一、引言:中级开发的 MyBatis "卡壳" 时刻
做开发半年到两年的你,是不是常遇到这些问题:
- 多条件查询时,写了一堆if-else拼接 SQL,还总因多了个AND或逗号报语法错;
- 查订单列表要关联用户、商品表,结果要么字段映射混乱,要么查出来数据重复;
- 同一页面频繁刷新,每次都查数据库,接口响应慢得被测试吐槽......
这些 "卡壳" 场景,本质是没掌握 MyBatis 的进阶能力。本文会从动态 SQL(解决复杂条件拼接) 、关联查询(处理多表数据) 、缓存机制(优化重复查询) 三个维度,用 "场景 + 代码 + 原理" 的方式拆解,帮你把 MyBatis 从 "能用" 升级到 "用好",应对 80% 的中级开发场景。
二、动态 SQL 深度解析:告别 "SQL 拼接地狱"
动态 SQL 是 MyBatis 的 "灵魂功能",能根据条件自动拼接 SQL 片段,避免手动拼接的冗余与错误。下面 6 个核心标签,从基础到进阶逐个拆解,每个标签都附实战场景与完整代码。
1. if 标签:最常用的 "条件判断"
场景:多条件查询(如电商列表页,用户可输入用户名、选择价格区间,非必填条件)
作用:满足test表达式时,才拼接标签内的 SQL 片段。
代码示例:根据用户名和年龄查询用户
java
<!-- UserMapper.xml -->
<select id="selectUserByCondition" resultType="User">
SELECT id, username, age, email
FROM user
WHERE 1=1 <!-- 占位符,避免后续if都不满足时出现"WHERE"后无条件的语法错 -->
<!-- test表达式:判断参数是否非空,支持OGNL语法(如username != null and username != '') -->
<if test="username != null and username != ''">
AND username LIKE CONCAT('%', #{username}, '%') <!-- 模糊查询拼接 -->
</if>
<if test="age != null">
AND age > #{age} <!-- 年龄大于传入值 -->
</if>
</select>
java
// UserMapper.java接口
List<User> selectUserByCondition(@Param("username") String username, @Param("age") Integer age);
// 测试代码
// 场景1:只传username,SQL会拼接"AND username LIKE '%张%'"
List<User> user1 = userMapper.selectUserByCondition("张", null);
// 场景2:只传age,SQL会拼接"AND age > 25"
List<User> user2 = userMapper.selectUserByCondition(null, 25);关键注意点:
test表达式中,参数名要和@Param或实体类属性一致(如参数是User对象,就用user.age);
为什么加WHERE 1=1?如果所有if都不满足,SQL 会变成SELECT ... FROM user WHERE,语法错误;加了1=1,不满足时就是WHERE 1=1,合法。
2. where 标签:自动 "收拾" 多余的 AND/OR
场景:替代WHERE 1=1,更优雅地处理条件拼接
作用:自动去除标签内 SQL 片段开头的AND或OR,避免语法错误。
代码示例:优化上面的多条件查询
java
<select id="selectUserByCondition" resultType="User">
SELECT id, username, age, email
FROM user
<!-- where标签自动处理多余的AND -->
<where>
<if test="username != null and username != ''">
AND username LIKE CONCAT('%', #{username}, '%') <!-- 开头的AND会被自动去除 -->
</if>
<if test="age != null">
AND age > #{age}
</if>
</where>
</select>对比优势:
无需写WHERE 1=1,代码更简洁;
即使第一个if不满足,第二个if开头的AND也会被处理(比如只传 age,SQL 是WHERE age > 25,无多余 AND)。
3. choose(when/otherwise)标签:"二选一" 的分支逻辑
场景:互斥条件查询(如电商订单查询,"按订单号查" 和 "按用户 ID 查" 只能选一个,不能同时生效)
作用:类似 Java 的switch-case,只执行第一个满足条件的when,都不满足则执行otherwise。
代码示例:订单查询(订单号优先,无则按用户 ID 查)
java
<select id="selectOrder" resultType="Order">
SELECT id, order_no, user_id, amount
FROM `order`
<where>
<choose>
<!-- 第一个满足的条件生效:有订单号则按订单号查 -->
<when test="orderNo != null and orderNo != ''">
AND order_no = #{orderNo}
</when>
<!-- 订单号为空,按用户ID查 -->
<when test="userId != null">
AND user_id = #{userId}
</when>
<!-- 都为空,查近7天的订单(默认条件) -->
<otherwise>
