Source
Source执行时由SourceOperatorCoordinator和SourceReader两部分组成,SourceOperatorCoordinator执行SourceSplitEnumerator逻辑,管理SourceSplit, 将SourceSplit分配给SourceReader;SourceReader则读取SourceSplit的具体内容, 传递给SourceOutput发送给下游。
Source接口抽象了工厂方法,可生产SplitEnumerator和SourceReader, 因此,自定义Source时主要关注实现自定义SourceReader和SourceEnumerator。
SourceReader与SourceEnumerator通信图:
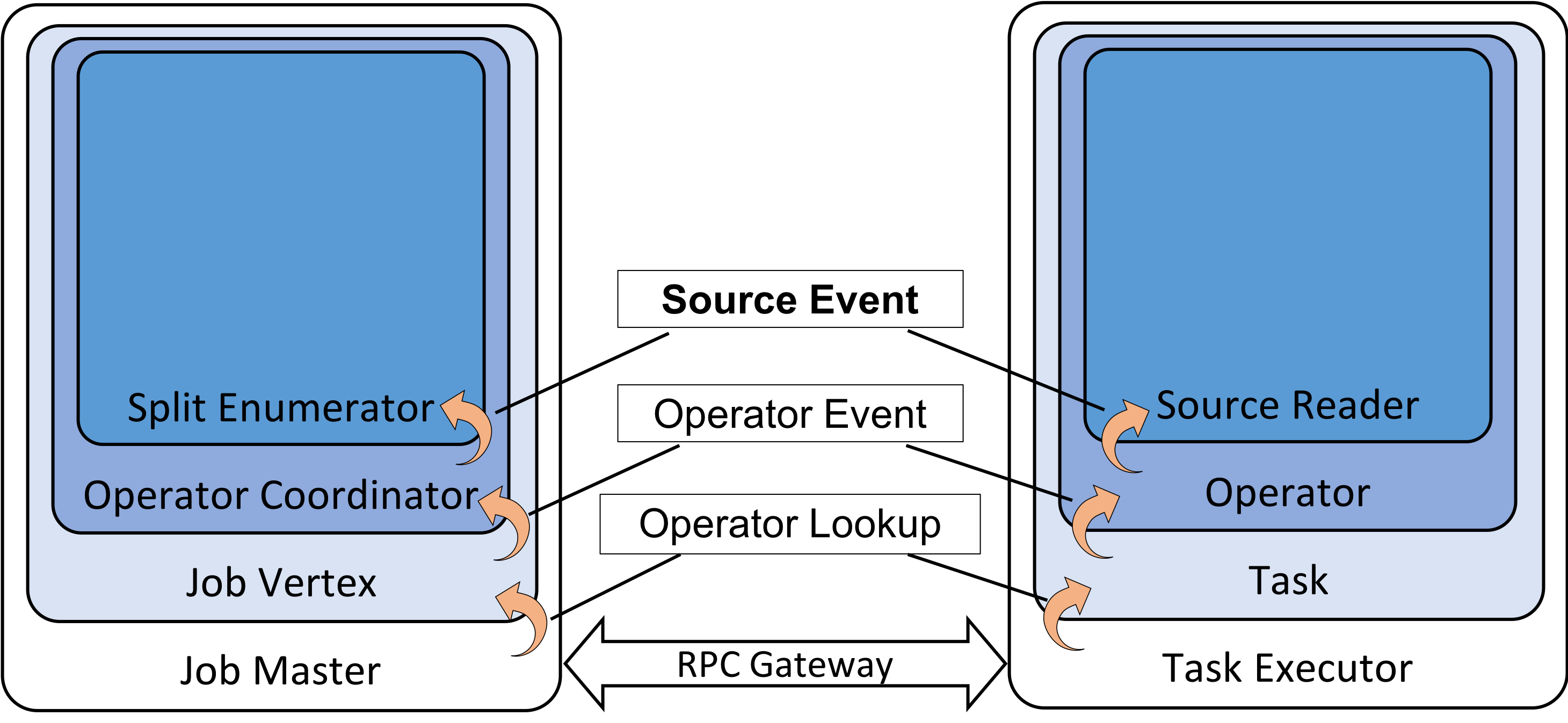
OperatorCoordinator&SplitEnumerator
OperatorCoordinator是在JobMaster启动时创建的,包括SourceOperatorCoordinator, SourceOperatorCoordinator会调用Source接口的createEnumerator方法生产SourceSplitEnumerator。
在创建ExecutionJobVertex时,在initialize方法中会为每个ExecutionJobVertex创建OperatorCoordinatorHolder, OperatorCoordinatorHolder持有对应OperatorID的OperatorCoordinator, 其中SourceOperator对应的SourceCoordinator是通过SourceCoordinatorProvider::getCoordinator创建出来。
SourceCoordinator启动时会调用Source::createEnumerator创建SplitEnumerator并启动,流程如下:
JobMaster::onStart
JobMaster::startJobExecution
JobMaster::startScheduling
SchedulerBase::startScheduling
DefaultOperatorCoordinatorHandler::startAllOperatorCoordinators
DefaultOperatorCoordinatorHandler::startOperatorCoordinators
OperatorCoordinatorHolder::start
SourceCoordinator::start
Source::createEnumerator
SplitEnumerator::startSourceCoordinator启动后就可以处理SourceReader的请求,比如请求Split分配事件RequestSplitEvent,SourceReader注册事件ReaderRegistrationEvent, Watermark报告ReportedWatermarkEvent
SourceReader
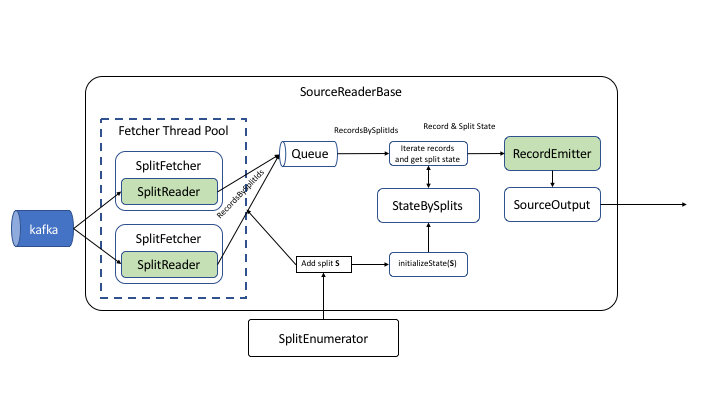
SourceReader是SourceOperator在启动时创建,SourceOperator和SourceCoordinatorProvider由SourceOperatorFactory创建。
