卡尔曼滤波新手入门指南
您可以把卡尔曼滤波想象成它在持续做三件大事:
【预测】凭经验猜一下
关键点:有一个"运动模型"
白话: 根据物体上一秒的状态(位置、速度),结合物理规律(比如它在匀速飞行),预测出它当前最可能处在什么状态。"按道理,它现在应该飞到这里了。"
【更新】用测量值修正一下
关键点:信任但不迷信测量
白话: 这时传感器报了一个数据回来(比如GPS说位置在那里)。卡尔曼滤波不会全盘接受这个数据,因为它知道传感器有误差。它会将 "预测值" 和 "测量值" 拿过来对比。
【融合】聪明地加权平均
关键点:动态计算"卡尔曼增益"
白话: 这是它最聪明的地方。它会自动判断此刻更应该相信预测还是相信测量:
如果预测很准(比如飞机飞得很平稳),它就更相信预测。
如果测量很准(比如GPS信号极好),它就更相信测量。
最终输出结果 = 预测值 + 增益 × (测量值 - 预测值)
这个"增益"就是一个自适应的权重,是整个算法的核心智慧。
总结一下这个循环就是:
预测 -> 测量 -> 对比 -> 智能融合 -> 输出最优结果 -> 接着预测...
什么是卡尔曼滤波?
卡尔曼滤波(Kalman Filter)是一种在存在不确定性的情况下对系统状态进行估计和预测的强大工具。 它的核心思想是通过数据融合的方法,结合预测值和测量值,得到更准确的观测结果。
核心思想
卡尔曼滤波的关键在于:当你有一个带噪声的测量值时,不要完全相信它;当你有一个预测值时,也不要完全相信它。而是要找到一个最优的平衡点。
想象一下:你在黑暗中用手电筒照一个移动的小球。手电筒的光斑(测量值)会晃动,你对小球运动的预测(预测值)也可能不准确。卡尔曼滤波就是帮你找到最可能的小球位置。
基本原理(简化版)
卡尔曼滤波主要包含两个步骤:预测 和更新。
- 预测阶段:基于系统模型,预测下一时刻的状态
- 更新阶段:当获得新的测量值时,用它来修正预测值
卡尔曼滤波通过一个叫做"卡尔曼增益"的参数来决定:在多大程度上信任新的测量值,而不是之前的预测值。
为什么需要卡尔曼滤波?
在现实世界中,我们的传感器测量总是包含噪声,而我们的系统模型也总有误差。卡尔曼滤波能够:
- 消除抖动的检测结果,产生更稳定的跟踪路径
- 处理遮挡情况(比如目标暂时消失)
- 融合来自多个传感器的数据,提高整体精度
应用领域
卡尔曼滤波应用极为广泛,包括:
- 导航与定位:GPS导航、自动驾驶、飞机及太空船的导引
- 目标跟踪:雷达系统、计算机视觉中的物体追踪
- 控制系统:机器人控制、工业自动化
- 信号处理:时间序列分析、语音处理、图像处理(人脸识别、图像分割等)
- 传感器数据融合:将多个传感器的数据结合起来获得更准确的结果
优缺点
优点:
- 计算效率高,适合实时系统
- 能够处理噪声数据
- 理论基础扎实
缺点:
- 对系统模型的假设比较敏感,如果模型不准确,效果会变差
- 要求系统是线性的(标准卡尔曼滤波),非线性系统需要扩展版本
Python案例
下面是一个简单的卡尔曼滤波Python代码示例,模拟跟踪一个在1D空间中移动的物体。代码包含详细注释,适合新手理解:
python
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以便结果可重现
np.random.seed(42)
# 模拟参数
n_steps = 50 # 模拟步数
true_position = 0.0 # 真实初始位置
true_velocity = 1.0 # 真实速度(恒定)
measurement_noise = 1.0 # 测量噪声标准差
process_noise = 0.1 # 过程噪声标准差
# 生成真实轨迹和带噪声的测量值
true_positions = []
measurements = []
for i in range(n_steps):
# 真实位置(匀速运动)
true_position += true_velocity * 0.1 # 时间步长为0.1
true_positions.append(true_position)
# 带噪声的测量值
noisy_measurement = true_position + np.random.normal(0, measurement_noise)
measurements.append(noisy_measurement)
# 卡尔曼滤波器实现
class KalmanFilter1D:
def __init__(self):
# 状态向量: [位置, 速度]
self.x = np.array([0.0, 0.0]) # 初始状态估计
# 状态协方差矩阵
self.P = np.array([[1.0, 0.0], # 位置方差
[0.0, 1.0]]) # 速度方差
# 状态转移矩阵 (匀速运动模型)
self.F = np.array([[1.0, 0.1], # 位置 = 位置 + 速度 * Δt
[0.0, 1.0]]) # 速度保持不变
# 测量矩阵 (只测量位置)
self.H = np.array([[1.0, 0.0]])
# 过程噪声协方差
self.Q = np.array([[0.1, 0.0],
[0.0, 0.1]]) * process_noise**2
# 测量噪声协方差
self.R = np.array([[measurement_noise**2]])
def predict(self):
"""预测步骤"""
# 状态预测: x = F * x
self.x = self.F @ self.x
# 协方差预测: P = F * P * F^T + Q
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x[0] # 返回预测的位置
