一、脚本功能描述
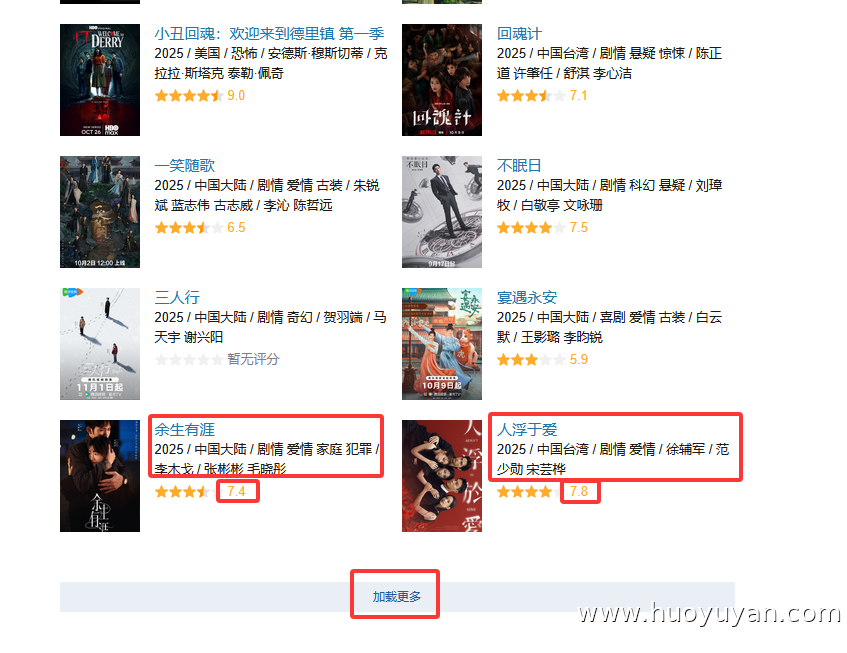
本脚本基于火语言 RPA 实现自动化访问豆瓣电影页面,循环点击 "加载更多" 按钮获取多页影视数据、批量采集剧集名称、年份、评分信息,并保存到 Excel 文档。
二、整体逻辑
1、准备
打开浏览器、浏览网页,访问豆瓣电影网页
初始化点击计数器(记录 "加载更多" 操作次数,从 1 开始)
2、循环采集:
重复执行以下操作,直到 "加载更多" 按钮消失或点击次数达到上限;
判断 "加载更多" 按钮是否存在,若存在则点击并更新点击次数(次数 + 1),若不存在则停止循环,获取需要采集的所有剧集条目列表;
