数据写进去了,接下来就是把它们查出来。InfluxDB使用InfluxQL作为查询语言,语法类似SQL,但专门为时间序列数据优化过。
如果你熟悉SQL,学InfluxQL会很快上手。如果不熟悉也没关系,我们从基础开始。
1 基础查询语法
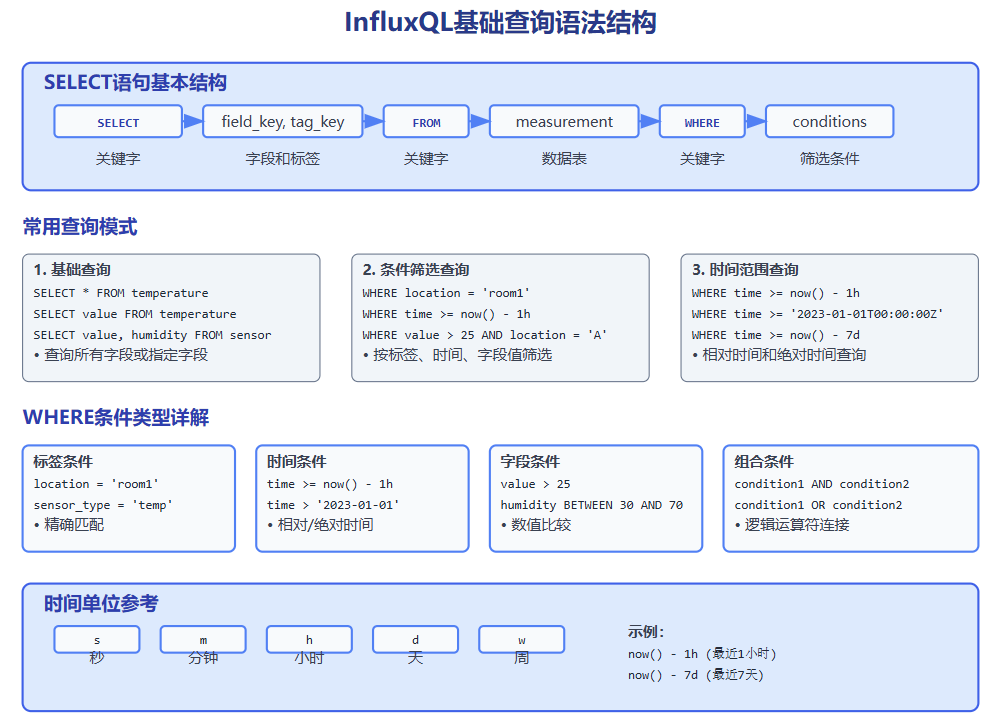
图1-1:InfluxQL基础查询语法结构示意图,展示了SELECT语句的组成部分、常见查询模式以及WHERE子句的使用方法
1.1 SELECT语句结构
InfluxQL的基本结构和SQL很像:
sql
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]最简单的查询:
sql
-- 查询所有字段
SELECT * FROM temperature
-- 查询特定字段
SELECT value FROM temperature
-- 查询多个字段
SELECT value, humidity FROM temperature1.2 WHERE条件筛选
用WHERE来筛选数据:
sql
-- 按标签筛选
SELECT * FROM temperature WHERE location = 'room1'
-- 按时间筛选
SELECT * FROM temperature WHERE time >= '2023-01-01T00:00:00Z'
-- 组合条件
SELECT * FROM temperature
WHERE location = 'room1' AND time >= now() - 1h1.3 时间范围查询
时间是时序数据的核心,InfluxQL提供了灵活的时间查询:
sql
-- 查询最近1小时的数据
SELECT * FROM temperature WHERE time >= now() - 1h
-- 查询特定时间段
SELECT * FROM temperature
WHERE time >= '2023-01-01T00:00:00Z'
AND time <= '2023-01-01T23:59:59Z'
-- 查询最近7天
SELECT * FROM temperature WHERE time >= now() - 7d
-- 查询今天的数据
SELECT * FROM temperature WHERE time >= now() - 1d时间单位很丰富:
s秒m分钟h小时d天w周
2 聚合函数
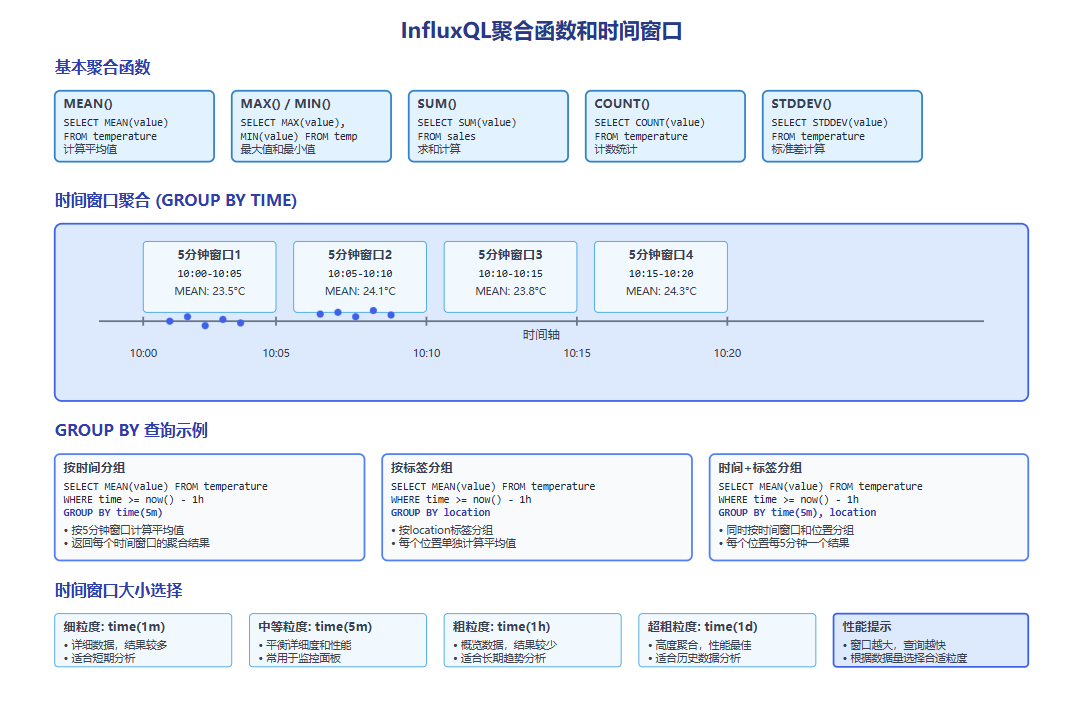
图2-1:InfluxQL聚合函数和时间窗口示意图,展示了基本聚合函数的使用方法、GROUP BY TIME的工作原理以及不同时间窗口粒度的性能对比
2.1 基本聚合函数
InfluxQL提供了丰富的聚合函数:
sql
-- 计算平均值
SELECT MEAN(value) FROM temperature WHERE time >= now() - 1h
