1:理解文件
1:狭义理解
1:文件在磁盘里
2:磁盘是永久性储存介质,因此文件在磁盘上的储存是永久性的
3:磁盘是外设(既是输入也是输出设备)
4:磁盘上的文件 本质是对文件的所有操作,都是对外设的输入和输出简称IO
2:广义理解
Linux下一切皆文件
3:文件操作的归类认识
1:对于0KB的文件是占用磁盘空间的
2:文件是文件属性(元数据)和文件内容的集合(文件=文件属性+内容)
3:所有的文件操作本质是文件内容操作和文件属性操作
4:系统角度
1:文件的操作本质是进程对文件的操作
2:磁盘的管理者是操作系统
3:文件的读写本质不是通过C/C++的库函数来实现的(这些库函数只是为用户提供方便)是通过文件相关的系统调用接口来实现的
2:系统文件IO
打开文件的方式不仅仅是fopen,ifstream等流式,语言层的方案,其中系统才是打开文件最底层的方案。
1:一种传递标志位的方法
cpp
#include <stdio.h>
#define ONE 0001 //0000 0001
#define TWO 0002 //0000 0010
#define THREE 0004 //0000 0100
void func(int flags) {
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");
printf("\n");
}
int main() {
func(ONE);
func(THREE);
func(ONE | TWO);
func(ONE | THREE | TWO);
return 0;
}操作⽂件,除了上C接⼝(当然,C++也有接⼝,其他语⾔也有),我们还可以采⽤系统接⼝来进⾏⽂件访问, 先来直接以系统代码的形式,实现和上⾯⼀模⼀样的代码:
2:hello.c写文件
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0);
int fd = open("myfile", O_WRONLY|O_CREAT, 0644);
if(fd < 0){
perror("open");
return 1;
}
int count = 5;
const char *msg = "hello bit!\n";
int len = strlen(msg);
while(count--){
write(fd, msg, len);//fd: 后⾯讲, msg:缓冲区⾸地址, len: 本次读取,期望写
⼊多少个字节的数据。 返回值:实际写了多少字节数据
}
close(fd);
return 0;
}3:hello.c读文件
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
const char* msg = "hello bit!\n";
char buf[1024];
while (1) {
ssize_t s = read(fd, buf, strlen(msg));//类⽐write
if (s > 0) {
printf("%s", buf);
}
else {
break;
}
}
close(fd);
return 0;
}4:open接口介绍
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的⽬标⽂件