SourceTask启动时加载SourceOperator,创建SourceReader, 向SourceOperatorCoordinator注册Reader后启动Reader, 向SourceCoordinator发送RequestSplitEvent事件。
SourceReader启动流程如下:
TaskManager.Task::run
TaskManager.Task::doRun
TaskManager.Task::restoreAndInvoke //调用TaskInvokable.invoke方法
StreamTask::invoke
StreamTask::restoreInternal
SourceOperatorStreamTask::init //创建StreamTaskSourceInput
SourceOperator::initReader
Source::createReader //创建SourceReader
StreamTask::restoreGates
OperatorChain::initializeStateAndOpenOperators
SourceOperator::open
SourceOperator::registerReader //注册Reader
SourceReader::start //启动Reader, 可向Coordinator发送RequestSplitEvent请求Split
StreamTask::runMailboxLoop
MailboxProcessor::runMailboxLoop
StreamTask::processInput
StreamOneInputProcessor::processInput
StreamTaskSourceInput::emitNext
SourceOperator::emitNext
SourceOperator::emitNextNotReading
SourceOperator::initializeMainOutput //创建Source ReaderOutput
SourceReader::pollNext //循环调用从Queue获取RecordsWithSplitIds数据传递给RecordEmitter发送出去
SourceReader::moveToNextSplit
SplitContext::getOrCreateSplitOutput //为每个split创建SourceOutput
RecordEmitter::emitRecord
SourceOutput::collect //发送数据到下游RequestSplitEvent
SourceReader启动后在start方法中向SourceCoordinator发送RequestSplitEvent事件请求Split, SourceCoordinator通过SplitEnumerator获取Split封装成AddSplitEvent返回给SourceReader
SourceCoordinator处理RequestSplitEvent流程:
DefaultOperatorCoordinatorHandler::deliverOperatorEventToCoordinator
OperatorCoordinatorHolder::handleEventFromOperator
SourceCoordinator::handleEventFromOperator
SourceCoordinator::handleRequestSplitEvent //判断是否有可用split
