1、发布历程
- 2025/10/23🚀🚀🚀 DeepSeek-OCR 现已正式在上游vLLM中得到支持。
- 2025/10/20🚀🚀🚀 我们发布了 DeepSeek-OCR,这是一个从 LLM 中心视角研究视觉编码器作用的模型。
🌐 相关链接
- Github: https://github.com/deepseek-ai/DeepSeek-OCR/tree/main
- 论文 PDF: DeepSeek_OCR_paper.pdf
- arxiv论文链接:https://arxiv.org/abs/2510.18234
- Huggingface: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- 原文链接 :https://www.yuque.com/lhyyh/ai/stk5rlh8mes42e20
2、介绍
2.1 简介
2025年10月20日,DeepSeek-OCR 是由 deepseek-ai 团队开发的一个先进的图像到文本(Image-Text-to-Text)模型。该项目的核心理念是 "上下文光学压缩(Contexts Optical Compression) ",旨在探索视觉-文本压缩技术的前沿。
作为一个多语言(multilingual)模型,DeepSeek-OCR 能够处理包含图像和文本提示的输入,并生成相应的文本输出。根据其模型卡信息,该项目基于 MIT 许可证开源,模型参数量为 30亿(3B),其研究成果已发表在 arXiv 论文DeepSeek-OCR: Contexts Optical Compression (arXiv:2510.18234) 中。该项目在其致谢部分提到了多个有价值的模型和思想来源,包括 Vary、GOT-OCR2.0、MinerU、PaddleOCR 等,这表明它是在借鉴和融合社区现有优秀成果的基础上进行的创新。
2.2 技术范式转变:从字符识别到视觉理解
DeepSeek-OCR与传统OCR的根本区别在于,它放弃了传统的"逐字识别"范式 ,转而采用**"** 全局视觉理解-特征压缩-语义解码" 的全新路径。传统OCR基于字符级拆解,需要将每个字符单独分割处理,导致token消耗过高、显存占用大等问题。
2.3 核心压缩原理:光学上下文压缩技术
2.3.1 视觉token替代文本token
DeepSeek-OCR的核心创新是**"** 光学上下文压缩技术 "。其基本思路是:将文本信息转换为图像形式,利用"一图胜千言"的特性,用少量视觉token来表示大量文本信息(在长上下文领域有极高研究价值)。
🔬 实验证明
-
当压缩比小于
10倍时(即文本token数是视觉token数的10倍以内),模型解码准确率高达97%; -
即使在
20倍压缩率下,准确率仍保持在60%左右。
2.3.2 双核架构设计
DeepSeek-OCR由两个核心组件构成:
- DeepEncoder视觉编码模块
- 采用串联设计:SAM-base(局部特征提取)→ 16倍卷积压缩器 → CLIP-large(全局理解)
- 能够将1024×1024像素的文档图像从4096个特征区块压缩至256个视觉token
- 根据文档复杂度自适应调整压缩策略,实现效率与精度的动态平衡
- DeepSeek-3B-MoE语义解码模块
- 采用混合专家模型架构,总参数量30亿,每次推理仅激活5.7亿参数
