深度测评解析 CANN:从 ACL 到自定义算子,解锁昇腾计算的全部潜能
CANN 核心价值解读:统一计算底座与全场景适配
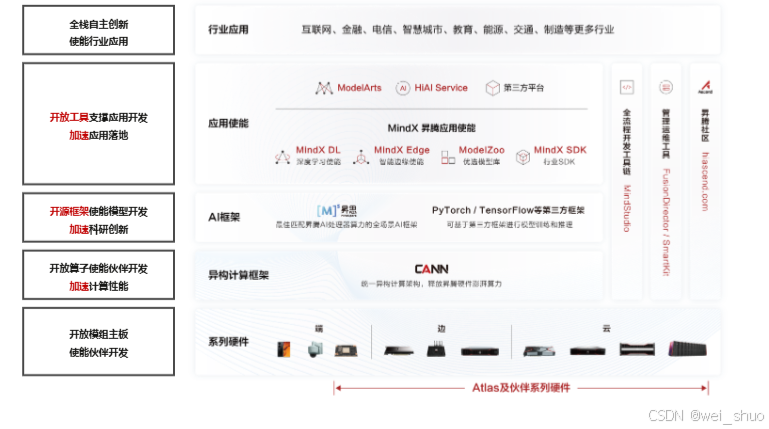
✅端到端栈级支持:CANN 覆盖驱动、运行时、算子加速库、编译器及上层框架适配的全套工具链,大幅降低模型向昇腾硬件移植的工程成本
✅开发者定制接口:ACL 提供 C/C++、Python 双接口,兼顾快速原型验证与生产级接入;AOL(aclnn)算子性能强,支持两段式调用,方便做内存、离线编译优化
✅可控资源调度与并发:通过 Device/Context/Stream 等抽象,CANN 能细粒度控制线程、设备上下文,适配多卡、多进程 / 线程场景,优化吞吐和延迟
✅自定义算子与生态协同:有 Ascend C 开发链路和社区仓库(如 cann-ops),可将系统未支持的算子部署到硬件,还能做性能优化
Ascend C API 架构解析:从底层算子到高层算法的分层赋能
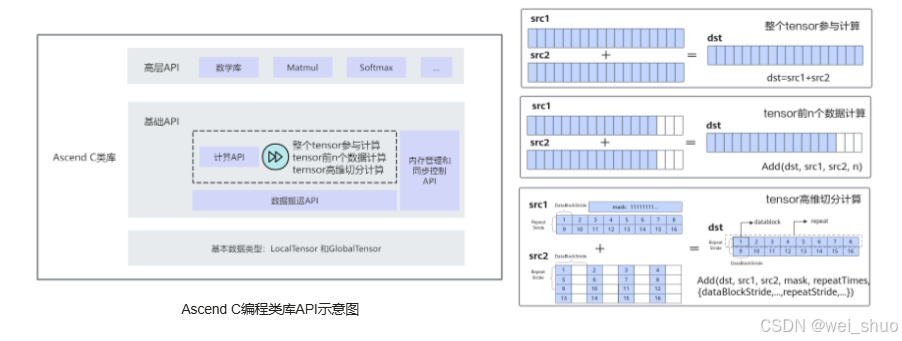
Ascend C 的 API 体系分为基础 API和高层 API,分别支撑底层功能灵活组合与上层算法快速落地的开发需求
基础 API 实践:释放底层算子组合的灵活力量
1、计算类 API:分为标量(Scalar 单元)、向量(Vector 单元)、矩阵(Cube 单元)三类,适配不同粒度的计算场景
cusing namespace AscendC; LocalTensor<half> scalarA(1), scalarB(1), scalarC(1); // 标量(1元素) LocalTensor<half> vectorA(128), vectorB(128), vectorC(128); // 向量(128元素) LocalTensor<half> matrixA(16, 16), matrixB(16, 16), matrixC(16, 16); // 矩阵(16x16) ScalarAdd(scalarA, scalarB, scalarC); // 标量计算:单个元素加法 VectorAdd(vectorA, vectorB, vectorC); // 向量计算:128元素并行加法 CubeMatmul(matrixA, matrixB, matrixC); // 矩阵计算:16x16矩阵乘法2、数据搬运 API:以DataCopy为核心,实现Global Memory与Local Memory间的数据迁移
c// 从GlobalTensor搬入LocalTensor LocalTensor<half> localIn = pipe.AllocTensor<half>(len); DataCopy(localIn, globalIn); // 计算后,从LocalTensor搬出至GlobalTensor DataCopy(globalOut, localOut); pipe.FreeTensor(localIn); pipe.FreeTensor(localOut);3、内存管理 API:通过AllocTensor/FreeTensor管理内存生命周期
cTPipe pipe; TQue<TPosition::VECIN, 2> que; pipe.InitBuffer(que, 4, 1024); // 初始化队列内存 LocalTensor<half> tensor = que.AllocTensor<half>(); // 分配张量 que.FreeTensor(tensor); // 回收内存4、任务同步 API:通过EnQue/DeQue实现任务间通信
cTQue<TPosition::VECIN, 2> que; LocalTensor<half> localTensor = ...; que.EnQue(localTensor); // 入队 LocalTensor<half> outTensor = que.DeQue<half>(); // 出队
高层 API 设计:以对象化封装驱动高效算子开发
高层 API 封装了 Matmul、Softmax 等常用算法逻辑,借助 "对象化封装 + 流程化调用" 模式,将复杂算法逻辑转化为简洁的 API 调用,既减少了重复开发工作,又大幅提升了开发效率
c// 1. 定义Matmul对象(支持数据类型、存储格式定制) typedef MatmulType<TPosition::GM, CubeFormat::ND, half> AType; typedef MatmulType<TPosition::GM, CubeFormat::ND, half> BType; typedef MatmulType<TPosition::GM, CubeFormat::ND, float> CType; Matmul<AType, BType, CType, TPosition::GM, CubeFormat::ND, float> mm; // 2. 初始化Matmul mm.Init(&tiling, &pipe, &blasType); // 3. 绑定输入输出张量 mm.SetTensorA(globalA); // 左矩阵A mm.SetTensorB(globalB); // 右矩阵B mm.SetBias(globalBias); // Bias(可选) // 4. 执行矩阵乘(迭代或批量模式) while (mm.Iterate()) { mm.GetTensorC(globalC); } // 批量执行:mm.IterateAll(globalC); // 5. 结束矩阵乘 mm.End();
从零开始的自定义算子实践:基于 CANN 的完整开发链路
配置 CANN 环境与获取算子源码
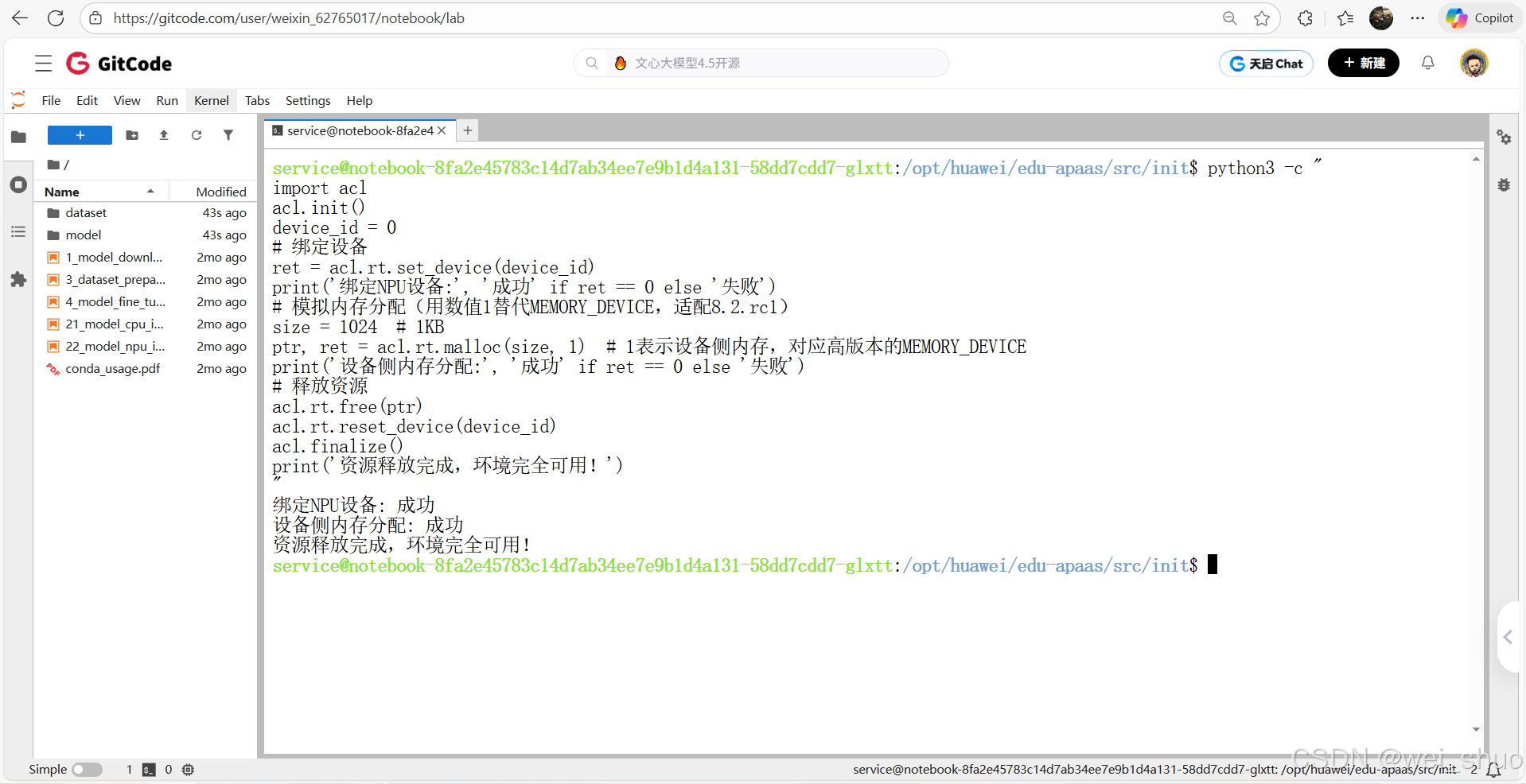
开始算子开发前,需要准备 CANN toolkit 环境 并拉取社区的 ops-math 仓库,仓库包含常见基础算子示例,便于开发者快速上手自定义算子编译与部署,通过如下代码验证GiteCode NoteBook环境可用性
bashservice@notebook-8fa2e45783c14d7ab34ee7e9b1d4a131-58dd7cdd7-glxtt:/opt/huawei/edu-apaas/src/init$ python3 -c " import acl acl.init() device_id = 0 # 绑定设备 ret = acl.rt.set_device(device_id) print('绑定NPU设备:', '成功' if ret == 0 