目录
[二、核函数(Kernel Function):并行计算的执行单元](#二、核函数(Kernel Function):并行计算的执行单元)
[2.1 核函数的定义与限定符](#2.1 核函数的定义与限定符)
[2.2 核函数的执行配置:网格(Grid)与块(Block)模型](#2.2 核函数的执行配置:网格(Grid)与块(Block)模型)
[3. 任务并行的核心引擎:Tiling 数据分割与实例索引](#3. 任务并行的核心引擎:Tiling 数据分割与实例索引)
[3.1 Host 侧:Tiling 策略的制定者("算子工程------Host侧实现Tiling函数实现")](#3.1 Host 侧:Tiling 策略的制定者(“算子工程——Host侧实现Tiling函数实现”))
[3.2 Kernel 侧:Tiling 信息的消费者("算子工程------Kernel侧使用Tiling信息")](#3.2 Kernel 侧:Tiling 信息的消费者(“算子工程——Kernel侧使用Tiling信息”))
[4.1 内存层次结构](#4.1 内存层次结构)
[4.2 计算流水线优化示意图](#4.2 计算流水线优化示意图)
摘要
本文基于"昇腾 CANN 训练营"核心素材,深度揭秘 Ascend C 的编程模型。我们将系统解析核函数(Kernel Function) 的运作机制、任务并行(Task Parallelism) 的实现原理,并重点剖析素材中反复强调的 **"算子工程"**在 Host 侧与 Kernel 侧的具体实现。通过引入多级自定义流程图、技术架构图、代码实战对比以及交互式思考块,本文旨在为您构建一个从理论到实践的完整知识体系,彻底掌握 Ascend C 的高性能编程精髓。
一、背景介绍:从串行思维到并行范式的范式转移
在传统 CPU 编程中,我们常常习惯于串行或简单的多线程编程模型。然而,这种模型在面对 AI 计算中大规模、规则的数据并行任务时,往往会遇到瓶颈。昇腾(Ascend)AI 处理器 作为一种大规模并行处理器(MPP, Massively Parallel Processor) ,其设计初衷就是高效处理海量数据的并行计算。Ascend C 编程模型的精髓,就在于它提供了一套抽象的机制,让开发者能够以 **"单程序多数据(SPMD, Single Program Multiple Data)"**的思维来组织计算。
简单来说,就是编写一份核函数代码,然后让成千上万个计算实例同时执行这份代码,每个实例处理不同的数据块。理解并掌握这一模型,是从"能写算子"到"能写好算子"的关键一步。素材中反复强调的 "算子工程------Host侧实现Tiling函数实现" 和 "算子工程------Kernel侧使用Tiling信息",正是这一并行模型在代码层面的具体体现,也是本文将要深入解析的核心。
🚀 本文与训练营素材的对应关系
本文将直接对应并深度扩展素材中的以下关键点:
两种算子开发流程的底层原理
算子工程中 Host 与 Kernel 的协同分工
Tiling 技术作为并行计算桥梁的核心作用
从代码层面理解 核函数的并行机制
二、核函数(Kernel Function):并行计算的执行单元
核函数是 Ascend C 代码的灵魂,它是在**设备(Device)**上执行的入口函数。其概念类似于 CUDA 中的 Kernel,但深度集成和优化了昇腾硬件的特性。
2.1 核函数的定义与限定符
核函数通过特定的限定符来标识,这在素材的代码示例中有所体现。
cpp
// 核函数定义示例:一个简单的向量加法核函数
extern "C" __global__ __aicore__ void vector_add_kernel(
const float* a,
