DeepSeek-OCR实战是一个系列文章,包含了从基础运行环境搭建到应用接入全过程。本章会对DeepSeek-OCR模型进行介绍
1.什么是DeepSeek-OCR?
简单来说,DeepSeek-OCR是DeepSeek AI在2025年10月20日发布的全新多模态模型,它采用了一种革命性的思路:把文字当成图片来处理和压缩.
传统的OCR工具就像"文字扫描仪",通过光学技术将图像中的文字提取出来。但DeepSeek反其道而行之------将文本信息"绘制"为视觉图像,再通过视觉模型实现高效理解.
这种创新尝试解决了大模型的核心痛点------处理长文本时面临的计算挑战。效果有多惊艳?10页密密麻麻的文本报告,被压缩成一张图片,AI能够一眼读懂它
地址:https://huggingface.co/deepseek-ai/DeepSeek-OCR
2.三大技术突破,让文档处理进入"秒级时代"
- 文字"缩水术":10倍压缩不失真
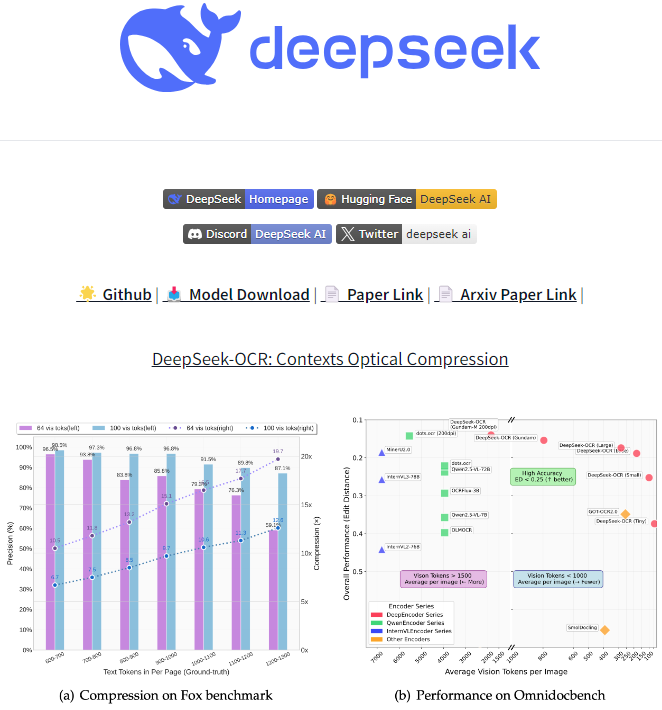
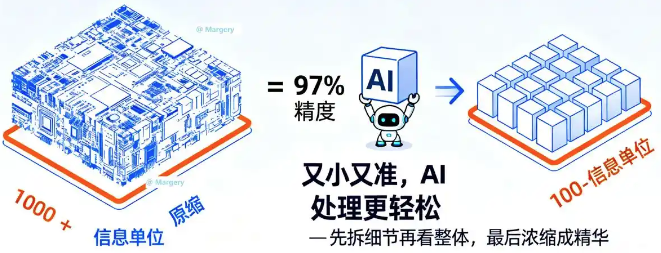
这是最令人惊艳的一点!DeepSeek-OCR能把文字信息高效压缩,传统OCR处理1024×1024的文档需要生成4096个"信息块",而它只用256个就够了,内存消耗直接降低90%
100页的学术论文,以前打开要等30秒,现在5秒就能加载完。在10倍压缩率下,文字一个没少,准确率高达97%。即使压缩率达到20倍,准确率仍保持在60%左右
- 全能识别:公式表格再也不用手敲
普通OCR认不出的化学公式、几何图形、代码块,DeepSeek-OCR全能搞定
- 科研党扫论文,化学分子式直接转成SMILES格式,复制就能进实验软件
- 财务人员扫报表,手写数字+表格线自动变Excel,不用再一个个核对
- 多语言支持:处理100种语言的混合文档,阿拉伯语、日语等复杂文字识别准确率达97%
- 低配友好:普通电脑也能流畅运行. 别以为这么强大的功能需要"万元显卡"才能撑住!它的解码器只需激活6个专家模块,总参数约3B,普通笔记本的GPU都能流畅运行
3.真实场景测试:效率提升惊人
行政人员每月整理报销单,要对着扫描件敲2000多条数据。使用DeepSeek-OCR扫描后,手写金额、发票抬头自动提取,还能校验格式错误,200张发票半小时搞定
律师朋友更夸张,以前翻上千页判决书找关键词要3天,现在扫描后秒定位,准备材料的时间直接从"天"变"小时"
写毕业论文时,引用的外文文献截图没法复制?用DeepSeek-OCR扫描一下,英文段落直接转成可编辑文本,公式自动转LaTeX格式,连图表的坐标轴数据都能提取出来

4.为什么说这是"改变游戏规则"的技术?
简单来说,DeepSeek-OCR的颠覆性在于,它让AI处理文本的方式,从"一个字一个字地朗读"变成了"一页一页地拍照记忆",从而用一种"作弊"般的方式,极大地解决了AI"记不住"和"算不起"长文本的行业难题。
想象一下,让AI阅读一本《产品说明书》来回答你的问题:
| 维度 | 传统AI模型 | DeepSeek-OCR |
|---|---|---|
| 工作方式 | 像逐字朗读,把所有文字转换成成千上万个"文本Token"。 | 像拍照存档,把整页内容变成一张"图片"来理解和存储。 |
| 记忆负担 | 负担沉重。Token越多,算力消耗按平方级增长,很快"大脑"过载,导致遗忘开头内容(上下文遗忘)。 | 轻松省力。用极少的"视觉Token"就能表示一整页的信息,大幅节省"脑力",能记住更长的对话和历史。 |
| 处理效果 | 处理长文档时速度慢、成本高,且容易因"记忆体"不足而中断对话或混淆信息。 | 高效且经济 。在保持97%高准确率的前提下,实现了10倍的信息压缩。单张显卡每天可处理20万页文档。 |
| 打个比方 | 像一个记忆力有限的速记员,文档太长就会手忙脚乱,记后忘前。 | 像一个配备了高级扫描仪和档案系统的图书管理员,效率极高,且过往档案随用随取。 |
5.结语
DeepSeek-OCR完全开源免费!个人和商业使用都不需要支付任何费用。本系列将讲述如何在本地部署,使用。以及如何在应用中接入 DeepSeek-OCR 能力