flags: 打开⽂件时,可以传⼊多个参数选项,⽤下⾯的⼀个或者多个常量进⾏"或"运算,构成
flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定⼀个且只能指定⼀个
O_CREAT : 若⽂件不存在,则创建它。需要使⽤mode选项,来指明新⽂件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的⽂件描述符
失败:-15:open函数的返回值
在认识返回值之前,先来认识⼀下两个概念: 系统调⽤ 和 库函数
•
上⾯的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数
(libc)。
•
⽽ open close read write lseek 都属于系统提供的接⼝,称之为系统调⽤接⼝
•
回忆⼀下我们讲操作系统概念时,画的⼀张图
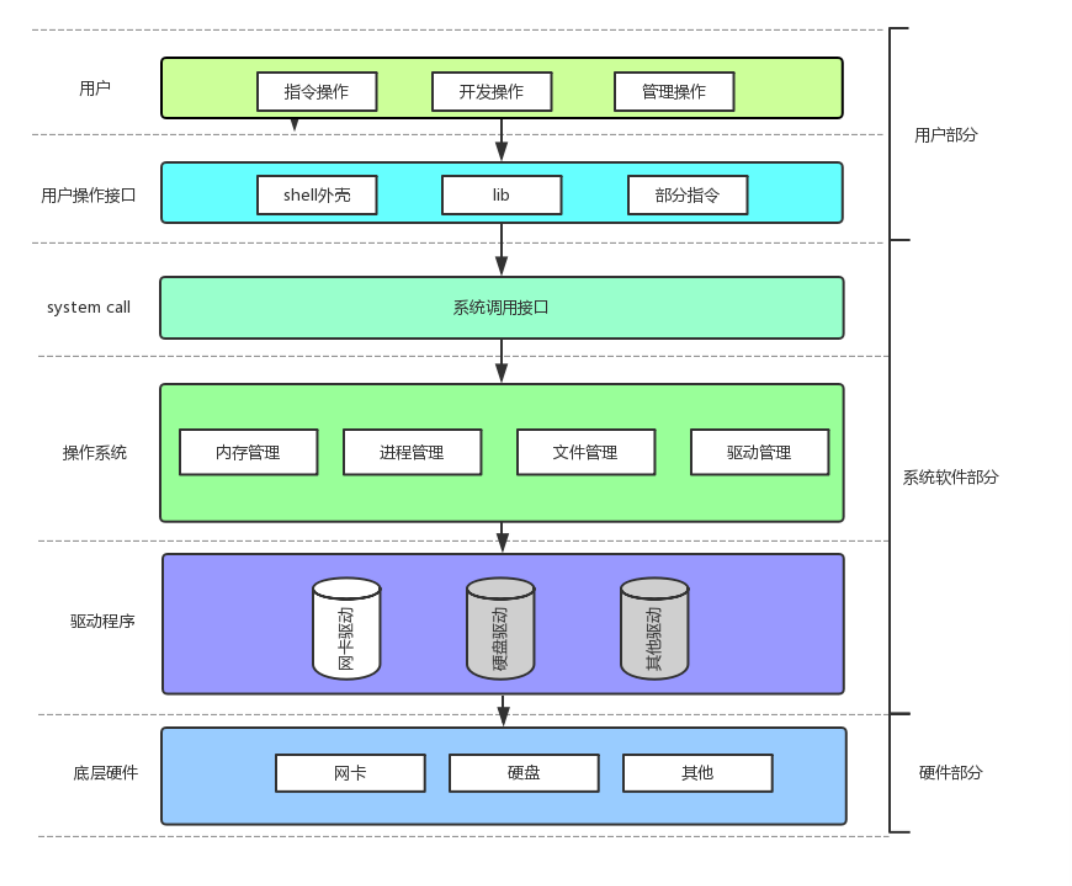
系统调用接口和库函数的关系,一目了然。
所以,可以认为,f#系列的函数,都是对系统调用的封装,方便二次开发。
6:文件描述符fd
在上面我们可以看到open函数的返回值是一个整数,所以fd作为返回值也是一个整数
1:0&1&2
Linux进程默认情况下会有三个缺省打开的文件描述符,分辨是标准输入0,标准输出1,标准错误2
0,1,2对应的外设也就是键盘,显示器,显示器
所以输入输出也可以采用下面方法
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
char buf[1024];
ssize_t s = read(0, buf, sizeof(buf));
if (s > 0) {
buf[s] = 0;
write(1, buf, strlen(buf));
write(2, buf, strlen(buf));
}
return 0;
}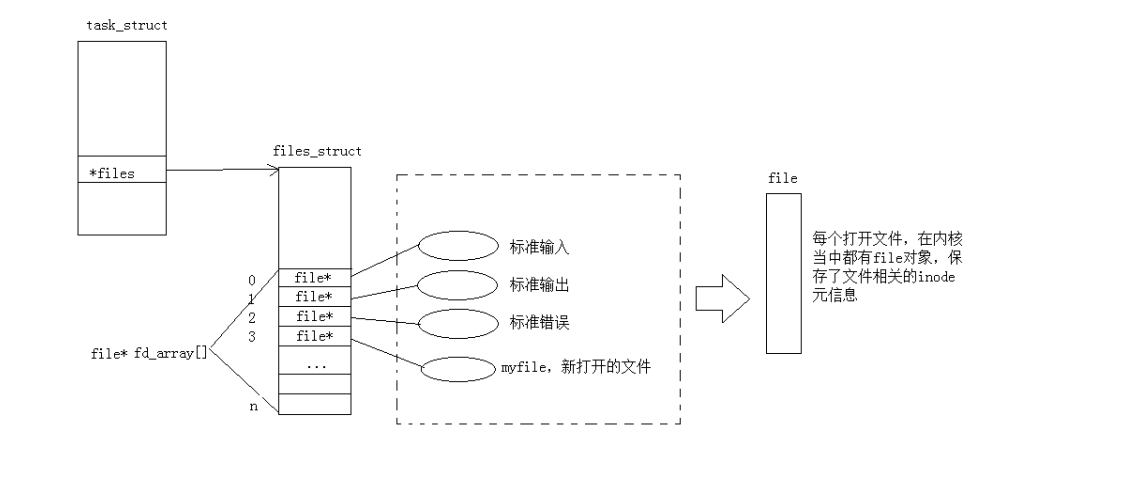
⽽现在知道,⽂件描述符就是从0开始的⼩整数。当我们打开⽂件时,操作系统在内存中要创建相应的数据结构来描述⽬标⽂件。于是就有了file结构体。表⽰⼀个已经打开的⽂件对象。⽽进程执⾏open系统调⽤,所以必须让进程和⽂件关联起来。每个进程都有⼀个指针* files, 指向⼀张表files_struct, 该表最重要的部分就是包含⼀个指针数组,每个元素都是⼀个指向打开⽂件的指针!所以,本质上,⽂件描述符就是该数组的下标。所以,只要拿着⽂件描述符,就可以找到对应的⽂件。
2:文件描述符的分配规则
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}输出发现fd:3
关闭0或者2
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}发现是结果是: fd: 0 或者 fd 2 ,可⻅,⽂件描述符的分配规则:在files_struct数组当中,找到
当前没有被使⽤的最⼩的⼀个下标,作为新的⽂件描述符。
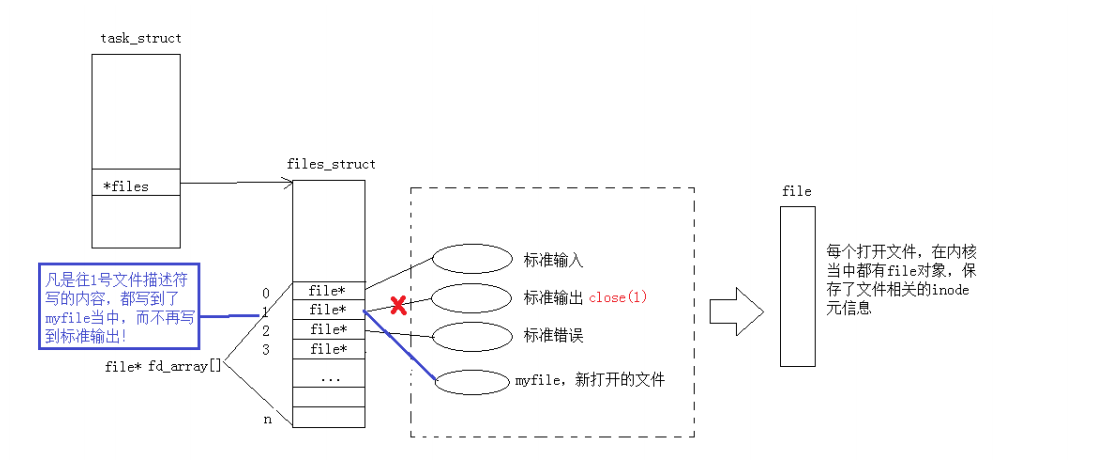
3:重定向
如果把1关闭了呢?
