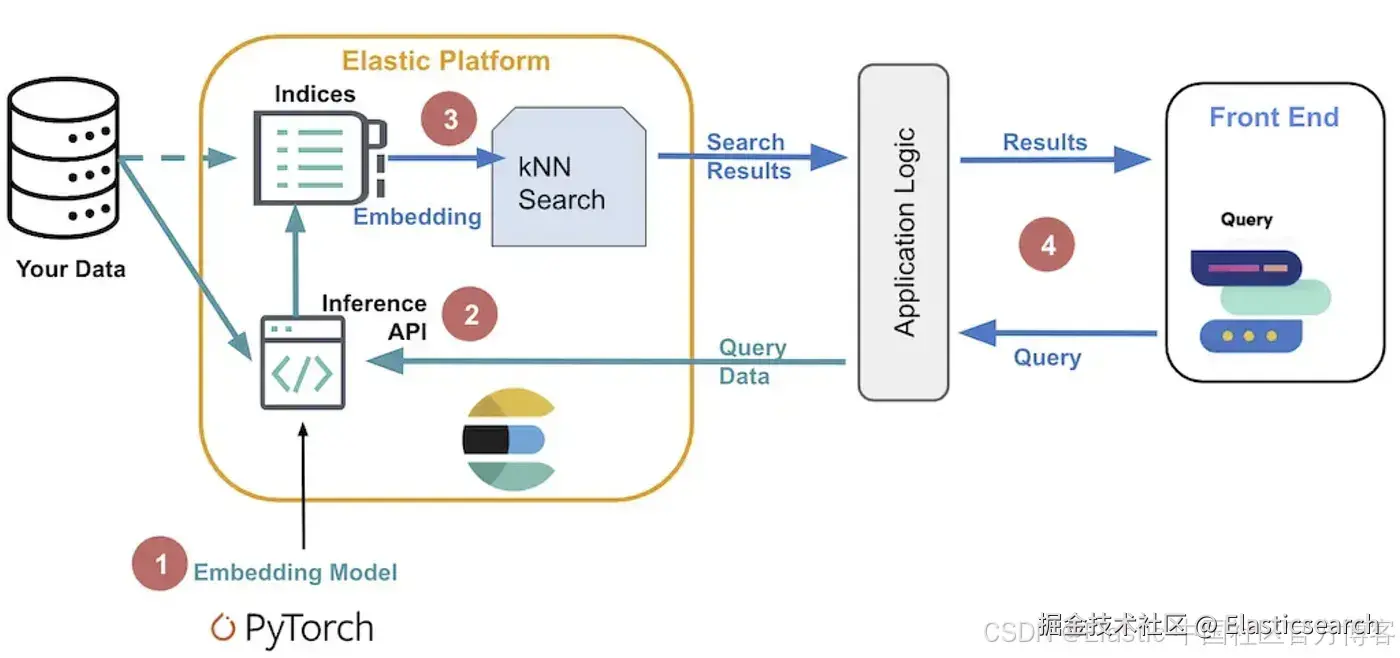
从双向编码器表示(Embeddings from bidirectional Encoder Representations,简称 E5)是一种自然语言处理模型,它可以通过使用稠密向量表示来执行多语言语义搜索。该模型推荐用于非英语文档和查询。如果你想对英文文档执行语义搜索,可以使用 ELSER 模型。
语义搜索根据上下文含义和用户意图提供搜索结果,而不是仅仅匹配关键词。
E5 有两个版本:
-
跨平台版本:可在任何硬件上运行
-
Intel® 硅优化版本:针对 Intel 硬件优化
在 Model Management > Trained Models 页面上,可以查看根据集群硬件推荐部署的 E5 版本。不过,推荐的使用方式是通过 inference API 作为服务 使用 E5,这样可以更方便地下载和部署模型,无需手动选择不同版本。
如需更多信息,包括许可说明,可以参考 HuggingFace 上的 multilingual-e5-small 和 multilingual-e5-small-optimized 模型卡。
要求
要使用 E5,你必须拥有用于 semantic search 的相应订阅等级或已激活试用期。
建议为你的 E5 部署启用 trained model autoscaling。参考 Trained model autoscaling 了解更多信息。
下载并部署 E5
下载并部署 E5 最简单且推荐的方式是使用 inference API。
1)在 Kibana 中,进入 Dev Console。
2)通过运行以下 API 请求,使用 elasticsearch 服务创建一个 inference endpoint:
bash
`
1. PUT _inference/text_embedding/my-e5-model
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "num_allocations": 1,
6. "num_threads": 1,
7. "model_id": ".multilingual-e5-small"
8. }
9. }
`AI写代码该 API 请求会自动启动模型下载,然后部署模型。
参考 elasticsearch inference service 文档了解可用设置的更多信息。
在创建 E5 inference endpoint 后,它即可用于 semantic search。在 Elastic Stack 中执行 semantic search 最简单的方法是遵循 semantic_text workflow。
下载并部署 E5 的替代方法
你也可以从 Trained models 页面、Search > Indices,或通过在 Dev Console 中使用 trained models API 下载并部署 E5 模型。
注意:在大多数情况下,推荐使用针对 Intel 和 Linux 优化的模型,建议下载并部署该版本。
使用 Trained Models 页面进行下载
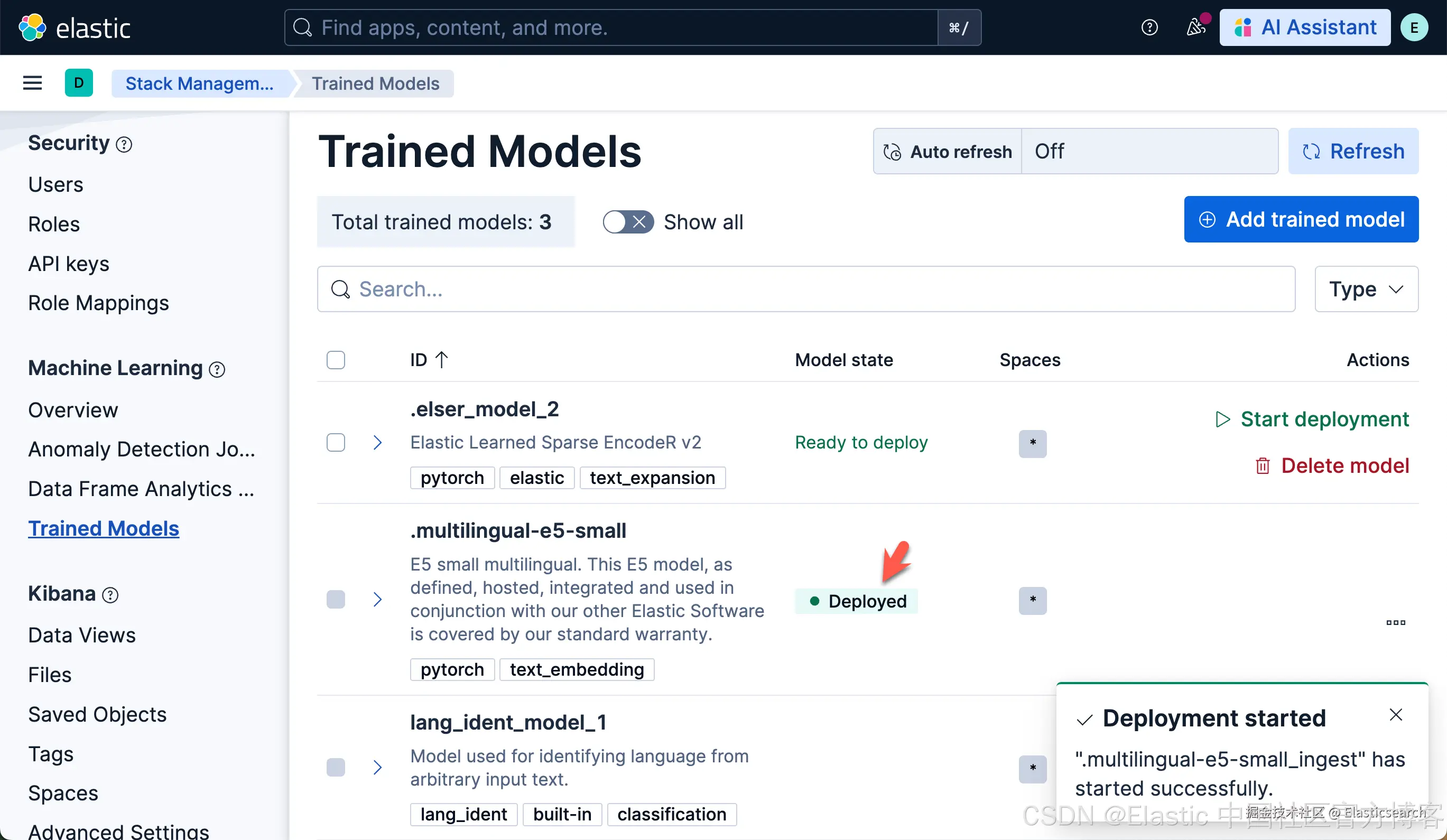
我们可以使用如下的命令来卸载已经安装好的模型:
ini
`DELETE _ml/trained_models/.multilingual-e5-small?force=true`AI写代码一旦被卸载,就会恢复到之前的样子:
在 Dev Console 中使用 trained models API
1)在 Kibana 中,进入 Dev Console。
2)通过运行以下 API 调用创建 E5 模型配置:
markdown
`
1. PUT _ml/trained_models/.multilingual-e5-small
2. {
3. "input": {
4. "field_names": [
5. "text_field"
6. ]
7. }
8. }
`AI写代码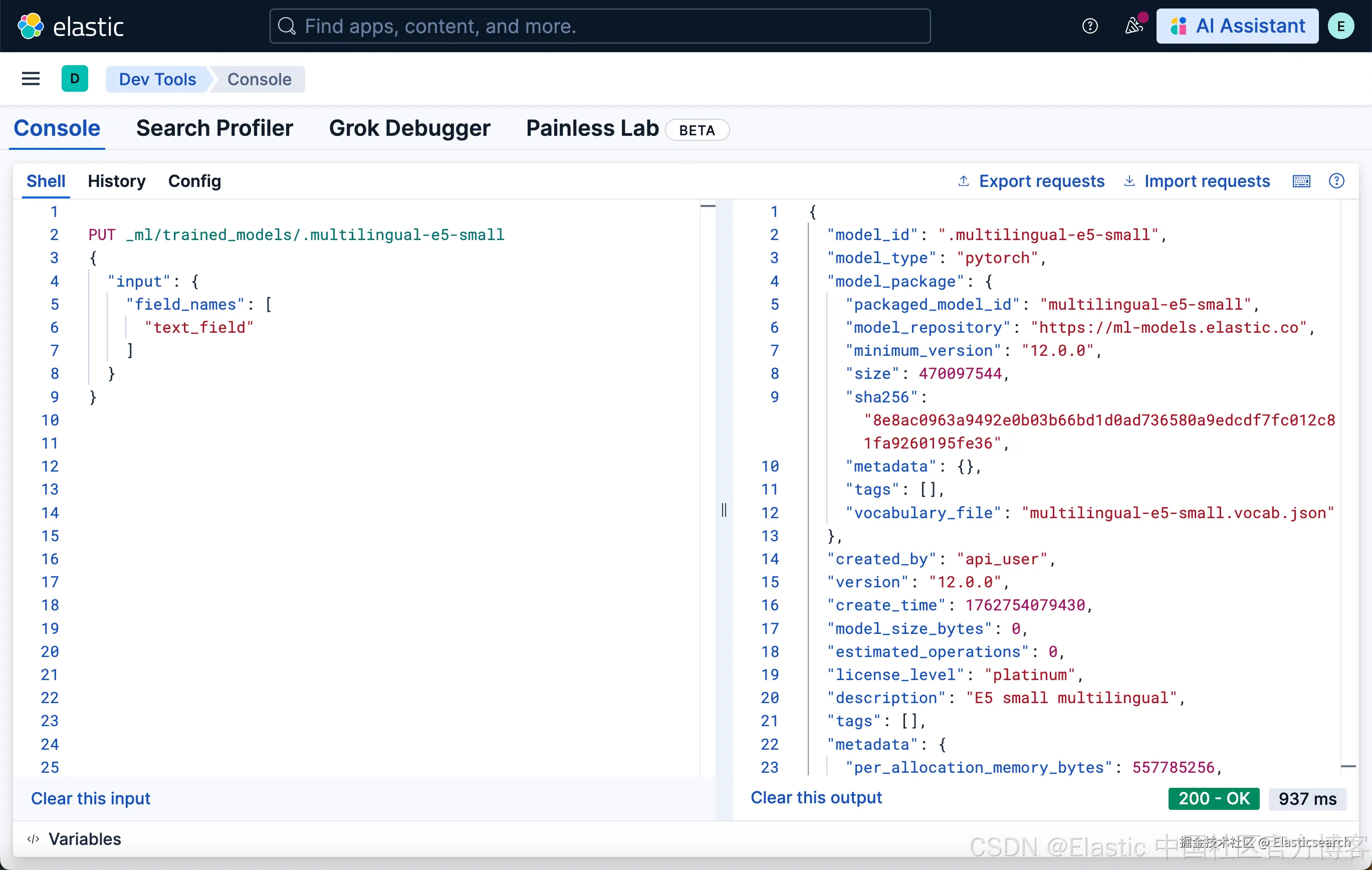
如果模型尚未下载,该 API 调用会自动启动模型下载。
3)使用 start trained model deployment API 并提供 deployment ID 来部署模型:
bash
`POST _ml/trained_models/.multilingual-e5-small/deployment/_start?deployment_id=for_search`AI写代码在隔离环境中部署 E5 模型
如果你想在隔离环境中安装 E5,你有以下选项:
-
将模型文件放入所有 master-eligible 节点 config 目录内的某个目录中(适用于 multilingual-e5-small 和 multilingual-e5-small-linux-x86-64)
-
使用 HuggingFace 安装模型(仅适用于 multilingual-e5-small 模型)
模型文件
对于 multilingual-e5-small 模型,你的系统中需要以下文件:
arduino
`
1. https://ml-models.elastic.co/multilingual-e5-small.metadata.json
