随着人工智能的日益火爆,大语言模型(LLM)的应用正变得无处不在。在垂直领域的SFT微调(Supervised Fine-Tuning)作为提升模型专业能力的关键技术,更是引人瞩目。
但你是否注意到一个奇怪的现象:相比经验丰富的专家,新手似乎对尝试SFT微调表现出了更大的热情?这究竟是为什么?是新手无畏的冒险精神,还是专家深思熟虑后的保留态度?
那么,什么是SFT微调?为什么它这么重要?具体怎么做?又该从哪个模型开始着手?别急,这篇文章将一步步为你解答。
一、为什么需要垂直领域的SFT微调?
通俗来讲,SFT微调是通过垂直领域数据对现有大语言模型进行二次训练,使其在特定领域表现得更精准、更专业。这一步骤的必要性主要体现在以下方面:
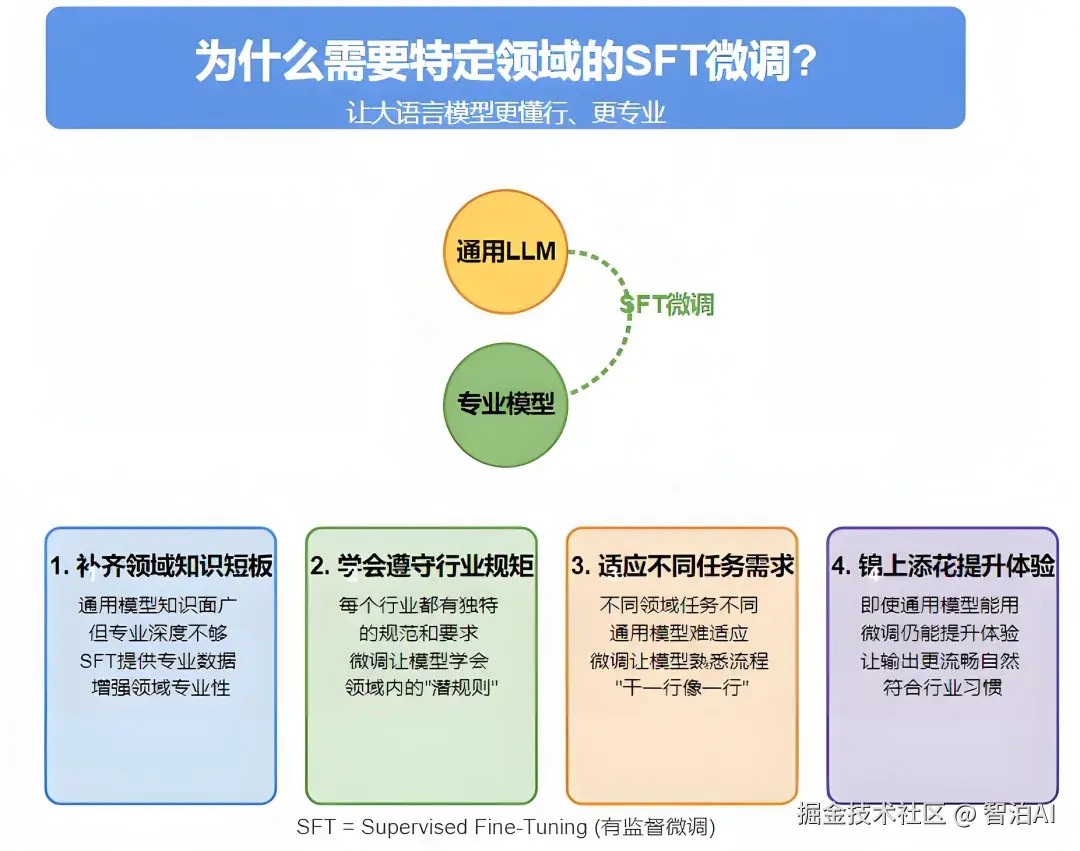
弥补专业领域认知不足
通用大语言模型基于海量互联网数据训练,具备广泛的知识覆盖,但在特定专业领域缺乏深度。
例如,当医生询问某种疾病的临床诊断标准,或律师咨询特定法规条款时,通用模型可能因知识局限而给出模糊甚至错误的回答。
通过SFT微调,引入领域专业数据(如医学期刊、法律案例)可强化模型对专业术语和核心知识的掌握,显著提升回答的准确性和权威性。
掌握行业特定规范
各行业均有其独特的操作准则。例如,医疗行业需严格遵守患者隐私保护,法律领域必须坚持程序公正原则,这些要求对专业性极为严苛。
通用模型可能因不熟悉行业潜规则而出现疏漏。SFT微调通过注入行业规范数据,使模型能够精准理解垂直场景下的合规要求,避免低级错误。
精准匹配多样化任务
不同领域的任务需求差异显著:临床医生需要生成结构化病历,法律从业者需审核合同条款,金融从业者则依赖市场趋势分析。
通用模型在面对此类细分任务时往往表现泛化。通过SFT微调,利用实际任务样本(如"指令-输出"对)训练模型,可使其深入理解任务流程,实现"专业对口"的高效输出。
优化交互体验
即使通用模型能完成基础领域任务,SFT微调仍可进一步优化表现。微调后的模型输出更贴合行业用语习惯,文本连贯性和专业性提升,从而大幅改善用户体验。
总结:SFT微调如同为通用模型提供"职业特训",将其从"通才"转化为特定领域的"专家",实现能力与场景的深度适配。
二、垂直领域SFT微调怎么做?
