神经网络 - 卷积神经网络
01 生物视觉与感受野
生物视觉
枕叶包含初级视觉皮层(V1区),位于新皮质的最后端,更高层级的视觉区域从这里向前延伸。显然,其主要功能是视觉处理。
感受野
20世纪60年代,1981年诺贝尔生理学或医学奖得主休贝尔(Hubel)和威塞尔(Wiesel)在研究猫视觉皮层电生理学时,提出了"感受野"的概念。
他们使用视觉处理机制与人类相似的猫作为实验对象,将电极插入猫大脑后部控制视觉的初级视觉皮层,观察哪些刺激会引发视觉皮层的强烈反应。研究发现,视觉处理基于边缘、光线朝向、特定方向的运动等简单结构,大脑会沿着视觉处理的方向,将这些简单视觉信息整合为复杂的视觉信息。
机器如何"读取"图像?
以存储和读取一张写有数字"4"的图像为例:
图像的像素值以特定顺序排列,若使用全连接网络识别图像,需将图像平整化为数组,把像素值作为预测特征。但这种方式难以让网络理解图像中的秩序和模式。
示例1:单权重与像素值相乘
通过单个权重与原始像素值相乘,尝试提取图像特征,保留图像的空间排列信息,让肉眼更容易识别出数字"4"。
示例2:双权重与像素值相乘
每次选取两个像素值而非一个,结合两个权重进行计算。这种方式能让网络捕捉相邻像素的特征,但可能导致图像右侧部分因权重值较低而信息丢失,清晰度下降。
示例3:权重移动时两侧补零
针对图像边角像素仅被权重扫描一次的问题,在权重移动路径的两侧补零。这样能保留边角信息,同时避免图像缩小。
示例4:多权重组合
为解决边角权重值较小导致像素值降低、识别困难的问题,采用多个权重组合计算。将多组权重处理后的图像整合,可获得更清晰的特征表达。
示例5:二维矩阵权重
此前的尝试主要针对水平方向的像素组合,而实际需要同时保留水平和垂直方向的空间布局。通过二维矩阵权重(卷积核)在水平和垂直方向移动,实现像素的二维组合特征提取。
滤波器的作用
权重矩阵在图像中如同提取特定信息的滤波器:
- 一组权重可用于提取边缘信息;
- 另一组可用于提取特定颜色;
- 还可用于模糊噪声。
卷积神经网络通过多个卷积层提取特征:
- 初始层通常提取边缘、纹理等通用特征;
- 网络结构越深,权重矩阵提取的特征越复杂,越贴合具体任务需求,鲁棒性也越强。
卷积操作的核心优势:
- 减少不必要的权重连接,引入稀疏连接或局部连接;
- 通过参数共享策略大幅减少参数量,相对增加有效数据量,避免过拟合;
- 具备平移不变性,使学习到的特征具有拓扑对应性和更强的鲁棒性。
02 卷积神经网络拓扑结构
卷积神经网络是一种前馈网络,能从像素图像中直接提取拓扑特征,仅需最少的预处理。它专为识别视觉模式设计,可处理手写字符等变异性极强的模式,且对输入图像的扭曲具有一定的不变性,在性能和准确率上优于多层感知器。
网络结构核心组件
- 特征提取层:包括卷积层和下采样层(池化层);
- 卷积层:通过多个滤波器进行卷积操作,每个特征图中的神经元共享权重(偏置不共享),可在图像不同位置检测相同特征,减少自由参数量;
- 下采样层(池化层):实现空间维度的聚合与缩减,降低计算量,增强特征的平移不变性,有效控制过拟合。
池化操作类型
- 最大池化(Max Pooling)
- 平均池化(Average Pooling)
- 范数池化(Norm Pooling)
- 对数概率池化(Log Probability Pooling)
全连接层
全连接层(Fully Connected Layer,简称 FC 层)是深度学习网络中的一种基础结构,其核心特点是层内每个神经元与前一层的所有神经元都存在连接,能够将前层提取的特征进行全局整合,最终输出用于分类、回归等任务的结果。
核心定义与结构
在全连接层中,假设前一层有 nnn 个神经元,当前层有 mmm 个神经元,那么会存在 n×mn \times mn×m 个可训练的权重(参数)。每个当前层神经元的输出由前层所有神经元的输出与对应权重的加权和,再经过激活函数变换得到,公式可表示为:
aj=f(∑i=1nwji⋅xi+bj)a_j = f\left( \sum_{i=1}^n w_{ji} \cdot x_i + b_j \right)aj=f(∑i=1nwji⋅xi+bj)
其中,xix_ixi 是前层第 iii 个神经元的输出,wjiw_{ji}wji 是前层第 iii 个神经元到当前层第 jjj 个神经元的权重,bjb_jbj 是当前层第 jjj 个神经元的偏置,f(⋅)f(\cdot)f(⋅) 是激活函数(如 ReLU、Sigmoid 等)。
功能与作用
- 特征整合:将卷积层、池化层等提取的局部特征(如图像的边缘、纹理、形状等)进行全局整合,转化为可直接用于分类或回归的抽象特征。例如在图像识别中,全连接层会把前层对"边缘""角点"的局部特征整合成"数字5""猫"等全局概念。
- 维度映射:实现特征维度的转换。比如前层输出是高维特征(如 1000 维),全连接层可将其映射到低维(如 10 维,对应 10 个类别),完成分类任务。
- 非线性表达:通过激活函数引入非线性,让网络能够学习复杂的非线性关系,增强模型的表达能力。
与卷积层的区别
| 维度 | 全连接层 | 卷积层 |
|---|---|---|
| 连接方式 | 全连接(每个神经元连所有) | 局部连接(仅连局部区域) |
| 参数共享 | 无参数共享 | 有参数共享(卷积核复用) |
| 空间信息保留 | 不保留(特征被展平为向量) | 保留(特征图有空间结构) |
| 典型应用 | 分类、回归的最终输出层 | 特征提取的中间层 |
举个栗子
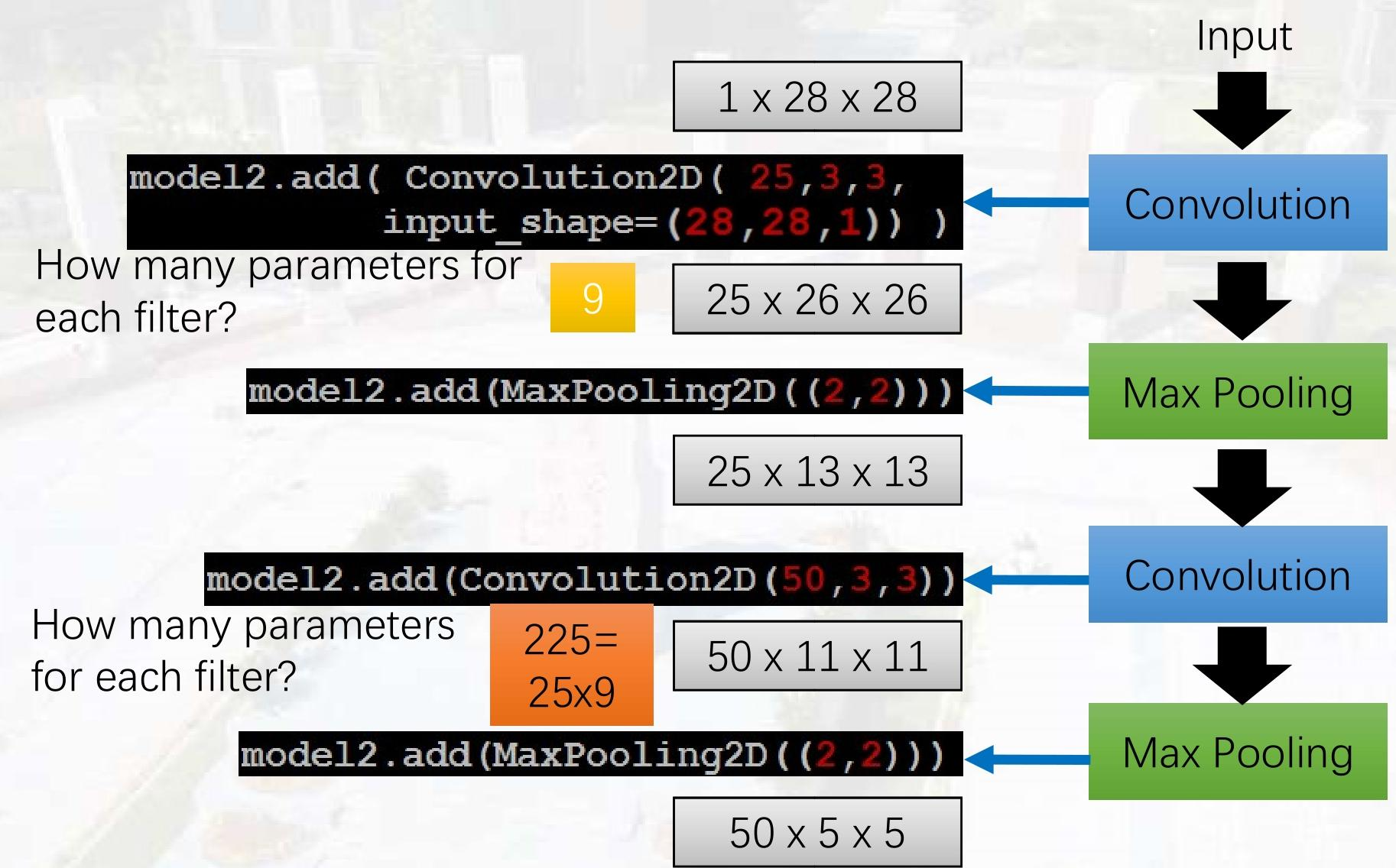
要理解图中卷积层的参数计算,需掌握卷积层参数的计算公式:
卷积层每个滤波器(filter)的参数数量 = (卷积核尺寸 × 输入通道数) + 偏置项(每个滤波器1个)
特征图尺寸公式:输出尺寸=输入尺寸−卷积核尺寸+2×填充步长+1\text{输出尺寸} = \frac{\text{输入尺寸} - \text{卷积核尺寸} + 2 \times \text{填充}}{\text{步长}} + 1输出尺寸=步长输入尺寸−卷积核尺寸+2×填充+1
一、第一个卷积层 Convolution2D(25, 3, 3, input_shape=(28,28,1))
1. 每个滤波器的参数(权重+偏置)
- 权重参数:
卷积核尺寸 × 输入通道数= 3×3×1=93 \times 3 \times 1 = 93×3×1=9 - 偏置参数:
1(每个滤波器1个偏置) - 单个滤波器总参数:9+1=109 + 1 = 109+1=10
2. 层总参数
- 滤波器数量:
25 - 层总参数:25×10=25025 \times 10 = 25025×10=250
3. 特征图尺寸计算
- 输入尺寸:
28(图像边长) - 卷积核尺寸:
3 - 填充(padding):
0(默认无填充) - 步长:
1(默认步长为1) - 输出尺寸:28−3+2×01+1=26\frac{28 - 3 + 2 \times 0}{1} + 1 = 26128−3+2×0+1=26
- 特征图维度:
25 × 26 × 26
二、第一个池化层 MaxPooling2D((2,2))
池化层无参数(仅下采样,不涉及权重学习)。
特征图尺寸计算
- 输入尺寸:
26 - 池化核尺寸:
2 - 输出尺寸:262=13\frac{26}{2} = 13226=13(下采样缩小一半)
- 特征图维度:
25 × 13 × 13
三、第二个卷积层 Convolution2D(50, 3, 3)
1. 每个滤波器的参数(权重+偏置)
- 权重参数:
卷积核尺寸 × 输入通道数= 3×3×25=2253 \times 3 \times 25 = 2253×3×25=225 - 偏置参数:
1 - 单个滤波器总参数:225+1=226225 + 1 = 226225+1=226