const float* b,
float* c,
int totalElements) {
// 核函数体:并行计算逻辑
}-
extern "C": 确保函数名在编译后不被 C++ 编译器进行名称修饰(Name Mangling),以便主机侧能够正确找到并调用它。 -
__global__: 标识该函数是一个全局函数(Global Function),既可以被主机侧调用,也可以在设备侧执行。 -
__aicore__: Ascend C 特有的限定符,明确指示该函数用于在 AI Core 上执行。
2.2 核函数的执行配置:网格(Grid)与块(Block)模型
当主机侧调用核函数时,必须指定其执行配置,即定义如何并行。这通过 **"网格-块"模型(Grid-Block Model)**来实现,该模型是理解任务并行的关键。下图清晰地展示了从 Host 调用到多个 Kernel 实例在 AI Core 上并行执行的全过程:

-
网格(Grid): 一个核函数启动的所有并行实例的集合,可以看作一个一维、二维或三维的任务阵列。在素材所示的向量算子中,通常使用一维网格。
-
块(Block): 网格中的基本调度单位。在 Ascend C 中,一个 Block 通常对应一个数据分块(Tile),并由一个 Kernel 实例处理。
主机侧启动核函数的伪代码示例:
cpp
// 假设我们有 totalLength 个数据元素, 每个Block处理 blockLength 个元素。
uint32_t blockNum = (totalLength + blockLength - 1) / blockLength; // 计算需要的Block数量, 即Grid大小
// 调用运行时API启动核函数
rtError_t launchResult = rtKernelLaunch(
vector_add_kernel, // 核函数指针
blockNum, // 网格大小(Grid Dimension): 启动的Block数量
nullptr, // 参数列表(现代用法常通过结构体指针传递)
argsSize, // 参数大小
nullptr, // 流(Stream, 用于异步执行)
deviceTiling); // Tiling参数结构体指针(在设备内存中)启动后,AI Core 上将并行执行 blockNum个核函数实例。每个实例都可以通过内置函数获取自己的唯一标识符,从而知道自己该处理哪部分数据。这种机制是实现 **数据并行(Data Parallelism)**的基石。
💡 核心概念:什么是"任务并行"?
在 Ascend C 的上下文中,任务并行主要指数据并行。即,将一个大任务(处理一个大张量)分解成许多个相同的子任务(处理多个数据分块),然后将这些子任务映射到大量的处理单元(AI Core)上同时执行。这与包含不同任务的"任务并行"(Task Parallelism)有所区别。
3. 任务并行的核心引擎:Tiling 数据分割与实例索引
素材中将 "算子工程------Host侧实现Tiling函数实现" 和 **"算子工程------Kernel侧使用Tiling信息"**作为独立且关键的环节,这凸显了 Tiling 是实现任务并行的桥梁。下面我们通过一个详细的序列图来展示 Host 与 Device 如何围绕 Tiling 进行协作:
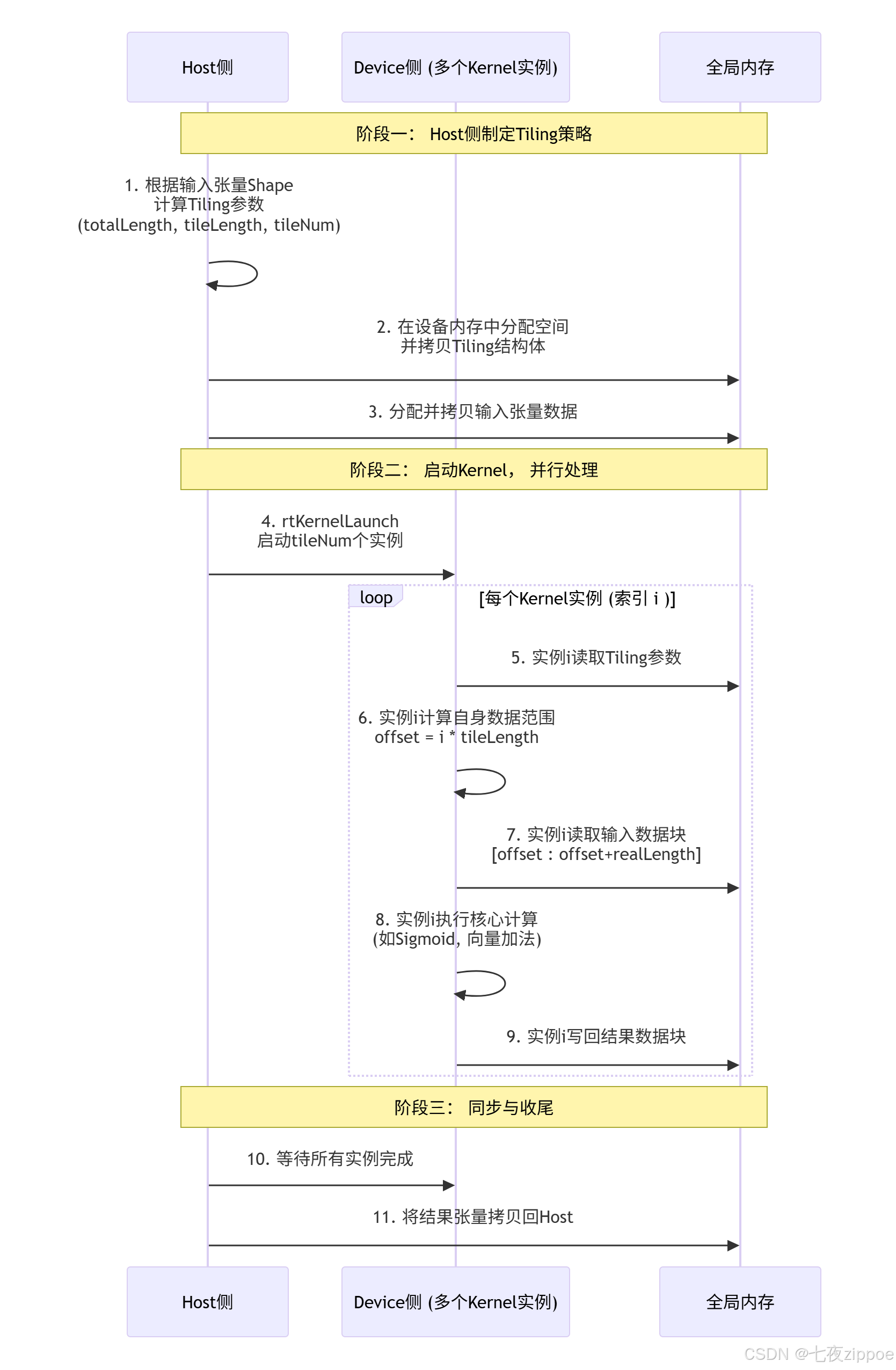
3.1 Host 侧:Tiling 策略的制定者("算子工程------Host侧实现Tiling函数实现")
如素材所示,Host 侧的职责是根据全局数据信息,制定并传递 Tiling 策略。
cpp
// Tiling参数结构体定义 (必须在Host和Kernel侧保持二进制兼容)