AND create_time >= DATE_SUB(NOW(), INTERVAL 7 DAY)
</otherwise>
</choose>
</where>
</select>实战提醒:
choose是 "互斥" 逻辑,和多个if的 "并列" 逻辑区分开(多个if会同时生效,choose只生效一个);
otherwise可选,无默认条件时可省略,但建议加上,避免无条件查询全表。
4. set 标签:动态更新时 "去掉多余逗号"
场景:部分字段更新(如用户编辑,只改用户名和邮箱,不改年龄)
作用:自动去除标签内 SQL 片段结尾的逗号,避免UPDATE ... SET username='xxx', WHERE ...的语法错。
代码示例:更新用户信息(只更非空字段)
java
<update id="updateUserSelective">
UPDATE user
<!-- set标签自动处理多余逗号 -->
<set>
<if test="username != null and username != ''">
username = #{username}, <!-- 结尾的逗号会被自动去除 -->
</if>
<if test="age != null">
age = #{age},
</if>
<if test="email != null and email != ''">
email = #{email}
</if>
</set>
WHERE id = #{id} <!-- 必须传id,否则更新全表! -->
</update>避坑指南:
千万不要漏写WHERE id = #{id},否则会更新表中所有数据,生产环境必出事故;
如果所有if都不满足(没传任何要更新的字段),SQL 会变成UPDATE user SET WHERE id=?,语法错误,建议在 Service 层加参数校验(至少有一个字段非空)。
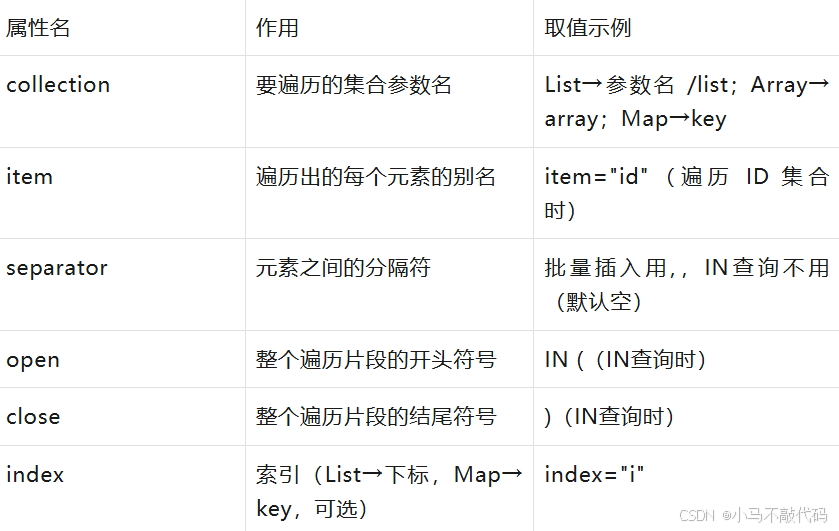
5. foreach 标签:遍历集合的 "批量操作神器"
场景:批量插入、批量删除、IN查询(如批量插入 10 个用户、删除 ID 为 1,2,3 的用户、查询 ID 在 10,20 的订单)
作用:遍历List/Array/Map,拼接成对应的 SQL 片段(如(1,2,3)或VALUES (?,?),(?,?))。
核心属性解析:
实战场景 1:批量插入用户(List 参数)
java
<insert id="batchInsertUser">
INSERT INTO user (username, age, email)
VALUES
<foreach collection="userList" item="user" separator=",">
(#{user.username}, #{user.age}, #{user.email})
</foreach>
</insert>
<!-- 对应的Mapper接口 -->
int batchInsertUser(@Param("userList") List<User> userList);
<!-- 测试代码:插入3个用户 -->
List<User> userList = new ArrayList<>();
userList.add(new User("李四", 28, "lisi@xxx.com"));
userList.add(new User("王五", 30, "wangwu@xxx.com"));
userMapper.batchInsertUser(userList);实战场景 2:批量删除用户(Array 参数)
java
<delete id="batchDeleteUser">
DELETE FROM user
WHERE id IN
<foreach collection="array" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</delete>
<!-- 对应的Mapper接口 -->
int batchDeleteUser(Integer[] ids);
<!-- 测试代码:删除ID为1、2的用户 -->
Integer[] ids = {1,2};
userMapper.batchDeleteUser(ids);性能优化:
批量插入时,若数据量超过 1000 条,建议分批次(如每次 500 条),避免 SQL 语句过长导致数据库执行超时;
collection取值易错:如果 Mapper 接口参数没加@Param,List 默认用list,Array 默认用array;加了@Param,就用@Param指定的名称(如@Param("userList")→collection="userList")。
6. trim 标签:自定义 SQL 拼接规则(万能标签)
场景:替代where/set,或实现更灵活的拼接(如给 SQL 加前缀、后缀,去除特定字符)
作用:通过prefix(前缀)、suffix(后缀)、prefixOverrides(去除开头字符)、suffixOverrides(去除结尾字符)自定义规则。
示例 1:用 trim 替代 where 标签
java
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="username != null">
AND username = #{username}
</if>
<if test="age != null">
AND age > #{age}
</if>
</trim>
<!-- 效果等同于where标签:开头加WHERE,去除多余AND/OR -->
示例 2:用 trim 替代 set 标签
<trim prefix="SET" suffixOverrides=",">
<if test="username != null">
username = #{username},
</if>
<if test="email != null">
