摘要:
本文主要介绍redis基本的持久化方式RDB和AOF,以及redis高可用的核心:集群模式,分别介绍了主从集群和分片集群。
一,持久化
1,RDB快照(记录内存物理数据)
RDB可以理解为一张redis物理内存的照片,会以指定的时间间隔执行数据集的时间点快照,优点是体积小而且同步代价小,缺点就是可能会丢失快照之间的数据。
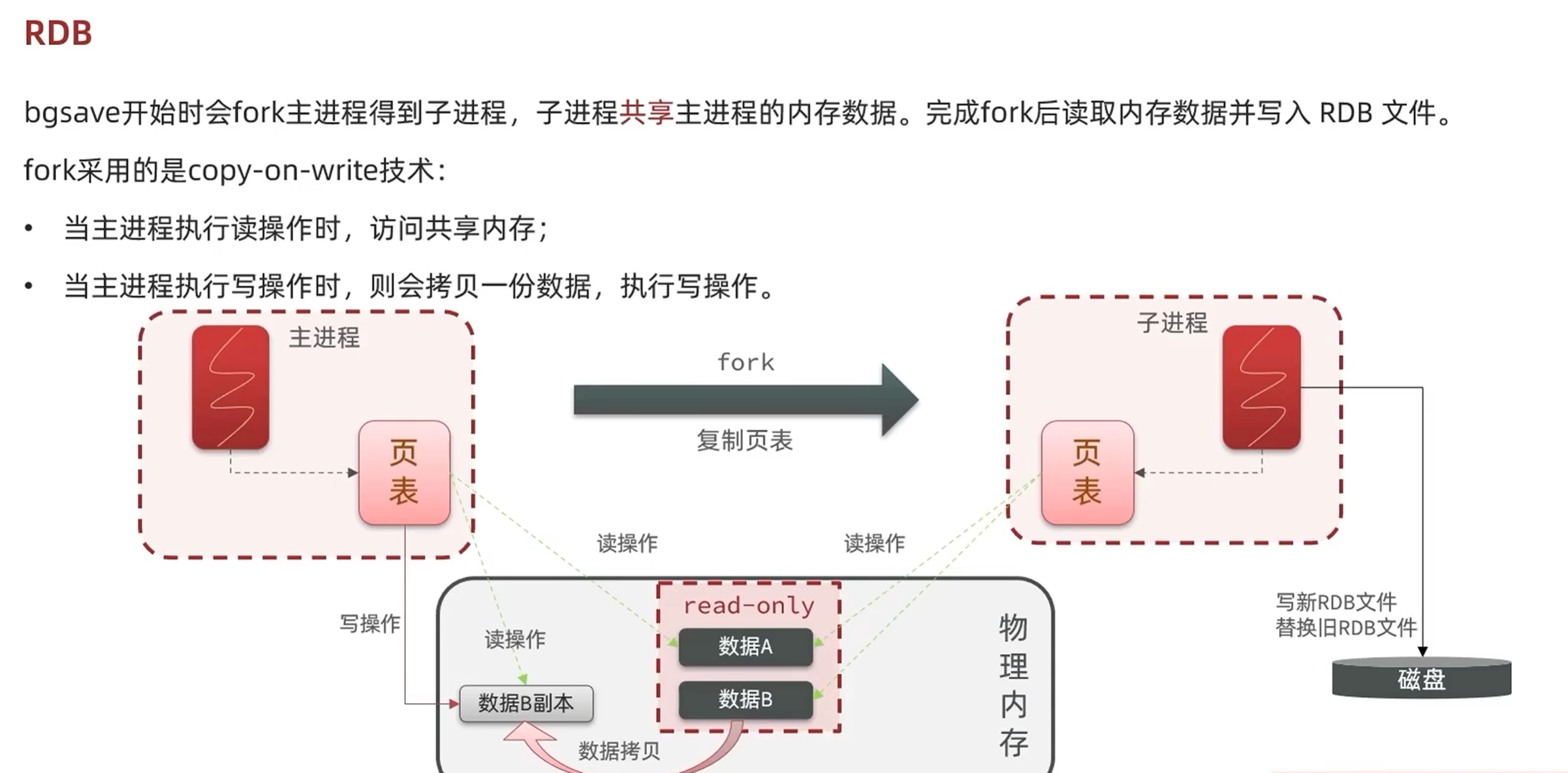
2,AOF日志(记录命令)
AOF日志会记录服务器接收到的每个写入操作,记录的这些操作会在服务器启动时再次执行,以实现数据恢复,优点记录更加完整,缺点就是文件体积大

二,主从集群
1,搭建主从集群
主从集群通过单个主节点和多个从节点不断进行数据同步复制实现读写分离,由主从同步保持数据一致性,同时分离来分担压力
(1)读写分离,提升性能:企业场景大多读多写少主节点专注写,从节点分担大量读请求,大幅度提升吞吐量。
