文章目录
- Redis常见面试题详解
-
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- Redis和DB双写一致性
- Redis数据持久化
-
- [RDB(Redis Database)](#RDB(Redis Database))
-
- [1. 工作原理](#1. 工作原理)
- [2. 优缺点](#2. 优缺点)
- [AOF(Append Only File)](#AOF(Append Only File))
-
- [1. 工作原理](#1. 工作原理)
- [2. 优缺点](#2. 优缺点)
- RDB与AOF核心对比
- [混合持久化(Redis 4.0+)](#混合持久化(Redis 4.0+))
- 数据过期策略
- Redis数据淘汰策略
- Redis分布式锁
-
- Redis原生实现
- Redisson实现分布式锁
-
- [看门狗(Watch Dog)机制](#看门狗(Watch Dog)机制)
- 主从一致性
-
- 主从一致性问题的成因
- [Redisson 的解决方案](#Redisson 的解决方案)
- Redis集群
- Redis为什么那么快?
- Redis为什么那么快?
Redis常见面试题详解
本文对Redis常见面试题进行详细的讲解,主要包括以下几个部分:Redis缓存击穿,缓存穿透,缓存雪崩、Redis和DB双写一致性、Redis数据持久化、数据过期策略、数据淘汰策略、Redis分布式锁、主从复制、Redis集群等。
缓存穿透
Client Redis DB 1.查询key(不存在于缓存) 2.返回缓存未命中(null) 3.查询数据库(该key实际也不存在于数据库) 4.返回无数据(null) 5.向用户返回"无数据"响应 缓存穿透:请求不存在的key,绕过缓存直接冲击数据库 Client Redis DB
缓存穿透 :查询一个不存在的数据,MySQL查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
这里我们主要有两个解决方案:
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 缓存空数据 | 简单 | 消耗内存,可能会发生不一致的问题 |
| 布隆过滤器 | 内存占用较少,没有多余key | 实现复杂,存在误判 |
下面详细说一下什么是布隆过滤器。
布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构 ,用于判断一个元素是否 "可能存在" 于一个集合中。它通过多个哈希函数将元素映射到一个 二进制数组(位数组)的多个位置,将这些位置标记为 1。当查询一个元素时,若其对应的所有哈希位置都为 1,则认为该元素 "可能存在";若有一个位置为 0,则确定该元素 "一定不存在"。

Client BloomFilter Redis DB DB 1.发起查询请求(key=待查ID) 2.通过哈希函数判断key是否"可能存在" 3.返回"无数据" 4.向用户返回"无数据"响应 3.允许查询缓存,key=待查ID 4.返回缓存结果(命中则直接响应;未命中则查数据库) 5.查询数据库,key=待查ID 6.返回数据(存在则返回,不存在则返回null) 7.将数据库结果写入缓存(存在则写正常数据,不存在则写空值缓存) 8.向用户返回响应 alt 缓存未命中 alt key一定不存在(位数组有0) key可能存在(位数组全1) 布隆过滤器拦截"一定不存在"的请求,避免缓存穿透 核心逻辑:用概率型结构过滤无效请求,保护数据库 Client BloomFilter Redis DB DB
要解决缓存穿透问题,布隆过滤器的核心思路是提前拦截 "一定不存在" 的请求,避免这些请求绕过缓存直接冲击数据库。具体逻辑如下:
步骤 1:初始化布隆过滤器
在系统启动或数据加载时,将数据库中所有存在的 key(比如用户 ID、商品 ID 等)通过布隆过滤器的哈希函数映射到其内部的位数组中,标记这些位置为 1。
步骤 2:拦截请求
当客户端发起查询请求时,流程变为:
先查布隆过滤器:用同样的哈希函数计算请求的 key 对应的位数组位置。
- 如果有任意一个位置为 0,说明这个 key一定不存在于数据库,直接返回 "无数据",无需再查缓存和数据库。
- 如果所有位置都为 1,说明这个 key可能存在(因布隆过滤器有误判率),再继续走正常的 "缓存→数据库" 流程。
缓存击穿
Client Cluster Redis DB DB 缓存中key已设置过期时间,此时恰好过期 1.大量并发请求:查询已过期的key 2.所有请求均返回:缓存未命中(key已过期) 3.大量并发请求同时冲击数据库,查询该key 缓存击穿核心:热点key过期瞬间,大量并发请求穿透缓存压垮DB Client Cluster Redis DB DB
**缓存击穿:**给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮。
这里主要有两种解决方式:互斥锁和逻辑过期
互斥锁
Client Cluster DistLock (Redis setnx/Redisson) Redis DB DB 热点key即将过期或已过期 1.并发请求查询热点key 2.返回缓存未命中 3.竞争分布式锁(只有一个客户端能获取) 4.查询数据库获取最新数据 5.返回数据 6.将数据写入缓存(并设置合理过期时间) 7.释放锁 8.返回数据给用户 9.短暂休眠后,再次查询缓存(等待持有锁的客户端更新缓存) 10.返回已更新的缓存数据 11.返回数据给用户 alt 成功获取锁 未获取到锁 互斥锁保证"只有一个请求去查数据库",其他请求等待缓存更新后再读缓存 Client Cluster DistLock (Redis setnx/Redisson) Redis DB DB