email = #{email},
</if>
</trim>
<!-- 效果等同于set标签:开头加SET,去除结尾逗号 -->
示例 3:自定义拼接(给查询结果加固定条件)
<select id="selectUserWithStatus" resultType="User">
SELECT id, username, age
FROM user
<trim prefix="WHERE" prefixOverrides="AND">
<if test="username != null">
AND username LIKE '%${username}%'
</if>
<!-- 强制拼接"status=1"(只查正常用户) -->
AND status = 1
</trim>
</select>使用建议:
简单场景用where/set,复杂场景用trim;
trim灵活性高,但可读性稍差,团队协作时建议统一规则(如优先用where/set)。
三、复杂关联查询实现:搞定多表数据映射
实际项目中,很少只查单表(如查订单要带用户信息,查用户要带订单列表),这就需要关联查询。下面按 "一对一→一对多→多对多" 的顺序,讲清实现方式、优缺点与性能优化。
1. 一对一关联:用户与身份证(一个用户对应一个身份证)
场景:查询用户时,同时返回其身份证信息(如用户表user,身份证表id_card,通过 user.id = id_card.user_id 关联)。
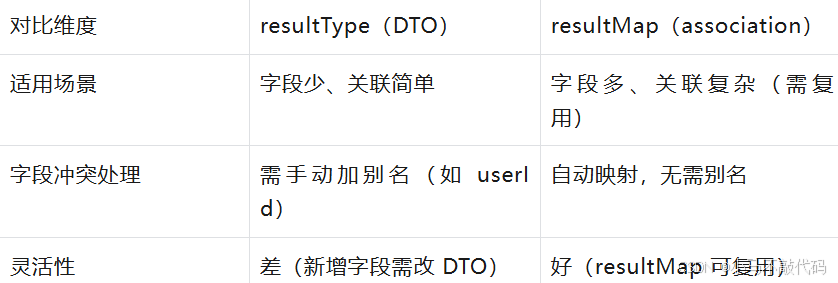
两种实现方式:resultType(用 DTO 接收) vs resultMap(用 association 标签配置)。
方式 1:resultType(简单场景,用 DTO 接收关联结果)
步骤 1:创建 DTO 类(包含用户和身份证的所有字段)
java
// UserWithIdCardDTO.java
@Data
public class UserWithIdCardDTO {
// 用户表字段
private Integer userId;
private String username;
private Integer age;
// 身份证表字段(加前缀区分,避免字段名冲突)
private Integer cardId;
private String cardNo; // 身份证号
private String issueOrg; // 发证机关
}步骤 2:编写 Mapper 接口与 XML
java
// UserMapper.java
List<UserWithIdCardDTO> selectUserWithIdCard();
<select id="selectUserWithIdCard" resultType="UserWithIdCardDTO">
SELECT
u.id AS userId,
u.username,
u.age,
ic.id AS cardId,
ic.card_no AS cardNo,
ic.issue_org AS issueOrg
FROM user u
LEFT JOIN id_card ic ON u.id = ic.user_id <!-- 左连接,确保没有身份证的用户也能查到 -->
</select>方式 2:resultMap(复杂场景,用 association 标签)
步骤 1:创建实体类(User 包含 IdCard 属性)
java
// IdCard.java(身份证实体)
@Data
public class IdCard {
private Integer id;
private String cardNo;
private String issueOrg;
private Integer userId; // 关联用户ID
}
// User.java(用户实体,包含IdCard)
@Data
public class User {
private Integer id;
private String username;
private Integer age;
private IdCard idCard; // 一对一关联:用户有一个身份证
}步骤 2:编写 resultMap 与 SQL
java
<!-- 定义resultMap:关联User和IdCard -->
<resultMap id="UserWithIdCardMap" type="User">
<!-- 用户表字段映射 -->
<id column="user_id" property="id"/> <!-- id标签:主键字段,提高映射效率 -->
<result column="username" property="username"/>
<result column="age" property="age"/>
<!-- association标签:配置一对一关联 -->
<association property="idCard" javaType="IdCard"> <!-- javaType:关联对象的类型 -->
<id column="card_id" property="id"/>
<result column="card_no" property="cardNo"/>
<result column="issue_org" property="issueOrg"/>
</association>
</resultMap>
<!-- 关联查询SQL -->
<select id="selectUserWithIdCard2" resultMap="UserWithIdCardMap">
SELECT
u.id AS user_id,
u.username,
u.age,
ic.id AS card_id,
ic.card_no,
ic.issue_org
FROM user u
LEFT JOIN id_card ic ON u.id = ic.user_id
</select>两种方式对比:
延迟加载配置:
一对一关联时,若默认不查身份证(需要时才查),可开启延迟加载(减轻数据库压力):
全局配置(application.yml):
java
mybatis:
configuration:
lazy-loading-enabled: true # 开启全局延迟加载
aggressive-lazy-loading: false # 关闭"积极加载"(只加载需要的属性)修改 association 标签,添加select和column:
java
<association
property="idCard"
javaType="IdCard"
select="com.example.mapper.IdCardMapper.selectIdCardByUserId" <!-- 关联查询的Mapper方法 -->
column="user_id"> <!-- 传递给关联方法的参数(用户ID) -->
</association>编写 IdCardMapper 的查询方法:
java
// IdCardMapper.java
IdCard selectIdCardByUserId(Integer userId);
<select id="selectIdCardByUserId" resultType="IdCard">
SELECT * FROM id_card WHERE user_id = #{userId}
</select>效果:查询用户时,只查user表;当调用user.getIdCard()时,才会执行id_card表的查询(按需加载)。
2. 一对多关联:用户与订单(一个用户对应多个订单)
场景:查询用户时,同时返回其所有订单(如用户表user,订单表order,通过user.id = order.user_id关联)。
核心标签:collection(配置集合关联,对应实体类中的List属性)。
实现步骤:
创建实体类(User 包含 List)
java
// Order.java(订单实体)
@Data
public class Order {
private Integer id;
private String orderNo; // 订单号
private BigDecimal amount; // 金额
private Integer userId; // 关联用户ID
}
// User.java(用户实体,包含订单列表)
@Data
public class User {
private Integer id;
private String username;
private Integer age;
private List<Order> orderList; // 一对多关联:用户有多个订单
}编写 resultMap 与 SQL
java
<!-- 定义resultMap:关联User和Order -->
<resultMap id="UserWithOrderMap" type="User">
<!-- 用户表字段映射 -->
<id column="user_id" property="id"/>
<result column="username" property="username"/>
<result column="age" property="age"/>
<!-- collection标签:配置一对多关联 -->
<collection
property="orderList" <!-- 实体类中的集合属性名 -->
ofType="Order" <!-- 集合中元素的类型(注意不是javaType) -->
column="user_id"> <!-- 关联的外键字段(用户ID) -->
<!-- 订单表字段映射 -->
<id column="order_id" property="id"/> <!-- 订单主键,避免数据重复 -->
<result column="order_no" property="orderNo"/>
<result column="amount" property="amount"/>
</collection>
</resultMap>
<!-- 关联查询SQL -->
<select id="selectUserWithOrder" resultMap="UserWithOrderMap">
SELECT
u.id AS user_id,
u.username,
u.age,
o.id AS order_id,
o.order_no,
o.amount
FROM user u
LEFT JOIN `order` o ON u.id = o.user_id
ORDER BY u.id, o.id <!-- 按用户ID和订单ID排序,避免数据混乱 -->
</select>关键注意点:
- ofType vs javaType:collection用ofType指定集合元素类型(如Order),association用javaType指定关联对象类型(如IdCard),别搞混;
- 避免数据重复:必须给主表(user)和从表(order)的主键加id标签,MyBatis 会通过主键判断是否为同一对象,否则会重复生成用户对象;
- 嵌套查询 vs 嵌套结果:
上面的示例是 "嵌套结果"(一次 SQL 联表查询),优点是效率高,缺点是 SQL 复杂;
"嵌套查询"(先查用户,再查订单)类似一对一延迟加载,需配置select属性,但可能出现 "N+1 问题"(查 1 个用户查 1 次,查 N 个用户查 N 次订单,共 N+1 次查询),数据量大时不推荐。
3. 多对多关联:用户与角色(一个用户有多个角色,一个角色有多个用户)
场景:查询用户时,同时返回其所有角色(需中间表user_role关联,三张表:user、role、user_role)。