- 负责从压缩后的视觉token中重建原始文本
2.3.3 技术优势与局限性
- 实际效能:在具体应用中,单张A100显卡每日可处理超过20万页文档,显存占用量比传统方法降低93.3%,处理速度提升3.2倍。
- 客观局限性
- 在超高压缩比(超过30倍)时,关键信息保留率会显著下降
- 对潦草手写体、低分辨率图像(≤50dpi)等极端场景的适应性仍有待提升
- 复杂格式的精确还原能力有限
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 
 |
| 
 |
|
| 
 |
| 
 |
|
3、特点
DeepSeek-OCR 的主要特点可以归纳如下:
-
先进的模型架构:
它采用
Image-Text-to-Text架构,使其不仅仅是一个简单的 OCR 工具,而是一个能够理解上下文提示并执行复杂任务(如根据指令将文档转换为 Markdown)的视觉语言模型。核心在于其 "上下文光学压缩" 技术,旨在高效地处理和压缩视觉文本信息。
-
多样的配置模式
:模型提供了多种预设的推理配置,以适应不同的硬件和性能需求,用户可以通过调整
base_size, image_size, crop_mode等参数来选择:
-
-
Tiny:
base_size = 512, image_size = 512, crop_mode = False
-
Small:
base_size = 640, image_size = 640, crop_mode = False
-
Base:
base_size = 1024, image_size = 1024, crop_mode = False
-
Large:
base_size = 1280, image_size = 1280, crop_mode = False
-
Gundam:
base_size = 1024, image_size = 640, crop_mode = True(此模式启用了图像裁剪,可能适用于特定场景)
-
-
高性能推理支持
支持使用
flash_attention_2进行注意力计算加速。已获得vLLM的官方上游支持,可以利用 vLLM 框架进行高效的模型推理加速和批量处理。
- 高级推理控制:
- 在 vLLM 中使用时,支持
NGramPerReqLogitsProcessor逻辑处理器。这允许用户通过设置n-gram参数(如 ngram_size, window_size)和白名单 token(whitelist_token_ids)来更精细地控制生成文本的格式和内容,例如在生成表格时强制输出<td>标签。
4、安装部署与推理
4.1 安装
我们的环境是 cuda11.8+torch2.6.0。
- 克隆此存储库并导航至 DeepSeek-OCR 文件夹
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
-
conda
conda create -n deepseek-ocr python=3.12.9 -yconda activate deepseek-ocr
-
Packages
-
下载 vllm-0.8.5whl
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whlpip install -r requirements.txtpip install flash-attn==2.7.3 --no-build-isolation