提取所有剧集的 "剧名、年份、评分",分别存入剧名列表、年份列表、评分列表;
3、保存数据:
新建 Excel 文件(路径为桌面,文件名为豆瓣TV.xlsx);
在 Excel 的A1、B1、C1单元格分别写入 "剧集""年份""评分" 作为表头;
将剧名列表、年份列表、评分列表的内容分别写入 Excel 的 A、B、C 列。
三、详细操作步骤
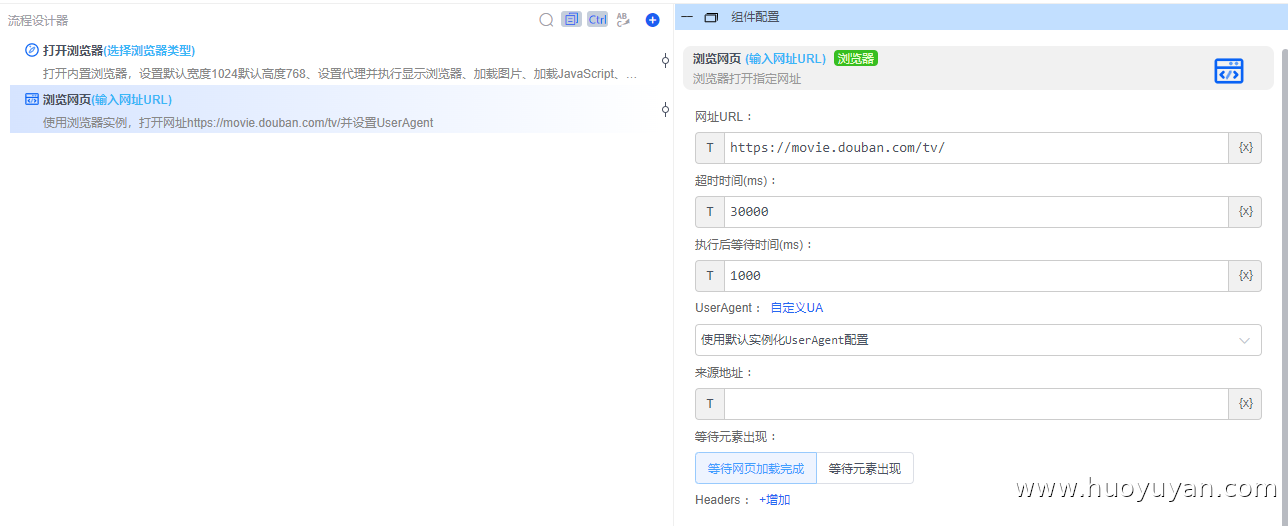
步骤 1:打开浏览器 + 打开目标页
操作细节
打开浏览器 (选择浏览器类型:内置、外置、指纹)