-- 计算最大值和最小值
SELECT MAX(value), MIN(value) FROM temperature WHERE time >= now() - 1h
-- 计算总和
SELECT SUM(value) FROM temperature WHERE time >= now() - 1h
-- 计算数量
SELECT COUNT(value) FROM temperature WHERE time >= now() - 1h
-- 计算标准差
SELECT STDDEV(value) FROM temperature WHERE time >= now() - 1h2.2 时间窗口聚合
GROUP BY TIME是InfluxQL的核心功能,用来按时间窗口聚合数据:
sql
-- 按5分钟窗口计算平均值
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(5m)
-- 按1小时窗口计算最大值
SELECT MAX(value) FROM temperature
WHERE time >= now() - 1d
GROUP BY time(1h)
-- 按天计算平均值
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 30d
GROUP BY time(1d)2.3 按标签分组
除了时间,还可以按标签分组:
sql
-- 按location分组
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY location
-- 按时间和标签同时分组
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(5m), location
-- 多个标签分组
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY location, sensor_type3 高级查询功能
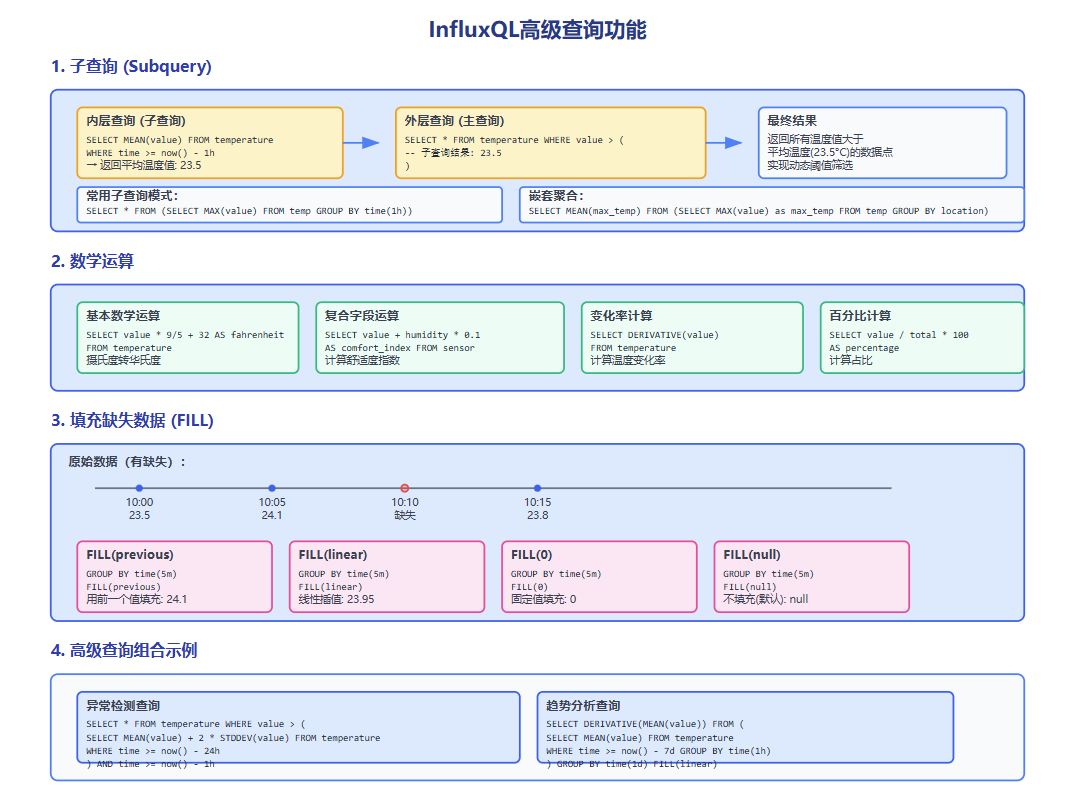
图3-1:InfluxQL高级查询功能示意图,展示了子查询、数学运算和数据填充等高级功能的使用方法和应用场景
3.1 子查询
InfluxQL支持子查询,用来处理复杂的数据分析:
sql
-- 查询高于平均温度的数据点
SELECT * FROM temperature
WHERE value > (
SELECT MEAN(value) FROM temperature WHERE time >= now() - 1h
)
-- 查询每小时最高温度的时间点
SELECT * FROM (
SELECT MAX(value) FROM temperature
WHERE time >= now() - 1d
GROUP BY time(1h)
)3.2 数学运算
可以对字段进行数学运算:
sql
-- 温度单位转换(摄氏度转华氏度)