- 思路 :当缓存未命中时,客户端先竞争分布式锁,只有获取到锁的客户端才去查询数据库并更新缓存,其他客户端则等待一段时间后重新查询缓存。
- 优点 :确保高并发场景下只有一个请求穿透到数据库,有效保护数据库;实现相对灵活,可适配多种分布式锁方案(如 Redis 的
setnx、Redisson 框架等)。 - 缺点:存在一定的锁竞争开销;若持有锁的客户端查询数据库或更新缓存时发生异常,需设置锁的超时时间避免死锁。
逻辑删除
Thread1 Thread2 Thread3 Thread4 Cache DB Lock 客户端 数据存储结构含"逻辑过期时间",缓存本身无物理过期时间 1.查询缓存,检查逻辑过期时间 返回数据(逻辑已过期) 2.尝试获取互斥锁 锁获取成功 3.开启新线程(线程2)执行缓存重建 4.返回过期数据 1.查询数据库,获取最新数据 返回最新数据 2.写入新数据到缓存,并重置逻辑过期时间 缓存更新成功 3.释放互斥锁 1.查询缓存,检查逻辑过期时间 返回数据(逻辑已过期) 2.尝试获取互斥锁 锁获取失败(被线程1持有) 3.返回过期数据 1.查询缓存,检查逻辑过期时间 返回数据(逻辑未过期) 返回正常数据 高可用:过期数据兜底,用户始终能拿到数据 性能优:仅单线程查库,避免并发冲击DB Thread1 Thread2 Thread3 Thread4 Cache DB Lock 客户端
这是逻辑过期 + 互斥锁的方案来解决缓存击穿,核心是通过 "逻辑上标记过期时间、加锁保证单线程更新、异步重建缓存" 的流程,既避免数据库被并发冲击,又保证用户能拿到数据(过期数据兜底)。具体过程如下:
- 缓存存储结构设计
缓存中存储的数据包含两部分:实际业务数据 + 逻辑过期时间戳 (缓存本身不设置物理过期时间)。例如存储结构为 {data: "商品详情", expireTime: 1741363200000}。
- 线程 1 的流程(触发缓存更新)
- 步骤 1 :线程 1 查询缓存,发现逻辑过期时间已到 (当前时间超过
expireTime)。 - 步骤 2 :线程 1 尝试获取互斥锁 (如 Redis 的
setnx锁),且获取成功。 - 步骤 3 :线程 1 开启新线程(线程 2) 去执行缓存重建逻辑,自己则立即返回过期的缓存数据给用户(保证用户能拿到数据,不阻塞)。
- 线程 2 的流程(重建缓存)
- 步骤 1:线程 2 查询数据库,获取最新的业务数据。
- 步骤 2 :线程 2 将新数据写入缓存,并重置逻辑过期时间戳(比如设置为未来 30 分钟)。
- 步骤 3:线程 2 释放互斥锁,完成缓存更新。
- 线程 3 的流程(锁竞争失败)
- 步骤 1:线程 3 查询缓存,发现逻辑过期时间已到。
- 步骤 2 :线程 3 尝试获取互斥锁,但获取失败(因为锁被线程 1 持有)。
- 步骤 3 :线程 3 直接返回过期的缓存数据给用户(等待线程 2 完成缓存更新)。
- 线程 4 的流程(缓存未过期)
- 线程 4 查询缓存时,发现逻辑过期时间未到,直接命中缓存并返回正常数据,流程结束。
缓存雪崩
Client Cluster Redis DB DB 大量key同时过期(或缓存服务宕机) 1.大量并发请求查询不同的key 2.所有请求均返回:缓存未命中 3.大量并发请求同时冲击数据库,查询多个key 4.数据库压力剧增,响应缓慢甚至宕机 5.用户请求超时,系统可用性下降 缓存雪崩核心:大量key同时失效/缓存宕机,导致流量全压向数据库 Client Cluster Redis DB DB
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
| 解决方法 | 具体说明 | 优势 | 注意事项 |
|---|---|---|---|
| 给不同Key的TTL添加随机值 | 为每个缓存Key的过期时间在基础值上增加一个随机偏移量(如基础TTL是30分钟,随机增加0-5分钟),避免大量Key在同一时间点集中过期。 | 实现简单,能从根源上分散Key的过期时间,防止"时间点集中击穿"的雪崩场景。 | 需合理设置随机偏移的范围,避免因偏移过大导致缓存数据长期未更新而出现一致性问题。 |
| 利用Redis集群提高服务的可用性 | 通过Redis主从、哨兵或Cluster集群模式,实现缓存服务的高可用。当部分节点故障时,集群可自动切换或路由请求,保证缓存服务不宕机。 | 从缓存服务层面保障可用性,避免因单点缓存故障导致所有请求穿透到数据库。 | 需做好集群的监控、扩容和数据同步策略,确保集群性能和数据一致性。 |
| 给缓存业务添加降级限流策略 | 当缓存服务出现异常(如响应超时、节点不可用)或数据库压力剧增时,启动降级策略(如返回默认值、拒绝部分请求),同时通过限流(如令牌桶、漏桶算法)控制请求流量,避免数据库被压垮。 | 能在缓存雪崩发生时,主动切断流量对数据库的冲击,保障核心业务的可用性。 | 需提前定义降级和限流的触发条件、阈值,以及降级后的兜底逻辑(如返回兜底数据、提示页面),同时要做好降级后的监控和恢复机制。 |
| 给业务添加多级缓存 | 构建"本地缓存(如Guava Cache)+ 分布式缓存(如Redis)"的多级缓存架构。请求优先查询本地缓存,本地缓存未命中再查询分布式缓存,最后才查询数据库。 | 多级缓存可分散流量压力,本地缓存能拦截大量高频请求,降低分布式缓存和数据库的负载;即使分布式缓存雪崩,本地缓存仍能提供部分数据兜底。 | 需注意多级缓存的一致性问题(如本地缓存的过期、更新机制),以及本地缓存的内存占用控制,避免影响业务系统本身的性能。 |
Redis和DB双写一致性
我们知道Redis作为缓存,数据是主要来源于数据库的,那么当数据库的数据需要更新时,是先删除缓存再更新数据库;还是先更新数据库再删除缓存呢?