浏览网页 ,输入需要采集的网址URL:https://movie.douban.com/tv/
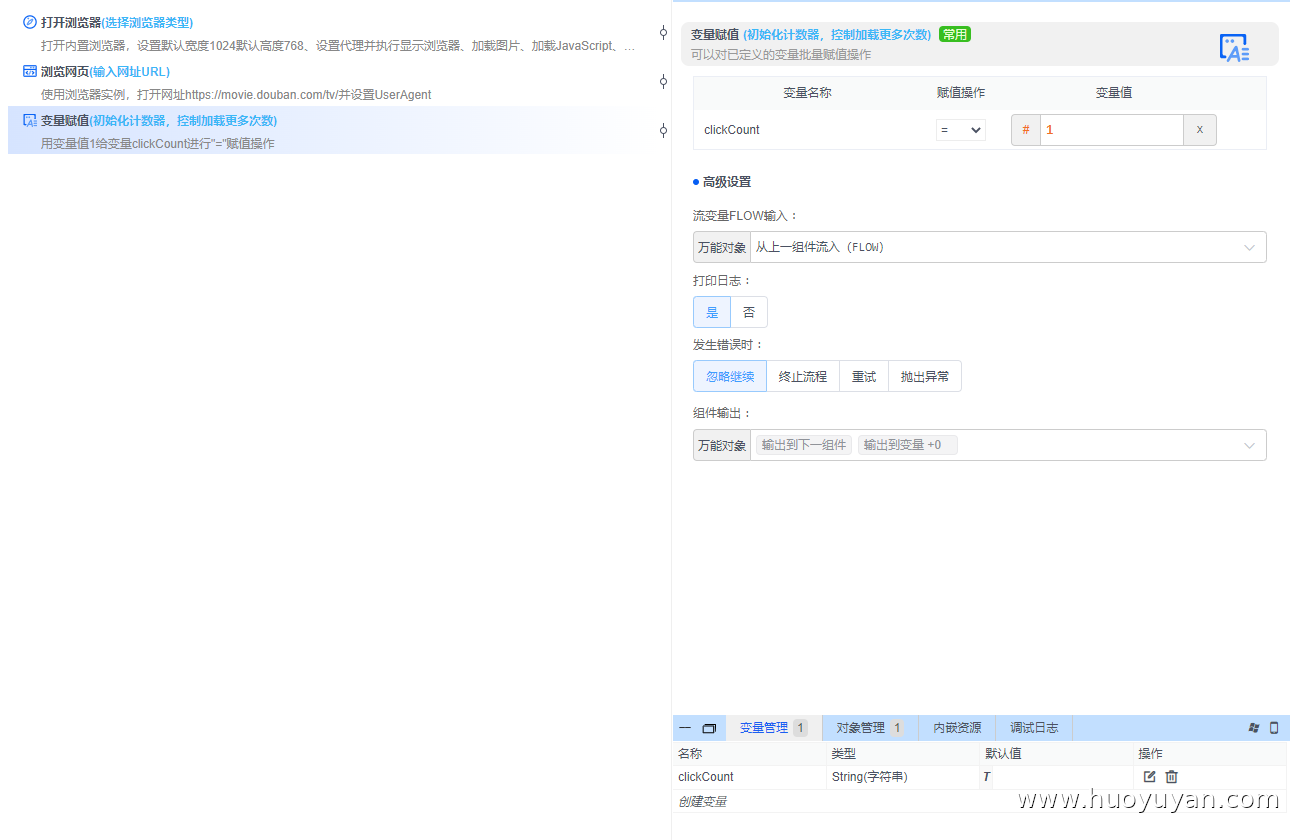
步骤 2:初始化计数器,控制加载更多次数
操作细节
变量赋值 :创建点击次数变量:clickCount,初始值1,用于控制"加载更多"的点击次数。
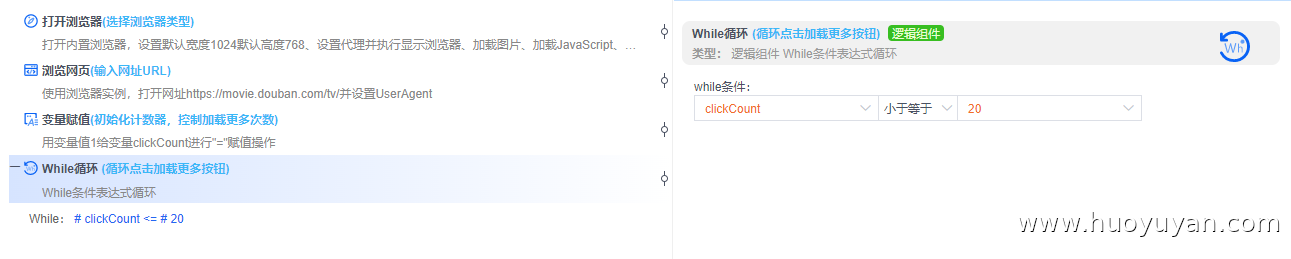
步骤 3:判断"加载更多"按钮是否存在,如存在进行循环点击,如不存在则跳出循环。
While循环 :循环点击"加载更多"按钮,为了避免无限循环,我们设置最多20次,clickCount≤20。