SELECT value * 9/5 + 32 AS fahrenheit FROM temperature
-- 计算温湿度指数
SELECT value + humidity * 0.1 AS comfort_index FROM temperature
-- 计算变化率
SELECT DERIVATIVE(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(1m)3.3 填充缺失数据
时序数据经常有缺失值,可以用FILL来处理:
sql
-- 用前一个值填充
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(5m)
FILL(previous)
-- 用线性插值填充
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(5m)
FILL(linear)
-- 用固定值填充
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(5m)
FILL(0)
-- 不填充(默认)
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(5m)
FILL(null)4 窗口函数和移动计算
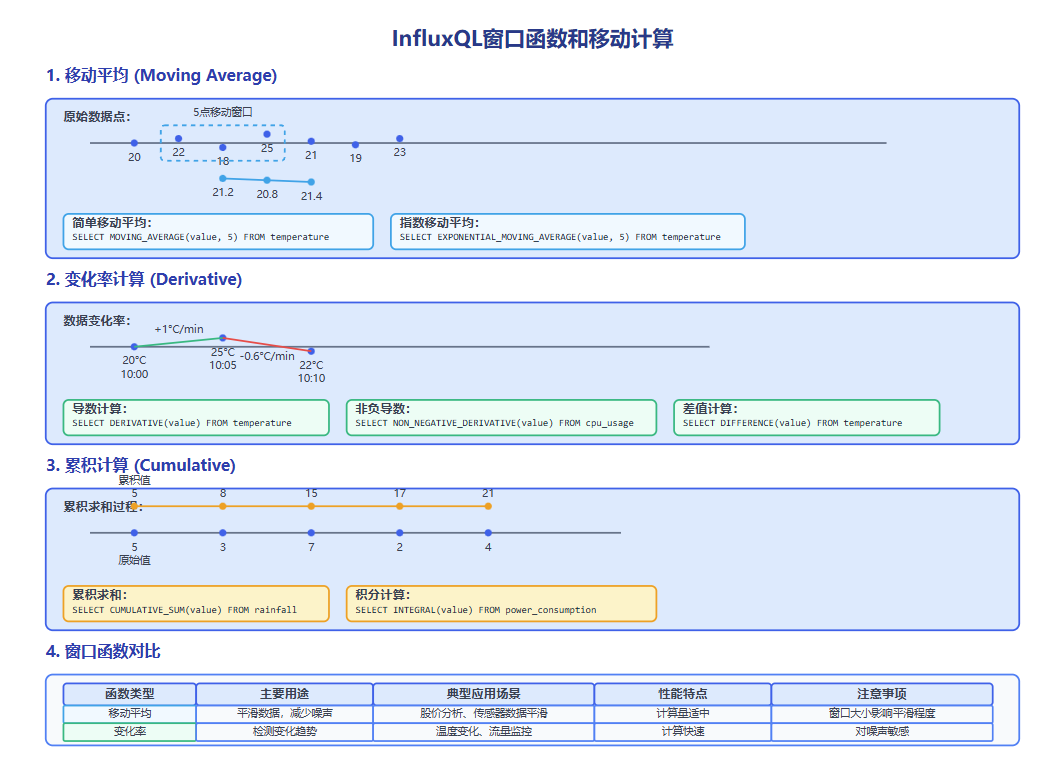
图4-1:InfluxQL窗口函数和移动计算示意图,展示了移动平均、导数计算和累积计算等窗口函数的工作原理和应用场景
4.1 移动平均
sql
-- 5点移动平均
SELECT MOVING_AVERAGE(value, 5) FROM temperature
WHERE time >= now() - 1h
-- 指数移动平均
SELECT EXPONENTIAL_MOVING_AVERAGE(value, 5) FROM temperature
WHERE time >= now() - 1h4.2 变化率计算
sql
-- 计算导数(变化率)
SELECT DERIVATIVE(value) FROM temperature
WHERE time >= now() - 1h
GROUP BY time(1m)
-- 计算非负导数
SELECT NON_NEGATIVE_DERIVATIVE(value) FROM cpu_usage
WHERE time >= now() - 1h
GROUP BY time(1m)
-- 计算差值
SELECT DIFFERENCE(value) FROM temperature
WHERE time >= now() - 1h4.3 累积计算
sql
-- 累积和
SELECT CUMULATIVE_SUM(value) FROM rainfall
WHERE time >= now() - 1d
-- 积分计算
SELECT INTEGRAL(value) FROM power_consumption