实现思路:先通过user和user_role联表,再关联role,用collection标签映射角色列表。
实现步骤:
创建实体类(User 包含 List)
java
// Role.java(角色实体)
@Data
public class Role {
private Integer id;
private String roleName; // 角色名(如"管理员""普通用户")
}
// User.java(用户实体,包含角色列表)
@Data
public class User {
private Integer id;
private String username;
private Integer age;
private List<Role> roleList; // 多对多关联:用户有多个角色
}编写 resultMap 与 SQL
java
<!-- 定义resultMap:关联User和Role -->
<resultMap id="UserWithRoleMap" type="User">
<!-- 用户表字段映射 -->
<id column="user_id" property="id"/>
<result column="username" property="username"/>
<result column="age" property="age"/>
<!-- collection标签:配置多对多关联(角色列表) -->
<collection
property="roleList"
ofType="Role"
column="user_id">
<id column="role_id" property="id"/> <!-- 角色主键,避免重复 -->
<result column="role_name" property="roleName"/>
</collection>
</resultMap>
<!-- 多表联查SQL:user → user_role → role -->
<select id="selectUserWithRole" resultMap="UserWithRoleMap">
SELECT
u.id AS user_id,
u.username,
u.age,
r.id AS role_id,
r.role_name
FROM user u
LEFT JOIN user_role ur ON u.id = ur.user_id <!-- 中间表关联 -->
LEFT JOIN role r ON ur.role_id = r.id <!-- 角色表关联 -->
WHERE u.id = #{userId} <!-- 按用户ID查询,避免返回所有用户 -->
</select>性能优化:
多对多查询本质是 "两次一对多"(用户→用户角色,用户角色→角色),联表时注意索引(user_role.user_id和user_role.role_id加索引);
若只需查询用户的角色 ID,可不用关联role表,直接查user和user_role,减少表连接次数。
四、MyBatis 缓存机制:从 "重复查库" 到 "缓存复用"
缓存是优化接口性能的关键 ------ 同一数据频繁查询时,从缓存取比查数据库快 10~100 倍。MyBatis 有两级缓存,再加上第三方缓存(如 Redis),能覆盖绝大多数场景。
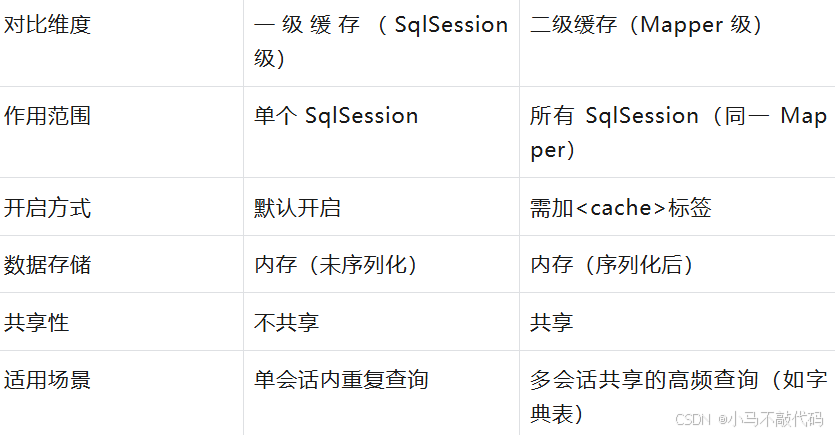
一级缓存(SqlSession 级缓存):默认开启,"会话内有效"
原理:MyBatis 默认在SqlSession(数据库会话)内缓存数据,同一SqlSession执行相同的 SQL(相同的 SQL 语句 + 参数),第一次查数据库并缓存,第二次直接从缓存取,无需查库。
实战验证:一级缓存命中与失效场景
java
// 测试代码:同一SqlSession内的缓存命中
@Test
public void testFirstLevelCache() {
// 1. 获取SqlSession(Spring环境下可通过SqlSessionTemplate获取)
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 2. 第一次查询:查数据库,缓存数据
User user1 = userMapper.selectUserById(1);
System.out.println("第一次查询:" + user1);
// 3. 第二次查询:相同SQL+参数,从缓存取(不查库)
User user2 = userMapper.selectUserById(1);
System.out.println("第二次查询:" + user2);
System.out.println("是否同一对象:" + (user1 == user2)); // 结果:true(缓存命中)
// 4. 关闭SqlSession:缓存清空
sqlSession.close();
// 5. 新的SqlSession:缓存失效,重新查库
SqlSession newSqlSession = sqlSessionFactory.openSession();
UserMapper newUserMapper = newSqlSession.getMapper(UserMapper.class);
User user3 = newUserMapper.selectUserById(1);
System.out.println("新SqlSession查询:" + user3);
System.out.println("是否同一对象:" + (user1 == user3)); // 结果:false(缓存失效)
}一级缓存失效场景(必须掌握):
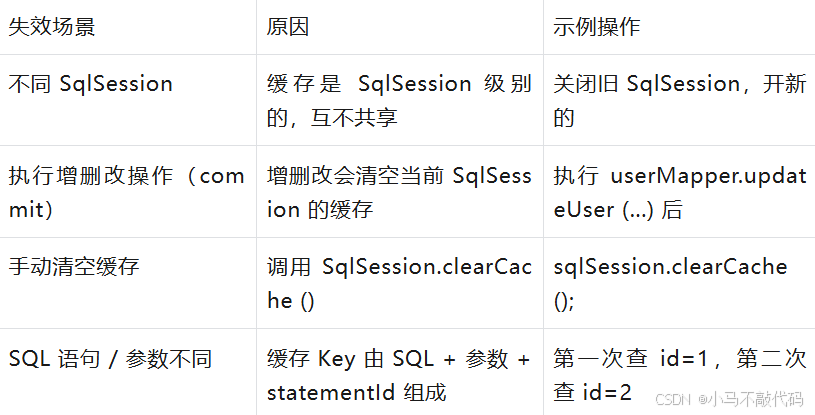
实战提醒:
Spring 整合 MyBatis 时,默认每个 Service 方法是一个SqlSession(事务提交后关闭),所以一级缓存在 Service 方法内有效,跨方法失效;