2. 层总参数
- 滤波器数量:
50 - 层总参数:50×226=1130050 \times 226 = 1130050×226=11300
3. 特征图尺寸计算
- 输入尺寸:
13 - 卷积核尺寸:
3 - 填充:
0 - 步长:
1 - 输出尺寸:13−3+2×01+1=11\frac{13 - 3 + 2 \times 0}{1} + 1 = 11113−3+2×0+1=11
- 特征图维度:
50 × 11 × 11
四、第二个池化层 MaxPooling2D((2,2))
池化层无参数。
特征图尺寸计算
- 输入尺寸:
11 - 池化核尺寸:
2 - 输出尺寸:112=5.5\frac{11}{2} = 5.5211=5.5?不,实际是向下取整为
5(因为池化是对整数区域操作) - 特征图维度:
50 × 5 × 5
总结表格
| 层类型 | 每个滤波器参数(权重+偏置) | 层总参数 | 特征图维度 |
|---|---|---|---|
| 第一个卷积层 | 10 | 250 | 25 × 26 × 26 |
| 第一个池化层 | 无参数 | 0 | 25 × 13 × 13 |
| 第二个卷积层 | 226 | 11300 | 50 × 11 × 11 |
| 第二个池化层 | 无参数 | 0 | 50 × 5 × 5 |
经典网络架构
LeNet-5
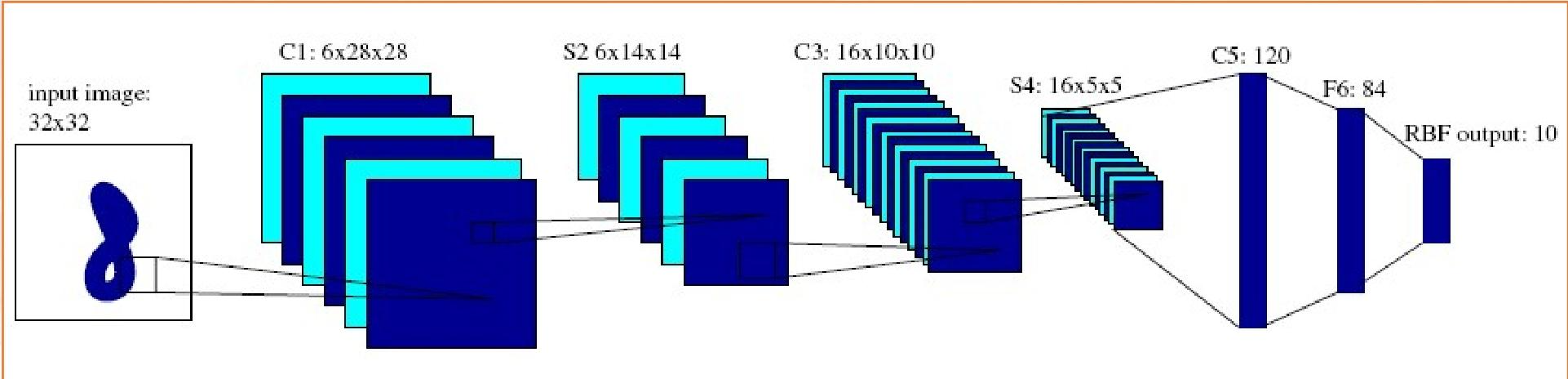
- 输入层(Input)
输入图像尺寸:32×32(经过归一化的手写数字图像,确保边缘信息不丢失)。 - C1层(第一个卷积层)
卷积核配置 :6个5×5的卷积核,步长1,无填充(no padding)。
特征图尺寸计算 :
公式:输出尺寸 = 输入尺寸 - 卷积核尺寸 + 1
即32 - 5 + 1 = 28,因此输出6×28×28的特征图(6个通道,每个通道28×28像素)。
参数计算 :
每个卷积核参数:5×5×1(输入通道数) + 1(偏置)= 26
层总参数:6×26 = 156 - S2层(第一个池化层)
池化配置 :2×2最大池化,步长2。
特征图尺寸计算 :
池化后尺寸:28 ÷ 2 = 14,因此输出6×14×14的特征图。
参数特点:池化层无学习参数(仅下采样,不涉及权重更新)。 - C3层(第二个卷积层)
卷积核配置 :16个5×5的卷积核,步长1,无填充。
特征图尺寸计算 :
公式:14 - 5 + 1 = 10,因此输出16×10×10的特征图。
参数计算 :
这里的卷积核输入通道数是6 (S2层的6个通道),因此每个卷积核参数:5×5×6 + 1 = 151
层总参数:16×151 = 2416 - S4层(第二个池化层)
池化配置 :2×2最大池化,步长2。
特征图尺寸计算 :
池化后尺寸:10 ÷ 2 = 5,因此输出16×5×5的特征图。 - C5层(第三个卷积层,实际等效全连接层)
卷积核配置 :120个5×5的卷积核,步长1,无填充。
特征图尺寸计算 :
输入尺寸是5×5,卷积核尺寸5×5,因此输出120×1×1的特征图(相当于120个神经元的向量)。
参数计算 :
每个卷积核输入通道数是16 (S4层的16个通道),因此每个卷积核参数:5×5×16 + 1 = 401
层总参数:120×401 = 48120 - F6层(全连接层)
神经元数量 :84个(设计灵感来自手写数字的7×12像素位图结构)。
参数计算 :
输入是C5层的120个神经元,因此参数数量:120×84 + 84(偏置)= 10164 - Output层(输出层,RBF激活)
神经元数量 :10个(对应数字0-9的分类)。
参数计算 :
输入是F6层的84个神经元,因此参数数量:84×10 + 10(偏置)= 850
AlexNet(2012年)
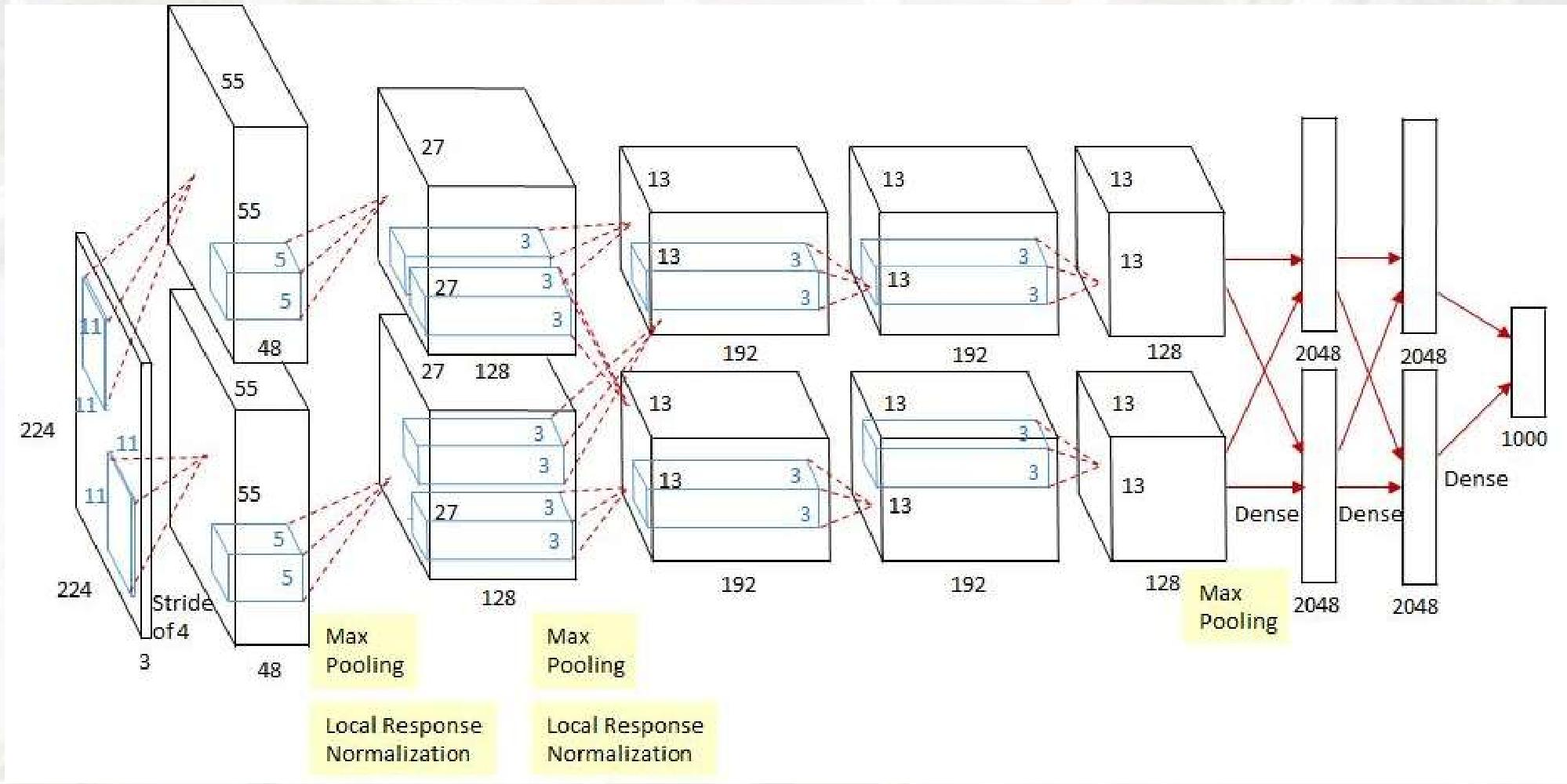