WHERE time >= now() - 1d
GROUP BY time(1h)5 正则表达式和模式匹配
5.1 正则表达式查询
sql
-- 匹配特定模式的标签值
SELECT * FROM temperature WHERE location =~ /room[0-9]+/
-- 不匹配特定模式
SELECT * FROM temperature WHERE location !~ /test.*/
-- 匹配多个measurement
SELECT * FROM /temperature|humidity/ WHERE time >= now() - 1h5.2 LIKE操作符
sql
-- 模糊匹配
SELECT * FROM temperature WHERE location LIKE 'room%'
-- 不匹配
SELECT * FROM temperature WHERE location NOT LIKE 'test%'6 数据排序和限制
6.1 ORDER BY排序
sql
-- 按时间升序(默认)
SELECT * FROM temperature ORDER BY time ASC
-- 按时间降序
SELECT * FROM temperature ORDER BY time DESC
-- 按字段值排序
SELECT * FROM temperature ORDER BY value DESC6.2 LIMIT限制结果
sql
-- 限制返回条数
SELECT * FROM temperature LIMIT 100
-- 跳过前N条记录
SELECT * FROM temperature LIMIT 100 OFFSET 50
-- 获取最新的10条记录
SELECT * FROM temperature ORDER BY time DESC LIMIT 107 多表查询和连接
7.1 多measurement查询
sql
-- 查询多个measurement
SELECT * FROM temperature, humidity WHERE time >= now() - 1h
-- 使用正则表达式查询多个measurement
SELECT * FROM /temperature|humidity/ WHERE time >= now() - 1h7.2 数据合并
虽然InfluxQL不支持传统的JOIN,但可以用其他方式合并数据:
sql
-- 在应用层合并不同measurement的数据
-- 或者使用Flux查询语言(InfluxDB 2.0+)8 实用查询示例
8.1 监控告警查询
sql
-- 查找温度异常的时间点
SELECT * FROM temperature
WHERE value > 30 OR value < 10
-- 查找CPU使用率持续高于80%的时间段
SELECT MEAN(cpu_percent) FROM cpu_usage