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
fflush(stdout);
close(fd);
exit(0);
}此时,我们发现,本来应该输出到显⽰器上的内容,输出到了⽂件 myfile 当中,其中,fd=1。这
种现象叫做输出重定向。常⻅的重定向有: > , >> , <
那重定向的本质是什么呢?
4:使用dup2系统调用
函数原型
cpp
#include <unistd.h>
int dup2(int oldfd, int newfd);示例代码
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd = open("./log", O_CREAT | O_RDWR);
if (fd < 0) {
perror("open");
return 1;
}
close(1);
dup2(fd, 1);
for (;;) {
char buf[1024] = {0};
ssize_t read_size = read(0, buf, sizeof(buf) - 1);
if (read_size < 0) {
perror("read");
break;
}
printf("%s", buf);
fflush(stdout);
}
return 0;
}printf是C库当中的IO函数,⼀般往 stdout 中输出,但是stdout底层访问⽂件的时候,找的还是fd:1,
但此时,fd:1下标所表⽰内容,已经变成了myfifile的地址,不再是显⽰器⽂件的地址,所以,输出的任何消息都会往⽂件中写⼊,进⽽完成输出重定向。
3:理解一切皆文件
首先,在Windows中是文件的东西,在Linux中也是文件;其次一些在Windows中不是文件的东西,比如进程,磁盘,显示器,键盘这样硬件设备也被抽象成了文件,你可以使用访问文件的方法访问他们的信息;甚至管道,也是文件;将来的网路编程的socket也是文件。使用的接口和文件接口也是一致的。
这样做的明显好处是,开发者仅需使用一套API和开发工具,即可调取Linux系统中绝大部分的资源。
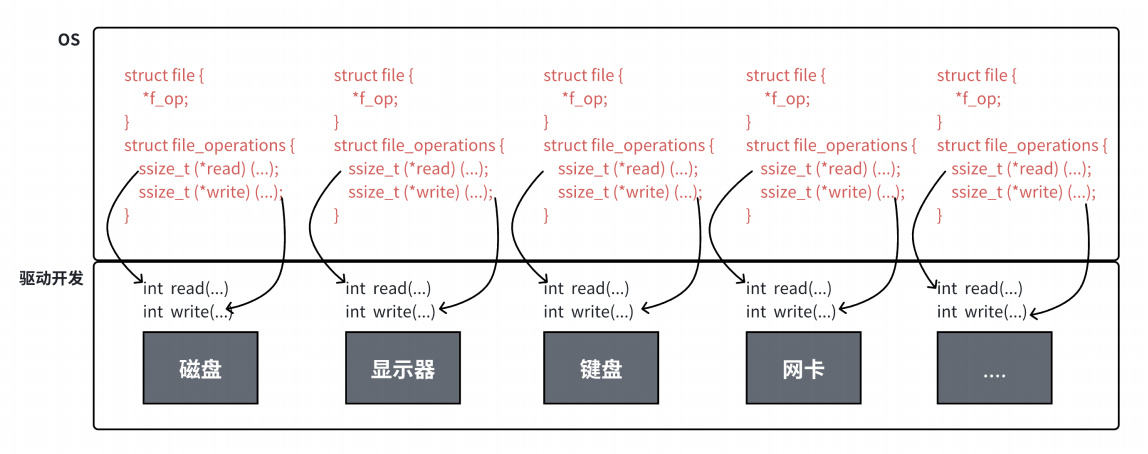
上图中的外设,每个设备都可以有⾃⼰的read、write,但⼀定是对应着不同的操作⽅法!!但通过
struct file 下 file_operation 中的各种函数回调,让我们开发者只⽤file便可调取 Linux 系统中绝⼤部分的资源!!这便是"linux下⼀切皆⽂件"的核⼼理解。
4:缓冲区、
1:什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设备,分为输⼊缓冲区和输出缓冲区。
2:为什么要有缓冲区
读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。
为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤⼤快于对磁盘的操作,故应⽤缓冲区可⼤⼤提⾼计算机的运⾏速度。
⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
3:缓冲类型