SplitEnumerator::handleSplitRequest
SplitEnumeratorContext::assignSplit //返回split给SourceReader
SourceCoordinatorContext::assignSplits
SourceCoordinatorContext::assignSplitsToAttempts //封装AddSplitEvent消息发送给SourceReaderSingleThreadMultiplexSourceReaderBase
为方便自定义SourceReader, Flink提供了SingleThreadMultiplexSourceReaderBase/SingleThreadFetcherManager实现单线程单分片串行或多分片多路同时读取模型。 SourceReader处理AddSplitEvent事件时会创建一个线程执行SplitFetcher逻辑,将获取的split信息传递给SplitReader, 只要存在未完成的split, SplitFetcher线程就会不断调用SplitReader::fetch获取RecordsWithSplitIds,将RecordsWithSplitIds存入Queue中 给SourceReader主线程消费
AddSplitEvent事件处理流程:
SourceOperator::handleOperatorEvent
SourceOperator::handleAddSplitsEvent
SourceReaderBase::addSplits
SplitContext::new 创建SplitContext, 记录split状态信息
SingleThreadFetcherManager::addSplits //添加split
SingleThreadFetcherManager::createSplitFetcher //创建SplitFetcher线程并启动执行
SplitFetcher::new //Feacher控制中心,保存分配的split信息,以及从split读取的数据
FetchTask::new //创建FetchTask, 从split读取数据,放入Queue
SplitFetcher::addSplits //封装成AddSplitsTask
AddSplitsTask::new
SplitFetcher::run //优先执行AddSplitsTask,将split信息传递给SplitReader,其次调用FetchTask,只要当前的SplitFetcher还有分配的split未读取完成,会不断调用FetchTask::run方法读取数据
AddSplitsTask::run
SplitReader::handleSplitsChanges
FetchTask::run
SplitReader::fetch //获取RecordsWithSplitIds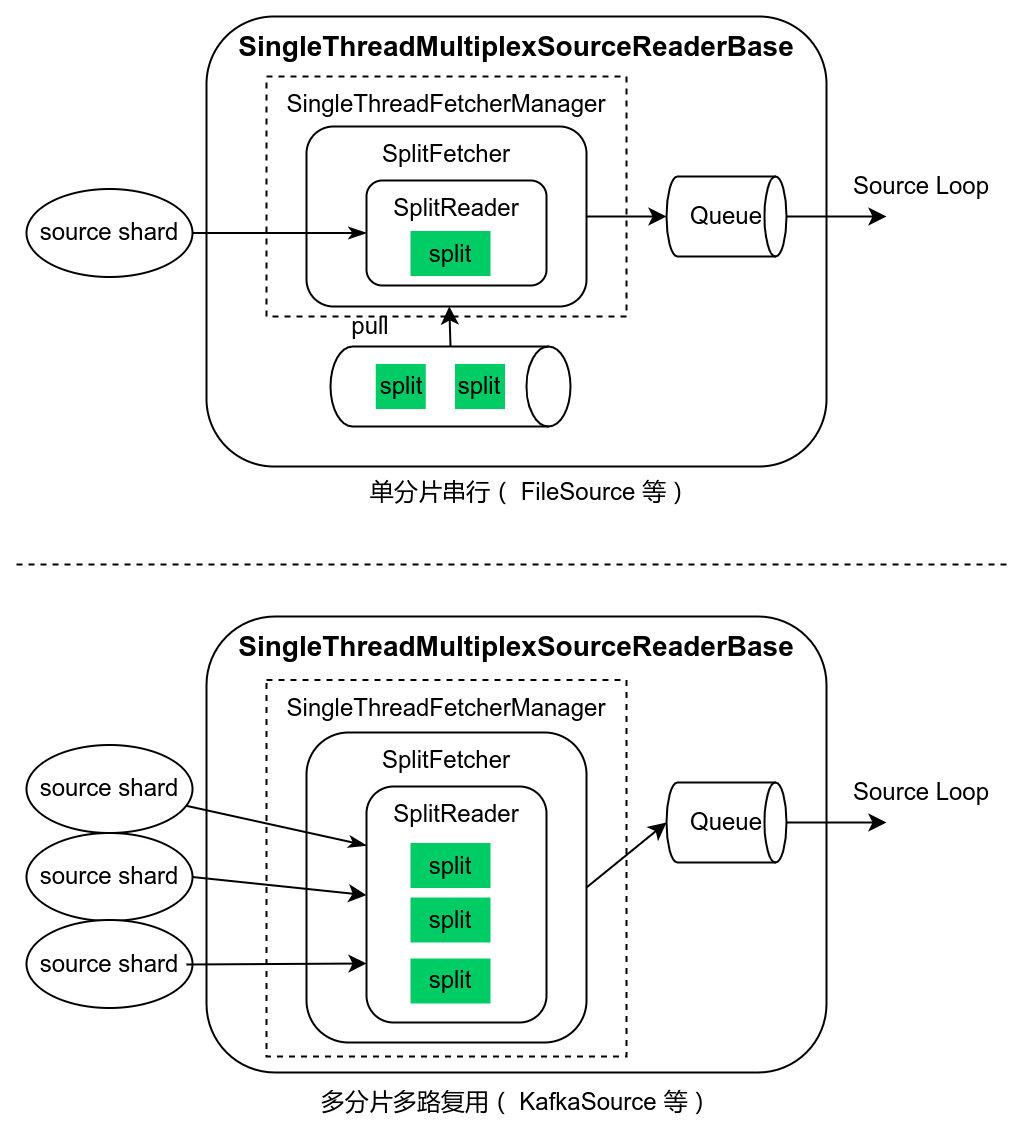
自定义SourceReader时如果继承自SingleThreadMultiplexSourceReaderBase,则主要实现SplitReader逻辑,关注如何根据split信息从数据源获取记录。
Flink CDC中各种数据源SourceReader的实现就是继承自SingleThreadMultiplexSourceReaderBase。
Ref:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface