啥是微调?为啥要微调?什么时候微调?
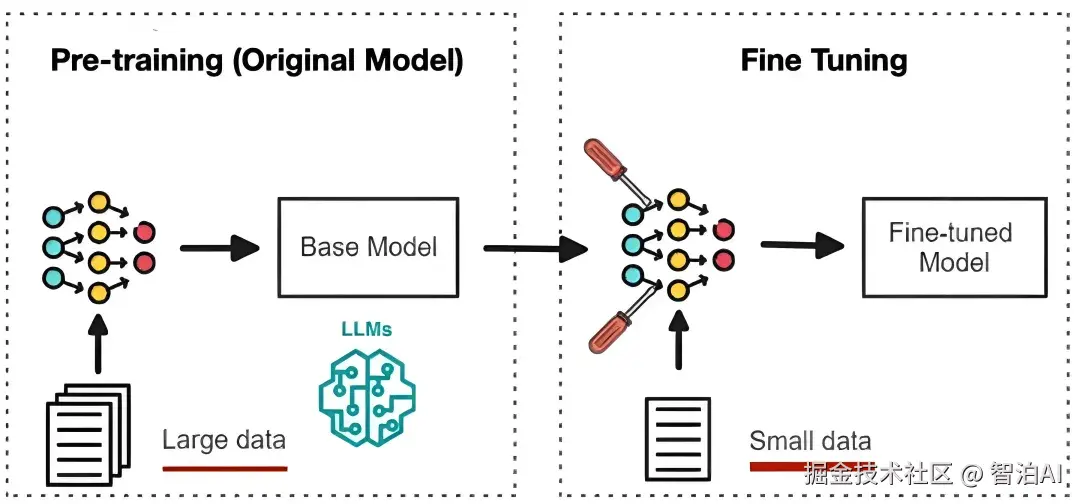
Fine-tuning(微调/精调)
指在预训练模型上,用特定任务的数据进行额外训练,微调模型参数,使其适应新任务。
预训练模型:
已在大规模数据上学习通用特征的基础模型(如qwen、deepseek)
belike: 应届毕业生
特点: 啥都会点,但缺特定行业经验
微调后:
注入领域专属知识(如金融、法律)使模型具备特定场景下的专业能力
belike: 培训后的牛马
特点: 专业打工人,业务能力杠杠的
Fine-tuning的优势
省钱省力:微调就像站在了"巨人(预训练模型)的肩膀上",避免了从零训练所需的巨大算力和数据成本。
性能强劲:在高质量领域数据上微调能显著提升模型在特定任务上的准确性和可靠性,使其表现远超通用模型。
灵活个性:可以塑造模型的风格和性格,使其输出更符合业务需求,如特定的文风、话术或决策逻辑。
Fine-tuning的类型
微调方法有很多种,从训练数据是否标注,可分为监督微调(SFT)和其他,从参数策略角度,可分为全量微调和高效微调。
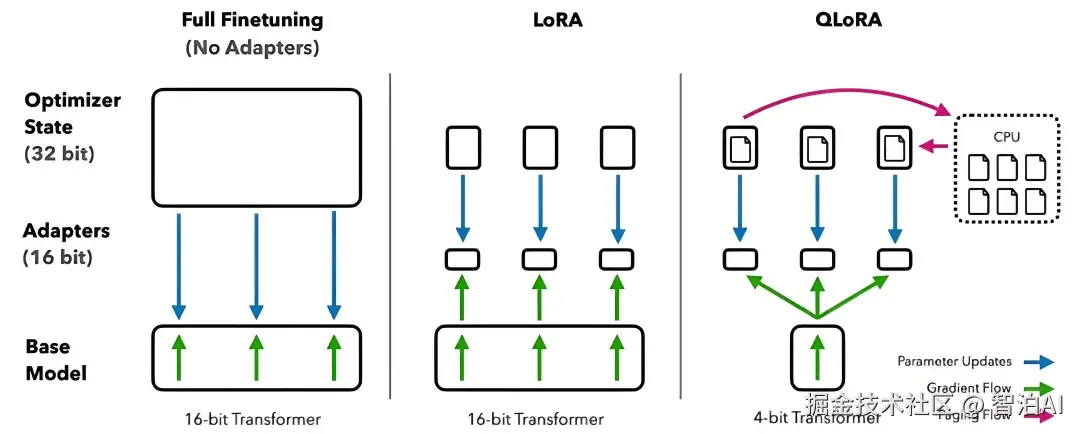
全量微调
把所有参数都训练一遍,算力消耗大,但对模型改造更彻底
高效微调
只训练底模的部分参数,通过修改部分参数调整模型整体能力,LoRA是其中的一种常用策略,(QLoRA类似于它的pro版,更轻量)
什么时候选择Fine-tunning?
RAG的本质是给大模型添加参考书
适用于:知识更新快/要引用外部资料(如智能客服、基于公司资料问答)
Fine-tuning的本质是培养大模型成为某个领域的专家
适用于:任务风格固定/要改变模型说话方式(如特定领域的医疗/法律顾问)
总结
微调就是培养大模型成为领域专家
它省钱省力、性能强劲、灵活个性
全量 vs 高效/LoRA
要让大模型学新技能/风格用微调
要给大模型查资料用RAG
更多AI大模型学习视频及资源,都在智泊AI。