注意: 如果您希望 vLLM 和 transformers 代码在同一环境下运行,则无需担心类似这样的安装错误:vllm 0.8.5+cu118 需要 transformers>=4.51.1
4.2 vLLM推理
注意:请修改 DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py 文件中的INPUT_PATH/OUTPUT_PATH 和其他设置。
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm# 图像:流输出python run_dpsk_ocr_image.py# pdf:并发量约为 2500tokens/s(A100-40G)python run_dpsk_ocr_pdf.py# 基准测试的批量评估python run_dpsk_ocr_eval_batch.py2025/10/23 上游vLLM 的版本 :
uv venvsource .venv/bin/activate# Until v0.11.1 release, you need to install vLLM from nightly builduv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
from vllm import LLM, SamplingParamsfrom vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessorfrom PIL import Image# Create model instancellm = LLM( model="deepseek-ai/DeepSeek-OCR", enable_prefix_caching=False, mm_processor_cache_gb=0, logits_processors=[NGramPerReqLogitsProcessor])# Prepare batched input with your image fileimage_1 = Image.open("path/to/your/image_1.png").convert("RGB")image_2 = Image.open("path/to/your/image_2.png").convert("RGB")prompt = "<image>\nFree OCR."model_input = [ { "prompt": prompt, "multi_modal_data": {"image": image_1} }, { "prompt": prompt, "multi_modal_data": {"image": image_2} }]sampling_param = SamplingParams( temperature=0.0, max_tokens=8192, # ngram logit processor args extra_args=dict( ngram_size=30, window_size=90, whitelist_token_ids={128821, 128822}, # whitelist: <td>, </td> ), skip_special_tokens=False,)# Generate outputmodel_outputs = llm.generate(model_input, sampling_param)# Print outputfor output in model_outputs: print(output.outputs[0].text)4.3 Transformers-推理
-
Transformers
from transformers import AutoModel, AutoTokenizerimport torchimport osos.environ["CUDA_VISIBLE_DEVICES"] = '0'model_name = 'deepseek-ai/DeepSeek-OCR'tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)model = model.eval().cuda().to(torch.bfloat16)# prompt = "
\nFree OCR. "prompt = " \n<|grounding|>Convert the document to markdown. "image_file = 'your_image.jpg'output_path = 'your/output/dir'res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
或者你可以
cd DeepSeek-OCR-master/DeepSeek-OCR-hfpython run_dpsk_ocr.py4.4 支持模式
当前开源模型支持以下几种模式:
- 原始分辨率:
-
- Tiny: 512×512 (64 vision tokens)✅
- Small: 640×640 (100 vision tokens)✅
- Base: 1024×1024 (256 vision tokens)✅
- Large: 1280×1280 (400 vision tokens)✅
- 动态分辨率
-
- Gundam: n×640×640 + 1×1024×1024 ✅
4.5 提示示例
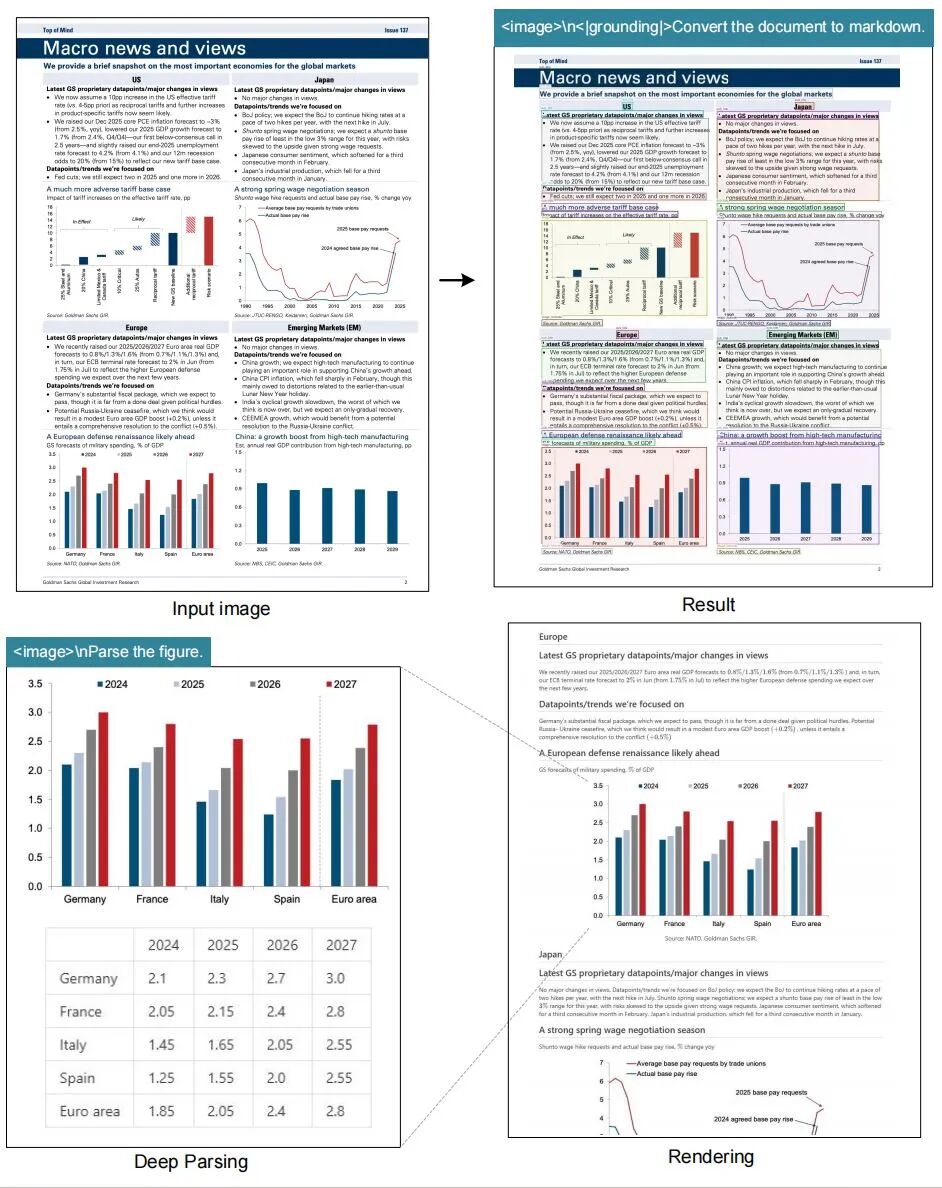
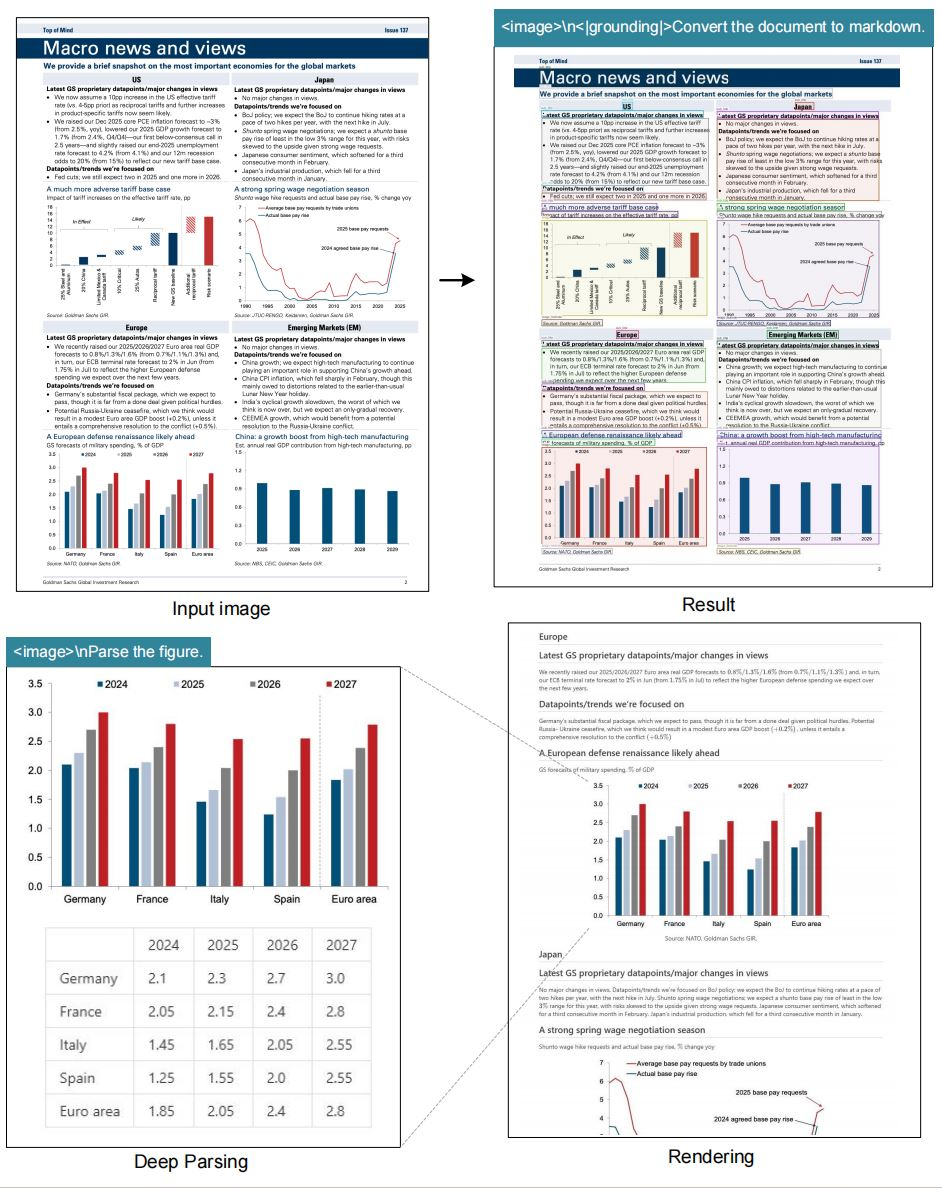
# document: <image>\n<|grounding|>Convert the document to markdown.# other image: <image>\n<|grounding|>OCR this image.# without layouts: <image>\nFree OCR.# figures in document: <image>\nParse the figure.# general: <image>\nDescribe this image in detail.# rec: <image>\nLocate <|ref|>xxxx<|/ref|> in the image.# '先天下之忧而忧'更多推荐
-
AI 工具集导航:https://tools.lhagi.com/
-
AI 大模型全栈 50 万字知识库:https://www.yuque.com/lhyyh/ai
3 年打磨,全是精华,从普通职场人士到大模型算法,应有尽有!