SFT微调并不是随便拿点数据丢给模型就行,它有一套清晰的流程。下面我们来一步步拆解:
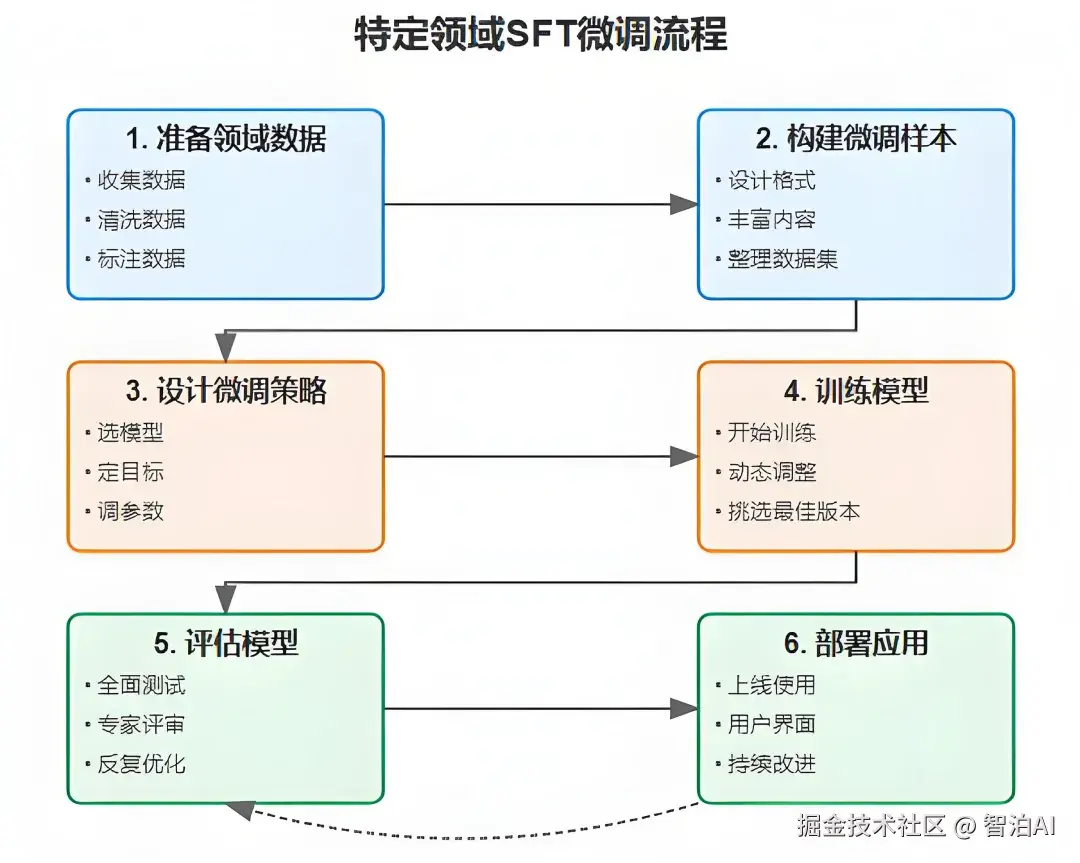
领域数据准备
数据采集:获取高价值的专业领域文本,例如临床病历、合同条款、财经报道等,数据形式可包含结构化表格或非结构化文档。
数据净化:剔除文本中的干扰项(如错别字、冗余信息)及隐私内容(如个人身份信息),保障数据纯净度。
数据标注:按任务需求将数据转换为定向格式,例如"问句-回复"对、"原文-精要"对等,以适配模型训练需求。
微调样本构建
模板设计:依据模型特性与任务目标,制定输入输出范例。例如在医疗场景中,输入为"主诉症状",输出为"诊疗方案"。
内容增强:结合领域知识库或行业标准文件,为输入样本补充上下文说明与规则限制。
数据集整合:将样本系统化整理为统一数据集,供后续训练调用。
微调策略制定
模型选择:优先选用与任务匹配度高的基础模型,可显著提升微调效率。
目标设定:除语言生成能力外,需纳入任务专项指标(如精确度、合规性等)。
参数优化:调整学习率、迭代次数等参数,实现效果与资源消耗的最优配比。
模型训练实施
启动训练:利用预处理数据对选定模型进行训练。
实时监控:训练过程中动态评估效果,及时调整参数以确保模型性能持续优化。
版本筛选:从多个训练版本中通过测试选出最优模型。
模型效果评估
多维测试:使用独立测试集验证模型,兼顾语言流畅度与任务达成度。
专家验证:邀请领域专家审核输出结果,识别改进点。
迭代优化:基于测试反馈调整数据或模型结构,进行多轮精进。
实际应用部署
系统上线:将优化后的模型投入实际业务场景,提供智能化服务。
交互设计:开发易用的操作界面,降低用户使用门槛。
长效更新:持续收集用户反馈,定期迭代模型以适应领域知识演进。
三、从哪个模型开始微调?基座模型 vs 对话模型
在进行SFT微调时,一个核心决策点是:从哪个起点开始?是选择预训练的基础模型(即基座模型),还是对话模型(例如聊天模型)?这两种路径各有其优势和局限性,我们一起来探讨一下:
1、基于预训练基础模型的微调
优势:
语言能力深厚:基座模型经过海量数据训练,具备扎实的语言理解和生成能力,为后续任务奠定了良好基础。
可塑性强:未针对特定任务固化,可根据实际需求灵活调整微调方向。
经济性高:相比对话模型,微调过程所需的计算资源和时间成本显著降低。
不足:
领域知识匮乏:对专业领域的认知近乎空白,需通过大量数据填补知识缺口。
对话适应性差:更适合处理独立文本,在多轮对话场景中可能表现生硬。
2、基于对话模型的微调
优势:
对话基础成熟:已掌握对话交互的基本模式,能更快适应特定领域的对话需求。
上下文连贯性:对对话逻辑和语境的把握更精准,输出更自然流畅。
交互体验优化:生成的响应更贴近人类交流习惯,提升用户满意度。
不足:
潜在偏差:可能继承通用对话中的某些倾向性,与垂直领域需求存在冲突。
知识深度有限:侧重对话交互能力,对专业复杂知识的理解可能不足。
资源消耗大:模型复杂度更高,微调过程需要更多算力和数据支持。
3、决策建议
若目标是构建高度专业的对话系统,且具备充足的数据和算力资源,建议优先选择对话模型作为起点,能快速实现领域适配并优化用户体验。
若数据有限或任务偏向通用性,从基座模型起步更具性价比,能以较低成本获得合格的基础模型。
混合策略也是可行方案:先通过基座模型建立领域知识基础,再通过对话模型优化交互体验;或尝试"提示工程"(Prompt Engineering),借助精心设计的输入模板实现快速适配。
最终选择需综合考量三个关键因素:任务特性、数据规模、预算限制。通过系统权衡,才能找到最优解决方案。
四、SFT微调有哪些实际应用?
当基础模型能力不足且RAG技术仍无法满足需求时,SFT微调将成为必要选择。其跨行业适用性极强,以下为典型领域案例:
1、医疗健康领域
智能问诊系统:基于患者症状描述,输出初步诊断或健康管理方案。
自动化报告生成:整合检验数据,一键生成标准化病历或影像分析报告。
新药研发支持:通过分子结构模拟,评估药物活性并加速研发流程。
2、法律司法领域
普法智能助手:面向公众提供法律知识解答与诉讼流程指导。
合同风险检测:自动识别条款中的法律漏洞并给出优化建议。
司法案例挖掘:从判决文书中提取裁判规则,辅助类案分析。
3、金融经济领域
财经快讯生成:实时聚合新闻关键信息,产出市场动态简报。
量化投资分析:融合财务数据与市场指标,构建股价预测模型。
行业研究报告:自动生成细分领域洞察或宏观经济趋势分析。
上述案例仅为SFT微调实际应用的局部展现,其价值边界仍在持续拓展中。
五、总结
垂直领域的SFT微调,是一把打开大语言模型潜力的钥匙。通过它,我们可以把通用的"全能选手"变成某个行业的"顶尖专家"。
无论是医疗诊断、法律咨询,还是金融分析、教育辅导,只要用对了方法,SFT微调都能让模型大放异彩。
总的来说,新手对垂直领域SFT微调的热情源于他们对技术的好奇、对成果的渴望以及对风险的相对无感,而专家则因丰富的经验和对技术边界的清醒认识而更显谨慎。
不管你是初入AI领域的新手,还是深耕多年的专家,理解SFT微调的价值与局限都至关重要。愿这篇文章点燃你的思考火花,激励你在垂直领域的AI探索中找到属于自己的答案。
更多AI大模型学习视频及资源,都在智泊AI。