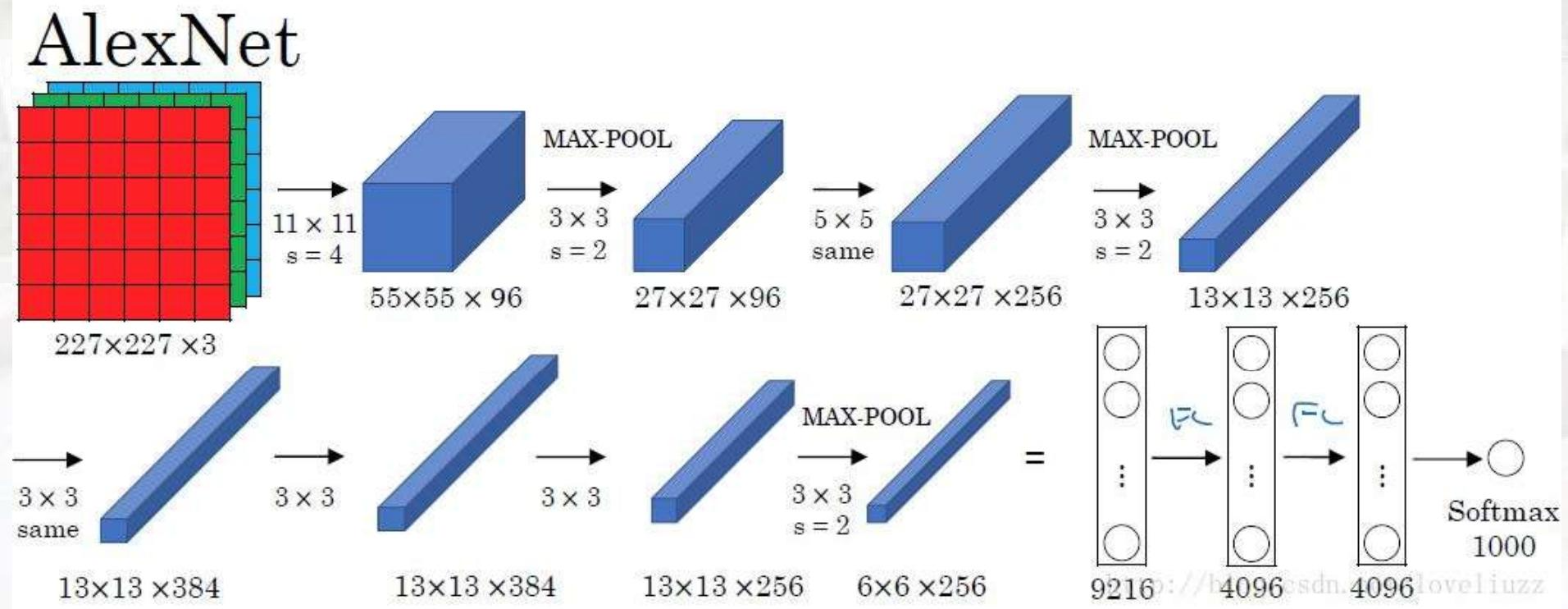
-
输入层(INPUT)
输入尺寸:
227×227×3(RGB彩色图像,3个通道,尺寸归一化后为227×227)。 -
CONV1(第一个卷积层)
卷积核配置 :96个11×11的卷积核,步长4,无填充(pad 0)。
特征图尺寸计算 :公式:
输出尺寸 = (输入尺寸 - 卷积核尺寸) ÷ 步长 + 1即
(227 - 11) ÷ 4 + 1 = 55,因此输出55×55×96的特征图(96个通道,每个通道55×55像素)。
参数计算 :每个卷积核参数:
11×11×3(输入通道数) + 1(偏置)= 364层总参数:
96×364 = 34944 -
MAX POOL1(第一个池化层)
池化配置 :3×3最大池化,步长2。
特征图尺寸计算 :池化后尺寸:
55 ÷ 2 = 27(向下取整),因此输出27×27×96的特征图。
参数特点:池化层无学习参数,仅下采样。 -
NORM1(局部响应归一化层)
作用 :对每个位置的特征图进行归一化,增强泛化能力,减少过拟合。
输出尺寸 :保持27×27×96(仅调整数值分布,不改变维度)。 -
CONV2(第二个卷积层)
卷积核配置 :256个5×5的卷积核,步长1,填充2(pad 2,保持尺寸不变)。
特征图尺寸计算 :因填充为2,输入输出尺寸相同,即
27×27×256。
参数计算 :输入通道数是96 (CONV1的96个通道),因此每个卷积核参数:
5×5×96 + 1 = 2401层总参数:
256×2401 = 614656 -
MAX POOL2(第二个池化层)
池化配置 :3×3最大池化,步长2。
特征图尺寸计算 :池化后尺寸:
27 ÷ 2 = 13(向下取整),因此输出13×13×256的特征图。 -
NORM2(局部响应归一化层)
作用 :同NORM1,对特征图数值分布归一化。
输出尺寸 :保持13×13×256。 -
CONV3(第三个卷积层)
卷积核配置 :384个3×3的卷积核,步长1,填充1(pad 1,保持尺寸不变)。
特征图尺寸计算 :因填充为1,输入输出尺寸相同,即
13×13×384。
参数计算 :输入通道数是256 (CONV2的256个通道),因此每个卷积核参数:
3×3×256 + 1 = 2305层总参数:
384×2305 = 885120 -
CONV4(第四个卷积层)
卷积核配置 :384个3×3的卷积核,步长1,填充1。
特征图尺寸计算 :保持
13×13×384(填充1,尺寸不变)。
参数计算 :输入通道数是384 (CONV3的384个通道),因此每个卷积核参数:
3×3×384 + 1 = 3457层总参数:
384×3457 = 1327488 -
CONV5(第五个卷积层)
卷积核配置 :256个3×3的卷积核,步长1,填充1。
特征图尺寸计算 :保持
13×13×256(填充1,尺寸不变)。
参数计算 :输入通道数是384 (CONV4的384个通道),因此每个卷积核参数:
3×3×384 + 1 = 3457层总参数:
256×3457 = 885092 -
MAX POOL3(第三个池化层)
池化配置 :3×3最大池化,步长2。
特征图尺寸计算 :池化后尺寸:
13 ÷ 2 = 6(向下取整),因此输出6×6×256的特征图。 -
FC6(第一个全连接层)
神经元数量 :4096个。
参数计算 :输入是
6×6×256的特征图,先扁平化为6×6×256 = 9216个神经元,因此参数数量:9216×4096 + 4096(偏置)= 37748736 -
FC7(第二个全连接层)
神经元数量 :4096个。
参数计算 :输入是FC6的4096个神经元,因此参数数量:
4096×4096 + 4096 = 16777216 -
FC8(输出层)
神经元数量 :1000个(对应ImageNet的1000类分类)。