检测元素是否存在 :检测"加载更多"按钮是否存在,目标元素:button,输出变量:加载更多。
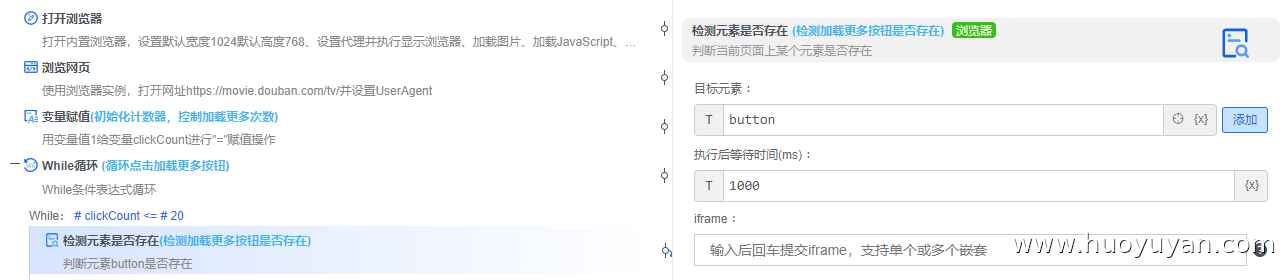
条件判断 :判断"加载更多"是否存在,存在就点击,不存在停止循环。
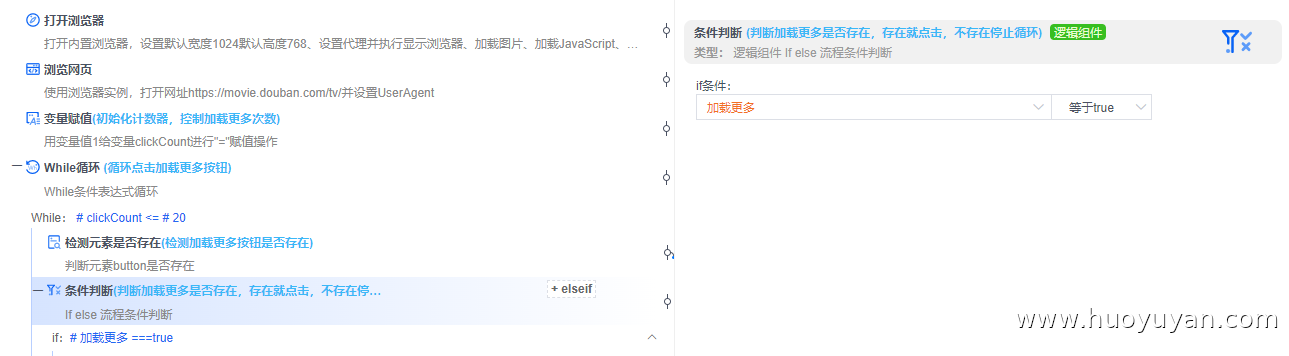
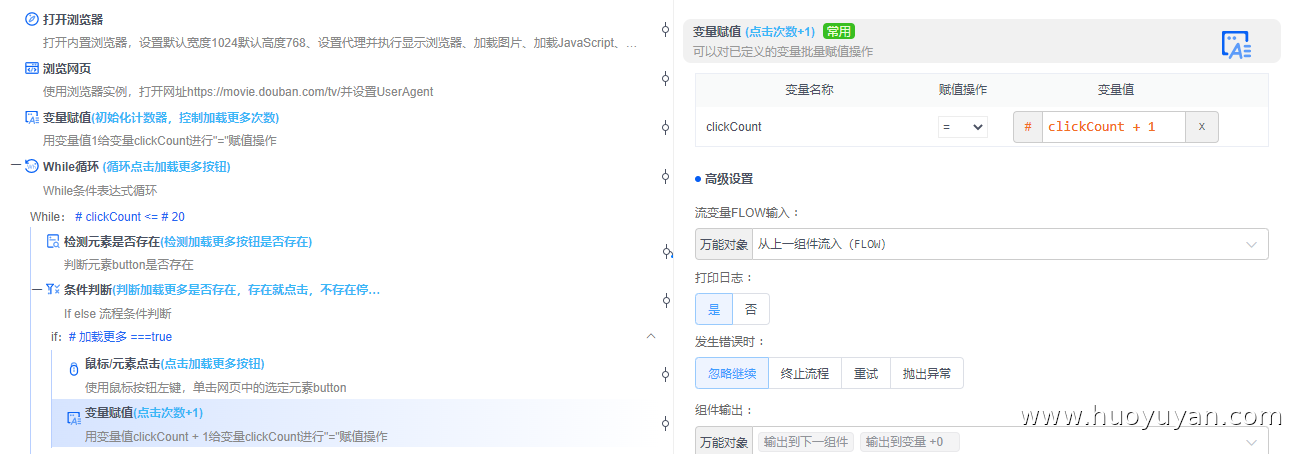
鼠标/元素点击 :如加载更多===ture,进行鼠标点击,
变量赋值 :点击后,点击次数+1,clickCount=clickCount + 1