(2)数据备份,防止丢失:从节点实时复制主节点数据,相当于多份数据副本。即使主节点因硬件故障、网络问题宕机,从节点仍保留完整数据,可升级为主节点,快速恢复服务。
(3)高可用性:主从集群是 Redis 高可用的基础,通常配合哨兵机制一起使用;当主节点故障时,可通过手动或自动选举的方式将某个从节点晋升为新主节点,避免服务中断。
2,数据同步原理

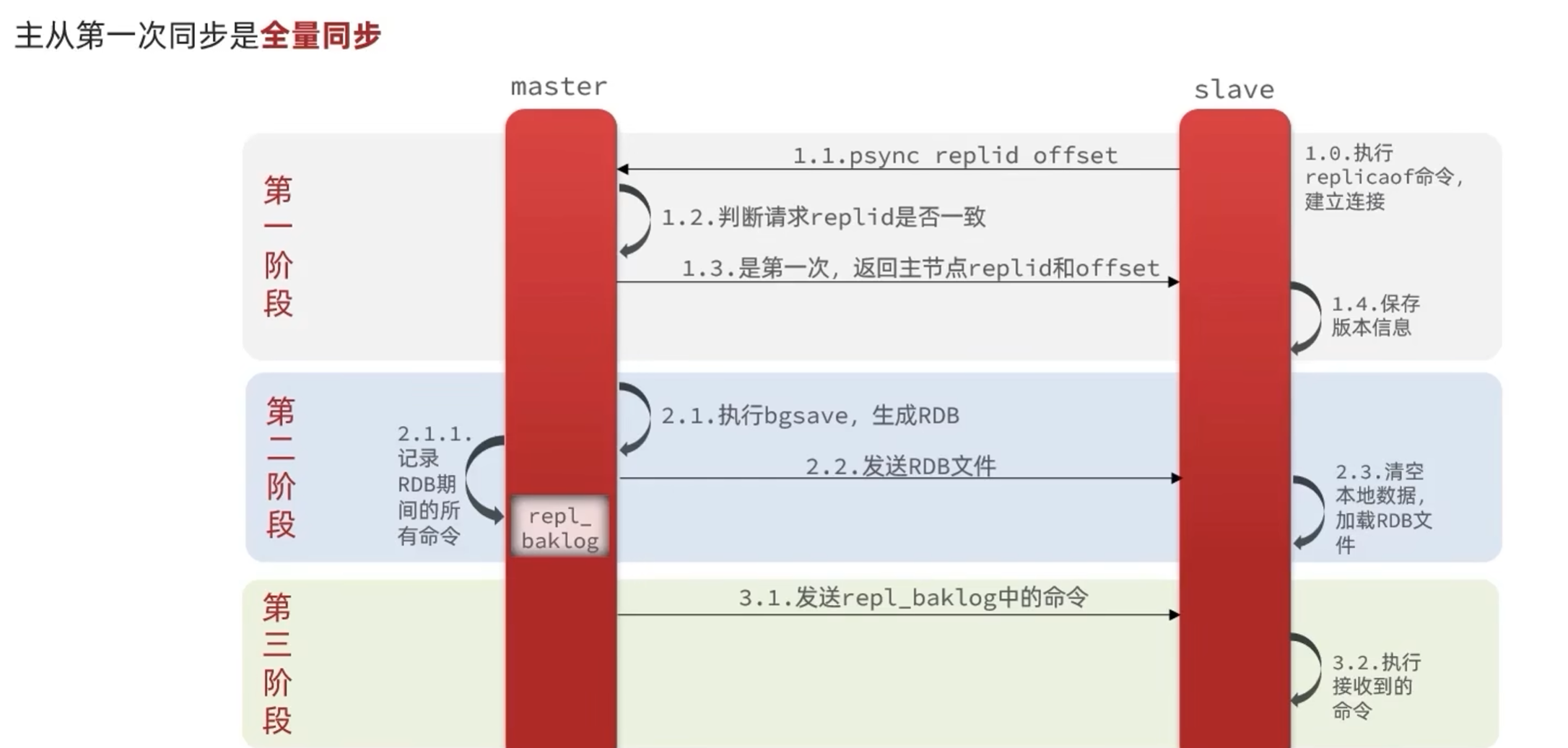
(1)全量同步(第一次连接/repl_baklog未同步数据超限)
主节点主线程fork一个子线程来生成RDB快照 (耗时较久),将快照发送到从节点,从节点写入快照数据,同时主节点将此过程中额外写入的数据的指令存入repl_baklog缓冲中,后续从节点持续从这个缓存中写入新的数据
第一次连接过程:
1,从节点请求增量连接,发送replid编号和偏移量offset