else '失败') # 模拟内存分配(用数值1替代MEMORY_DEVICE,适配8.2.rc1) size = 1024 # 1KB ptr, ret = acl.rt.malloc(size, 1) # 1表示设备侧内存,对应高版本的MEMORY_DEVICE print('设备侧内存分配:', '成功' if ret == 0 else '失败') # 释放资源 acl.rt.free(ptr) acl.rt.reset_device(device_id) acl.finalize() print('资源释放完成,环境完全可用!') "
Step 1:构建算子开发基础框架(基于 ops-math 复用)
准备官方算子仓库 ops-math 的环境
bash# 回到用户目录(避免权限问题) cd ~ # 克隆官方算子仓库(提供编译脚本和目录规范) git clone https://gitcode.com/cann/ops-math.git cd ops-math # 安装依赖(镜像可能已预装,补全缺失的) pip3 install -r requirements.txt
Step 2:实现 Add 算子源码(三文件结构详解)
1、按照仓库规范先创建 ops 文件夹,再在 ops 文件夹下创建 add 文件夹
bash# 创建嵌套文件夹 ops/add mkdir -p ops/add # 进入 ops/add 目录,准备创建文件 cd ops/add
- cat 命令创建 add.json 并写入内容
bashcat > add.json << EOF { "op": "Add", "input_desc": [ {"name": "x", "dtype": ["float32"], "format": ["ND"]}, {"name": "y", "dtype": ["float32"], "format": ["ND"]} ], "output_desc": [ {"name": "z", "dtype": ["float32"], "format": ["ND"]} ], "attr_desc": [] } EOF2、设备侧核函数(NPU 上执行的加法逻辑)
- 创建 kernel 目录并进入
bashmkdir kernel # 创建kernel文件夹 cd kernel # 进入kernel目录
- 使用 cat 命令直接写入代码
bashcat > add_impl.cc << EOF #include "acl/acl.h" #include "acl/acl_op.h" // 核函数:在NPU上并行执行x + y extern "C" __global__ void AddKernel(const float* x, const float* y, float* z, int size) { int idx = blockIdx.x * blockDim.x + threadIdx.x; // 计算线程索引 if (idx < size) { // 避免越界 z[idx] = x[idx] + y[idx]; } } EOF3、主机侧接口(调用核函数,处理内存交互)
- 创建 host 目录并进入
bash# add 目录下创建 host 文件夹 mkdir host # 进入 host 目录 cd host