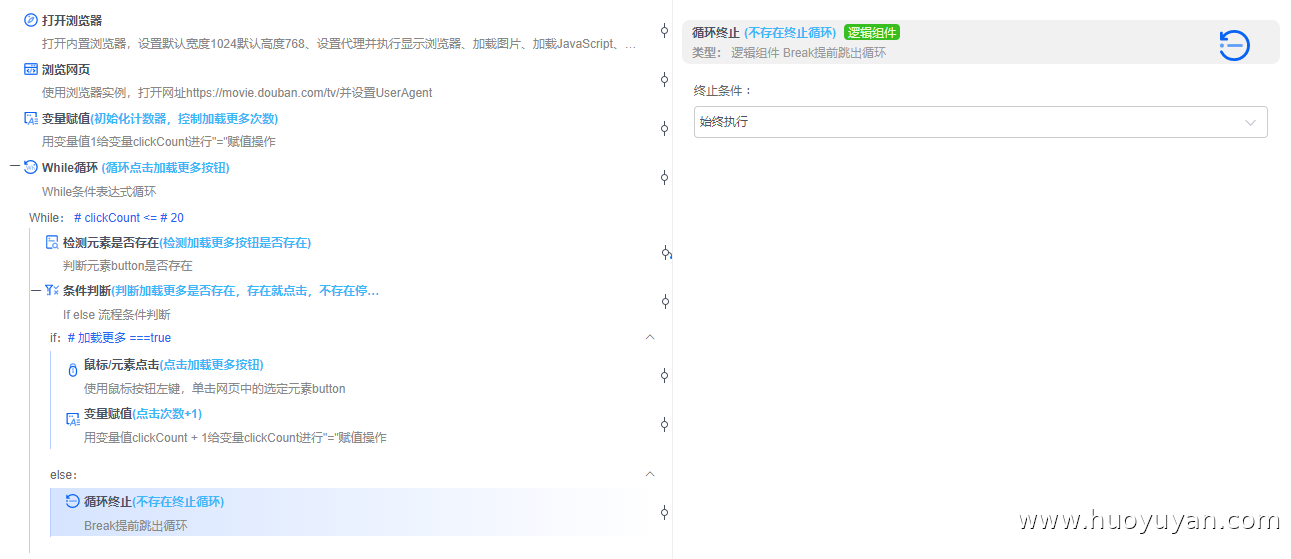
循环终止 :如加载更多不存在,终止循环。
步骤 4:采集 "剧名、年份、评分" 数据
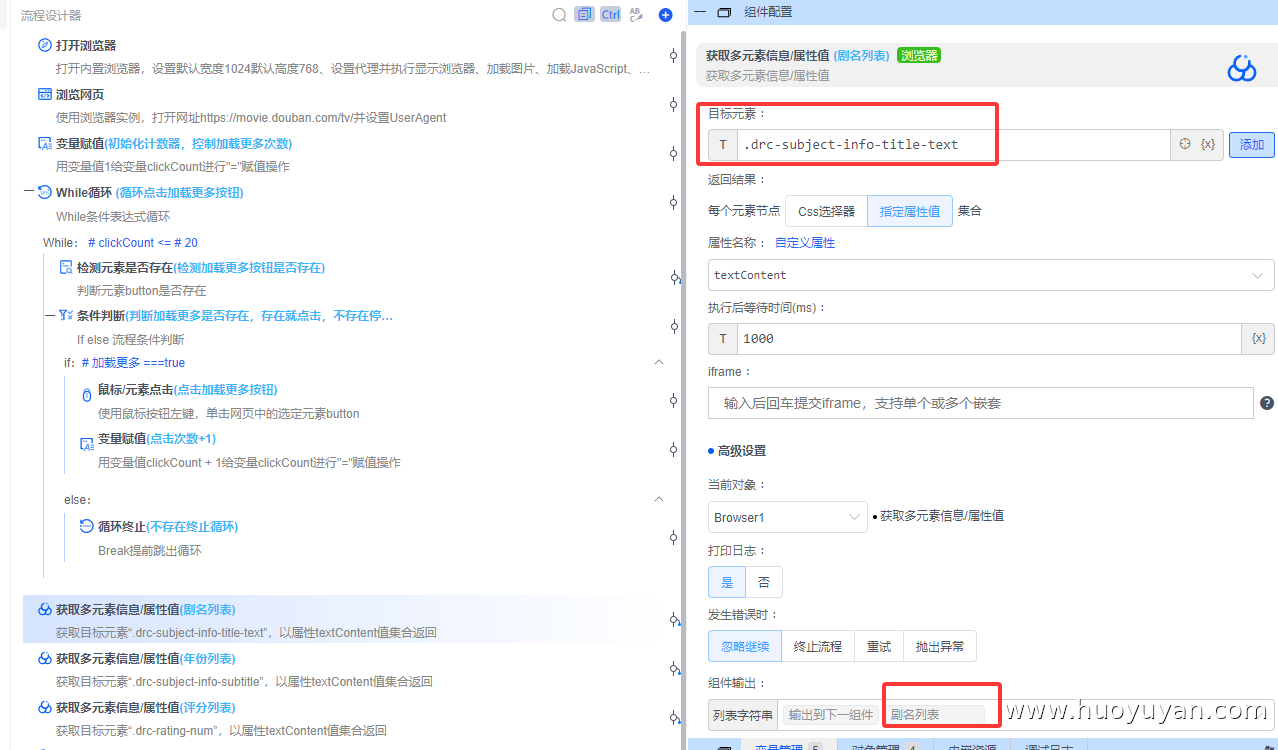
获取多元素信息/属性值 :采集剧名,元素:.drc-subject-info-title-text,属性:textContent(文本内容),输出变量:剧名列表
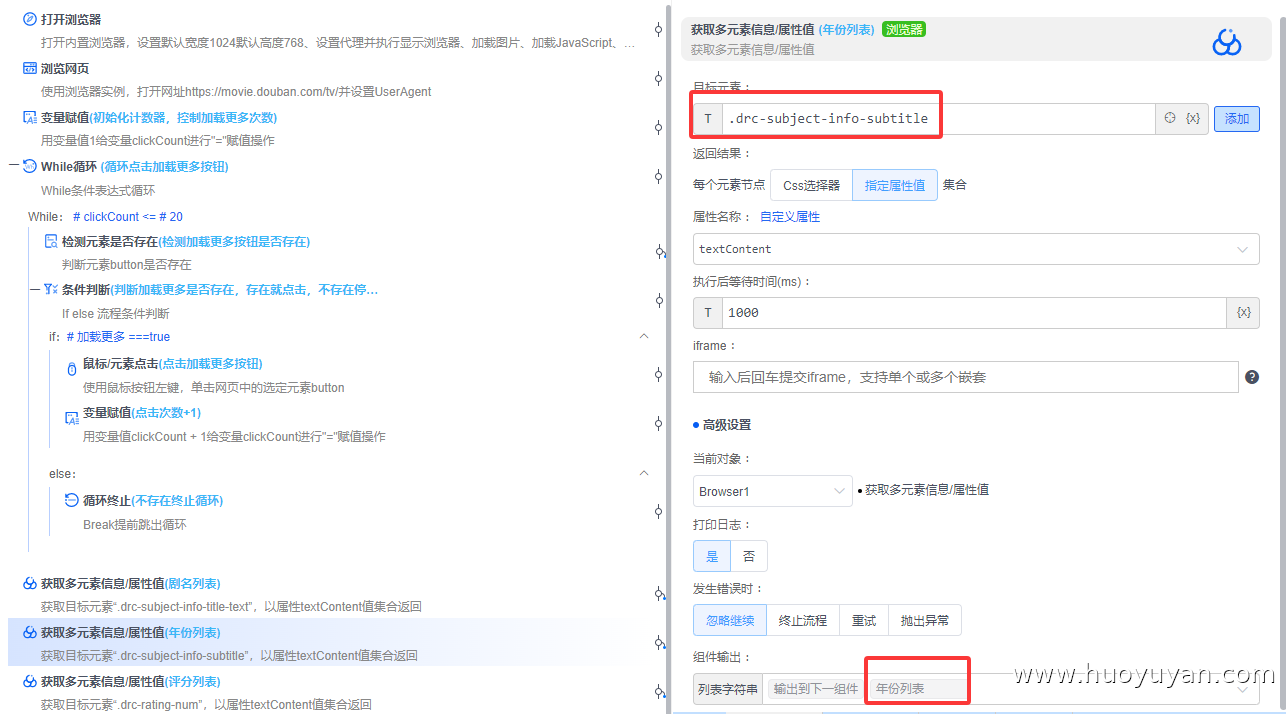