typedef struct {
uint32_t totalLength; // 数据的总长度(以元素个数为单位)
uint32_t tileLength; // 每个分块(Tile)的标准长度
uint32_t tileNum; // 总的分块数量
uint32_t lastTileLength;// 最后一个分块的实际长度(用于处理非对齐情况)
} VectorAddTiling;
// Host侧Tiling策略实现函数 (对应素材中的"Host侧实现Tiling函数实现")
VectorAddTiling* CalcTilingStrategy(uint32_t totalElements, uint32_t preferredTileSize) {
VectorAddTiling* tiling = (VectorAddTiling*)malloc(sizeof(VectorAddTiling));
if (tiling == nullptr) {
// 错误处理...
return nullptr;
}
tiling->totalLength = totalElements;
tiling->tileLength = preferredTileSize; // 此值需根据UB大小精心设计
tiling->tileNum = (totalElements + preferredTileSize - 1) / preferredTileSize; // 向上取整
tiling->lastTileLength = totalElements - (tiling->tileNum - 1) * preferredTileSize;
// 将Tiling结构体拷贝到Device内存, 供所有Kernel实例读取
// aclrtMemcpy(deviceTilingPtr, ..., tiling, sizeof(VectorAddTiling), ...);
return tiling;
}逻辑解析 :Host 侧如同总指挥,它知晓全局数据(totalLength),并制定分块规则(tileLength),从而决定了需要投入多少兵力(tileNum)。lastTileLength确保了在数据总量不是分块大小整数倍时的正确性。
3.2 Kernel 侧:Tiling 信息的消费者("算子工程------Kernel侧使用Tiling信息")
每个核函数实例在设备侧需要知道自己具体负责哪个数据块。这是通过查询自己的**块索引(Block Index)**并结合 Host 传来的 Tiling 信息实现的。
cpp
// Kernel侧使用Tiling信息示例 (对应素材中的"Kernel侧使用Tiling信息")
extern "C" __global__ __aicore__ void vector_add_kernel(
VectorAddTiling* tiling,
const float* a,
const float* b,
float* c) {
// 1. 获取当前Kernel实例的块索引(从0开始)
uint32_t blockIdx = GetBlockIdx();
// 2. 安全检查:索引是否有效
if (blockIdx >= tiling->tileNum) {
return;
}
// 3. 计算本实例负责的数据在全局内存中的偏移量
uint32_t dataOffset = blockIdx * tiling->tileLength;
// 4. 计算本实例实际要处理的数据长度(处理最后一个块可能不满的情况)
uint32_t realLength = (blockIdx == (tiling->tileNum - 1)) ?