不要在多线程中共享SqlSession,会导致缓存数据被覆盖,出现数据一致性问题(如线程 A 查 id=1,线程 B 查 id=2,缓存可能混乱)。
2. 二级缓存(Mapper 级缓存):手动开启,"跨会话共享"
原理:二级缓存是Mapper接口级别的缓存(如UserMapper的缓存独立于OrderMapper),不同SqlSession执行同一Mapper的相同 SQL,可共享缓存,缓存数据存储在Mapper对应的Cache对象中。
开启二级缓存的 3 个步骤:
全局配置开启(application.yml)
java
mybatis:
configuration:
cache-enabled: true # 开启全局二级缓存(默认true,可省略,但建议显式配置)在 Mapper XML 中添加标签(关键)
java
<!-- UserMapper.xml:开启当前Mapper的二级缓存 -->
<cache
eviction="LRU" <!-- 缓存回收策略:LRU(最近最少使用) -->
flushInterval="60000" <!-- 缓存刷新间隔:60秒(60000毫秒),到期自动清空 -->
size="1024" <!-- 缓存最大条目:最多存1024条数据 -->
readOnly="true"/> <!-- 只读:true(返回缓存对象的引用,性能高);false(返回副本,安全) -->实体类实现Serializable接口(否则缓存报错)
java
// User.java必须实现Serializable,因为二级缓存会序列化数据
@Data
public class User implements Serializable {
private Integer id;
private String username;
private Integer age;
// ...其他字段
}二级缓存核心参数解析(标签):
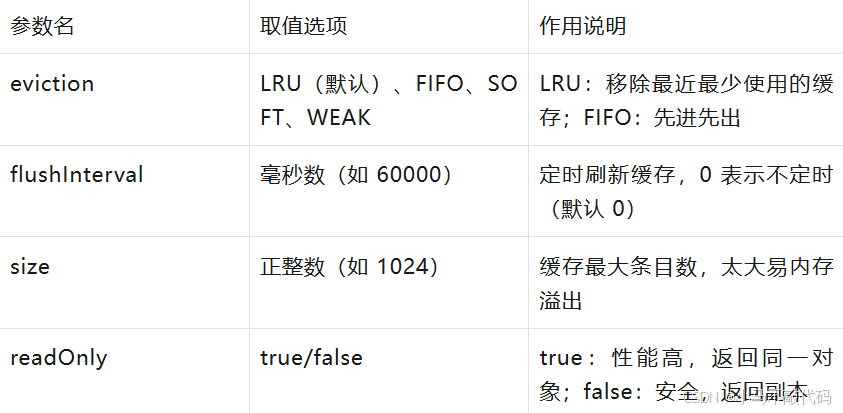
二级缓存生效与失效场景:
- 生效:不同SqlSession执行同一Mapper的相同 SQL(如UserMapper.selectUserById(1)),第二次从缓存取;
- 失效:
执行当前Mapper的增删改操作(会清空该Mapper的二级缓存);
缓存到期(flushInterval时间到)或达到size上限(触发回收策略);
方法上加@Options(useCache = false)(禁用当前方法的二级缓存)。
示例:禁用某个方法的二级缓存
java
// UserMapper.java:查询用户列表时,禁用二级缓存(数据变化频繁)
@Options(useCache = false)
List<User> selectAllUsers();二级缓存 vs 一级缓存对比:
3. 整合第三方缓存(Redis):解决分布式缓存共享问题
问题:二级缓存默认是内存缓存,分布式环境下(多台服务器),各服务器的缓存不共享(如服务器 A 查了 id=1,服务器 B 查 id=1 仍需查库),需用 Redis 实现分布式缓存。
整合步骤(SpringBoot+Redis):
1. 引入依赖(pom.xml)
java
<!-- Redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- MyBatis-Redis整合依赖(提供RedisCache实现) -->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>2. 配置 Redis(application.yml)
java
spring:
redis:
host: localhost # Redis服务器地址
port: 6379 # Redis端口
password: # Redis密码(无则空)
database: 0 # Redis数据库索引(默认0)
timeout: 3000 # 连接超时时间(毫秒)3. 修改 Mapper XML 的标签,指定 Redis 缓存实现
java
<!-- UserMapper.xml:使用Redis作为二级缓存 -->
<cache
type="org.mybatis.caches.redis.RedisCache" <!-- RedisCache的全类名 -->
eviction="LRU"
flushInterval="60000"
size="1024"
readOnly="true"/>自定义 Redis 缓存配置(可选,解决默认配置问题):
MyBatis-Redis 默认缓存时间是永久的,可自定义RedisCache类,设置过期时间:
java
// 自定义RedisCache,继承MyBatis的RedisCache
public class CustomRedisCache extends RedisCache {
// 缓存过期时间:30分钟(1800000毫秒)
private static final long EXPIRE_TIME = 1800000;
public CustomRedisCache(String id) {
super(id); // 调用父类构造器
}
// 重写putObject方法,添加过期时间
@Override
public void putObject(Object key, Object value) {
RedisManager redisManager = RedisConfigurationBuilder.getInstance().build();
try (Jedis jedis = redisManager.getResource()) {
jedis.set(Objects.toString(key), SerializeUtil.serialize(value));