2,主节点对比自己的replid和从节点发送的,第一次连接必定不一致
3,准备进行全量同步,执行bgsave生成RDB快照,在此期间将写操作记录到repl_baklog缓冲中
4,发送快照给从节点,从节点清空本地数据,加载RDB文件
5,发送缓冲中的指令文件,从节点持续写入
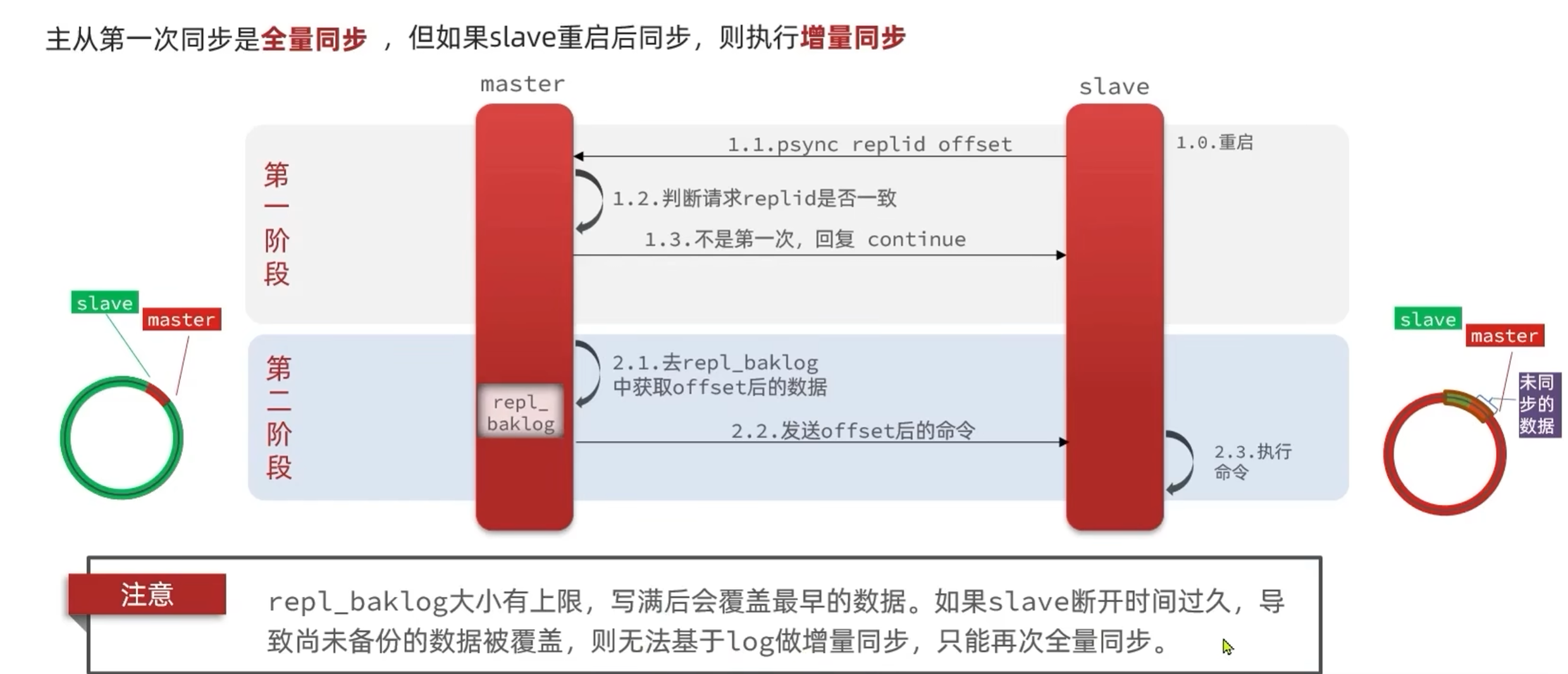
(2)增量同步(从节点恢复连接)
同样发送从节点的id和offset到主节点,对比成功执行增量同步,主节点根据从节点的偏移量offset 得到从节点断开连接后缓冲repl_baklog中额外产生的数据,然后将这些命令发送给从节点
(3)区别
**全量同步:**master节点将完整内存数据生成RDB快照,并发送RDB到slave节点,RDB生成期间和后续的写命令记录在repl_baklog,持续地发送给slave节点。