def update(self, measurement):
"""更新步骤"""
# 计算卡尔曼增益: K = P * H^T * (H * P * H^T + R)^-1
S = self.H @ self.P @ self.H.T + self.R
K = self.P @ self.H.T @ np.linalg.inv(S)
# 状态更新: x = x + K * (z - H * x)
y = measurement - self.H @ self.x # 测量残差
self.x = self.x + K @ y
# 协方差更新: P = (I - K * H) * P
I = np.eye(2)
self.P = (I - K @ self.H) @ self.P
return self.x[0] # 返回更新后的位置
# 创建卡尔曼滤波器实例
kf = KalmanFilter1D()
# 存储滤波结果
filtered_positions = []
filtered_velocities = []
# 运行卡尔曼滤波
for i in range(n_steps):
# 预测步骤
kf.predict()
# 更新步骤
filtered_pos = kf.update(measurements[i])
# 保存结果
filtered_positions.append(filtered_pos)
filtered_velocities.append(kf.x[1])
# 可视化结果
plt.figure(figsize=(12, 8))
# 位置跟踪图
plt.subplot(2, 1, 1)
plt.plot(range(n_steps), true_positions, 'g-', linewidth=2, label='真实位置')
plt.plot(range(n_steps), measurements, 'r.', markersize=8, alpha=0.6, label='测量值 (带噪声)')
plt.plot(range(n_steps), filtered_positions, 'b-', linewidth=3, label='卡尔曼滤波估计')
plt.title('卡尔曼滤波 - 1D位置跟踪', fontsize=14)
plt.xlabel('时间步', fontsize=12)
plt.ylabel('位置', fontsize=12)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
# 速度估计图
plt.subplot(2, 1, 2)
plt.plot(range(n_steps), [true_velocity] * n_steps, 'g-', linewidth=2, label='真实速度')
plt.plot(range(n_steps), filtered_velocities, 'b-', linewidth=3, label='卡尔曼滤波估计速度')
plt.title('速度估计', fontsize=14)
plt.xlabel('时间步', fontsize=12)
plt.ylabel('速度', fontsize=12)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 打印最终结果
print("=== 卡尔曼滤波结果总结 ===")
print(f"最终真实位置: {true_positions[-1]:.2f}")
print(f"最终测量值: {measurements[-1]:.2f}")
print(f"最终估计位置: {filtered_positions[-1]:.2f}")
print(f"最终估计速度: {filtered_velocities[-1]:.2f}")
print(f"位置估计误差: {abs(filtered_positions[-1] - true_positions[-1]):.4f}")
# 计算均方根误差
rmse = np.sqrt(np.mean((np.array(filtered_positions) - np.array(true_positions))**2))
print(f"位置估计RMSE: {rmse:.4f}")代码说明:
1. 模拟场景
- 模拟一个在1D空间中以恒定速度移动的物体
- 生成带高斯噪声的测量值
- 真实运动是匀速直线运动
2. 卡尔曼滤波器类
- 状态向量 :
[位置, 速度] - 预测步骤: 基于物理模型预测下一状态
- 更新步骤: 用测量值修正预测结果
- 卡尔曼增益: 自动平衡预测和测量的权重
3. 关键参数
- F (状态转移矩阵): 描述系统如何随时间演化
- H (测量矩阵): 将状态映射到测量空间
- Q (过程噪声): 模型不确定性
- R (测量噪声): 传感器不确定性
- P (协方差矩阵): 估计的不确定性
4. 可视化
- 上图:位置跟踪效果对比
- 下图:速度估计效果
- 绿色:真实值
- 红色:带噪声的测量值
- 蓝色:卡尔曼滤波估计值
5. 新手学习要点
- 卡尔曼增益是核心:它自动决定信任预测还是测量
- 不确定性传播:协方差矩阵P跟踪估计的可靠性
- 数据融合:结合模型预测和实际测量
- 递归算法:每一步只依赖前一步结果,计算效率高
运行这段代码,你会看到卡尔曼滤波器如何有效地从噪声数据中恢复出平滑的轨迹,并准确估计速度。这是理解卡尔曼滤波工作原理的绝佳起点!
数学理解
卡尔曼滤波的5个公式
假设我们要研究的对象是一个房间的温度,首先,我们先要引入一个离散控制过程的系统。该系统可用一个线性随机微分方程来描述:
X(k)=A X(k-1)+B U(k)+W(k)
再加上系统的测量值:
Z(k)=H X(k)+V(k)
上面两式子中,X(k)是k时刻的系统状态,U(k)是k时刻对系统的控制量。A和B是系统参数,对于多模型系统,他们为矩阵。Z(k)是k时刻的测量值,H是测量系统的参数,对于多测量系统,H为矩阵。W(k)和V(k)分别表示过程和测量的噪声,他们被假设成高斯白噪声,他们的协方差分别是Q,R(这里我们假设他们不随系统状态变化而变化)。
X(k|k-1)=A X(k-1|k-1)+B U(k) ...... (1)
P(k|k-1)=A P(k-1|k-1) A'+Q ............ (2)
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-H X(k|k-1)) ............ (3)
Kg(k)= P(k|k-1) H' / (H P(k|k-1) H' + R) ............. (4)
P(k|k)=(I-Kg(k) H)P(k|k-1) ...... (5)
式(1)中,X(k|k-1)是利用上一状态预测的结果,X(k-1|k-1)是上一状态最优的结果,U(k)为现在状态的控制量,如果没有控制量,它可以为0。
到现在为止,我们的系统结果已经更新了,可是,对应于X(k|k-1)的协方差还没更新。
我们用P表示协方差,式(2)中,P(k|k-1)是X(k|k-1)对应的协方差,P(k-1|k-1)是X(k-1|k-1)对应的协方差,A'表示A的转置矩阵,Q是系统过程的协方差。式子1,2就是卡尔曼滤波器5个公式当中的前两个,也就是对系统的预测。
现在我们有了现在状态的预测结果,然后我们再收集现在状态的测量值。结合预测值和测量值,我们可以得到现在状态(k)的最优化估算值X(k|k)。
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-H X(k|k-1))
其中Kg为卡尔曼增益,到现在为止,我们已经得到了k状态下最优的估算值X(k|k)。但是为了要令卡尔曼滤波器不断的运行下去直到系统过程结束,我们还要更新k状态下X(k|k)的协方差。
Kg(k)= P(k|k-1) H' / (H P(k|k-1) H' + R)
P(k|k)=(I-Kg(k) H)P(k|k-1)
其中I 为1的矩阵,对于单模型单测量,I=1。当系统进入k+1状态时,P(k|k)就是式子(2)的P(k-1|k-1)。这样,算法就可以自回归地运算下去。
卡尔曼滤波器的原理基本描述了,式子1,2,3,4和5就是他的5 个基本公式。根据这5个公式,可以很容易用计算机编程实现。
通过观察可以发现:W(k)和V(k)分别表示过程和测量的误差,误差是独立存在的,误差不受数据的影响。误差按照统计学的协方差公式更新,跟数据无关,而且误差是不断变化的。
卡尔曼滤波的基本原理
5个核心方程(简化版)
预测阶段(先预测,再测量)
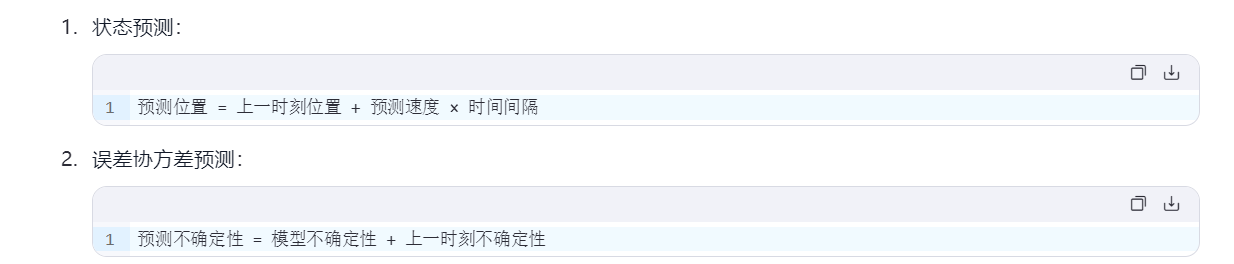
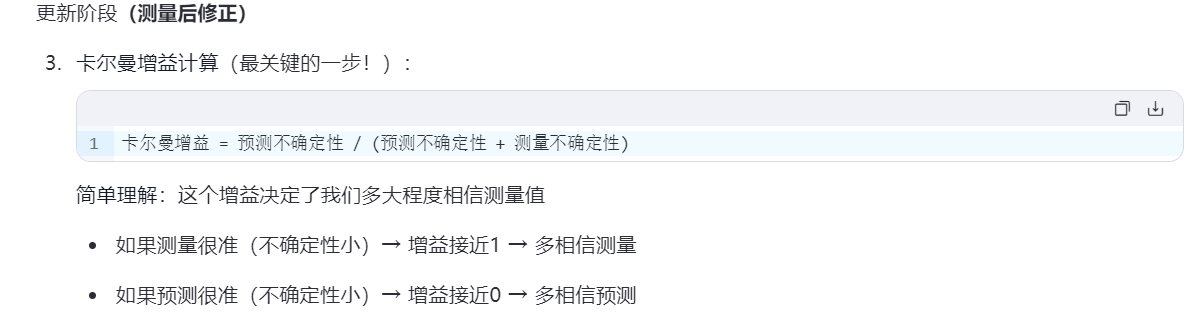
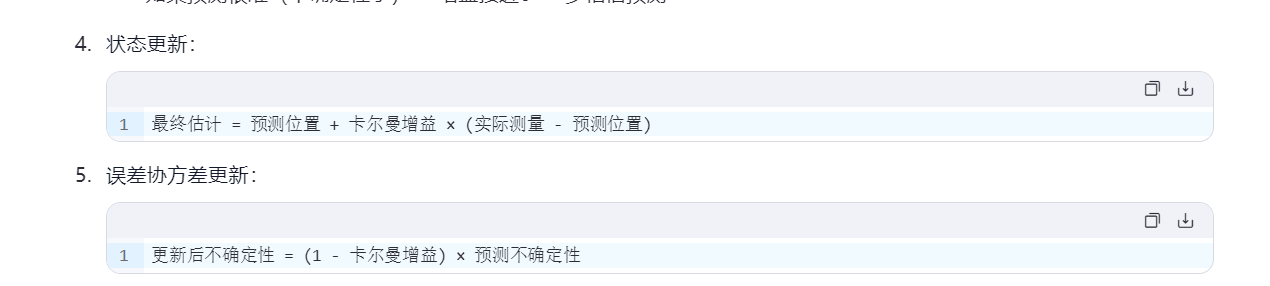
虽然卡尔曼滤波器在许多领域都有广泛的应用,但它也有一些缺点。以下是一些可能的问题:
对模型假设的敏感性:卡尔曼滤波器依赖于对系统的数学模型,如果模型不准确或存在偏差,那么滤波器的性能可能会受到影响。
计算复杂性:对于高维度的系统,卡尔曼滤波器的计算量可能会变得很大,需要更快的处理器或更高效的算法。
收敛速度:对于某些系统,卡尔曼滤波器可能需要很长的时间才能收敛到真实的状态,这会影响到实时应用的效果。
稳定性问题:在某些情况下,卡尔曼滤波器可能会变得不稳定,产生振荡或发散的情况。
初值选择依赖:卡尔曼滤波器的性能对初值的选择很敏感,如果初值选择不当,可能会导致滤波器性能不佳。
难以处理非线性系统:虽然有非线性卡尔曼滤波器(如扩展卡尔曼滤波器),但它们可能仍然不适合处理高度非线性的系统。
对噪声假设的敏感性:卡尔曼滤波器对系统噪声和测量噪声的假设很敏感,如果这些假设不准确,可能会导致滤波器的性能下降。
尽管存在这些缺点,但卡尔曼滤波器在许多领域中仍然是一种非常有用的工具。随着新的技术和算法的发展,这些问题可能会得到解决或缓解。
详细介绍一下P是由Q和R确定的吗?
非常好的问题!让我们详细探讨卡尔曼滤波中的 P矩阵 (状态协方差矩阵)以及它与 Q (过程噪声协方差)和 R(测量噪声协方差)的关系。
1. P矩阵的本质
P矩阵 是卡尔曼滤波中最核心的概念之一,它表示:
- 状态估计的不确定性:P矩阵的对角线元素表示各个状态变量的方差(不确定性大小)
- 状态变量之间的相关性:非对角线元素表示不同状态变量之间的协方差
在二维位置-速度的例子中:
python
P = [[P_xx, P_xv], # P_xx: 位置的方差
[P_vx, P_vv]] # P_vv: 速度的方差
# P_xv, P_vx: 位置和速度的协方差2. P矩阵的演化过程
P矩阵不是静态的,而是通过卡尔曼滤波的两个步骤动态演化:
预测步骤(时间更新):
python
P_pred = F @ P_prev @ F.T + Q- F @ P_prev @ F.T:状态转移带来的不确定性传播
- + Q:过程噪声引入的额外不确定性
更新步骤(测量更新):
python
K = P_pred @ H.T @ np.linalg.inv(H @ P_pred @ H.T + R)
P_new = (I - K @ H) @ P_pred- 卡尔曼增益K:决定了测量信息对状态估计的修正程度
- (I - K @ H) @ P_pred:测量更新后减少的不确定性
3. Q和R对P的影响
Q矩阵(过程噪声协方差)的影响:
- Q越大 → 预测步骤中P增长越快 → 算法更信任测量值
- Q越小 → 预测步骤中P增长越慢 → 算法更信任模型预测
python
# Q矩阵的例子(二维系统)
Q = np.array([
[0.1, 0.0], # 位置的过程噪声方差
[0.0, 0.1] # 速度的过程噪声方差
])R矩阵(测量噪声协方差)的影响:
- R越大 → 卡尔曼增益K越小 → 算法更信任预测值
- R越小 → 卡尔曼增益K越大 → 算法更信任测量值
python
# R矩阵的例子(只测量位置)
R = np.array([[1.0]]) # 测量噪声方差4. P矩阵的初始值设定
P矩阵不是完全由Q和R确定的,它还依赖于:
4.1 初始协方差 P₀
python
P = np.array([
[10.0, 0.0], # 初始位置不确定性很大
[0.0, 10.0] # 初始速度不确定性很大
])- 初始值通常根据对系统的先验知识设定
- 如果初始状态很不确定,P₀应该设得大一些
- 如果初始状态很确定,P₀应该设得小一些
4.2 系统动态特性(F矩阵)
python
F = np.array([
[1.0, dt], # 位置 = 位置 + 速度 * dt
[0.0, 1.0] # 速度保持不变
])- F矩阵决定了不确定性如何随时间传播
- 不同的系统模型会导致不同的P演化
5. 稳态分析
在长时间运行后,P矩阵可能会达到稳态值,此时:
5.1 离散代数Riccati方程
稳态P满足:
P = F @ P @ F.T + Q - F @ P @ H.T @ (H @ P @ H.T + R)^(-1) @ H @ P @ F.T5.2 稳态P与Q、R的关系
- Q增加 → 稳态P增加 → 整体不确定性增大
- R增加 → 稳态P增加 → 因为测量信息不可靠,无法有效减少不确定性
6. 实际代码示例
让我修改之前的代码,展示P矩阵的演化过程:
python
import numpy as np
import matplotlib.pyplot as plt
class KalmanFilter1D_Detailed:
def __init__(self):
# 状态: [位置, 速度]
self.x = np.array([0.0, 0.0])
# 初始协方差矩阵 - 这是关键!
self.P = np.array([
[5.0, 0.0], # 初始位置不确定性
[0.0, 5.0] # 初始速度不确定性
])
# 系统参数
dt = 0.1
self.F = np.array([
[1.0, dt],
[0.0, 1.0]
])
self.H = np.array([[1.0, 0.0]]) # 只测量位置
# 噪声协方差
self.Q = np.array([
[0.1, 0.0],
[0.0, 0.1]
])
self.R = np.array([[1.0]]) # 测量噪声
# 用于记录P矩阵演化
self.P_history = []
def predict(self):
# 状态预测
self.x = self.F @ self.x
# 协方差预测 - Q在这里起作用
self.P = self.F @ self.P @ self.F.T + self.Q
# 记录P矩阵
self.P_history.append(np.copy(self.P))
return self.x[0], np.copy(self.P)
def update(self, measurement):
# 计算卡尔曼增益 - R在这里起作用
S = self.H @ self.P @ self.H.T + self.R
K = self.P @ self.H.T @ np.linalg.inv(S)
# 状态更新
y = measurement - self.H @ self.x
self.x = self.x + K @ y
# 协方差更新
I = np.eye(2)
self.P = (I - K @ self.H) @ self.P
return self.x[0], np.copy(self.P), K7. 重要结论
P矩阵不是完全由Q和R确定的,而是:
- 初始值 P₀:取决于对初始状态的先验知识
- 系统动态 F:决定了不确定性如何传播
- 过程噪声 Q:影响预测步骤中不确定性的增长
- 测量噪声 R:影响更新步骤中不确定性的减少
- 测量矩阵 H:决定了哪些状态可以被观测到
关键关系:
- Q和R的比值 比绝对值更重要:
Q/R决定了算法在预测和测量之间的权衡 - P矩阵是动态的:每个时间步都在变化,反映了当前估计的可靠性
- 稳态P:在长时间运行后,P会收敛到一个稳定值,这个值确实与Q和R有关
8. 调参建议
作为新手,调整Q和R时要注意:
python
# 好的调参策略
Q_factor = 0.1 # 相对较小的过程噪声
R_factor = 1.0 # 相对较大的测量噪声
# 如果滤波结果太"抖动",可能是R太小或Q太大
# 如果滤波结果太"迟钝",可能是R太大或Q太小
# 调整原则:
# 1. 先根据传感器规格设定R
# 2. 根据模型精度设定Q
# 3. 观察P矩阵的演化,确保它收敛到合理值理解P矩阵的动态特性是掌握卡尔曼滤波的关键!它不仅仅是数学符号,而是算法"自信程度"的量化表示。
卡尔曼增益
卡尔曼增益(Kalman Gain)详解
卡尔曼增益 K 是卡尔曼滤波器中最核心、最精妙的概念,它决定了算法如何最优地平衡预测值和测量值。让我从多个维度为你详细解析。
1. 数学定义
卡尔曼增益的计算公式为:
Kk=Pk∣k−1HT(HPk∣k−1HT+R)−1K_k = P_{k|k-1} H^T (H P_{k|k-1} H^T + R)^{-1}Kk=Pk∣k−1HT(HPk∣k−1HT+R)−1
其中:
- KkK_kKk:第k时刻的卡尔曼增益
- Pk∣k−1P_{k|k-1}Pk∣k−1:预测的协方差矩阵(先验估计的不确定性)
- HHH:观测矩阵(将状态映射到测量空间)
- RRR:测量噪声协方差矩阵
- −1^{-1}−1:矩阵求逆
2. 物理意义:最优权重分配器
核心思想
卡尔曼增益本质上是一个自适应权重系数,它动态决定:
- 应该在多大程度上信任新的测量值
- 应该在多大程度上信任之前的预测值
直观理解
想象你是一个投资者,有两个信息来源:
- 预测值:基于历史数据和模型的分析报告(可能有偏差)
- 测量值:实时的市场数据(可能有噪声)
卡尔曼增益就是你的投资决策权重:
- 如果分析报告很可靠(P小),就多信任预测
- 如果市场数据很准确(R小),就多信任测量
- 如果两者都不可靠,就找一个最优平衡点
3. 动态平衡机制
3.1 当测量非常可靠时(R → 0)
Kk≈Pk∣k−1HT(HPk∣k−1HT)−1=H−1K_k ≈ P_{k|k-1} H^T (H P_{k|k-1} H^T)^{-1} = H^{-1}Kk≈Pk∣k−1HT(HPk∣k−1HT)−1=H−1
结果:卡尔曼增益趋近于1(在标量情况下)
- 几乎完全信任测量值
- 状态更新:xk=xk∣k−1+1⋅(zk−Hxk∣k−1)=H−1zkx_k = x_{k|k-1} + 1 \cdot (z_k - H x_{k|k-1}) = H^{-1} z_kxk=xk∣k−1+1⋅(zk−Hxk∣k−1)=H−1zk
- 测量值主导估计结果
3.2 当预测非常可靠时(P → 0)
Kk≈0⋅(0+R)−1=0K_k ≈ 0 \cdot (0 + R)^{-1} = 0Kk≈0⋅(0+R)−1=0
结果:卡尔曼增益趋近于0
- 几乎完全信任预测值
- 状态更新:xk=xk∣k−1+0⋅(任何值)=xk∣k−1x_k = x_{k|k-1} + 0 \cdot (\text{任何值}) = x_{k|k-1}xk=xk∣k−1+0⋅(任何值)=xk∣k−1
- 测量值被完全忽略
3.3 一般情况:最优加权平均
xk=(1−K)⋅xk∣k−1+K⋅H−1zkx_k = (1-K) \cdot x_{k|k-1} + K \cdot H^{-1} z_kxk=(1−K)⋅xk∣k−1+K⋅H−1zk
卡尔曼增益自动找到最小化估计误差方差的权重分配。
4. 与不确定性(P, Q, R)的关系
4.1 与预测不确定性 P 的关系
- P 越大 → 预测越不可靠 → K 越大 → 更信任测量值
- P 越小 → 预测越可靠 → K 越小 → 更信任预测值
python
# 伪代码示例
if P_large: # 预测不确定性大
K = 0.8 # 大权重给测量值
else: # 预测不确定性小
K = 0.2 # 小权重给测量值4.2 与测量噪声 R 的关系
- R 越大 → 测量越不可靠 → K 越小 → 更信任预测值
- R 越小 → 测量越可靠 → K 越大 → 更信任测量值
4.3 与过程噪声 Q 的间接关系
- Q 越大 → 预测步骤中 P 增长越快 → K 越大 → 更信任测量值
- Q 越小 → 预测步骤中 P 增长越慢 → K 越小 → 更信任预测值
5. 标量情况下的直观理解
对于一维系统(如温度估计),公式简化为:
Kk=Pk∣k−1Pk∣k−1+RK_k = \frac{P_{k|k-1}}{P_{k|k-1} + R}Kk=Pk∣k−1+RPk∣k−1
5.1 具体数值示例
假设:
- 预测温度:25°C,不确定性 P = 4(方差)
- 测量温度:28°C,测量噪声 R = 1(方差)
计算卡尔曼增益:
K=44+1=0.8K = \frac{4}{4 + 1} = 0.8K=4+14=0.8
状态更新:
xk=25+0.8×(28−25)=25+2.4=27.4°Cx_k = 25 + 0.8 \times (28 - 25) = 25 + 2.4 = 27.4°Cxk=25+0.8×(28−25)=25+2.4=27.4°C
解释:因为预测不确定性(4)比测量噪声(1)大4倍,所以给测量值分配了80%的权重。
5.2 不同场景对比
| 场景 | P (预测不确定性) | R (测量噪声) | K (卡尔曼增益) | 信任偏向 |
|---|---|---|---|---|
| 高精度传感器 | 4.0 | 0.1 | 0.976 | 几乎完全信任测量 |
| 低精度传感器 | 4.0 | 10.0 | 0.286 | 倾向信任预测 |
| 精确模型 | 0.1 | 1.0 | 0.091 | 几乎完全信任预测 |
| 不确定模型 | 10.0 | 1.0 | 0.909 | 倾向信任测量 |
6. 矩阵情况下的深层理解
在多维系统中,卡尔曼增益是一个矩阵,具有更丰富的含义:
6.1 跨状态耦合
- 不同状态变量之间的卡尔曼增益可能不同
- 一个测量值可能同时影响多个状态变量
python
# 二维位置-速度系统示例
K = [[0.8], # 位置的卡尔曼增益
[0.3]] # 速度的卡尔曼增益6.2 相关性处理
卡尔曼增益自动处理状态变量之间的相关性:
- 如果位置和速度高度相关,测量位置也会修正速度估计
- 通过协方差矩阵P中的非对角线元素体现
7. 代码实现中的卡尔曼增益
让我们看一个完整的代码示例,展示卡尔曼增益的计算和演化:
python
import numpy as np
import matplotlib.pyplot as plt
class KalmanFilter_Demonstration:
def __init__(self):
# 状态: [位置, 速度]
self.x = np.array([0.0, 0.0])
self.P = np.array([[5.0, 0.0], [0.0, 5.0]]) # 初始不确定性大
# 系统参数
dt = 0.1
self.F = np.array([[1.0, dt], [0.0, 1.0]]) # 状态转移
self.H = np.array([[1.0, 0.0]]) # 只测量位置
# 噪声协方差
self.Q = np.array([[0.1, 0.0], [0.0, 0.1]]) # 过程噪声
self.R = np.array([[1.0]]) # 测量噪声
# 用于记录历史
self.k_history = []
self.p_history = []
def predict(self):
"""预测步骤"""
self.x = self.F @ self.x
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x
def update(self, measurement):
"""更新步骤 - 卡尔曼增益计算在这里"""
# 1. 计算卡尔曼增益
S = self.H @ self.P @ self.H.T + self.R # 残差协方差
K = self.P @ self.H.T @ np.linalg.inv(S) # 卡尔曼增益
# 2. 状态更新
y = measurement - self.H @ self.x # 残差
self.x = self.x + K @ y # 更新状态
# 3. 协方差更新
I = np.eye(2)
self.P = (I - K @ self.H) @ self.P
# 记录历史
self.k_history.append(K.copy())
self.p_history.append(self.P.copy())
return self.x, K, y
# 模拟演示
def demonstrate_kalman_gain():
kf = KalmanFilter_Demonstration()
true_position = 0.0
true_velocity = 2.0
measurements = []
estimates = []
k_gains = []
for t in range(50):
# 生成真实轨迹和带噪声的测量
true_position += true_velocity * 0.1
measurement = true_position + np.random.normal(0, 1.0)
# 卡尔曼滤波
kf.predict()
estimate, K, residual = kf.update(measurement)
# 记录数据
measurements.append(measurement)
estimates.append(estimate[0])
k_gains.append(K[0, 0]) # 位置的卡尔曼增益
# 打印关键信息
if t % 10 == 0:
print(f"时间步 {t}:")
print(f" 卡尔曼增益 K = {K[0,0]:.4f}")
print(f" 位置不确定性 P = {kf.P[0,0]:.4f}")
print(f" 预测: {kf.x[0]:.2f}, 测量: {measurement:.2f}, 估计: {estimate[0]:.2f}")
print("-" * 50)
# 可视化
plt.figure(figsize=(15, 10))
# 1. 位置跟踪
plt.subplot(3, 1, 1)
plt.plot(measurements, 'r.', label='测量值', alpha=0.6)
plt.plot([pos for pos in np.linspace(0, 10, 50)], 'g--', label='真实轨迹')
plt.plot(estimates, 'b-', linewidth=2, label='卡尔曼估计')
plt.title('位置跟踪效果')
plt.legend()
plt.grid(True)
# 2. 卡尔曼增益演化
plt.subplot(3, 1, 2)
plt.plot(k_gains, 'b-', linewidth=2, label='位置的卡尔曼增益 K')
plt.axhline(y=0.5, color='r', linestyle='--', alpha=0.3, label='K=0.5 参考线')
plt.title('卡尔曼增益的动态演化')
plt.xlabel('时间步')
plt.ylabel('卡尔曼增益 K')
plt.legend()
plt.grid(True)
# 3. 不确定性演化
p_values = [p[0,0] for p in kf.p_history]
plt.subplot(3, 1, 3)
plt.plot(p_values, 'g-', linewidth=2, label='位置不确定性 P')
plt.title('不确定性(协方差)的演化')
plt.xlabel('时间步')
plt.ylabel('不确定性 P')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 关键观察
print("\n=== 卡尔曼增益的关键观察 ===")
print(f"初始卡尔曼增益: {k_gains[0]:.4f} (不确定性大,信任测量)")
print(f"最终卡尔曼增益: {k_gains[-1]:.4f} (不确定性小,信任预测)")
print(f"卡尔曼增益变化范围: {min(k_gains):.4f} 到 {max(k_gains):.4f}")
print("结论: 卡尔曼增益是自适应的,根据不确定性动态调整权重!")
# 运行演示
demonstrate_kalman_gain()8. 关键特性总结
8.1 自适应性
- 自动调整:无需人工设定权重,根据系统状态动态调整
- 收敛性:随着滤波进行,卡尔曼增益通常会收敛到稳定值
- 鲁棒性:对初始参数不敏感,能自动找到最优权重
8.2 最优性
- 最小方差:卡尔曼增益使估计误差的方差最小化
- 无偏性:在系统模型正确的情况下,估计是无偏的
- 效率:计算复杂度低,适合实时应用
8.3 直观理解框架
不确定性大 (P大) ───┐
├───→ 卡尔曼增益大 ───→ 信任测量
测量噪声小 (R小) ───┘
不确定性小 (P小) ───┐
├───→ 卡尔曼增益小 ───→ 信任预测
测量噪声大 (R大) ───┘9. 实际应用建议
9.1 调参要点
python
# 好的实践
# 1. 根据传感器规格设定R
sensor_accuracy = 0.1 # 传感器精度
R = np.array([[sensor_accuracy**2]])
# 2. 根据模型精度设定Q
model_uncertainty = 0.05 # 模型不确定性
Q = np.array([[model_uncertainty**2, 0],
[0, model_uncertainty**2]])
# 3. 观察卡尔曼增益的演化
if K consistently > 0.9:
print("警告: 算法过度信任测量,检查R是否设置过小")
if K consistently < 0.1:
print("警告: 算法过度信任预测,检查Q是否设置过小")9.2 常见误区
- 误区1 :认为卡尔曼增益是固定值
- 纠正:它是动态变化的,反映当前的不确定性
- 误区2 :只关注最终估计值,不关注卡尔曼增益
- 纠正:卡尔曼增益是诊断滤波器性能的重要指标
- 误区3 :手动调整卡尔曼增益
- 纠正:让算法自动计算,除非有特殊需求
10. 深层思考
卡尔曼增益体现了贝叶斯估计的核心思想:
- 先验知识 (预测)+ 新证据 (测量)= 后验估计(更新)
- 通过不确定性(P, R)来量化对不同信息源的信任程度
- 在噪声环境中寻找最优的估计策略
总结 :卡尔曼增益不是简单的加权系数,而是一个智能的、自适应的决策机制,它让卡尔曼滤波器能够在不确定性和噪声中找到最优的估计路径。理解卡尔曼增益,就理解了卡尔曼滤波的精髓!