数据一致的场景
先删除缓存,再更新数据库
要理解"先删除缓存,再修改数据库"为何会导致数据不一致,需结合并发场景分析流程:
假设存在两个并发操作的线程:
- 线程1(写操作):执行"删除缓存 → 修改数据库(将值从10改为20)"。
- 线程2(读操作):执行"查询缓存(未命中)→ 查询数据库(此时线程1的数据库修改可能还未完成)→ 写入缓存(将旧值10写入缓存)"。
此时,数据库中是新值20,但缓存中是旧值10,就出现了缓存与数据库的数据不一致。
先更新数据库,再更新缓存
假设存在两个并发线程:
- 线程 1 查询缓存,未命中 ,于是去查询数据库(此时数据库中是旧值 ,比如
v=10)。 - 线程 2先更新数据库 ,将值从
10改为20。 - 线程 2再更新缓存 ,将缓存值设为
20。 - 线程 1 拿到数据库的旧值
10,写入缓存 ,将缓存值覆盖为10。
双写一致
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致。
延迟双删
延迟双删是针对 "先删除缓存,再修改数据库" 场景的优化方案,流程如下:
- 第一次删除缓存:写操作开始时,先删除缓存中的旧数据。
- 修改数据库:执行数据库的更新操作。
- 延迟一段时间后,第二次删除缓存:等待足够时间(确保读操作的 "缓存未命中→查数据库→写缓存" 流程完成),再次删除缓存。
共享锁,排他锁
**共享锁:**读锁readLock,加锁之后,其他线程可以共享读操作
**排他锁:**独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作
对于数据强一致性来说,我们可以通过共享锁和排他锁来解决。
写操作(如更新数据)需加排他锁,确保写过程中没有并发读 / 写干扰,步骤如下:
- 写线程发起写请求,先对数据库中要修改的数据行加排他锁(X 锁)。
- 加锁成功后,执行数据库更新(如值从 10→20);若加锁失败(被其他锁占用),则等待直到锁释放。
- 数据库更新完成后,更新或删除缓存(根据双写策略选择,如 "改库后更缓存""删缓存后改库")。
- 缓存操作完成后,释放排他锁(X 锁)。
读操作(如查询数据)需加共享锁,确保读过程中不会被写操作打断,步骤如下:
- 读线程发起读请求,先对数据库中要查询的数据行加共享锁(S 锁)。
- 加锁成功后,查询数据库(此时数据库数据已被写锁保护,要么是旧值的稳定态,要么是新值的稳定态,不会读到 "中间修改值");若加锁失败(被写锁占用),则等待直到写锁释放。
- 查询到数据库最新值后,写入或更新缓存。
- 缓存操作完成后,释放共享锁(S 锁)。
读线程 数据库 写线程 缓存 1. 加共享锁(S锁) 加锁成功 2. 查库(旧值10) 返10 3. 加排他锁(X锁) 4. 阻塞(S/X冲突) 5. 写10到缓存 写完 6. 释放S锁 锁释放 7. 加X锁成功 8. 改库(10→20) 改完 9. 写20到缓存 写完 10. 释放X锁 锁释放 结果:缓存=20 数据库=20→一致 读线程 数据库 写线程 缓存
异步通知
异步通知保证数据的最终一致性
- 数据写入阶段 :
- 业务发起 "修改数据" 请求,由
item-service(业务服务)执行数据库操作,将新数据写入MySQL。 - 数据库写入成功后,
item-service向MQ(消息队列,如 RabbitMQ、Kafka)发布一条 "数据已更新" 的消息。
- 业务发起 "修改数据" 请求,由
- 缓存更新阶段 :
cache-service(缓存服务)监听MQ中的消息(步骤 2.1),当收到 "数据已更新" 的通知后,执行缓存更新操作。
Redis数据持久化
在Redis中提供了两种数据持久化的方式:1) RDB;2) AOF。
RDB(Redis Database)
RDB是Redis默认的持久化方式,通过周期性生成内存数据的全量快照(.rdb文件)来实现持久化。
1. 工作原理
- 触发方式分手动和自动:手动用
save(阻塞Redis)或bgsave(fork子进程,主进程不阻塞);自动通过配置save <秒数> <修改次数>(如save 900 1表示900秒内1次修改就触发)。 - 子进程遍历内存数据,生成快照文件并替换旧文件,主进程继续处理命令,不影响服务。
2. 优缺点
- 优点:文件体积小,加载速度极快(恢复时直接读快照到内存),对Redis性能影响小(仅fork瞬间有轻微阻塞)。
- 缺点:数据安全性低,快照间隔内(如15分钟)Redis宕机,这段时间的数据会丢失;fork子进程时,内存占用临时翻倍(拷贝写机制)。
AOF(Append Only File)
AOF是"日志型"持久化,通过记录每一条写命令(如set、hmset)到.aof文件,恢复时重新执行命令来还原数据。
1. 工作原理
- 开启方式:配置
appendonly yes,命令执行后先写入aof缓冲区,再根据同步策略刷盘。 - 同步策略(影响性能和安全性):
appendfsync always:每条命令刷盘,数据无丢失,但性能最差;appendfsync everysec:每秒刷盘一次,平衡性能和安全性(默认);appendfsync no:由操作系统决定刷盘时机,性能最好,但数据丢失风险最高。