**增量同步:**slave节点提交自己的offset(增量偏移)到master节点,master节点根据offset从repl_baklog中找到slave缺失的命令起点,逐条发送给slave。
3,哨兵机制
(1)哨兵作用及原理
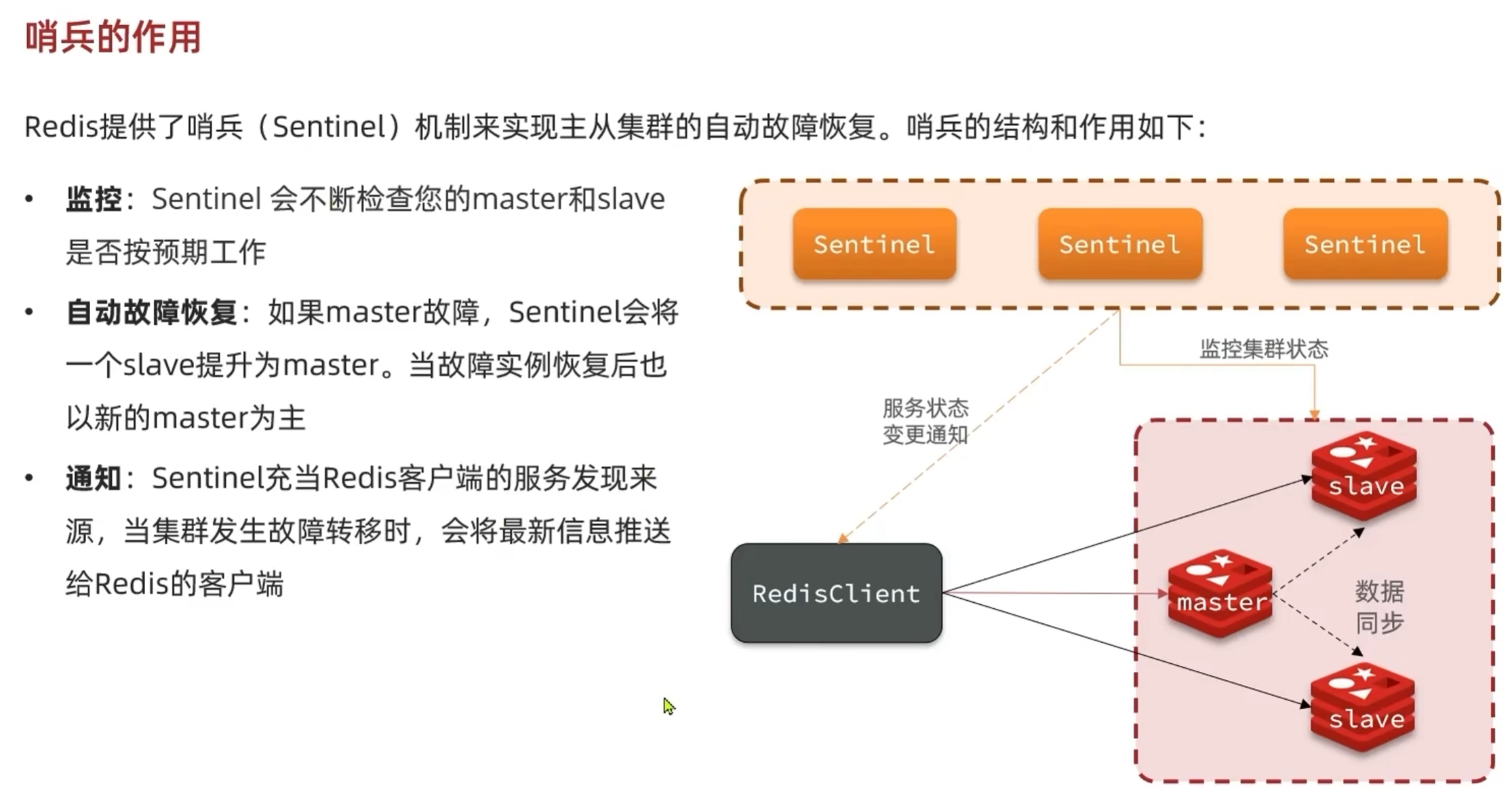
(2)心跳机制(ping命令)
sentinal节点会每隔一秒不断向master节点发送ping命令,根据是否回复来判断节点状态
如果在规定时间内没有收到pong回复,那么就认为该节点主观下线 ,当认为其主观下线的sentinal节点超过指定值 (一般为sentinal实例一半)那么就认定其客观下线
(3)master选择依据

三,分片集群(16384)
1,插槽机制(hash分配)
一个插槽可以对应多个key,一个key经过hash函数之后在对插槽数16384取模(将位置控制在插槽数内)就能够得到key所对应的插槽位置。
2,故障转移
(1)自动故障转移