获取多元素信息/属性值 :采集年份,元素:.drc-subject-info-subtitle,属性:textContent(文本内容),输出变量:年份列表
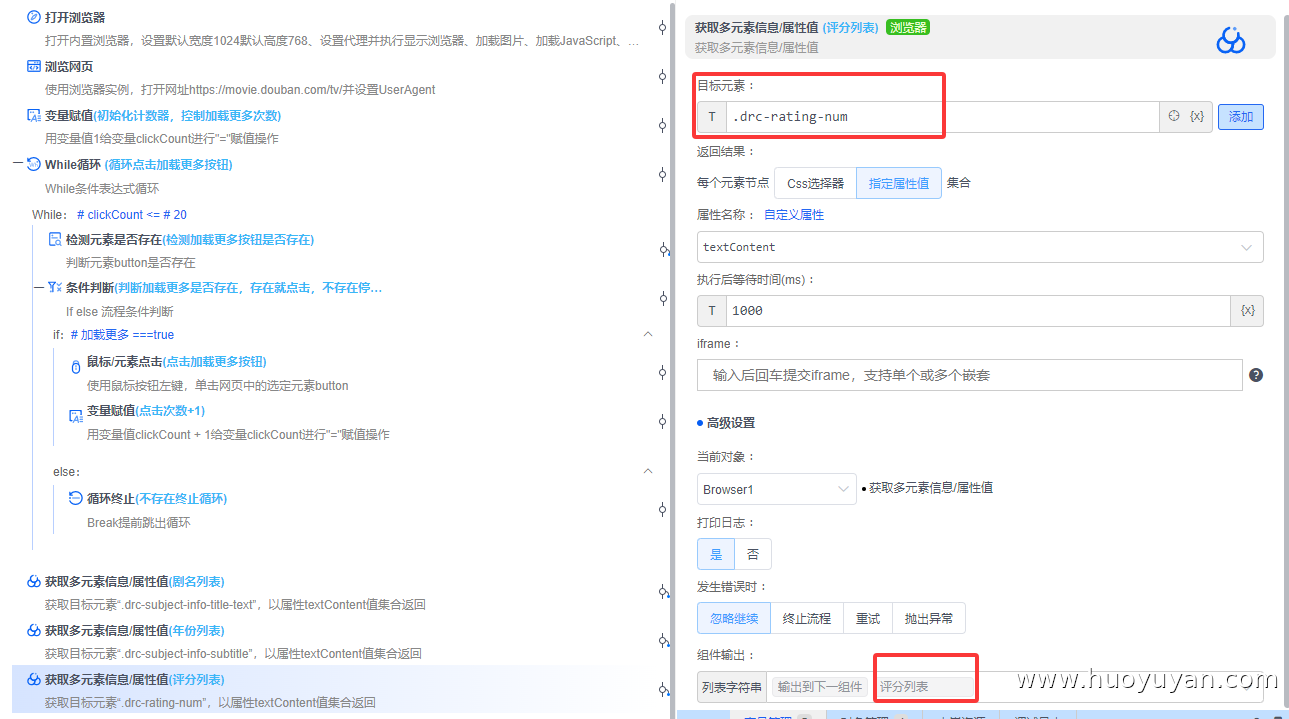
获取多元素信息/属性值 :采集评分,元素:.drc-rating-num,属性:textContent(文本内容),输出变量:评分列表
步骤 5:Excel 写入表头与数据
将采集到的结构化数据写入到 Excel,表格列头:剧名、年份、评分;
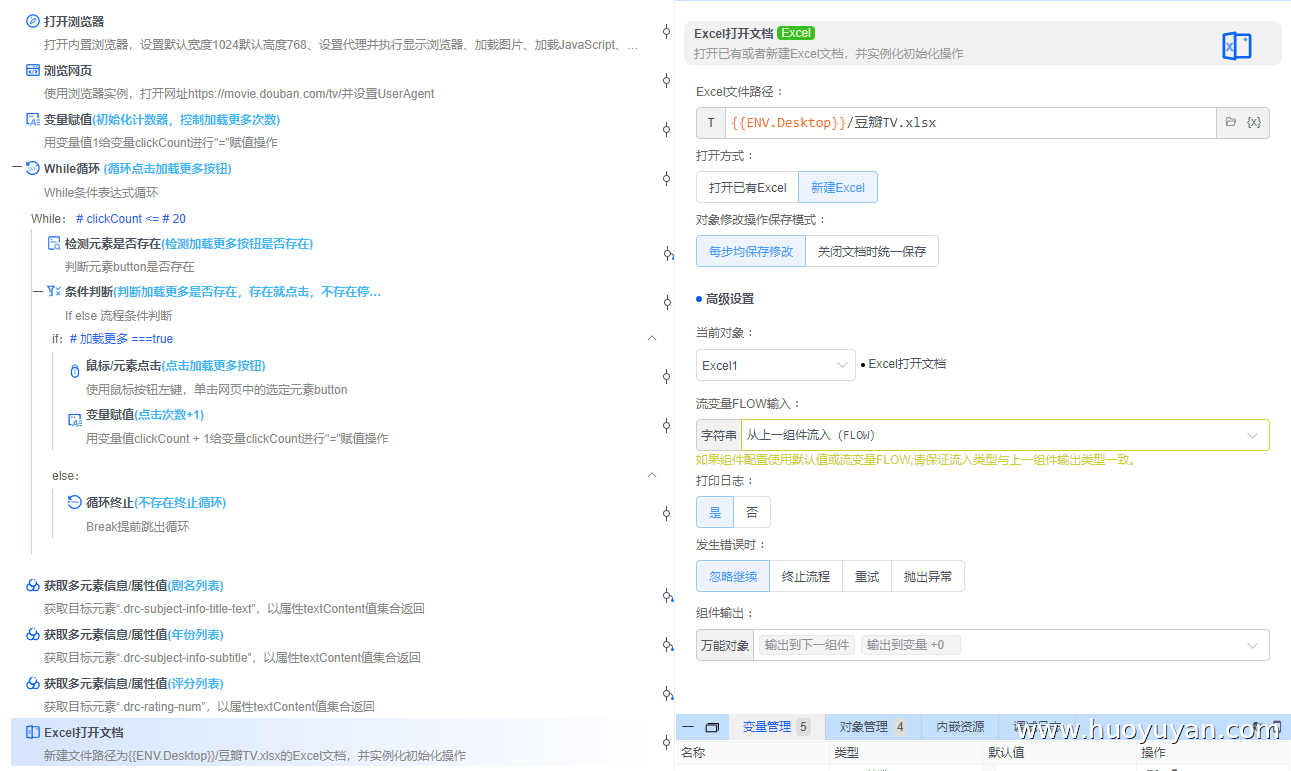
Excel打开文档 :新建空文档,用于存储数据