2. https://ml-models.elastic.co/multilingual-e5-small.pt
3. https://ml-models.elastic.co/multilingual-e5-small.vocab.json
`AI写代码对于优化版本,你的系统中需要以下文件:
arduino
`
1. https://ml-models.elastic.co/multilingual-e5-small_linux-x86_64.metadata.json
2. https://ml-models.elastic.co/multilingual-e5-small_linux-x86_64.pt
3. https://ml-models.elastic.co/multilingual-e5-small_linux-x86_64.vocab.json
`AI写代码使用基于文件的访问
对于基于文件的访问,请按照以下步骤操作:
-
下载模型文件。
-
将文件放入 Elasticsearch 部署的 config 目录下的 models 子目录中。
-
通过在 config/elasticsearch.yml 文件中添加以下行,将你的 Elasticsearch 部署指向模型目录:
bash`xpack.ml.model_repository: file://${path.home}/config/models/`AI写代码 -
在所有 master-eligible 节点重复步骤 2 和步骤 3。
-
逐一重启 master-eligible 节点。
-
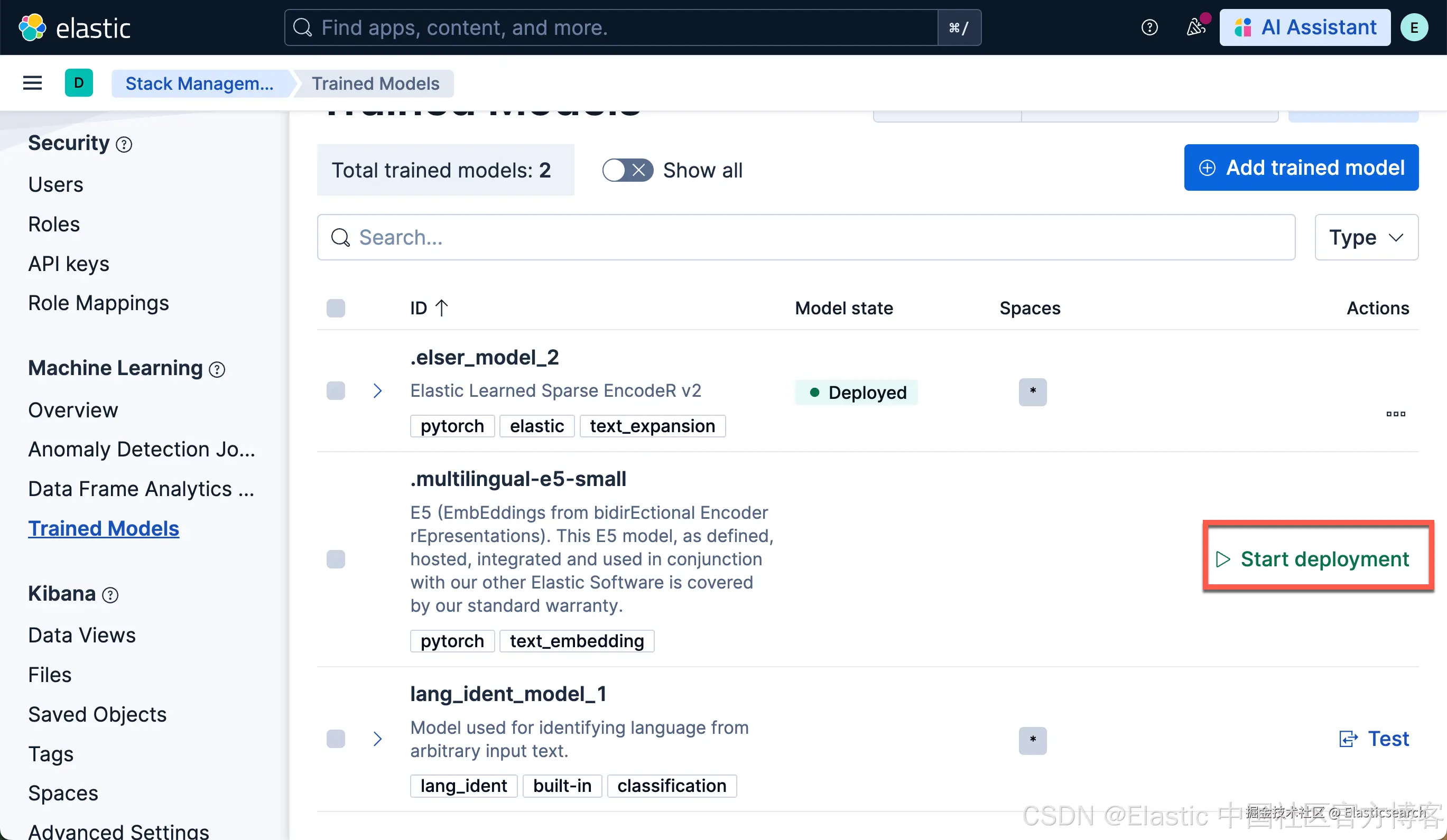
从主菜单进入 Trained Models 页面,或使用 Kibana 的全局搜索字段。你可以在训练模型列表中找到 E5。