tiling->lastTileLength :
tiling->tileLength;
// 5. 基于 dataOffset 和 realLength 进行后续的数据加载和计算
// 例如: for (int i = 0; i < realLength; ++i) { c[dataOffset+i] = a[dataOffset+i] + b[dataOffset+i]; }
}逻辑解析 :每个 Kernel 实例如同一个士兵,它通过 GetBlockIdx()知道自己的编号(blockIdx),再结合总指挥下发的作战计划(tiling),就能精确计算出自己应该从哪个位置(dataOffset)开始,处理多长的战线(realLength)。所有士兵(Kernel 实例)同时行动,共同完成整个战役(计算任务)。
四、超越基础并行:内存层次结构与计算流水线优化
高效的并行计算不仅依赖于任务划分,还依赖于对内存层次结构的深刻理解和利用。Ascend C 编程模型提供了清晰的内存层次结构,为实现极致性能提供了可能。
4.1 内存层次结构
-
全局内存(Global Memory): 设备上的主内存(通常位于板载 DDR),容量大但访问延迟高。输入/输出张量通常驻留于此。所有 Kernel 实例都可以访问。
-
统一缓冲区(UB, Unified Buffer): 每个 AI Core 上的高速缓存,容量有限(例如 1MB)但访问速度极快。用于暂存从全局内存加载的数据块,以供计算单元快速访问。
典型的计算流程是:
-
Kernel 实例通过 **直接内存访问(DMA, Direct Memory Access)**将全局内存中自己负责的数据块搬运到 UB。
-
计算单元从 UB 中读取数据进行计算。
-
将计算结果从 UB 写回全局内存。
这种"全局内存->UB->计算->全局内存"的操作是性能优化的基础。但更高级的优化是让第1步和第2步重叠执行,即流水线(Pipeline)优化。
4.2 计算流水线优化示意图
下图展示了一个理想的双缓冲(Double Buffering)流水线,它允许数据搬运和计算完全重叠,从而几乎完全隐藏了 DMA 搬运的延迟。
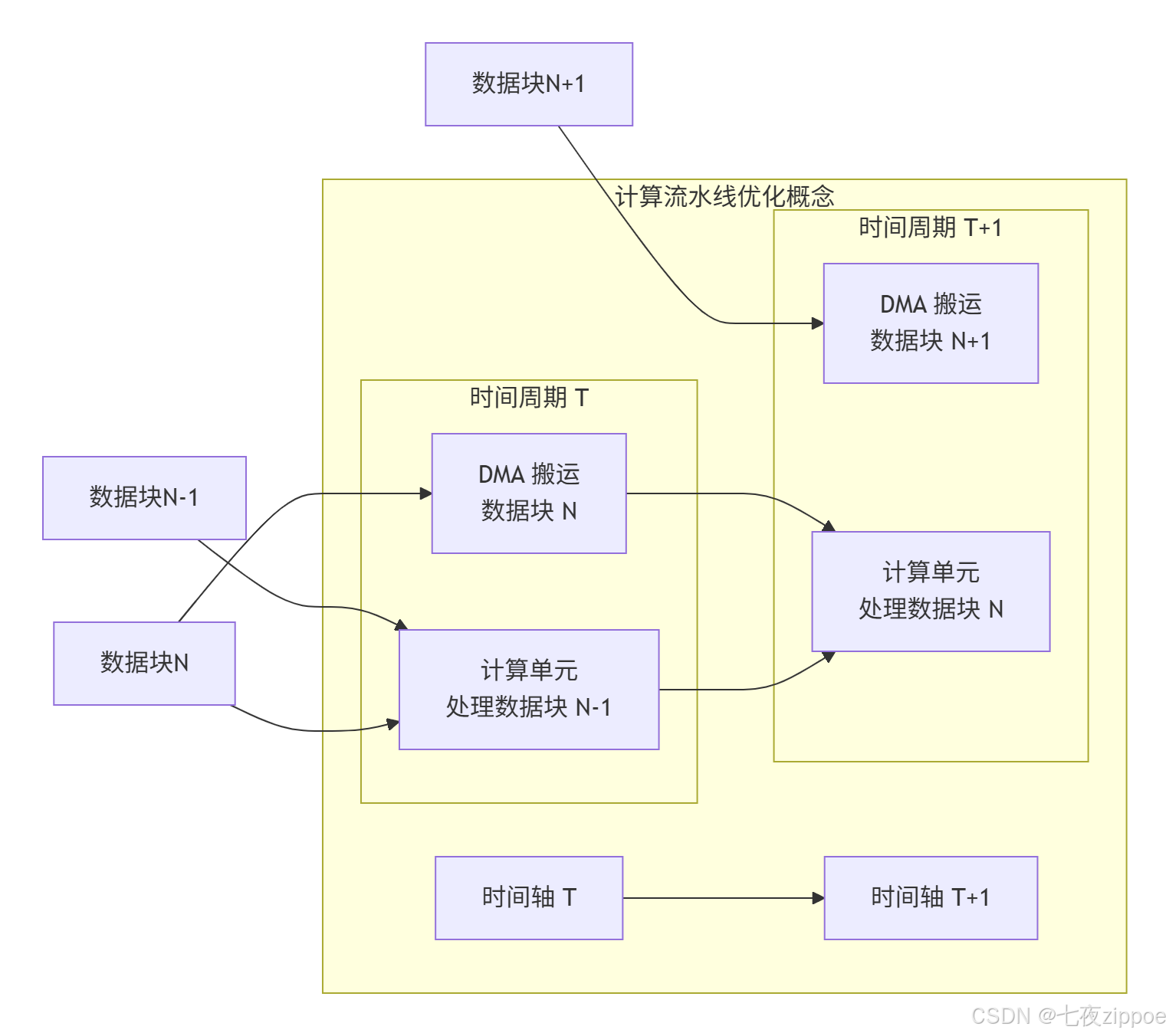
-
原理:将 UB 分为两部分(Buffer A 和 Buffer B)。当计算单元在处理 Buffer A 中的数据时,DMA 控制器可以同时将下一个数据块搬运到 Buffer B。下一个周期,两者角色互换。
-
效果:从宏观上看,计算单元几乎一直在工作,无需等待数据搬运,极大提升了计算单元的利用率。
✅ 性能优化检查点
我的 Kernel 是否使用了 UB 进行数据缓存,而非直接操作全局内存?
我是否尝试通过向量化加载/存储来最大化内存带宽利用率?
对于计算密集型的 Kernel,我是否考虑了实现双缓冲或其他流水线技术来隐藏延迟?
五、代码实战:向量加法算子的并行实现与优化
下面我们以经典的向量加法(ci = ai + bi)为例,展示一个完整的、更具实践性的 Ascend C 算子实现。
步骤 1:定义 Kernel 函数(Device侧) - 基础版本
cpp
// vector_add_kernel.h
#ifndef __VECTOR_ADD_KERNEL_H__
#define __VECTOR_ADD_KERNEL_H__
#include <acl/acl.h>
// 1. 定义Tiling结构体(必须与Host侧一致)
typedef struct {
uint32_t totalLength;
uint32_t tileLength;
uint32_t tileNum;
uint32_t lastTileLength;
} VectorAddTiling;
// 2. 声明核函数
extern "C" __global__ __aicore__ void vector_add_kernel(
VectorAddTiling* tiling,
const float* a,
const float* b,