WHERE time >= now() - 1h
GROUP BY time(5m)
HAVING MEAN(cpu_percent) > 808.2 性能分析查询
sql
-- 计算响应时间的95百分位数
SELECT PERCENTILE(response_time, 95) FROM api_requests
WHERE time >= now() - 1h
GROUP BY time(5m)
-- 查找最慢的请求
SELECT * FROM api_requests
WHERE time >= now() - 1h
ORDER BY response_time DESC
LIMIT 108.3 趋势分析查询
sql
-- 计算同比增长率
SELECT MEAN(value) FROM sales
WHERE time >= now() - 7d
GROUP BY time(1d)
-- 计算移动平均趋势
SELECT MOVING_AVERAGE(MEAN(value), 7) FROM temperature
WHERE time >= now() - 30d
GROUP BY time(1d)9 查询优化技巧
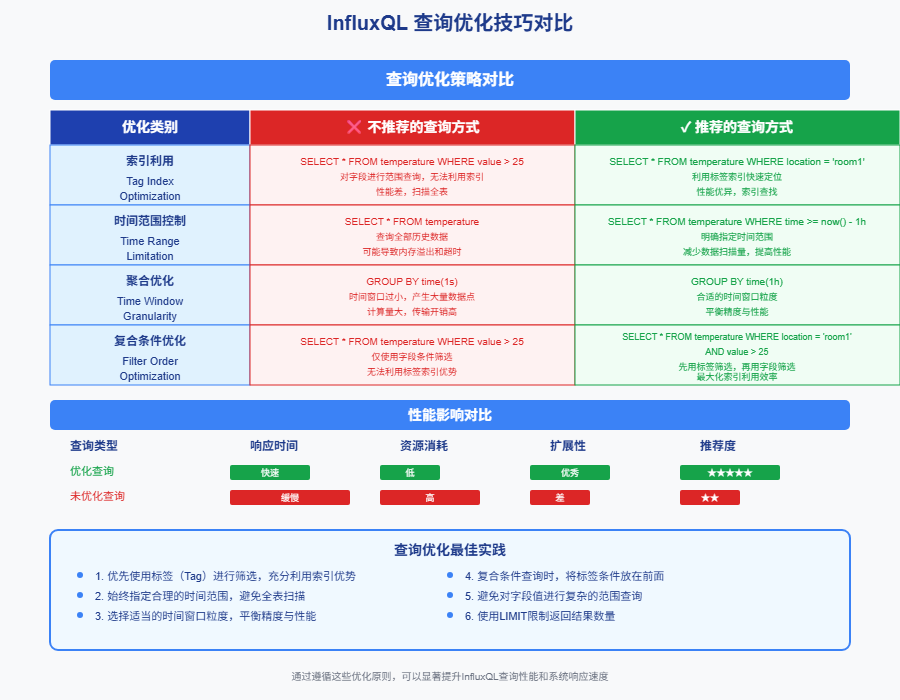
图9-1:InfluxQL查询优化技巧对比图,展示了推荐与不推荐的查询方式对比,以及各种优化策略的性能影响分析
9.1 索引利用
sql
-- 好的查询:利用标签索引
SELECT * FROM temperature WHERE location = 'room1' AND time >= now() - 1h
-- 避免:对字段进行范围查询
SELECT * FROM temperature WHERE value > 25 -- 这会很慢9.2 时间范围控制
sql
-- 总是指定时间范围
SELECT * FROM temperature WHERE time >= now() - 1h
-- 避免查询全部历史数据
SELECT * FROM temperature -- 这可能很慢9.3 聚合优化
sql
-- 使用适当的时间窗口
SELECT MEAN(value) FROM temperature
WHERE time >= now() - 1d
GROUP BY time(1h) -- 而不是 GROUP BY time(1s)10 常见错误和解决方案
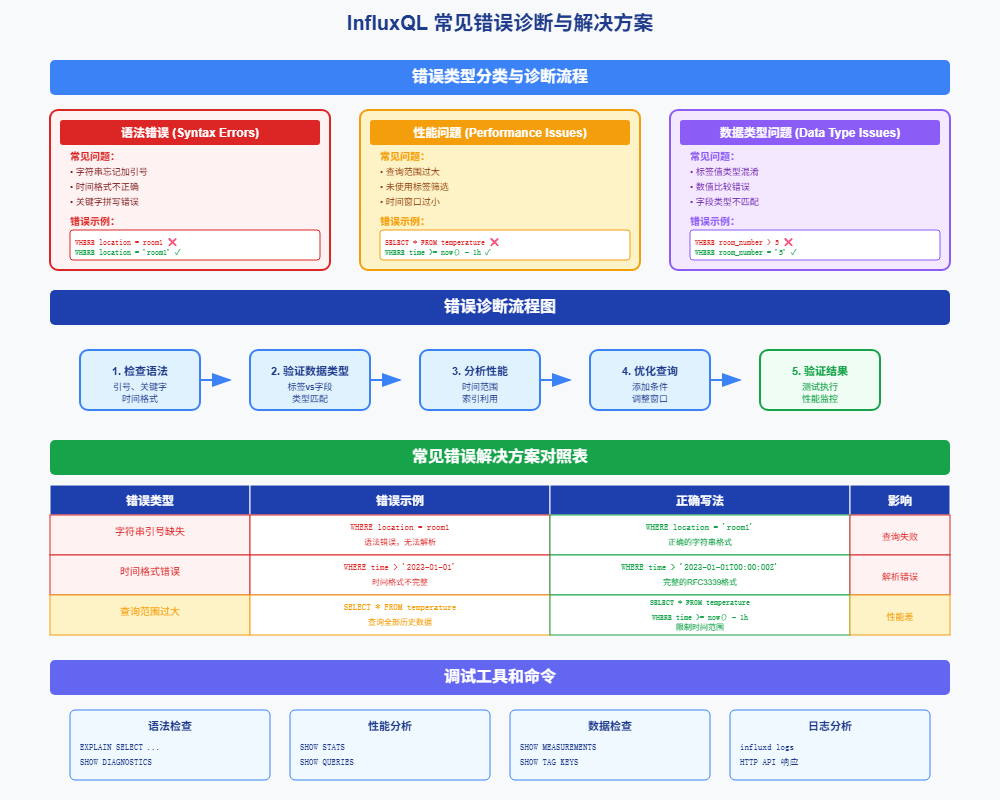
图10-1:InfluxQL常见错误诊断与解决方案图,展示了语法错误、性能问题和数据类型问题的诊断流程以及相应的解决方案
10.1 语法错误
sql
-- 错误:忘记引号
SELECT * FROM temperature WHERE location = room1
-- 正确:字符串要加引号
SELECT * FROM temperature WHERE location = 'room1'
-- 错误:时间格式不对