-
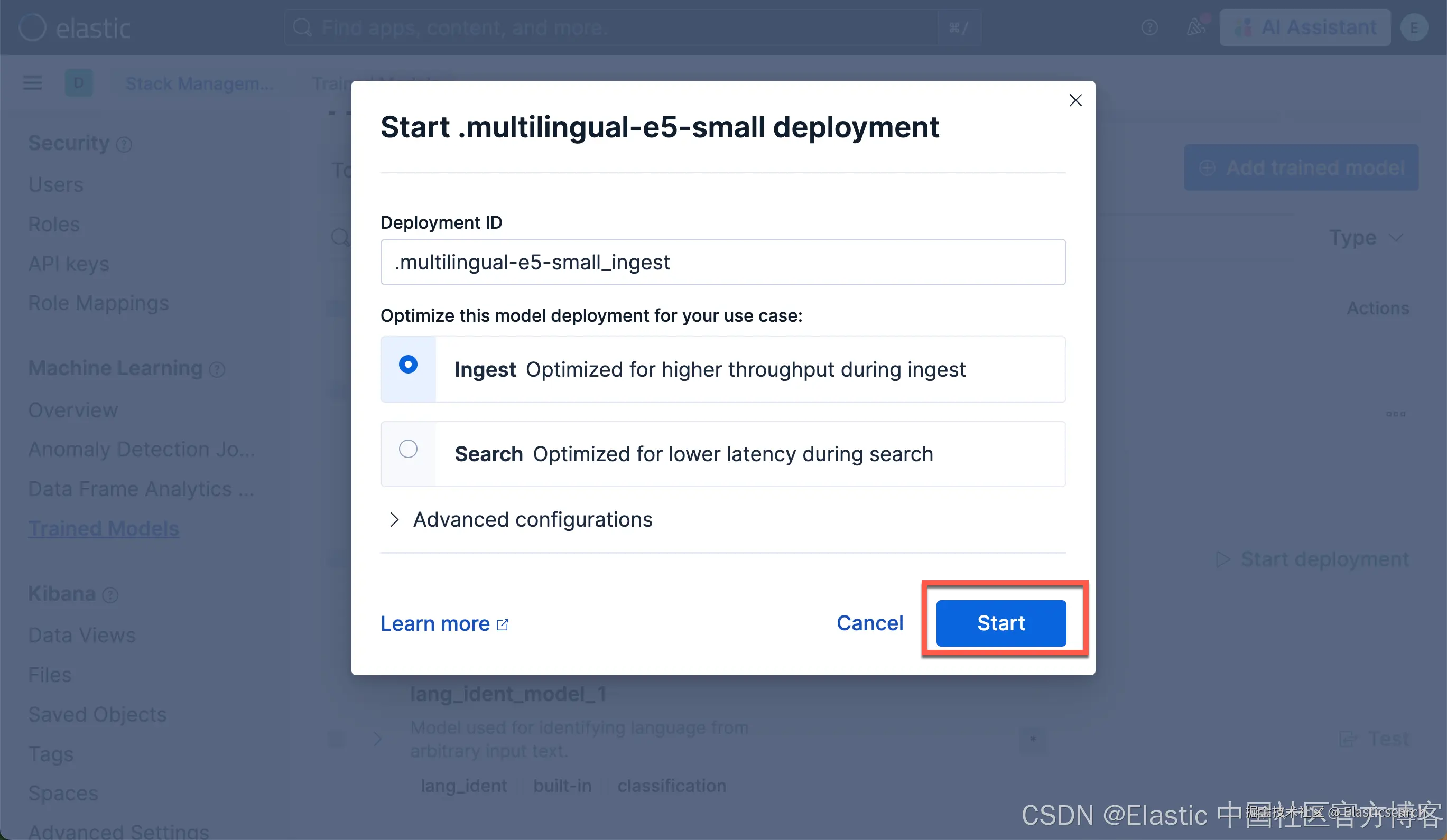
点击 Add trained model 按钮,选择你在步骤 1 下载并想要部署的 E5 模型版本,然后点击 Download。所选模型将从你在步骤 2 放置的模型目录中下载。
-
下载完成后,点击 Start deployment 按钮启动部署。
-
提供 deployment ID,选择优先级,并设置每个分配的 allocation 数量和线程数。
-
点击 Start。
使用 HuggingFace 仓库
你可以通过将 eland_import_hub_model 脚本指向模型的本地文件,在受限或封闭网络中安装 multilingual-e5-small 模型。
对于离线安装,模型需要先在本地克隆,你的系统中需要安装 Git 和 Git Large File Storage。
1)使用模型 URL 从 Hugging Face 克隆 E5 模型。
bash
`git clone https://huggingface.co/intfloat/multilingual-e5-small`AI写代码该命令会在 multilingual-e5-small 目录中生成模型的本地副本。
2)使用 eland_import_hub_model 脚本,并将 --hub-model-id 设置为克隆模型的目录来安装它:
css
`
1. eland_import_hub_model \
2. --url 'XXXX' \
3. --hub-model-id /PATH/TO/MODEL \
4. --task-type text_embedding \