float* c);
#endif // __VECTOR_ADD_KERNEL_H__
cpp
// vector_add_kernel.cc (基础版本 - 逐元素处理)
#include "vector_add_kernel.h"
extern "C" __global__ __aicore__ void vector_add_kernel(
VectorAddTiling* tiling,
const float* a,
const float* b,
float* c) {
uint32_t blockIdx = GetBlockIdx();
if (blockIdx >= tiling->tileNum) return;
uint32_t offset = blockIdx * tiling->tileLength;
uint32_t realLength = (blockIdx == tiling->tileNum - 1) ? tiling->lastTileLength : tiling->tileLength;
// 基础版本:逐元素加法循环
for (uint32_t i = 0; i < realLength; ++i) {
uint32_t index = offset + i;
c[index] = a[index] + b[index];
}
}步骤 2:Host 侧代码实现
cpp
// vector_add_host.cpp
#include <iostream>
#include <vector>
#include "vector_add_kernel.h"
#include <acl/acl.h>
int main() {
// ... (省略: aclInit, aclrtSetDevice等初始化代码)
// 1. 准备测试数据
const uint32_t totalElements = 10000;
std::vector<float> hostA(totalElements, 1.0f); // 初始化10000个1.0
std::vector<float> hostB(totalElements, 2.0f); // 初始化10000个2.0
std::vector<float> hostC(totalElements, 0.0f); // 结果向量
// 2. 分配Device内存并拷贝数据 (H2D)
float *deviceA, *deviceB, *deviceC;
aclrtMalloc((void**)&deviceA, totalElements * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&deviceB, totalElements * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&deviceC, totalElements * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMemcpy(deviceA, ..., hostA.data(), ..., ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(deviceB, ..., hostB.data(), ..., ACL_MEMCPY_HOST_TO_DEVICE);
// 3. 计算Tiling参数(对应素材中的"Host侧实现Tiling函数实现")
VectorAddTiling tiling;
tiling.totalLength = totalElements;
tiling.tileLength = 256; // 假设每个块处理256个元素
tiling.tileNum = (totalElements + tiling.tileLength - 1) / tiling.tileLength;
tiling.lastTileLength = totalElements - (tiling.tileNum - 1) * tiling.tileLength;