SELECT * FROM temperature WHERE time > '2023-01-01'
-- 正确:使用完整的时间格式
SELECT * FROM temperature WHERE time > '2023-01-01T00:00:00Z'10.2 性能问题
sql
-- 问题:查询范围太大
SELECT * FROM temperature WHERE time >= '2020-01-01T00:00:00Z'
-- 解决:限制时间范围
SELECT * FROM temperature WHERE time >= now() - 7d
-- 问题:没有使用标签筛选
SELECT * FROM temperature WHERE value > 25
-- 解决:先用标签筛选,再用字段筛选
SELECT * FROM temperature WHERE location = 'room1' AND value > 2510.3 数据类型问题
sql
-- 错误:标签值用数字比较
SELECT * FROM temperature WHERE room_number > 5
-- 正确:标签值是字符串
SELECT * FROM temperature WHERE room_number = '5'11 命令行查询实践
11.1 使用influx CLI
bash
# 进入InfluxDB命令行
influx -host localhost -port 8086
# 选择数据库(InfluxDB 1.x)
USE mydb
# 执行查询
SELECT * FROM temperature WHERE time >= now() - 1h;
# 格式化输出
SELECT * FROM temperature WHERE time >= now() - 1h FORMAT json;11.2 HTTP API查询
bash
# 使用curl查询
curl -G 'http://localhost:8086/query' \
--data-urlencode "db=mydb" \
--data-urlencode "q=SELECT * FROM temperature WHERE time >= now() - 1h"
# InfluxDB 2.0 API
curl -XPOST 'http://localhost:8086/api/v2/query' \
-H 'Authorization: Token your-token' \
-H 'Content-Type: application/vnd.flux' \
-d 'from(bucket:"mybucket") |> range(start:-1h) |> filter(fn:(r) => r._measurement == "temperature")'掌握了InfluxQL,你就能从时序数据中挖掘出有价值的信息了。下一篇我们会学习聚合函数的高级用法,让数据分析更加强大。