jedis.expire(Objects.toString(key), (int) (EXPIRE_TIME / 1000)); // 设置过期时间(秒)
}
}
}然后在 Mapper XML 中引用自定义缓存:
java
<cache type="com.example.cache.CustomRedisCache"/>五、实战案例:电商订单查询模块(整合所有进阶技能)
用一个真实场景,把动态 SQL、关联查询、缓存串起来,让你看到 "学以致用" 的效果。
1. 需求分析
功能:查询订单列表,支持多条件筛选(订单号、用户 ID、时间范围、订单状态);
关联:订单需显示用户信息(一对一)、订单商品列表(一对多);
性能:查询结果缓存,订单增删改后清空缓存。
2. 技术设计
表结构:order(订单表)、user(用户表)、order_item(订单商品表);
核心技能:动态 SQL(多条件筛选)、关联查询(订单→用户、订单→商品)、二级缓存(缓存订单列表)。
3. 代码实现
实体类与 DTO 设计
java
// 订单商品实体(OrderItem.java)
@Data
public class OrderItem implements Serializable {
private Integer id;
private Integer orderId; // 关联订单ID
private String productName; // 商品名
private Integer quantity; // 数量
private BigDecimal price; // 单价
}
// 订单实体(Order.java,包含用户和商品列表)
@Data
public class Order implements Serializable {
private Integer id;
private String orderNo;
private Integer userId;
private BigDecimal amount;
private Integer status; // 订单状态:0-待支付,1-已支付
private Date createTime;
// 关联用户(一对一)
private User user;
// 关联订单商品(一对多)
private List<OrderItem> orderItemList;
}
// 订单查询DTO(OrderQueryDTO.java,接收前端筛选条件)
@Data
public class OrderQueryDTO {
private String orderNo; // 订单号(模糊查询)
private Integer userId; // 用户ID
private Date startTime; // 开始时间
private Date endTime; // 结束时间
private Integer status; // 订单状态
}Mapper 接口与 XML
java
// OrderMapper.java
public interface OrderMapper {
// 多条件查询订单列表(带关联)
List<Order> selectOrderList(OrderQueryDTO queryDTO);
// 新增订单(用于测试缓存失效)
int insertOrder(Order order);
}
java
<!-- OrderMapper.xml -->
<!-- 1. 开启二级缓存(用Redis) -->
<cache type="com.example.cache.CustomRedisCache"/>
<!-- 2. 定义resultMap:关联订单、用户、商品 -->
<resultMap id="OrderWithUserAndItemMap" type="Order">
<!-- 订单表字段 -->
<id column="order_id" property="id"/>
<result column="order_no" property="orderNo"/>
<result column="user_id" property="userId"/>
<result column="amount" property="amount"/>
<result column="status" property="status"/>
<result column="create_time" property="createTime"/>
<!-- 关联用户(一对一) -->
<association property="user" javaType="User">
<id column="u_id" property="id"/>
<result column="username" property="username"/>
<result column="email" property="email"/>
</association>
<!-- 关联订单商品(一对多) -->
<collection property="orderItemList" ofType="OrderItem">
<id column="item_id" property="id"/>
<result column="product_name" property="productName"/>
<result column="quantity" property="quantity"/>
<result column="price" property="price"/>
</collection>
</resultMap>
<!-- 3. 动态SQL:多条件查询订单列表 -->
<select id="selectOrderList" resultMap="OrderWithUserAndItemMap">
SELECT
o.id AS order_id,
o.order_no,
o.user_id,
o.amount,
o.status,
o.create_time,
-- 用户表字段
u.id AS u_id,
u.username,
u.email,
-- 订单商品表字段
oi.id AS item_id,
oi.product_name,
oi.quantity,
oi.price
FROM `order` o
LEFT JOIN user u ON o.user_id = u.id
LEFT JOIN order_item oi ON o.id = oi.order_id
<where>
<!-- 动态条件:订单号模糊查询 -->
<if test="orderNo != null and orderNo != ''">
AND o.order_no LIKE CONCAT('%', #{orderNo}, '%')
</if>
<!-- 用户ID -->
<if test="userId != null">
AND o.user_id = #{userId}
</if>
<!-- 时间范围:创建时间 >= 开始时间 -->
<if test="startTime != null">
AND o.create_time >= #{startTime}
</if>
<!-- 时间范围:创建时间 <= 结束时间 -->
<if test="endTime != null">
AND o.create_time <= #{endTime}
</if>
<!-- 订单状态 -->
<if test="status != null">
AND o.status = #{status}
</if>
</where>
ORDER BY o.create_time DESC
</select>
<!-- 4. 新增订单:执行后会清空当前Mapper的二级缓存 -->
<insert id="insertOrder" useGeneratedKeys="true" keyProperty="id">
INSERT INTO `order` (order_no, user_id, amount, status, create_time)
VALUES (#{orderNo}, #{userId}, #{amount}, #{status}, #{createTime})
</insert>Service 层(整合缓存与业务逻辑)
java
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
// 查询订单列表(缓存生效)
public List<Order> getOrderList(OrderQueryDTO queryDTO) {
return orderMapper.selectOrderList(queryDTO);
}
// 新增订单(执行后缓存失效)
@Transactional
public void addOrder(Order order) {
order.setCreateTime(new Date());
orderMapper.insertOrder(order);
// 新增订单后,OrderMapper的二级缓存会自动清空,下次查列表会重新查库
}
}效果验证
第一次调用getOrderList:查数据库,结果存入 Redis 缓存;
第二次调用getOrderList(相同条件):从 Redis 取,接口响应时间从 500ms→50ms;
调用addOrder新增订单:OrderMapper的二级缓存清空;
第三次调用getOrderList:重新查数据库,获取最新订单列表。
六、性能优化与最佳实践
掌握进阶技能后,还要知道 "怎么用才更好",下面是动态 SQL、关联查询、缓存的实战优化建议。
1. 动态 SQL 优化
避免冗余条件:相同的条件判断(如username != null and username != '')可抽成 SQL 片段,用和复用:
java
<!-- 定义SQL片段 -->
<sql id="usernameCondition">
<if test="username != null and username != ''">
AND username LIKE CONCAT('%', #{username}, '%')
</if>
</sql>
<!-- 引用片段 -->
<select id="selectUser" resultType="User">
SELECT * FROM user
<where>
<include refid="usernameCondition"/>
<if test="age != null">
AND age > #{age}
</if>
</where>
</select>批量操作分批次:批量插入 / 删除超过 1000 条时,分批次处理(如每次 500 条),避免 SQL 过长导致数据库执行超时。
2. 关联查询优化
减少表连接数量:多表联查尽量控制在 3 张表以内,超过 3 张可拆分成多次查询(用延迟加载);
避免笛卡尔积:联表时确保关联条件正确(如 u.id = o.user_id),否则会出现数据爆炸(如 100 个用户 ×100 个订单 = 10000 条重复数据);
用索引优化联表:关联字段(如order.user_id、user_role.role_id)必须加索引,否则联表查询会全表扫描,性能极差。
3. 缓存优化
缓存高频、少变的数据:如字典表、商品分类表(更新频率低),避免缓存高频变化的数据(如订单表、用户余额表);
不缓存大对象:如包含大量商品的订单详情(数据量大,序列化耗时),可只缓存关键信息(如订单 ID、金额),详情按需查库;
分布式缓存用 Redis:单机用二级缓存,分布式环境必须用 Redis,避免缓存不共享问题;
缓存一致性保障:增删改操作后,确保缓存被清空(MyBatis 二级缓存会自动清空当前 Mapper 的缓存,Redis 需手动或通过自定义缓存处理)。