// 4. 分配并拷贝Tiling结构体到Device
VectorAddTiling* deviceTiling = nullptr;
aclrtMalloc((void**)&deviceTiling, sizeof(VectorAddTiling), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMemcpy(deviceTiling, ..., &tiling, ..., ACL_MEMCPY_HOST_TO_DEVICE);
// 5. 启动Kernel (启动tiling.tileNum个Block)
std::cout << "Launching Kernel with " << tiling.tileNum << " blocks." << std::endl;
// rtKernelLaunch(vector_add_kernel, tiling.tileNum, ...);
// 6. 同步等待并获取结果 (D2H)
aclrtSynchronizeDevice();
aclrtMemcpy(hostC.data(), ..., deviceC, ..., ACL_MEMCPY_DEVICE_TO_HOST);
// 7. 验证结果
std::cout << "First 5 results: ";
for (int i = 0; i < 5; ++i) {
std::cout << hostC[i] << " "; // 应输出 3.0, 3.0, 3.0, ...
}
std::cout << std::endl;
// ... (省略: 资源释放, aclFinalize等清理代码)
return 0;
}六、总结与深度思考
本文系统性地揭秘了 Ascend C 的编程模型,紧密围绕训练营素材的核心概念。我们从核函数的定义和执行模型入手,深入剖析了基于 Tiling 的任务并行机制,并通过详细的流程图和代码示例,具象化地展示了 **"算子工程"**在 Host 侧和 Kernel 侧的分工与协作。最后,我们展望了超越基础并行的内存层次利用和流水线优化技术,为性能优化指明了方向。
-
核心要点归纳:
-
核函数是载体:核函数是并行执行的基本单位,通过 Grid-Block 模型在硬件上实现大规模并行。
-
Tiling 是灵魂:Tiling 策略是连接 Host 侧管理与 Device 侧计算的桥梁,是实现数据并行的核心。
-
异构协同是基础:深刻理解 Host(调度管理)与 Device(并行计算)的职责分离,是编写正确、高效算子的前提。
-
内存优化是关键:理解全局内存与 UB 的层次结构,并尝试应用流水线技术,是提升性能的进阶之路。
-
-
讨论与思考:
思考点一 :在向量加法的例子中,如果
a、b、c三个向量的内存地址不是连续对齐的,会对性能产生什么影响?Ascend C 提供了哪些内存访问指令或优化建议来应对这种情况?思考点二:本文提到的双缓冲流水线优化,虽然能有效隐藏延迟,但也会增加代码的复杂性和 UB 的占用。在什么情况下(例如,数据块大小、计算与搬运的时间比例)使用双缓冲是值得的?你是否能设想一个简单的模型来帮助做出决策?
参考链接
-
华为昇腾社区:Ascend C 核函数开发指南:最权威的编程指南(请登录社区后搜索具体文档)。
-
华为昇腾社区:性能调优指南:了解如何分析和优化 Ascend C 算子的性能。
-
《Programming Massively Parallel Processors: A Hands-on Approach》:一本关于并行编程概念的经典著作,虽然基于 CUDA,但其核心思想(如内存层次、并行模式)与 Ascend C 高度相通。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接 : https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!