Excel写入内容 :写入Excel列头
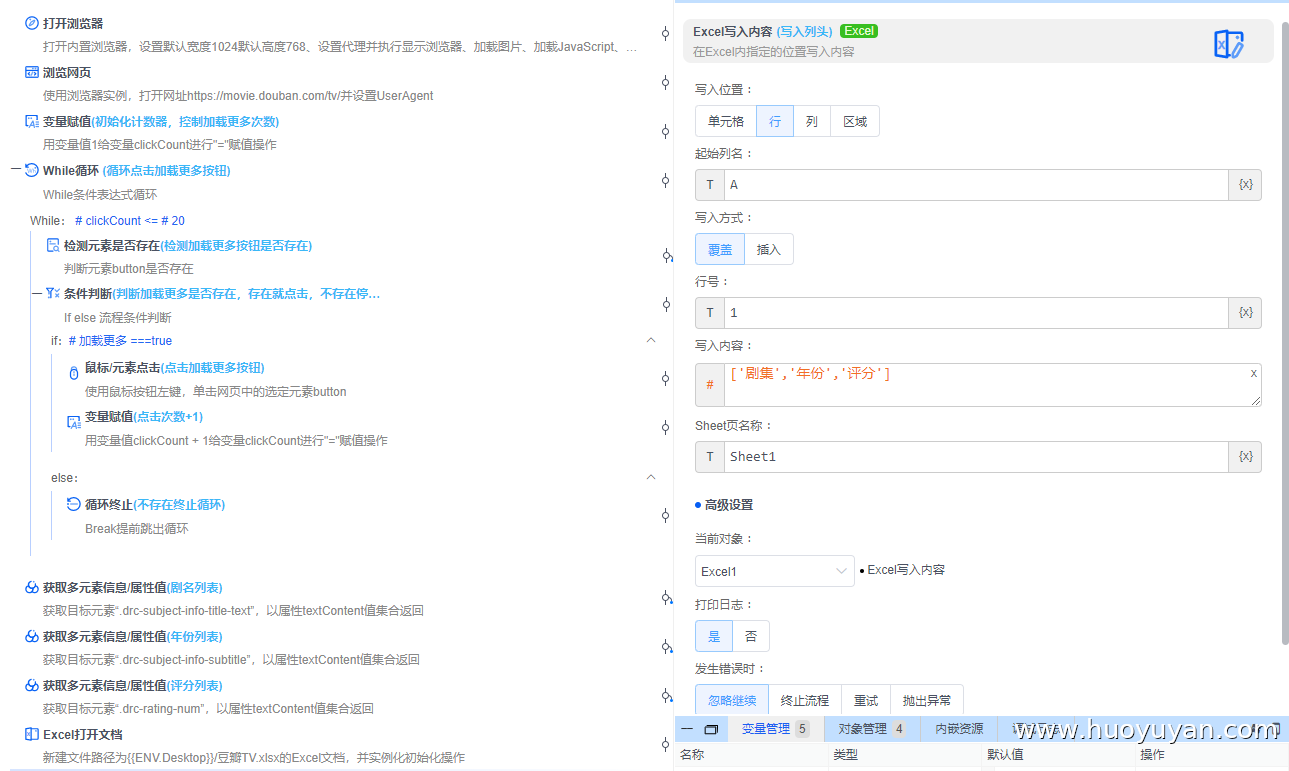
Excel写入内容 :写入剧名,按列,起始行号2,列名A,写入内容:#剧名列表
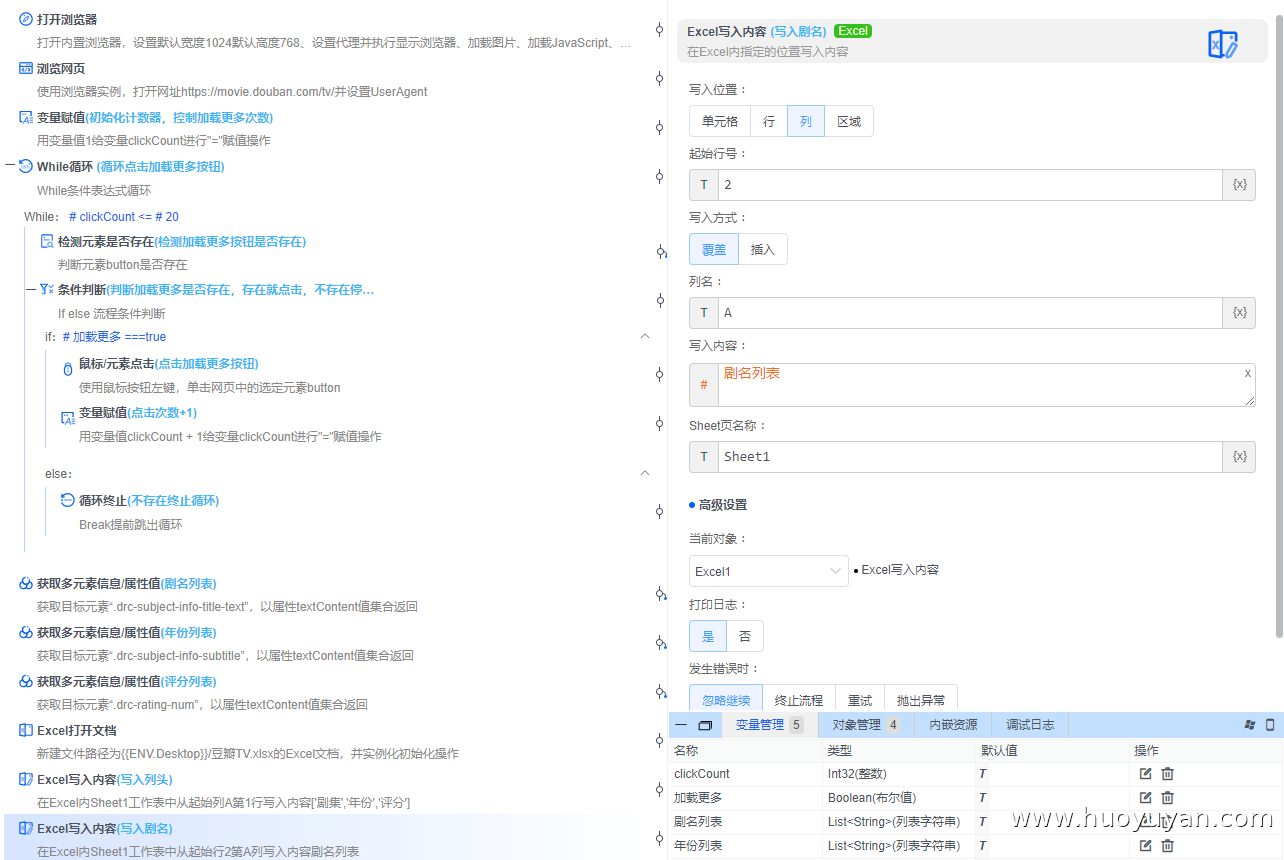
Excel写入内容 :写入剧名,按列,起始行号2,列名B,写入内容:#年份列表
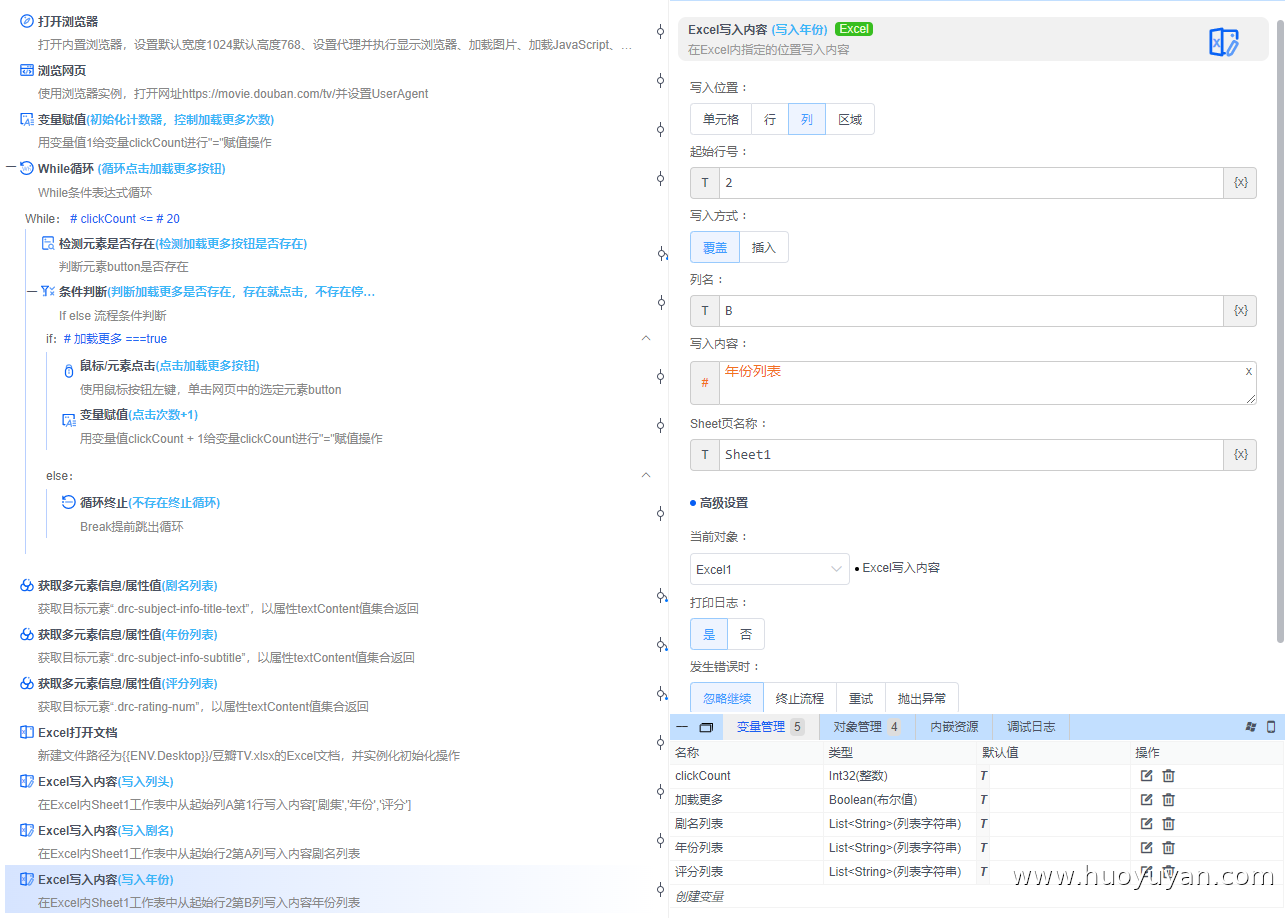
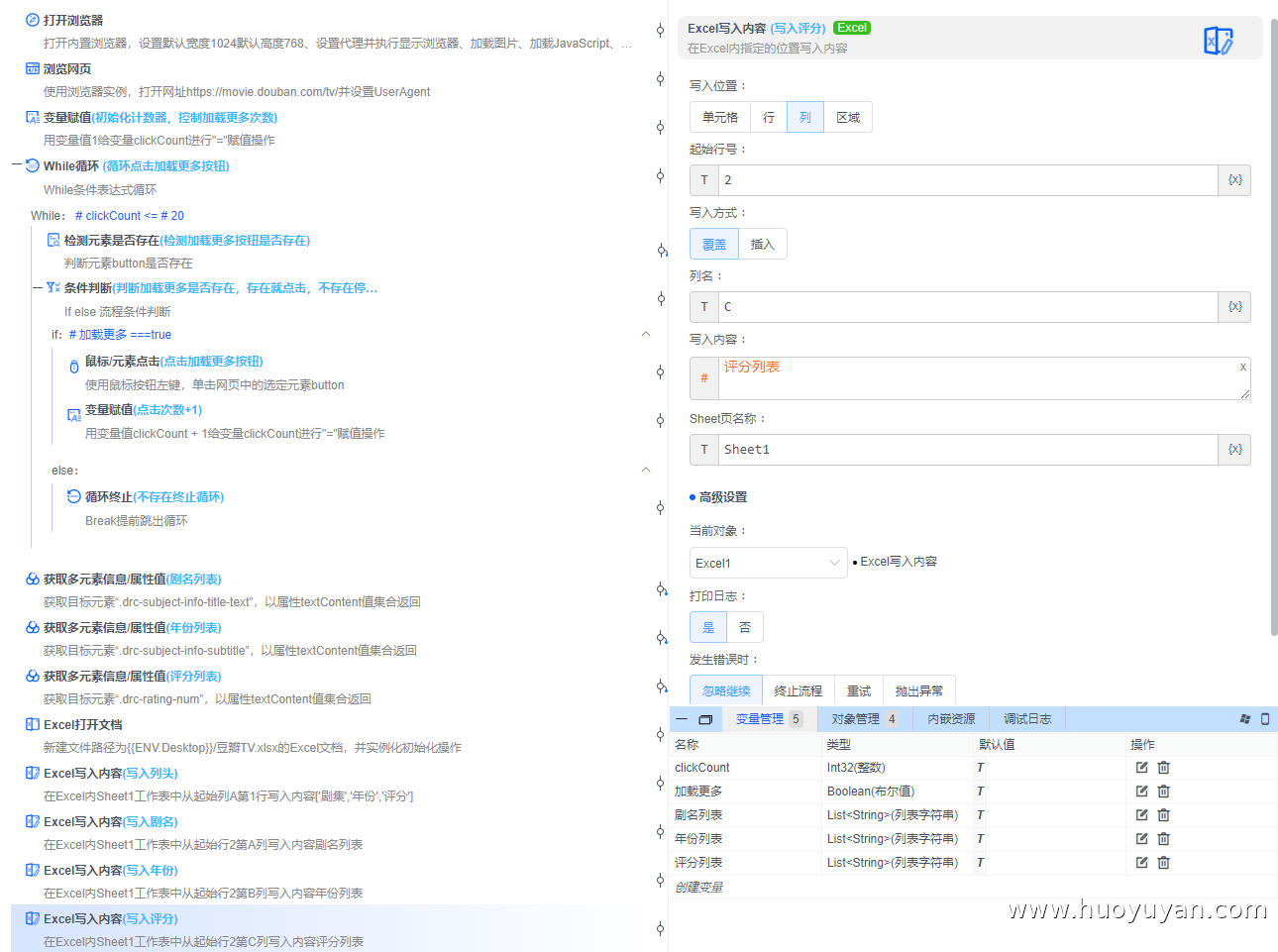
Excel写入内容 :写入剧名,按列,起始行号2,列名C,写入内容:#评分列表
Excel关闭保存文档 :保存Excel
关闭浏览器:关闭内置浏览器
四、脚本注意事项
豆瓣电影页的内容需要点击 "加载更多" 才会出来,所以用 RPA 采集时,先精准找到这个按钮,再循环点击它来加载更多内容,实现采集。
案例脚本分享 : https://www.huoyuyan.com/share.html?key=eyJhdXRvQ29kZSI6IkZhbHNlIiwia2V5IjoiZTFmY2I1NzUzZDk0NDgwM2I4MzkxYTI0YjYzNGNiYjcifQ== 提取码: wTRN