标准I/O提供了3种类型的缓冲区。
全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通
常使⽤全缓冲的⽅式访问。
⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤
操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准
I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏
I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。
⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通
常是不带缓冲区的,这使得出错信息能够尽快地显⽰出来。
除了上面的三种缓冲刷新,还有两种也会导致缓冲区刷新
1:缓冲区满
2:flush语句
4:FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的
所以C库中的FILE结构体内部,必定封装了FILE
我们来研究一下
cpp
#include <stdio.h>
#include <string.h>
int main()
{
const char* msg0 = "hello printf\n";
const char* msg1 = "hello fwrite\n";
const char* msg2 = "hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}运行结果
hello printf
hello fwrite
hello write
如果进行输出重定向呢?文件里面又变成了
hello write
hello printf
hello fwrite
hello printf
hello fwrite
我们发现print和fwrite(库函数)都输出了两次,而write只输出了一次(系统调用)。那肯定和fork有关了。
⼀般C库函数写⼊⽂件时是全缓冲的,⽽写⼊显⽰器是⾏缓冲。
printf fwrite 库函数+会⾃带缓冲区(进度条例⼦就可以说明),当发⽣重定向到普通⽂
件时,数据的缓冲⽅式由⾏缓冲变成了全缓冲。
⽽我们放在缓冲区中的数据,就不会被⽴即刷新,甚⾄fork之后
但是进程退出之后,会统⼀刷新,写⼊⽂件当中。
但是fork的时候,⽗⼦数据会发⽣写时拷⻉,所以当你⽗进程准备刷新的时候,⼦进程也就有了
同样的⼀份数据,随即产⽣两份数据。·
write 没有变化,说明没有所谓的缓冲。
综上:
printf fwrite 库函数会⾃带缓冲区,⽽ write 系统调⽤没有带缓冲区。另外,我们这
⾥所说的缓冲区,都是⽤⼾级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。
那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调⽤,库函数在系统调⽤的
"上层", 是对系统调⽤的"封装",但是 write 没有缓冲区,⽽ printf fwrite 有,⾜以说明,该缓冲区是⼆次加上的,⼜因为是C,所以由C标准库提供。