- AOF重写:解决文件膨胀问题,Redis会生成"最终状态"的精简命令集(如多次set同一key合并为一条),替换旧AOF文件。
2. 优缺点
- 优点:数据安全性高(最多丢失1秒数据),日志文件是文本格式,可手动修改恢复(如删除误操作命令)。
- 缺点:文件体积大,加载速度慢(需重新执行所有命令),写命令刷盘对性能有一定影响(比RDB略高)。
RDB与AOF核心对比
| 维度 | RDB | AOF |
|---|---|---|
| 持久化方式 | 全量快照(周期性) | 增量命令日志(实时/秒级) |
| 数据安全性 | 低(间隔内数据丢失) | 高(最多丢1秒数据) |
| 文件体积 | 小 | 大 |
| 加载速度 | 快 | 慢 |
| 性能影响 | 小(仅fork时阻塞) | 中(刷盘消耗) |
| 适用场景 | 备份、主从复制初始化 | 生产环境高可用(默认开启) |
混合持久化(Redis 4.0+)
- 开启配置
aof-use-rdb-preamble yes,AOF文件开头存储RDB快照,后续存储增量命令日志。 - 优势:加载时先读RDB(快),再执行AOF命令(数据全),兼顾RDB的速度和AOF的安全性。
数据过期策略
Redis 的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用
惰性删除
惰性删除:设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
优点 :对CPU友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查
缺点 :对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放
定期删除
定期删除:每隔一段时间,我们就对一些key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)。
定期清理有两种模式:
- lSLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的hz 选项来调整这个次数
- lFAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。
Redis数据淘汰策略
数据的淘汰策略:当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
Redis支持8种不同策略来选择要删除的key:
| 策略名称 | 核心说明 |
|---|---|
| noeviction | 不淘汰任何key,内存满时不允许写入新数据,默认策略 |
| volatile-ttl | 仅针对设置了TTL的key,比较剩余TTL值,TTL越小越先被淘汰 |
| allkeys-random | 针对全体key,随机选择进行淘汰 |
| volatile-random | 仅针对设置了TTL的key,随机选择进行淘汰 |
| allkeys-lru | 针对全体key,基于LRU(最近最少使用)算法进行淘汰 |
| volatile-lru | 仅针对设置了TTL的key,基于LRU(最近最少使用)算法进行淘汰 |
| allkeys-lfu | 针对全体key,基于LFU(最不经常使用)算法进行淘汰 |
| volatile-lfu | 仅针对设置了TTL的key,基于LFU(最不经常使用)算法进行淘汰 |
LRU (L east R ecently Used)最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
例如:key1是在3s之前访问的, key2是在9s之前访问的,删除的就是key2
LFU (L east F requently Used)最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
例如:key1最近5s访问了4次, key2最近5s访问了9次, 删除的就是key1
使用建议:
-
优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
-
如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
-
如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
-
如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
Redis分布式锁
Redis 分布式锁是基于 Redis 实现的跨进程、跨服务器的并发控制机制,用于解决分布式系统中多个节点(或服务实例)对共享资源的竞争问题,确保同一时刻只有一个节点能操作共享资源,避免并发冲突(比如超卖、重复下单、数据不一致等场景)。
Redis原生实现
Redis实现分布式锁主要利用Redis的setnx命令。setnx是SET if not exists(如果不存在,则 SET)的简写。
bash
# 添加锁,NX是互斥、EX是设置超时时间
SET lock value NX EX 10
# 释放锁,删除即可
DEL key那么Redis实现分布式锁如何合理的控制锁的有效时长?