参数计算 :输入是FC7的4096个神经元,因此参数数量:
4096×1000 + 1000 = 4097000
AlexNet的核心突破在于**"深度+工程优化"**:
- 首次使用ReLU激活函数,解决传统Sigmoid的梯度消失问题;
- 引入Dropout(全连接层随机失活),防止过拟合;
- 采用双GPU并行训练,大幅提升训练效率;
- 局部响应归一化(NORM层)增强特征鲁棒性。
VGGNet(2014年)
- 核心特点:采用小尺寸(3×3)卷积核和更深的网络结构(16-19层),使用步长为1的卷积和步长为2的2×2最大池化;
- 性能:在ILSVRC'14中达到7.3%的top-5错误率;
- 参数量:约1.38亿,内存占用和计算量较大。

GoogLeNet(2014年)
- 核心特点:22层网络,引入"Inception模块",无全连接层,仅500万参数量(为AlexNet的1/12);
- Inception模块:通过1×1、3×3、5×5卷积核和平行池化操作,将输出在通道维度级联,提取多尺度特征;
- 性能:ILSVRC'14分类冠军,top-5错误率6.7%。
ResNet(2015年)
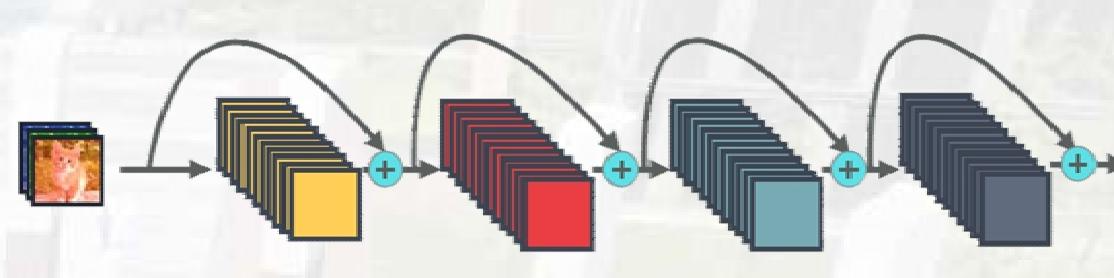
ResNet(残差网络)是卷积神经网络领域的里程碑模型,其核心创新是残差结构(residual structure) ,解决了深层网络的梯度消失和退化问题。下面结合你提供的三张图,从残差结构原理到ResNet34的网络设计逐一解析。
残差结构的本质是引入"捷径连接(shortcut connection)",让网络在学习"残差映射"的同时,保留原始输入的信息传递路径。
传统卷积网络在层数超过一定阈值后,会出现准确率饱和甚至下降的 "退化现象"。残差块通过 "捷径连接(Shortcut)" 让梯度直接回传 ,同时让网络学习 "残差映射"(即输出 = 输入 + 残差),从而突破了深度限制。
残差块的类型差异,本质是 "深度需求" 与 "计算效率" 的权衡 ------ 不同任务(轻量 / 高性能)、不同硬件(移动端 / 服务器)需要不同结构的残差块。
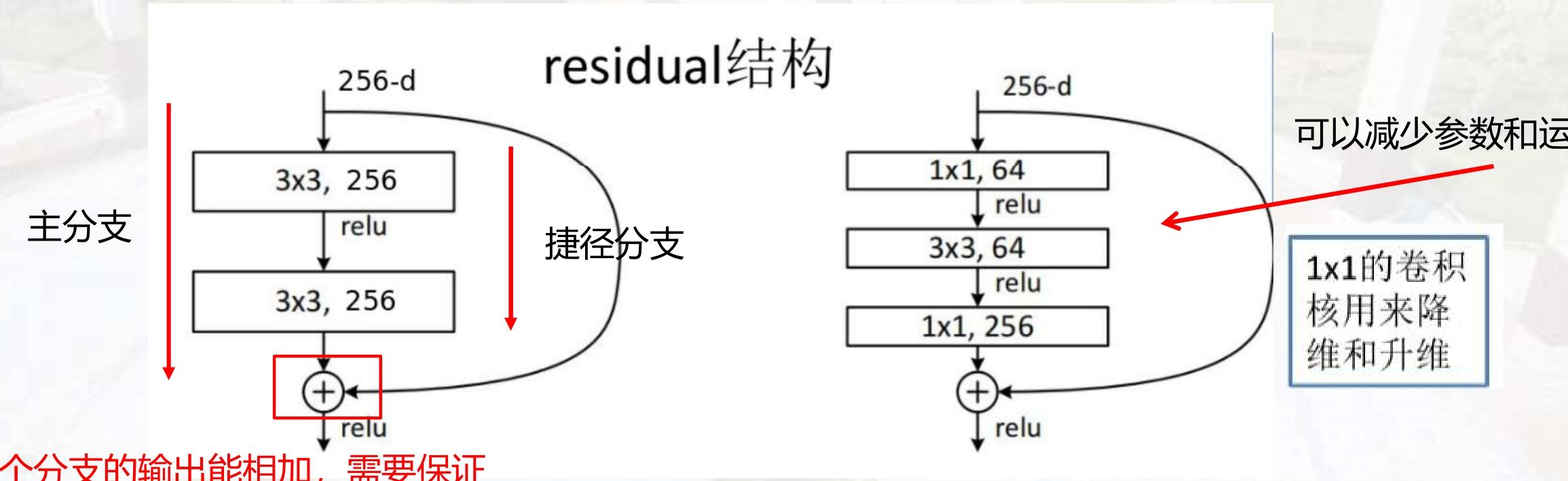
- 基础残差结构
- 主分支:由多个卷积层组成(如两个3×3卷积),负责学习输入与输出之间的"残差"。
- 捷径分支:直接将输入跳过主分支的卷积层,与主分支的输出相加。
- 数学表达 :设输入为xxx,主分支的映射为F(x)F(x)F(x),则残差结构的输出为H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x。
- 关键要求 :主分支和捷径分支的输出尺寸(高、宽、通道数)必须完全一致 ,才能进行元素级相加。
这种结构的优势在于:
- 梯度可以通过捷径分支直接反向传播,缓解了深层网络的梯度消失问题。
- 网络可以"自由选择"学习残差还是直接传递输入,降低了训练难度。
为了进一步减少参数和计算量,ResNet 引入了 **"瓶颈结构(Bottleneck)"**主要用于更深的网络(如 ResNet50、101 等)。
结构流程:1×1卷积(降维)→ 3×3卷积(特征提取)→ 1×1卷积(升维)
1×1 卷积的作用:
降维:将输入通道数从 256 压缩到 64,减少后续 3×3 卷积的计算量。
升维:将 64 通道再扩展回 256 通道,保证与捷径分支的通道数一致。
计算量对比:
无瓶颈结构:(3×3×256×256×2 = 1179648)
有瓶颈结构:(1×1×256×64 + 3×3×64×64 + 1×1×64×256 = 69632)(仅为前者的 6%)
ResNet34 深度解析:结构、原理与应用
ResNet34是残差网络(Residual Network)的经典变体之一,以34层的深度和高效的残差结构设计,在图像分类、目标检测等任务中表现出色。
