存区域的数量,像 Elasticsearch、Apache Doris、Kafka这类高性能数据存储和搜索引擎应用,为了追求极致的I/O效率,会广泛使用内存映射文件技术来访问磁盘上的大量数据文件。
-
一般vm.max_map_count默认配置为65530,我们可以通过命令
cat /proc/sys/vm/max_map_count查看配置。 -
编辑 /etc/sysctl.conf文件,在末尾添加一行 vm.max_map_count=262144,然后执行 sudo sysctl -p使配置立即生效
部署
-
在主目录中通过touch命令创建docker-compose.yml 配置文件,将下面文件内容复制进去,记得将我的中文注释删除,要不容器可能启动报错
yamlversion: '3.8' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.17.20 container_name: elasticsearch environment: #设置 Elasticsearch 为单节点模式,适合开发和测试 - discovery.type=single-node #为 Elasticsearch 分配堆内存 - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - cluster.name=es-docker-cluster volumes: #注意数据卷不要配置错,冒号前面的是宿主机数据卷目录,后面是挂载的容器内目录,冒号后面的不需要修改,只需配置对冒号前面的数据集目录 - ./elasticsearch/data:/usr/share/elasticsearch/data - ./elasticsearch/plugins:/usr/share/elasticsearch/plugins ports: - "9200:9200" - "9300:9300" networks: - elastic kibana: image: docker.elastic.co/kibana/kibana:7.17.20 container_name: kibana environment: - ELASTICSEARCH_HOSTS=http://elasticsearch:9200 - I18N_LOCALE=zh-CN ports: - "5601:5601" depends_on: - elasticsearch networks: - elastic restart: unless-stopped networks: elastic: driver: bridge -
注意数据卷目录不要配置错,别忘了提前把IK分词器目录放到plugins数据卷目录中
-
端口冲突的改下端口,其他的就不要修改了。
-
在主目录(docker-compose.yml 同级目录)执行
docker compose up -d,启动容器(有的是docker-compose up -d 自己提前确认下),通过docker compose ps查看容器运行状态
验证服务状态
- 用 docker-compose ps命令查看容器状态,确认两者均为 "Up"。
- 访问 http://你的服务器IP:9200。如果浏览器返回包含 "you know, for search"的 JSON 信息,说明 Elasticsearch 已成功运行。
- 访问 http://你的服务器IP:5601。稍等片刻(Kibana 启动需要一些时间),即可看到 Kibana 的 Web 界面
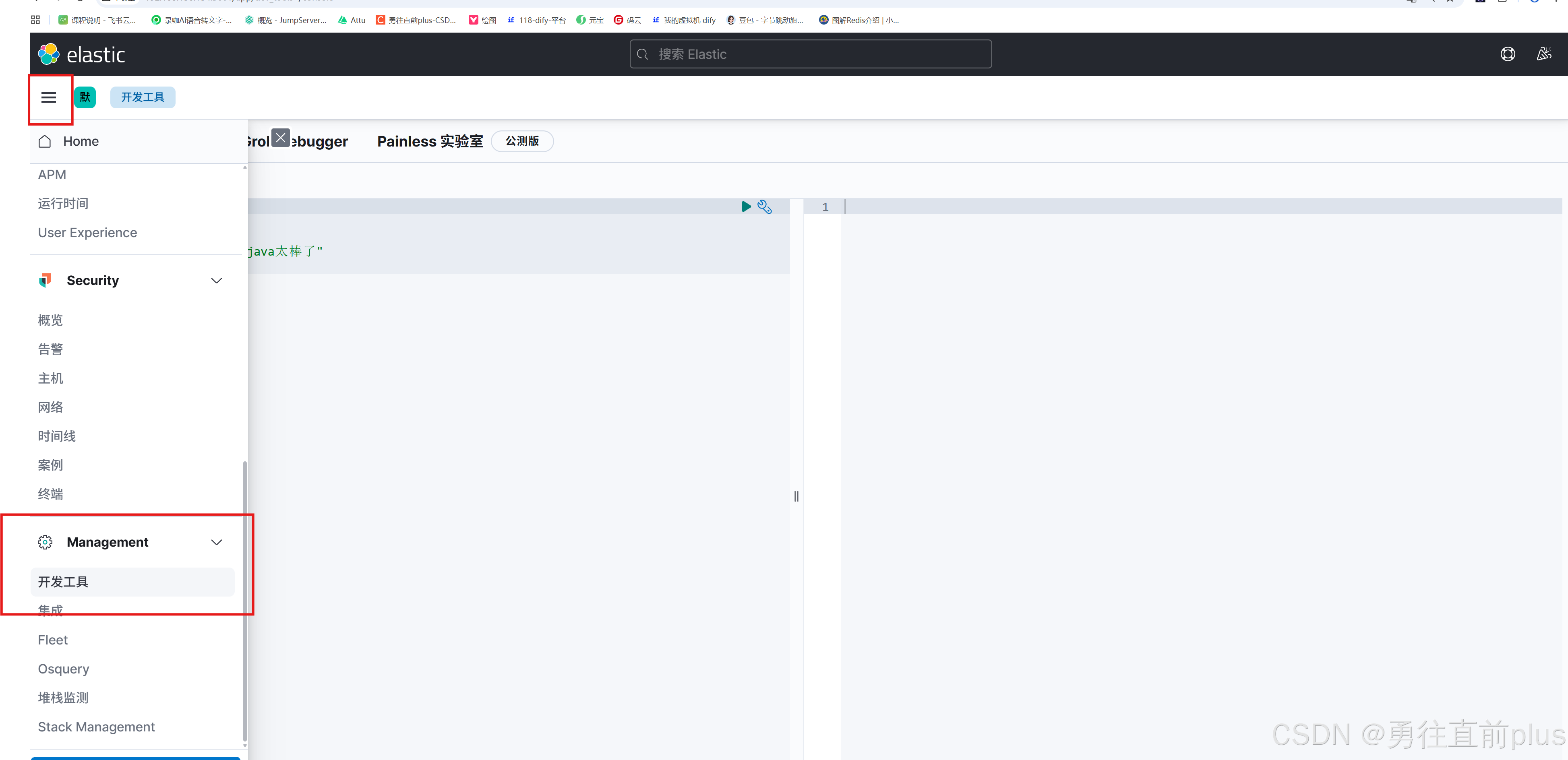
- 根据下面的指示,进入elasticsearch的命令访问界面。
-
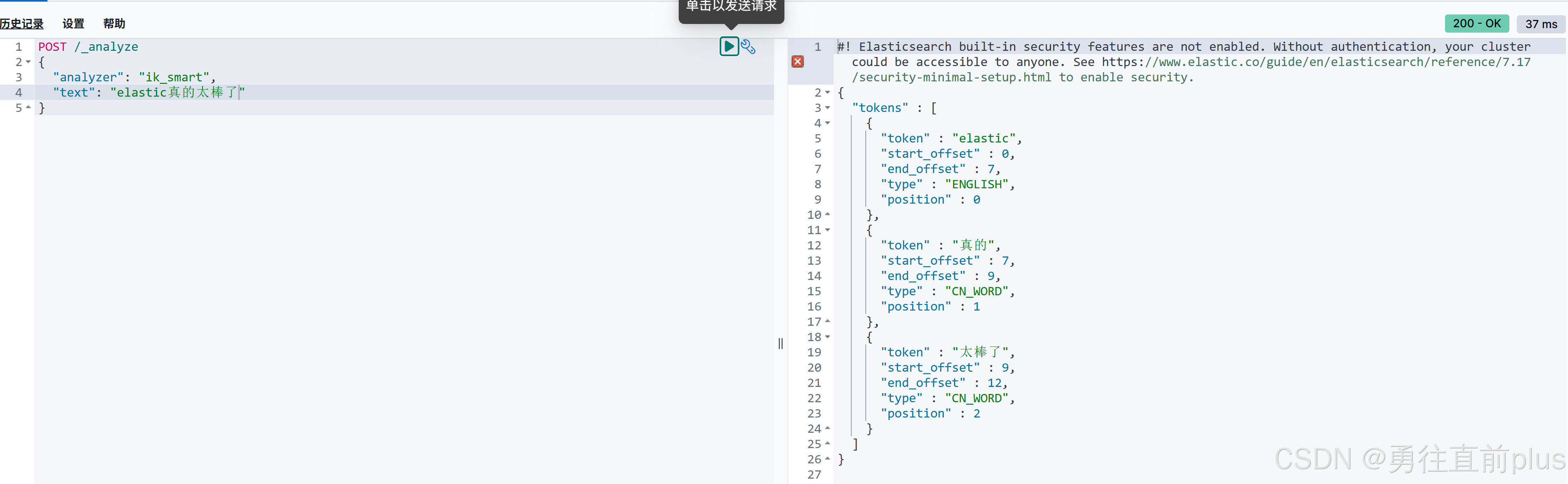
执行下面的elasticsearch的解析指令,如果能正常返回分词数据,说明IK分词器插件也加载成功
yamlPOST /_analyze { "analyzer": "ik_smart", "text": "elastic真的太棒了" }