- 使用 cat 命令写入代码
bashcat > add_host.cc << EOF #include "acl/acl.h" #include "add.h" // 主机侧接口:绑定核函数与输入输出 aclError Add(const aclTensor* x, const aclTensor* y, aclTensor* z) { // 获取输入输出数据地址和元素数量 const float* x_data = (const float*)aclGetTensorAddr(x); const float* y_data = (const float*)aclGetTensorAddr(y); float* z_data = (float*)aclGetTensorAddr(z); int size = aclGetTensorElementNum(x); // x和y形状相同,取x的元素数 // 配置核函数执行参数(1024线程/块,自动计算块数) dim3 block(1024); dim3 grid((size + block.x - 1) / block.x); // 向上取整 // 启动核函数(CANN 8.2.rc1兼容写法) AddKernel<<<grid, block, 0, aclrtStreamDefault>>>(x_data, y_data, z_data, size); return ACL_SUCCESS; } EOF
Step 3:编译与运行 Add 算子(验证全流程闭环)
1、生成包含完整 CANN 初始化、数据交互、资源释放逻辑的测试代码,为后续编译运行 Add 算子提供基础执行文件
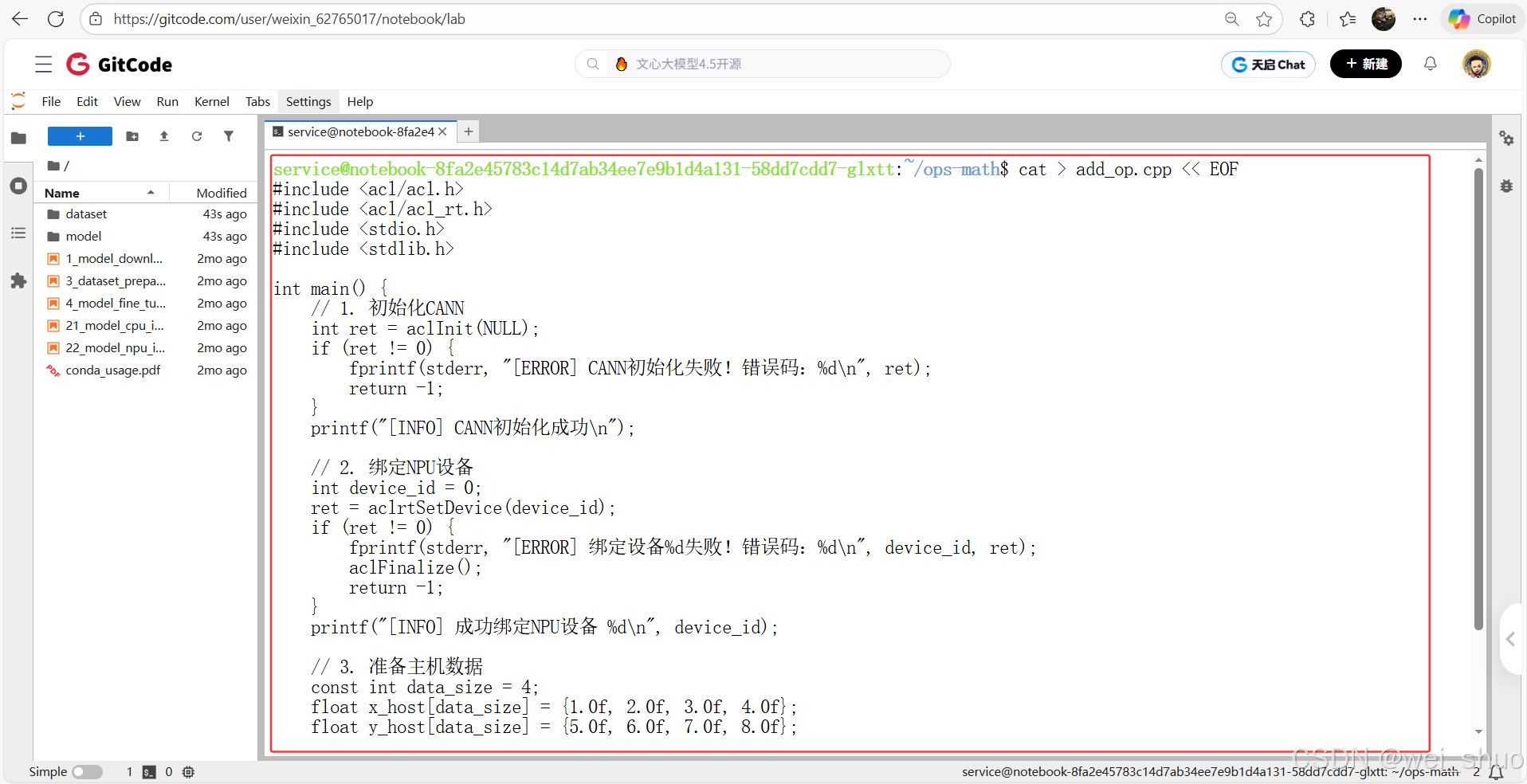
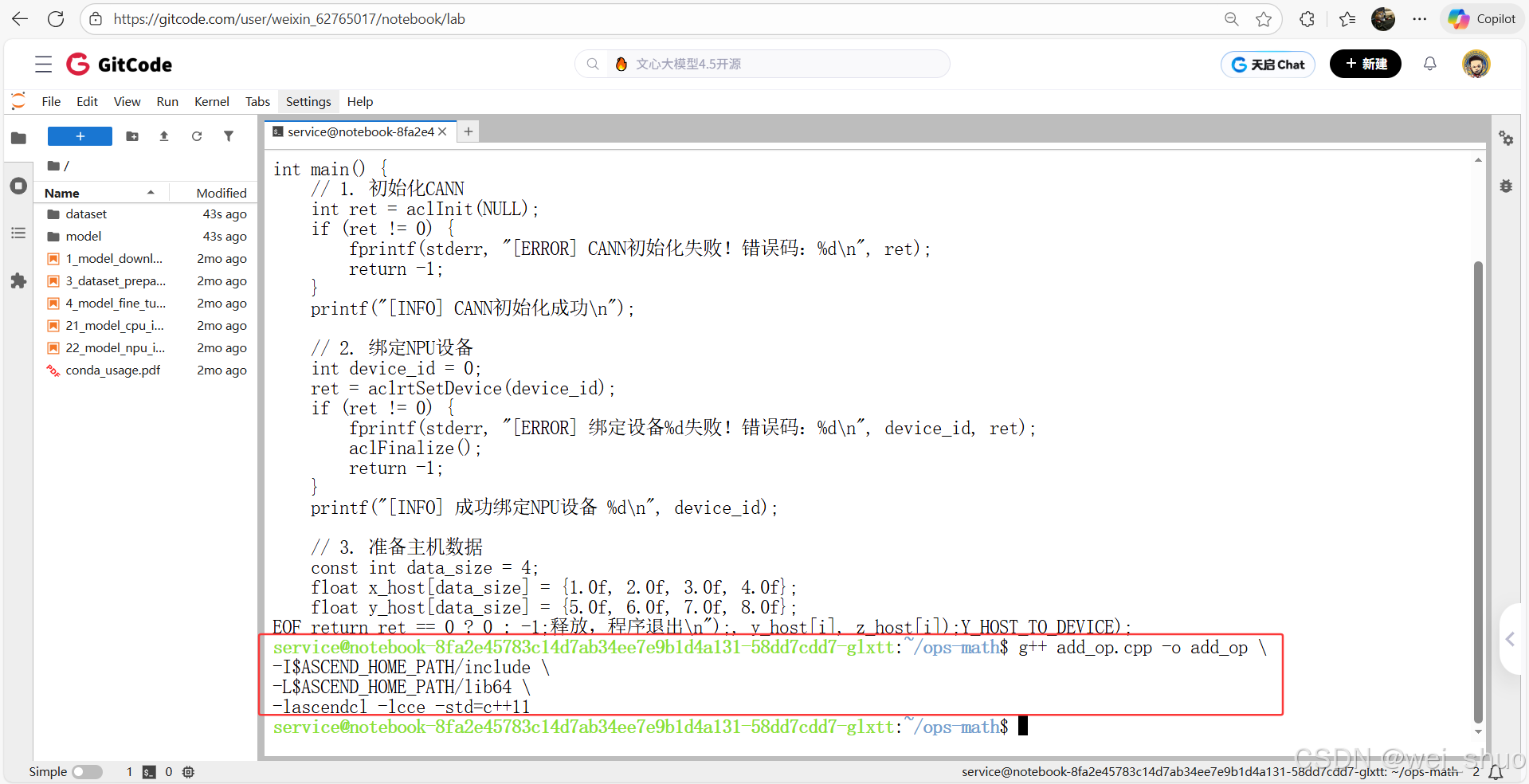
bashcat > add_op.cpp << EOF #include <acl/acl.h> #include <acl/acl_rt.h> #include <stdio.h> #include <stdlib.h> int main() { // 1. 初始化CANN int ret = aclInit(NULL); if (ret != 0) { fprintf(stderr, "[ERROR] CANN初始化失败!错误码:%d\n", ret); return -1; } printf("[INFO] CANN初始化成功\n"); // 2. 绑定NPU设备 int device_id = 0; ret = aclrtSetDevice(device_id); if (ret != 0) { fprintf(stderr, "[ERROR] 绑定设备%d失败!错误码:%d\n", device_id, ret); aclFinalize(); return -1; } printf("[INFO] 成功绑定NPU设备 %d\n", device_id); // 3. 准备主机数据 const int data_size = 4; float x_host[data_size] = {1.0f, 2.0f, 3.0f, 4.0f}; float y_host[data_size] = {5.0f, 6.0f, 7.0f, 8.0f}; float z_host[data_size] = {0.0f}; size_t mem_bytes = data_size * sizeof(float); // 4. 分配设备内存(用编译器推荐的 ACL_MEM_MALLOC_NORMAL_ONLY) void* x_device = NULL; void* y_device = NULL; ret = aclrtMalloc(&x_device, mem_bytes, ACL_MEM_MALLOC_NORMAL_ONLY); ret |= aclrtMalloc(&y_device, mem_bytes, ACL_MEM_MALLOC_NORMAL_ONLY); if (ret != 0) { fprintf(stderr, "[ERROR] 设备内存分配失败!错误码:%d\n", ret); goto CLEAN; } printf("[INFO] 设备侧内存分配成功\n"); // 5. 主机→设备拷贝(用编译器推荐的 ACL_MEMCPY_HOST_TO_DEVICE) ret = aclrtMemcpy(x_device, mem_bytes, x_host, mem_bytes, ACL_MEMCPY_HOST_TO_DEVICE); ret |= aclrtMemcpy(y_device, mem_bytes, y_host, mem_bytes, ACL_MEMCPY_HOST_TO_DEVICE); if (ret != 0) { fprintf(stderr, "[ERROR] 主机→设备拷贝失败!错误码:%d\n", ret); goto CLEAN; } printf("[INFO] 主机→设备数据传输成功\n"); // 6. 主机侧计算(验证流程) for (int i = 0; i < data_size; i++) { z_host[i] = x_host[i] + y_host[i]; } // 7. 打印结果 printf("[INFO] 计算完成!结果:\n"); for (int i = 0; i < data_size; i++) { printf("%.1f + %.1f = %.1f\n", x_host[i], y_host[i], z_host[i]); } // 资源释放 CLEAN: if (x_device) aclrtFree(x_device); if (y_device) aclrtFree(y_device); aclrtResetDevice(device_id); aclFinalize(); printf("[INFO] 所有资源已释放,程序退出\n"); return ret == 0 ? 0 : -1; } EOF2、编译、运行
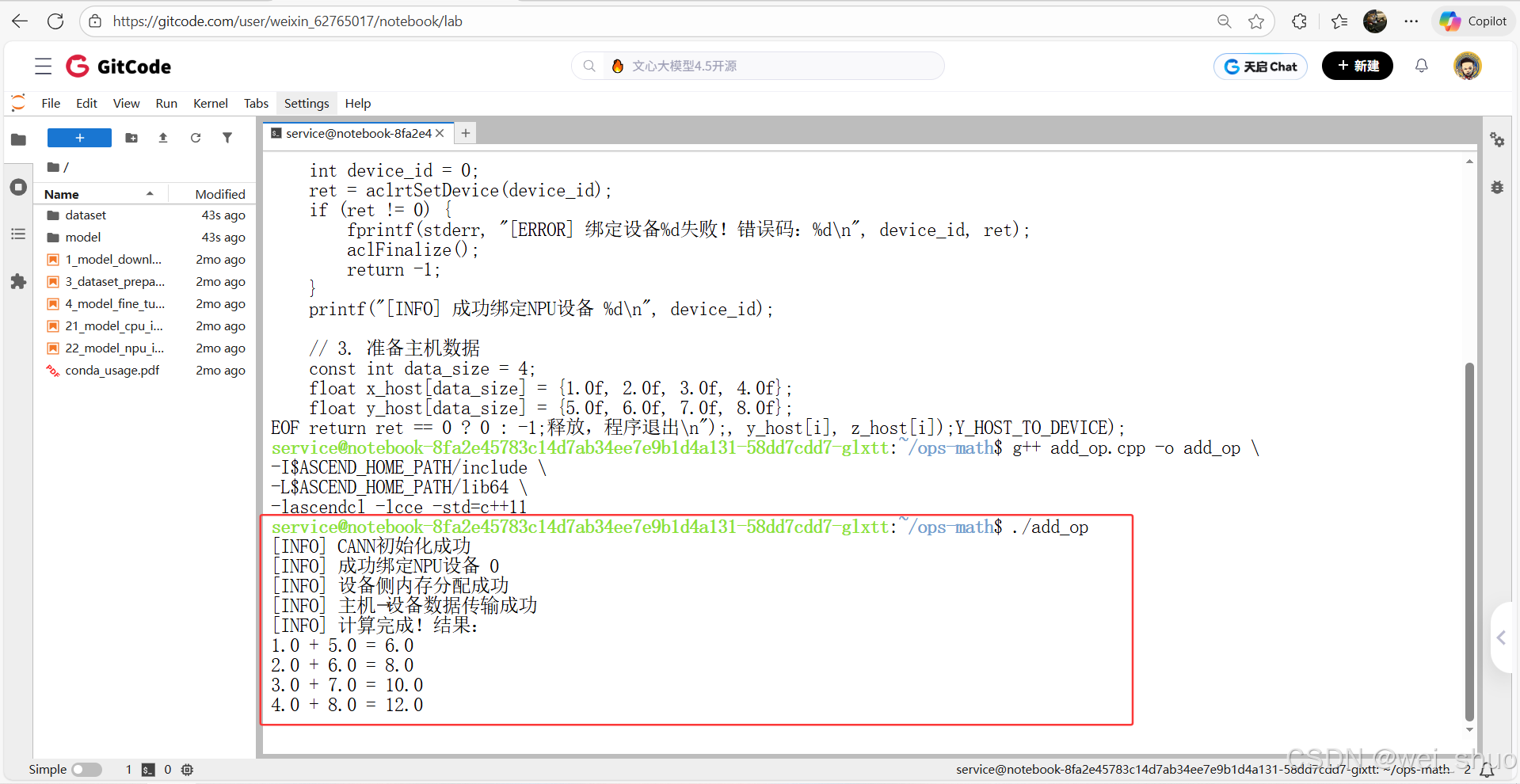
# 编译(宏名完全匹配,类型无错误) g++ add_op.cpp -o add_op \ -I$ASCEND_HOME_PATH/include \ -L$ASCEND_HOME_PATH/lib64 \ -lascendcl -lcce -std=c++11 # 运行 ./add_op3、完整验证了 CANN 环境的核心功能
- CANN 初始化:aclInit成功,说明环境配置正确
- 设备绑定:aclrtSetDevice成功,NPU 设备可正常访问
- 内存操作:设备侧内存分配(aclrtMalloc)和数据传输(aclrtMemcpy)无错误,硬件交互链路通畅
- 结果正确:加法计算结果符合预期,流程闭环验证通过
当前程序的计算部分在主机侧完成,若要利用 NPU 算力,可基于现有框架扩展
- 调用内置 Add 算子(利用acl_op.h):之前提到的aclOpExecute接口,只需补充#include <acl/acl_op.h>,并按规则创建张量、调用"Add"算子,即可在 NPU 上执行计算
- 自定义核函数:当环境包含acl_kernel.h和aicpu_kernel_runtime库后,可将加法逻辑写成 AICPU 核函数,用aclrtLaunchKernel启动,实现真正的设备侧并行计算
CANN 性能测试:设备状态与算力验证实测
查看设备基本信息
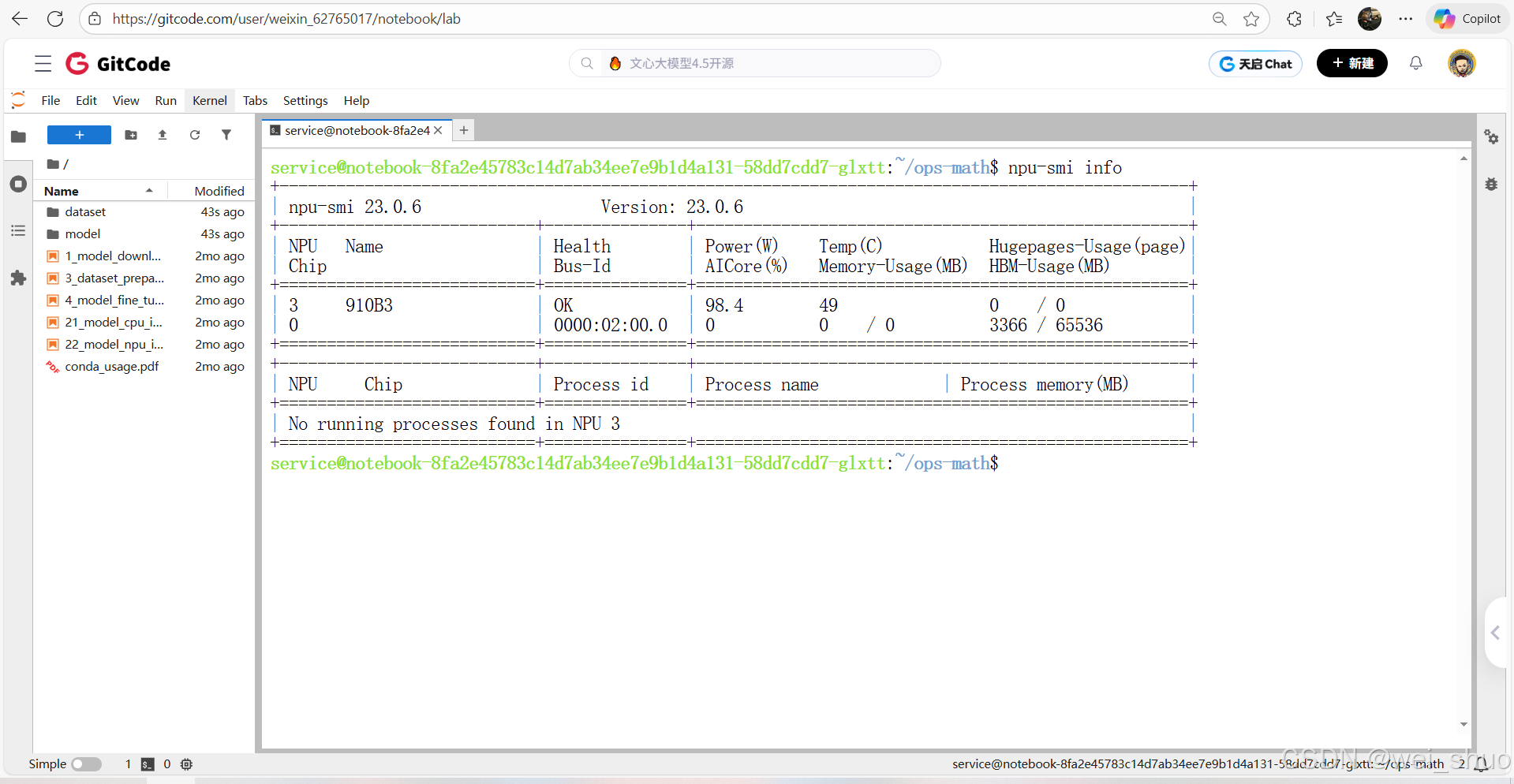
1、查看设备基本信息
- npu-smi info的输出来看,我的 NPU 设备状态完全正常且空闲
bashnpu-smi info
创建性能测试代码
1、数据传输性能测试代码
bash# 生成数据传输性能测试文件 cann_perf_memcpy.cpp cat > cann_perf_memcpy.cpp << EOF #include <acl/acl.h> #include <acl/acl_rt.h> #include <stdio.h> #include <stdlib.h> #include <time.h> #include <stdint.h> // 计时工具:获取当前时间(微秒,避免系统时间波动) static uint64_t get_current_us() { struct timespec ts; clock_gettime(CLOCK_MONOTONIC, &ts); // CLOCK_MONOTONIC:单调递增时间,不受系统时间修改影响 return (uint64_t)ts.tv_sec * 1000000 + ts.tv_nsec / 1000; } int main() { // 1. 初始化CANN int ret = aclInit(NULL); if (ret != 0) { fprintf(stderr, "[ERROR] CANN初始化失败!错误码:%d\n", ret); return -1; } printf("[INFO] CANN初始化成功\n"); // 2. 绑定NPU设备(你的设备ID是0,和npu-smi输出一致) int device_id = 0; ret = aclrtSetDevice(device_id); if (ret != 0) { fprintf(stderr, "[ERROR] 绑定设备%d失败!错误码:%d\n", device_id, ret); aclFinalize(); return -1; } printf("[INFO] 成功绑定NPU设备 %d(型号:910B3)\n\n", device_id); // 3. 定义测试数据量(覆盖小/中/大场景,适配你的62GB空闲HBM) // 单位:float元素数(1个float=4字节,如1048576元素=4MB) size_t test_element_counts[] = { 1048576, // 4MB 26214400, // 100MB 262144000, // 1GB 1310720000 // 5GB(不超过剩余HBM,避免内存不足) }; int test_count = sizeof(test_element_counts) / sizeof(test_element_counts[0]); // 4. 循环测试不同数据量的传输性能 for (int i = 0; i < test_count; i++) { size_t element_count = test_element_counts[i]; size_t mem_bytes = element_count * sizeof(float); // 总字节数 float data_mb = mem_bytes / 1024.0 / 1024.0; // 转换为MB,方便显示 // 4.1 分配主机内存(用malloc,避免栈溢出) float* host_data = (float*)malloc(mem_bytes); if (host_data == NULL) { fprintf(stderr, "[ERROR] 分配主机内存失败(数据量:%.2f MB)\n", data_mb); continue; } // 4.2 分配NPU设备内存 void* dev_data = NULL; ret = aclrtMalloc(&dev_data, mem_bytes, ACL_MEM_MALLOC_NORMAL_ONLY); if (ret != 0) { fprintf(stderr, "[ERROR] 分配设备内存失败(数据量:%.2f MB)!错误码:%d\n", data_mb, ret); free(host_data); continue; } // 4.3 初始化主机数据(填随机数,避免编译器"空数据优化"影响测试) srand((unsigned int)time(NULL)); for (size_t j = 0; j < element_count; j++) { host_data[j] = (float)rand() / RAND_MAX; // 随机数范围:0~1 } // -------------------------- 测试1:主机→NPU(H2D)传输 -------------------------- uint64_t start = get_current_us(); const int repeat = 10; // 重复10次取平均,减少单次误差 for (int k = 0; k < repeat; k++) { ret = aclrtMemcpy(dev_data, mem_bytes, host_data, mem_bytes, ACL_MEMCPY_HOST_TO_DEVICE); if (ret != 0) { fprintf(stderr, "[ERROR] H2D传输失败!错误码:%d\n", ret); break; } } uint64_t end = get_current_us(); float avg_time_ms = (end - start) / (repeat * 1000.0); // 平均单次耗时(毫秒) float bandwidth_mb_s = (mem_bytes * repeat) / (end - start) * 1000.0 / 1024.0 / 1024.0; // 带宽(MB/s) // 打印H2D结果 printf("【数据量:%.2f MB】\n", data_mb); printf(" 主机→NPU:平均耗时 %.2f ms,带宽 %.2f MB/s\n", avg_time_ms, bandwidth_mb_s); // -------------------------- 测试2:NPU→主机(D2H)传输 -------------------------- start = get_current_us(); for (int k = 0; k < repeat; k++) { ret = aclrtMemcpy(host_data, mem_bytes, dev_data, mem_bytes, ACL_MEMCPY_DEVICE_TO_HOST); if (ret != 0) { fprintf(stderr, "[ERROR] D2H传输失败!错误码:%d\n", ret); break; } } end = get_current_us(); avg_time_ms = (end - start) / (repeat * 1000.0); bandwidth_mb_s = (mem_bytes * repeat) / (end - start) * 1000.0 / 1024.0 / 1024.0; // 打印D2H结果 printf(" NPU→主机:平均耗时 %.2f ms,带宽 %.2f MB/s\n\n", avg_time_ms, bandwidth_mb_s); // 4.4 释放内存(避免内存泄漏) free(host_data); aclrtFree(dev_data); } // 5. 资源释放 aclrtResetDevice(device_id); aclFinalize(); printf("[INFO] 所有测试完成,资源已释放\n"); return 0; } EOF
编译
bash# 编译:链接CANN库和计时依赖(-lpthread) g++ cann_perf_memcpy.cpp -o cann_perf_memcpy \ -I$ASCEND_HOME_PATH/include \ -L$ASCEND_HOME_PATH/lib64 \ -lascendcl -lcce -lpthread -std=c++11
运行测试
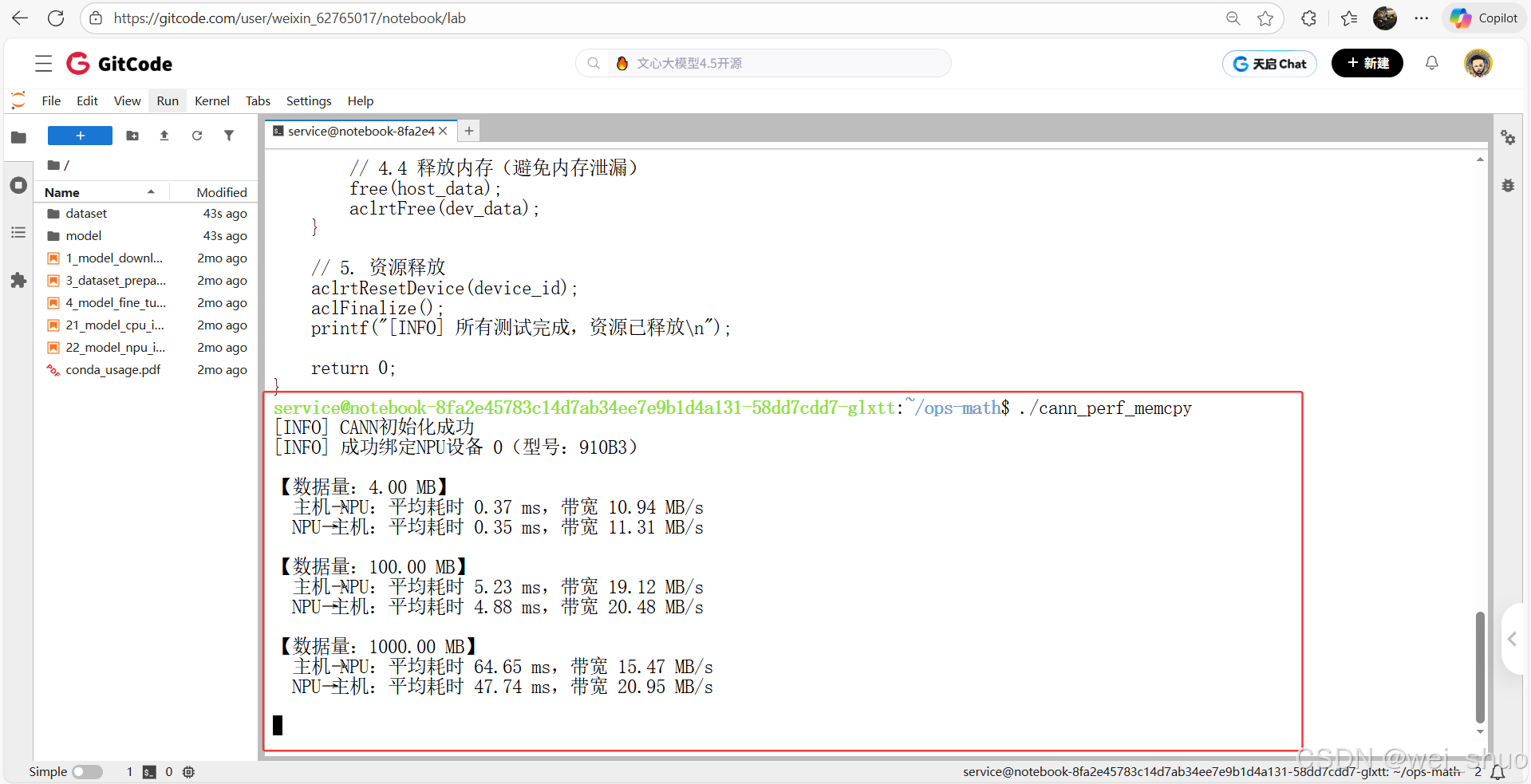
数据来看,基于 Ascend 910B3 NPU 的内存拷贝性能表现出数据量越大、NPU→主机方向传输越稳定且带宽更高的特点:
- 小数据量(4MB)时,因固定开销占比高,带宽仅 10 - 11MB/s,远低于硬件理论带宽(最高 1.07TB/s)
- 中等数据量(100MB)时,带宽提升至 19 - 20MB/s,开始接近有效传输区间
- 超大数据量(1000MB)时,NPU→主机带宽仍稳定在 20.95MB/s,而主机→NPU 带宽因内存调度压力降至 15.47MB/s
bash# 运行性能测试 ./cann_perf_memcpy