5. --es-username elastic --es-password XXX \
6. --es-model-id multilingual-e5-small
`AI写代码如果你使用 Docker 镜像运行 eland_import_hub_model,必须绑定挂载模型目录,以便容器可以读取文件。
bash
`
1. docker run --mount type=bind,source=/PATH/TO/MODELS,destination=/models,readonly -it --rm docker.elastic.co/eland/eland \
2. eland_import_hub_model \
3. --url 'XXXX' \
4. --hub-model-id /models/multilingual-e5-small \
5. --task-type text_embedding \
6. --es-username elastic --es-password XXX \
7. --es-model-id multilingual-e5-small
`AI写代码一旦上传到 Elasticsearch,模型将使用 --es-model-id 指定的 ID。如果未设置,则模型 ID 将从 --hub-model-id 推导;空格和路径分隔符会被转换为双下划线 __。
免责声明
客户可以将第三方训练模型添加到 Elastic 进行管理。这些模型不属于 Elastic。虽然 Elastic 会根据文档支持与这些模型的集成性能,但你理解并同意 Elastic 对第三方模型或它们可能使用的底层训练数据不拥有控制权,也不承担任何责任。
本 E5 模型,如定义、托管、集成并与我们的其他 Elastic 软件一起使用,受我们的标准保修覆盖。