master宕机后,其slave节点就会自动成为master节点,而原来的主节点在恢复后就会成为slave节点。
(2)手动转移
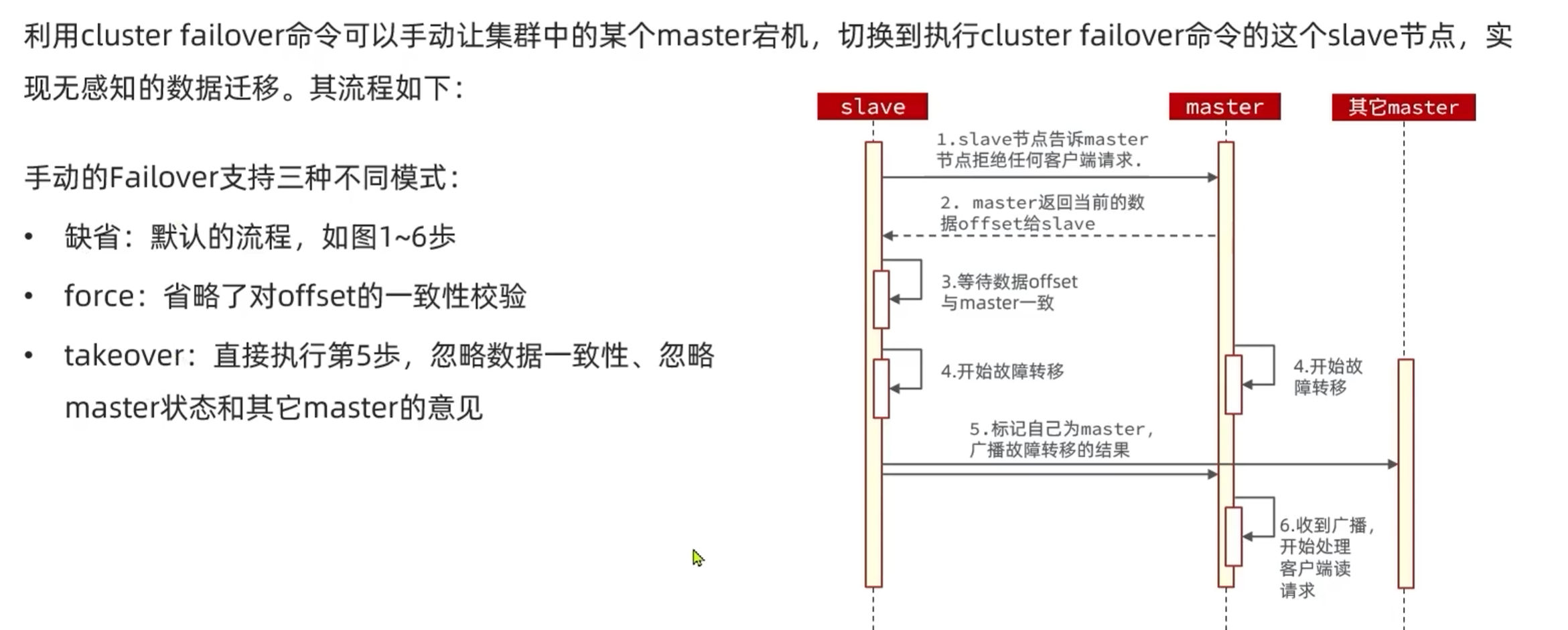
3,集群伸缩
(1)redis-cli --cluster help查看操作集群的命令
(2)添加节点:redis-cli --cluster add-node ip:port + 已存在的ip和port
(3)分配插槽:redis-cli --cluster reshard ip:port(要分配插槽的实例)
(4)配置读写分离(REPLICA_PREFERRED从节点读优先)
java
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder->
clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED)
}