一、ResNet34的核心结构
-
- 网络总览
- 总层数:34层(含卷积层、池化层和全连接层)
- 残差模块类型 :采用基础残差块(Basic Block)(即两个3×3卷积的串联设计)
- 模块堆叠数:(3, 4, 6, 3),即四个阶段分别包含3、4、6、3个残差块
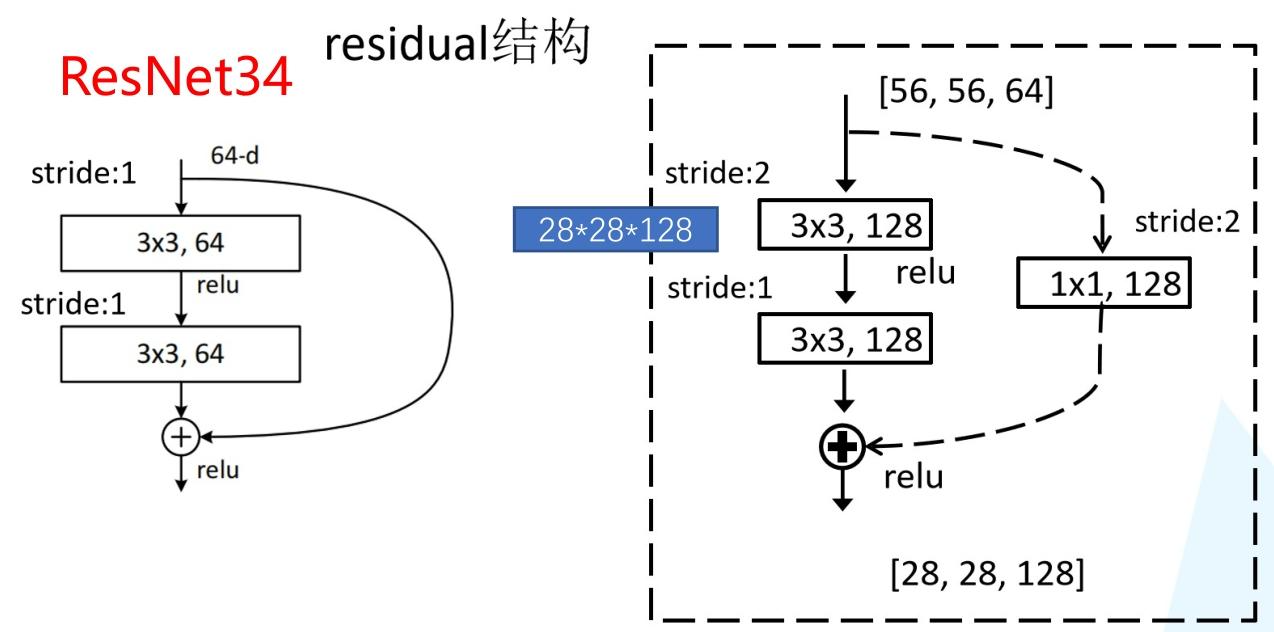
2. 基础残差块(Basic Block)详解
基础残差块是ResNet34的核心单元,结构如下:
- 主分支:两个3×3卷积层(均带ReLU激活),负责学习输入与输出的"残差"。
- 捷径分支 :直接将输入跳过主分支的卷积层,与主分支的输出进行元素级相加。
- 维度匹配:当残差块需要改变空间尺寸或通道数时,捷径分支会引入1×1卷积(步长为2)来保证维度一致。
数学表达:设输入为xxx,主分支的映射为F(x)F(x)F(x),则残差块的输出为H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x(或H(x)=F(x)+WsxH(x) = F(x) + W_s xH(x)=F(x)+Wsx,其中WsW_sWs是用于维度匹配的卷积权重)。
3. 网络阶段划分(以输入224×224×3为例)
| 阶段 | 残差块数量 | 输入尺寸 | 输出通道数 | 残差块内卷积配置 |
|---|---|---|---|---|
| 初始阶段 | - | 224×224×3 | 64 | 7×7卷积(步长2)+ 3×3最大池化(步长2) |
| 阶段1 | 3 | 56×56×64 | 64 | 每个块:3×3(64)→ReLU→3×3(64)→ReLU |
| 阶段2 | 4 | 56×56×64 | 128 | 第一个块步长2(尺寸减半),后续步长1;卷积配置:3×3(128)→ReLU→3×3(128)→ReLU |
| 阶段3 | 6 | 28×28×128 | 256 | 第一个块步长2(尺寸减半),后续步长1;卷积配置:3×3(256)→ReLU→3×3(256)→ReLU |
| 阶段4 | 3 | 14×14×256 | 512 | 第一个块步长2(尺寸减半),后续步长1;卷积配置:3×3(512)→ReLU→3×3(512)→ReLU |
| 输出阶段 | - | 7×7×512 | 1000 | 全局平均池化 + 全连接层(分类1000类) |
参数量与计算量
- 参数量:约21.8M(百万),仅为VGG16的1/6,但深度是其2倍以上。
- 浮点运算量(FLOPs):约3.6 GFLOPs(输入224×224时),在同类网络中属于轻量高效的模型。
核心优势
- 解决深层退化问题:传统CNN在层数超过一定阈值后,准确率会饱和甚至下降,而ResNet34通过残差连接打破了这一限制,34层的深度仍能稳定训练。
- 梯度传播高效:捷径连接让梯度直接回传,避免了梯度消失,使深层网络的训练成为可能。
- 特征表达能力均衡:相比更深的ResNet(如ResNet101),ResNet34的特征更偏向"平衡型",在中小规模数据集上泛化性更优。
ResNet101 深度解析:结构、特性与应用
ResNet101是残差网络家族中的深层模型,在ResNet34的基础上进一步提升了深度和特征表达能力,尤其适合复杂计算机视觉任务。以下从结构、特性和应用三个维度详细讲解:
一、ResNet101的核心结构
1. 网络总览
- 总层数:101层(含卷积层、池化层和全连接层)
- 残差模块类型 :采用Bottleneck(瓶颈结构)(即1×1卷积→3×3卷积→1×1卷积的三段式设计)
- 模块堆叠数:(3, 4, 23, 3),即四个阶段分别包含3、4、23、3个残差块
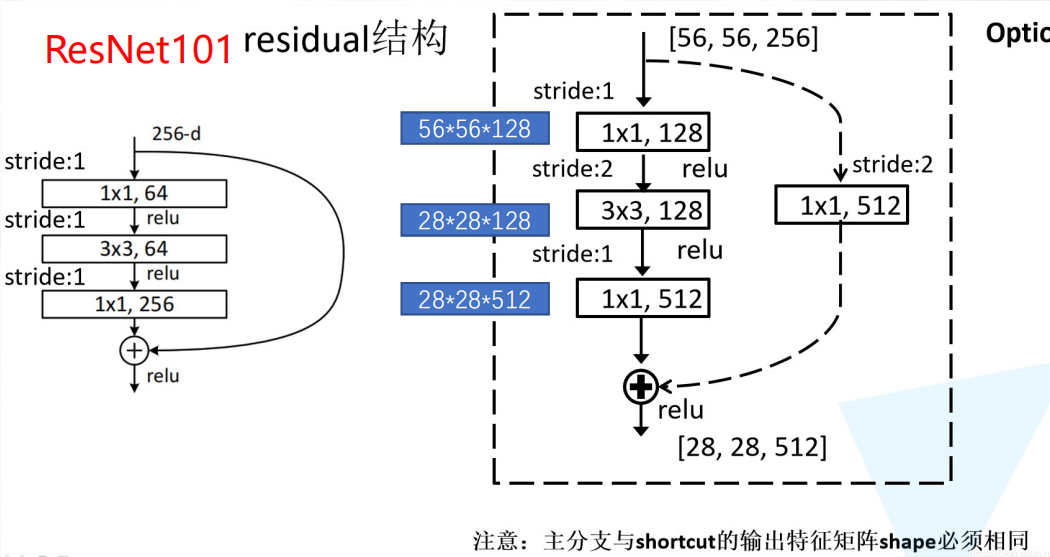
2. 瓶颈结构(Bottleneck)详解
相比ResNet34的"双3×3卷积"基础残差块,ResNet101的瓶颈结构通过1×1卷积的降维与升维大幅减少计算量,具体流程:
- 1×1卷积(降维):将输入通道数压缩(如256→64),减少后续3×3卷积的计算负担。
- 3×3卷积(特征提取):在低通道数下进行核心特征提取。
- 1×1卷积(升维):将通道数恢复(如64→256),保证与捷径分支的维度一致。
这种设计使ResNet101在参数量增加有限的情况下,实现了网络深度的大幅提升。
3. 网络阶段划分(以输入224×224×3为例)
| 阶段 | 残差块数量 | 输入尺寸 | 输出通道数 | 残差块内卷积配置 |
|---|---|---|---|---|
| 初始阶段 | - | 224×224×3 | 64 | 7×7卷积(步长2)+ 3×3最大池化(步长2) |
| 阶段1 | 3 | 56×56×64 | 256 | 每个块:1×1(64)→3×3(64)→1×1(256) |
| 阶段2 | 4 | 56×56×256 | 512 | 第一个块步长2(尺寸减半),后续步长1;卷积配置:1×1(128)→3×3(128)→1×1(512) |
| 阶段3 | 23 | 28×28×512 | 1024 | 第一个块步长2(尺寸减半),后续步长1;卷积配置:1×1(256)→3×3(256)→1×1(1024) |
| 阶段4 | 3 | 14×14×1024 | 2048 | 第一个块步长2(尺寸减半),后续步长1;卷积配置:1×1(512)→3×3(512)→1×1(2048) |
| 输出阶段 | - | 7×7×2048 | 1000 | 全局平均池化 + 全连接层(分类1000类) |
- 参数量与计算量
- 参数量:约44.5M(百万),仅为VGG16的1/3,但深度是其3倍以上。
- 浮点运算量(FLOPs):约7.6 GFLOPs(输入224×224时),在深层网络中属于效率较优的模型。
- 核心优势
- 解决深层退化问题:通过残差连接,即使101层的深度也能稳定训练,不会出现准确率饱和或下降。
- 特征表达能力强:深层结构使其能捕捉更复杂的语义特征,在目标检测、语义分割等任务中表现突出。
- 迁移性好:预训练模型在ImageNet上的Top-1准确率约77%,可作为下游任务的骨干网络。
3. 与其他ResNet版本对比
| 模型 | 层数 | 残差块类型 | 参数量(M) | 适用场景 |
|---|---|---|---|---|
| ResNet34 | 34 | 基础块 | 21.8 | 中等复杂度图像分类 |
| ResNet50 | 50 | 瓶颈块 | 25.6 | 通用图像分类 |
| ResNet101 | 101 | 瓶颈块 | 44.5 | 复杂任务(目标检测、语义分割) |
| ResNet152 | 152 | 瓶颈块 | 60.2 | 高性能计算场景(充足算力) |
DenseNet
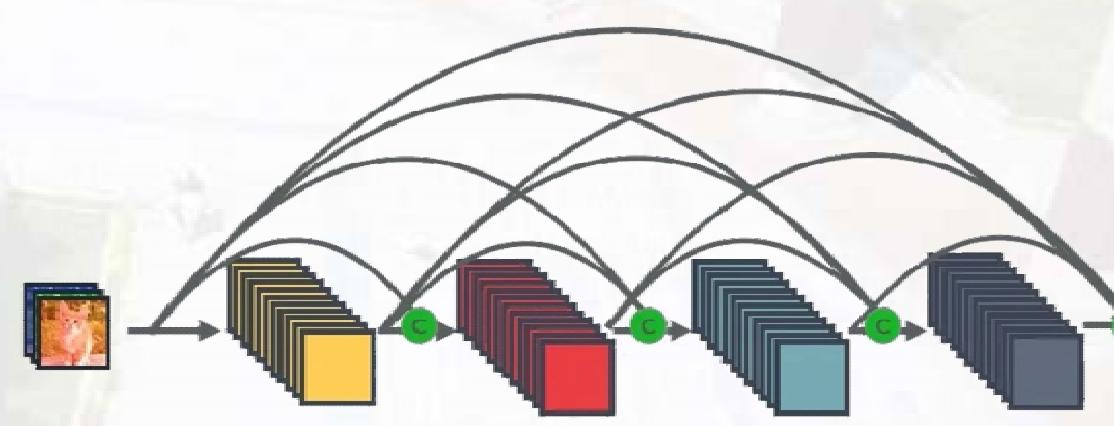
- 核心机制:密集连接,每层与前面所有层在通道维度连接,实现特征重用;
- 网络组件:Dense Block(密集块)+ Transition Layer(过渡层),过渡层通过1×1卷积和平均池化降低特征图尺寸,可设置压缩系数;
- 优势:梯度流动更强,参数量更少,能利用多尺度特征,数据不足时表现稳定;
- 不足:多次拼接操作导致显存占用较高,通用性不如ResNet。
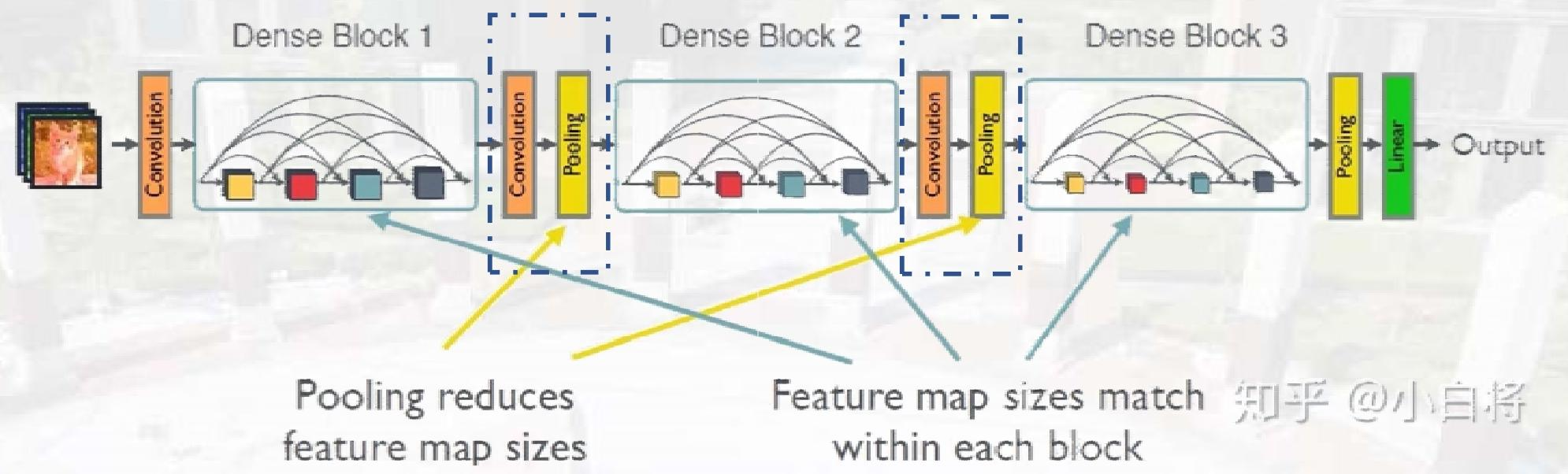
Dense Block是包含很多层的模块,每个层的特征图大小相同 每个层的特征图大小相同,层与层之间采用密集连接方式。
Transition模块是连接两个相邻的DenseBlock,并且通过 并且通过Pooling使特征图大小降低。
三种模块在DenseNet中的具体区别
| 模块结构 | 在DenseNet中的角色 | 核心作用(结合密集连接) | 典型位置 |
|---|---|---|---|
| BN+ReLU+3x3 Conv | 基础特征转换单元 | 对拼接后的高通道特征进行局部特征提取,维持通道数稳定(输出通道数=增长率( k )) | 每个Dense Block内部的核心计算层 |
| BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv | 瓶颈层(Bottleneck) | 通过1x1 Conv先压缩拼接后的高通道特征,降低3x3 Conv的计算量,再输出低通道特征(( k )) | 多数Dense Block中(为减少计算,默认带瓶颈层) |
| BN+ReLU+1x1 Conv+2x2 AvgPooling | 过渡层(Transition Layer) | 连接两个Dense Block,通过1x1 Conv压缩通道数,2x2 AvgPooling下采样减少空间维度,控制网络规模 | Dense Block之间的连接层 |
为什么有效:
- 强大的梯度流:梯度可以直接流向更早的层。
- 保存了低维度的特征:解释了为什么训练数据不足时DenseNet表现依旧良好。
- 减少了参数数量
03 局部连接
全连接网络存在大量冗余连接,而图像中的许多模式远小于整体图像,可通过局部连接减少参数量:
- 每个神经元仅连接输入图像的局部区域,用较少参数表示小范围特征(如"鸟喙检测器");
- 相同模式可能出现在图像不同位置,可通过"移动"检测器并共享参数,压缩网络规模。
卷积操作示例
以6×6图像和3×3滤波器为例,步长(stride)为1:
- 滤波器在图像上滑动,每次与局部区域计算点积;
- 每个滤波器检测一种小模式,多个滤波器输出多张特征图(如2个滤波器输出2张4×4特征图,形成2×4×4矩阵)。
彩色图像卷积
RGB彩色图像含3个通道,卷积时需使用3维滤波器(如3×3×3),每个通道对应一个2维卷积核,最终输出单通道特征图。
特征图尺寸计算
featuremap_size=image_size−kernel_size+2×padsizestride+1\text{featuremap\_size} = \frac{\text{image\_size} - \text{kernel\_size} + 2 \times \text{padsize}}{\text{stride}} + 1featuremap_size=strideimage_size−kernel_size+2×padsize+1
04 参数共享
在卷积层中,所有神经元共享同一组权重(滤波器参数):
- 无需为每个位置的检测器单独训练参数,大幅减少自由参数量;
- 确保在图像不同位置检测相同特征,实现平移不变性。
与全连接网络的对比
- 全连接网络:6×6图像需连接36个输入,参数量大;
- 局部连接+参数共享:仅需9个参数(3×3滤波器),参数量显著减少,且保持特征检测能力。
卷积神经网络整体流程
- 输入层:接收图像数据(如28×28×1的黑白图像或227×227×3的彩色图像);
- 卷积层:通过多个滤波器提取局部特征,输出特征图;
- 池化层:对特征图下采样,降低维度,保留关键信息;
- 重复卷积-池化操作:深层网络可多次堆叠,逐步提取复杂特征;
- 平整化(Flatten):将多维特征图转换为一维向量;
- 全连接层:接收一维向量,进行分类计算;
- 输出层:输出分类结果(如数字识别的0-9概率分布)。
模型性能对比
- 参数量:AlexNet(65M)→ VGG-16(138M)→ ResNet-50(25M)→ DenseNet-121(8M);
- 计算量:VGG系列最大,ResNet和DenseNet效率更高;
- 准确率:深层网络(ResNet-152、DenseNet-264)优于浅层网络,Inception-v4结合ResNet和Inception优势,性能领先。