- 根据业务时间进行预估
- 给锁续期
nil ok 业务超时
或服务宕机 开始 尝试获取锁 判断结果 获取锁失败 获取锁成功 执行业务 释放锁 自动释放锁
手动用 Redis 命令实现分布式锁容易踩坑(如死锁、误删、单点故障),而 Redisson 已经帮你封装好了工业级的分布式锁及各类分布式组件,直接开箱即用。
Redisson实现分布式锁
Redisson 是一个 基于 Redis 实现的 Java 分布式框架,它不仅封装了 Redis 分布式锁的完整实现(解决了手动实现的各种坑),还提供了大量分布式场景下的工具类(如分布式集合、分布式对象、分布式服务等),让开发者无需关注底层 Redis 命令细节,就能快速实现高可用的分布式应用。
Redisson 提供了多种类型的分布式锁,满足不同场景需求:
| 锁类型 | 适用场景 | 核心特点 |
|---|---|---|
| 可重入锁(RLock) | 同一线程需多次获取同一把锁(如递归、嵌套调用) | 支持重入性(避免自己阻塞自己),自动续期(看门狗机制) |
| 公平锁(FairLock) | 需按请求顺序获取锁(避免饥饿) | 保证锁的获取顺序与请求顺序一致 |
| 红锁(RedLock) | Redis 集群场景,需极高可靠性 | 实现 Redis 官方 Redlock 算法,基于多独立 Redis 节点,避免单点故障 |
| 读写锁(RReadWriteLock) | 读多写少场景(如缓存查询 + 更新) | 读锁共享(多个线程可同时读),写锁互斥(同一时刻只有一个线程能写) |
| 信号量(RSemaphore) | 控制并发访问数量(如限流、资源池) | 类似 Java 的 Semaphore,支持 acquire/release,可动态调整许可数 |
| 闭锁(RLatch) | 等待多个线程完成任务后再执行(如批量处理) | 类似 Java 的 CountDownLatch,支持 countDown/await |
看门狗(Watch Dog)机制
手动实现分布式锁时,若业务执行时间超过锁的过期时间,会导致锁提前释放,引发并发问题。Redisson 的 看门狗机制 自动解决此问题:
- 当获取锁成功后,Redisson 会启动一个后台线程(看门狗);
- 若业务未执行完,且锁快过期时,看门狗会自动向 Redis 发送命令延长锁的过期时间;
- 业务执行完成后,手动释放锁,看门狗线程自动销毁;
- 若持有锁的节点崩溃,看门狗线程终止,锁会因过期时间自动释放,避免死锁。
客户端A 客户端B Redisson Redis WatchDog(看门狗) 加锁流程 请求加锁 执行Lua脚本(加锁+设置过期时间) 加锁成功响应 加锁成功 启动续期任务(每隔releaseTime/3续期) 执行Lua脚本(续期锁过期时间) 续期成功响应 执行业务逻辑 loop 执行业务 请求释放锁 执行Lua脚本(释放锁) 释放锁成功响应 释放锁成功 终止续期任务 竞争加锁流程 请求加锁 执行Lua脚本(加锁) 加锁失败响应 加锁失败 再次请求加锁 执行Lua脚本(加锁) 加锁失败响应 加锁失败 loop while循环尝试加锁 请求加锁 执行Lua脚本(加锁) 加锁成功响应 加锁成功 启动续期任务(每隔releaseTime/3续期) 客户端A 客户端B Redisson Redis WatchDog(看门狗)
主从一致性
Redisson 主要通过 MultiLock(联锁)和 RedLock(红锁) 两种机制解决 Redis 主从架构下的一致性问题,核心思路是避免依赖单主节点的同步延迟,通过多独立节点的加锁逻辑保证锁的可靠性。
主从一致性问题的成因
在 Redis 主从架构中,写操作先在主节点 执行,再异步同步到从节点。若主节点在锁信息同步到从节点前宕机,从节点升级为主节点后会丢失锁信息,导致其他节点可重复获取锁,引发并发安全问题。
Redisson 的解决方案
1. MultiLock(联锁):多节点同时加锁
- 原理 :将锁同时写入多个独立的 Redis 节点(可包含主从架构的节点),只有所有节点都加锁成功,才算整体加锁成功。
- 解决逻辑:即使某主节点宕机且从节点未同步锁信息,其他独立节点仍持有锁标识,因此其他线程无法在所有节点上获取锁,避免了锁失效。
2. RedLock(红锁):多节点过半成功机制
- 原理 :基于 Redis 官方 Redlock 算法,向多个无主从关系的独立 Redis 节点(通常 3~5 个)发起加锁请求,只要超过半数节点加锁成功,即视为整体加锁成功。
- 解决逻辑:即使部分节点宕机,只要多数节点正常,锁机制仍能工作,彻底避免主从同步延迟导致的锁丢失。
Redis集群
在Redis中提供的集群方案总共有三种
- 主从复制
- 哨兵模式
- 分片集群
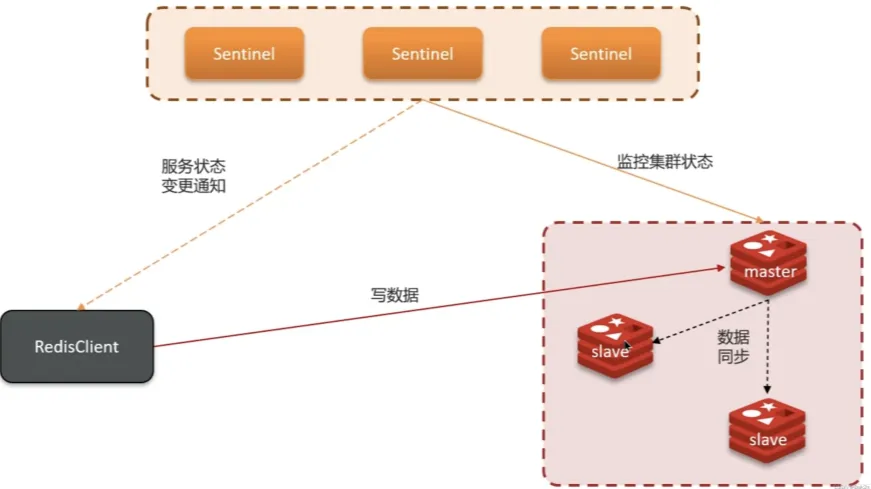
主从复制
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
写操作 数据同步 数据同步 读操作 读操作 客户端 RedisClient master slave/replica slave/replica
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
全量同步
- slave 发起同步请求
slave 执行 replicaof 命令(旧版本为 slaveof),主动与 master(主节点)建立网络连接,开启数据同步流程。 - slave 向 master 请求数据同步
slave 向 master 发送包含自身 replid(复制 ID,标识数据版本)和 offset(复制偏移量,标识已同步到的位置)的请求,告知 master 自己当前的同步状态,请求开始数据同步。 - master 判断同步类型
master 收到请求后,检查 slave 的 replid:
若 replid 与自身不一致(说明是第一次同步,或 slave 之前的主节点不是当前 master),则触发全量复制;
若 replid 一致但 offset 有差异,则触发部分复制(这里我们聚焦全量复制)。 - master 返回自身数据版本信息
master 向 slave 返回自己的 replid 和 offset,让 slave 记录这些信息,作为后续同步的 "基准版本"。 - master 执行 bgsave 生成 RDB 文件
master 执行后台持久化命令 bgsave,在后台异步生成 RDB 快照文件(包含 master 所有数据的全量快照)。这个过程中,master 会继续处理客户端的写请求。 - master 记录 RDB 生成期间的写命令
为了保证 "RDB 生成期间的新写操作不丢失",master 会将这些命令记录到 **repl_backlog 缓冲区 **(复制积压日志)中。 - master 向 slave 发送 RDB 文件
master 生成 RDB 文件后,将其发送给 slave。slave 接收并保存该文件。 - slave 清空本地数据并加载 RDB
slave 先清空自身的旧数据(避免数据冲突),然后加载从 master 收到的 RDB 文件,将 RDB 中的全量数据加载到内存中。 - master 发送 repl_backlog 中的命令
slave 加载完 RDB 后,master 会将 repl_backlog 中记录的 "RDB 生成期间的所有写命令" 发送给 slave。 - slave 执行收到的命令
slave 逐条执行这些命令,确保自己的数据与 master 在 "RDB 生成时刻 + 后续写操作" 后的状态完全一致。
至此,全量复制流程完成,slave 拥有了与 master 完全一致的全量数据。后续 master 有新写操作时,会通过增量复制(基于 repl_backlog 和 offset)持续同步,保证主从数据一致。
Slave Master RDB文件 repl_backlog 1. 执行replicaof命令,建立连接 2. 请求数据同步(携带replid、offset) 3. 判断是否第一次同步(replid是否一致) 4. 返回master的数据版本信息(replid、offset) 5. 保存版本信息 6. 执行bgsave,生成RDB 9. 记录RDB期间的所有命令 7. 发送RDB文件 8. 清空本地数据,加载RDB文件 10. 发送repl_backlog中的命令 11. 执行接收到的命令 Slave Master RDB文件 repl_backlog
增量同步
Redis 主从架构中的增量同步 是用于在主从数据已完成全量同步后,持续保持数据一致的机制,尤其适用于 slave 重启或主从间仅存在少量数据差异的场景。其核心是通过repl_backlog(复制积压日志)和offset(复制偏移量),仅同步 master 上新增的写命令,避免全量复制的性能开销。
以下是 slave 重启后触发增量同步的完整步骤:
- slave 重启
slave 节点重启后,需要重新与 master 同步数据,此时触发增量同步流程。
- slave 向 master 发送
psync请求
slave 向 master 发送psync replid offset命令,其中:
replid:slave 记录的 master 复制 ID(标识数据版本);offset:slave 记录的复制偏移量(标识已同步到的位置)。
- master 判断
replid是否一致
master 收到请求后,检查 slave 的replid是否与自身的replid一致:
- 若一致:说明 slave 之前的主节点就是当前 master,可进行增量同步;
- 若不一致:说明 slave 是新节点或之前的主节点已变更,将触发全量复制 (本文聚焦增量同步,故假设
replid一致)。
- master 回复
continue
master 确认replid一致后,回复continue,表示将进行增量同步。
- slave 保存版本信息
slave 记录 master 返回的replid和offset,作为后续同步的基准。
- master 从
repl_backlog中获取增量数据
master 内部维护repl_backlog缓冲区,该缓冲区按顺序记录了所有 master 的写命令。master 根据 slave 的offset,从repl_backlog中筛选出 "offset之后的所有写命令"。
- master 发送增量命令
master 将筛选出的增量写命令发送给 slave。
- slave 执行增量命令
slave 逐条执行收到的写命令,使自身数据与 master 完全一致。
Slave Master repl_backlog 1. 重启 2. psync replid offset 3. 判断请求replid是否一致 4. 回复 continue 5. 保存版本信息 6. 去repl_backlog中获取offset后的数据 7. 发送offset后的命令 8. 执行命令 Slave Master repl_backlog
哨兵模式
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
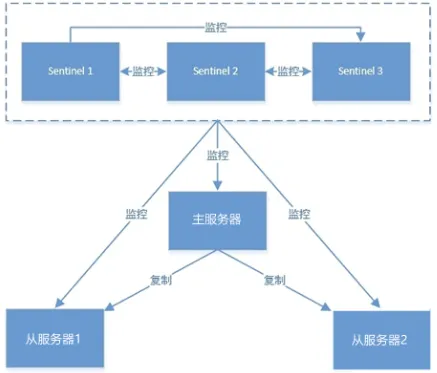
-
监控:Sentinel 会不断检查您的master和slave是否按预期工作
-
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
-
通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
-
主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
-
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
哨兵选主规则
-
首先判断主与从节点断开时间长短,如超过指定值就排该从节点
-
然后判断从节点的slave-priority值,越小优先级越高
-
如果slave-prority一样,则判断slave节点的offset值,越大优先级越高
-
最后是判断slave节点的运行id大小,越小优先级越高。
Redis集群(哨兵模式)脑裂
在 Redis 哨兵(Sentinel)模式中,脑裂(Split Brain) 是指主从架构因网络分区(或主节点短暂不可达),导致哨兵误判主节点宕机,将从节点升级为新主节点;而原主节点恢复后,集群中出现 两个独立的主节点(旧主 + 新主),最终引发数据不一致、业务冲突的严重问题。
关于解决的话,我记得在redis的配置中可以设置:第一可以设置最少的salve节点个数,比如设置至少要有一个从节点才能同步数据,第二个可以设置主从数据复制和同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失。
min-replicas-to-write 1 表示最少的salve节点为1个
min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过5秒
分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
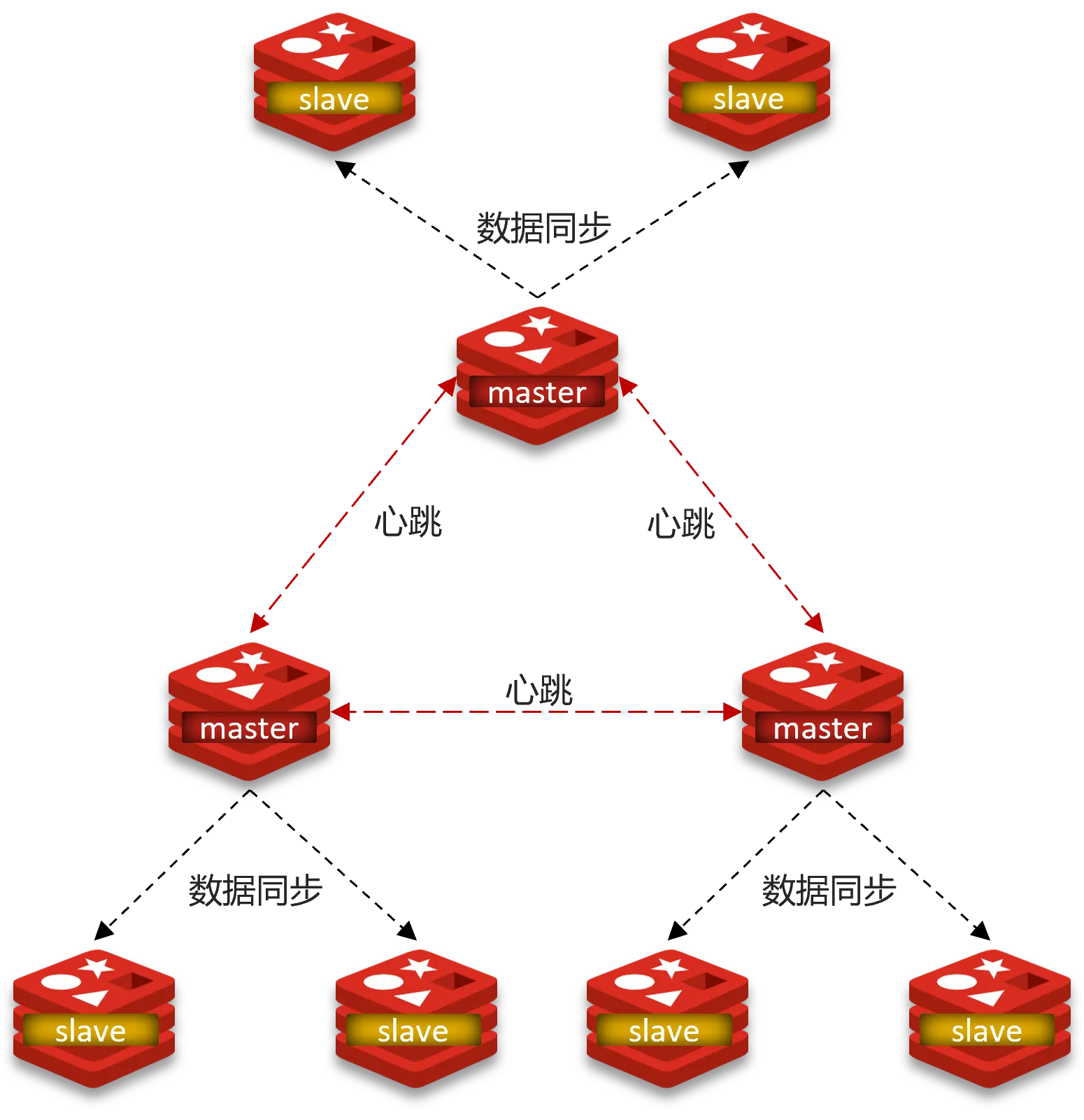
分片集群结构-数据读写
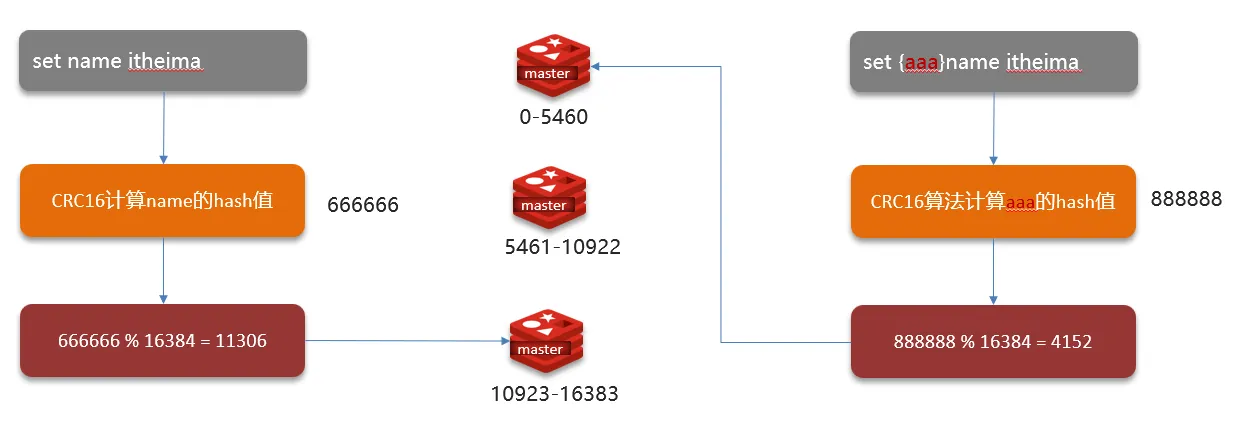
Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
Redis为什么那么快?
-
Redis是纯内存操作,执行速度非常快
-
采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
-
使用I/O多路复用模型,非阻塞IO
I/O多路复用模型
IO多路复用:是利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
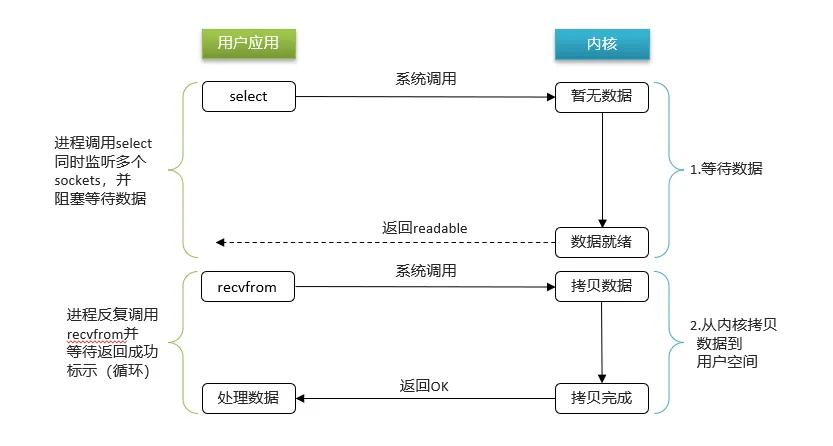
阶段一:
①用户进程调用select,指定要监听的Socket集合
②内核监听对应的多个socket
③任意一个或多个socket数据就绪则返回readable
④此过程中用户进程阻塞
阶段二:
①用户进程找到就绪的socket
②依次调用recvfrom读取数据
③内核将数据拷贝到用户空间
④用户进程处理数据
er都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
分片集群结构-数据读写
Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
外链图片转存中...(img-ioDCfcbK-1762528250691)
Redis为什么那么快?
-
Redis是纯内存操作,执行速度非常快
-
采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
-
使用I/O多路复用模型,非阻塞IO
I/O多路复用模型
IO多路复用:是利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
阶段一:
①用户进程调用select,指定要监听的Socket集合
②内核监听对应的多个socket
③任意一个或多个socket数据就绪则返回readable
④此过程中用户进程阻塞
阶段二:
①用户进程找到就绪的socket
②依次调用recvfrom读取数据
③内核将数据拷贝到用户空间
④用户进程处理数据