本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
在大模型快速迭代的今天,Qwen3 作为开源圈的黑马,凭借强悍的推理能力、多语言支持和灵活的"思考模式"切换,吸引了无数开发者关注。
你想让自己的AI项目更聪明、更高效吗?今天就带你全流程掌握如何用 Unsloth 框架对 Qwen3 进行高效微调、推理和评估,让你的应用一飞冲天!
一、Qwen3模型亮点全解析
Qwen3 是新一代开源大语言模型,主打以下几个核心优势:
- 多尺寸可选、部署灵活:无论是手机、智能眼镜还是自动驾驶、机器人,Qwen3 都能按需选择模型大小,适配边缘设备或云端服务器。
- 推理透明可控:独特的"思考模式"能让模型在输出答案前,先展示推理过程,极大方便调试、教学和代码生成。
- 多语言天花板:支持119种语言及方言,轻松应对全球化产品需求。
- 超长上下文处理:最大支持128K tokens,适合法律、代码、文档等超长文本场景。
- 高性能低成本:MoE(专家混合)架构只激活部分专家,推理快、成本低,媲美甚至超越同体量闭源大模型。
- 开源可定制:Apache 2.0协议,权重可随意下载、二次开发,直接对接Hugging Face生态。
二、Qwen3"思考模式"揭秘:让你的AI会"思考"
Qwen3 的最大特色就是"思考模式"与"非思考模式"自由切换:
- 思考模式 :模型在输出答案前,会用
<think>...</think>标签详细展示推理步骤,比如数学计算、逻辑推断等,让你清楚看到AI的思路。 - 非思考模式:直接给出答案,速度更快,适合对话机器人、实时助手等场景。
你可以通过三种方式控制思考模式:
- API参数 :
enable_thinking=True(默认开启,输出完整推理过程);enable_thinking=False(只输出答案,不展示推理)。 - Prompt指令 :在用户消息中加
/no_think,即使API参数为True,也强制关闭思考展示。 - 后处理 :如果只想要纯答案,可以在输出后通过字符串处理移除
<think>标签。
应用场景举例:
- 教育/数学题讲解:展示每一步推导,AI秒变"讲题老师"。
- 代码生成/调试:看到AI决策流程,快速定位bug。
- 聊天助手/智能客服:关闭思考模式,响应更快,体验更丝滑。
三、Qwen3 + Unsloth 微调与推理全流程(附代码)
下面以 PyTorch + Unsloth 框架为例,手把手教你微调和推理 Qwen3:
1. 环境准备
python
import torch
from unsloth import FastLanguageModel
import weave # 可选,用于可视化和分析
weave.init('think_test')2. 模型加载与配置
ini
BASE_MODEL_NAME = "unsloth/Qwen3-8B"
max_seq_length = 2048
dtype = None
load_in_4bit = False
BASE_MODEL, TOKENIZER = FastLanguageModel.from_pretrained(
model_name=BASE_MODEL_NAME,
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit
)
BASE_MODEL.eval().to("cuda")
FastLanguageModel.for_inference(BASE_MODEL)3. Prompt构建与推理函数
ini
def make_prompt(instruction):
return [{"role": "user", "content": instruction}]
defapply_chat_template(prompt, tokenizer, enable_thinking=True):
messages = make_prompt(prompt)
return tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
@weave.op
defgenerate_response(prompt, enable_thinking=True):
prompt_text = apply_chat_template(prompt, TOKENIZER, enable_thinking)
inputs = TOKENIZER([prompt_text], return_tensors="pt").to("cuda")
with torch.no_grad():
gen_output = BASE_MODEL.generate(
**inputs,
max_new_tokens=128,
use_cache=False,
temperature=0.7,
top_p=0.8,
top_k=20,
min_p=0.0,
)
output_text = TOKENIZER.decode(gen_output[0], skip_special_tokens=True)
return output_text4. 实战测试
scss
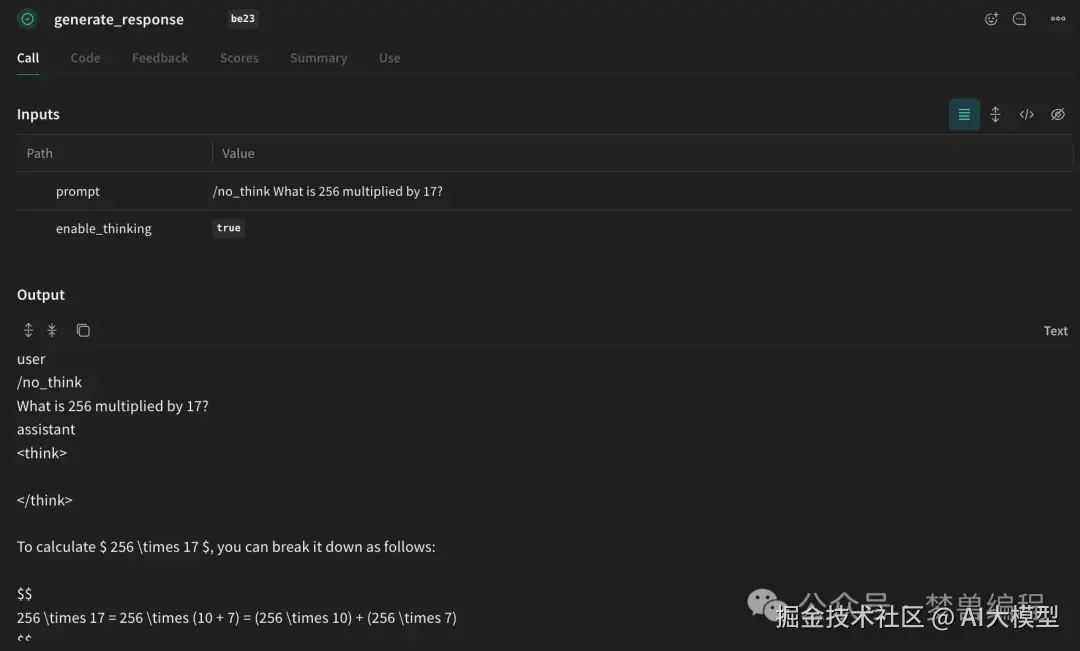
math_question = "What is 256 multiplied by 17?"
math_question_no_think = "/no_think\nWhat is 256 multiplied by 17?"
print("=== enable_thinking=True (默认) ===")
print(generate_response(math_question, enable_thinking=True).strip())
print("=== enable_thinking=False ===")
print(generate_response(math_question, enable_thinking=False).strip())
print("=== enable_thinking=True + /no_think in prompt ===")
print(generate_response(math_question_no_think, enable_thinking=True).strip())效果说明:
- 默认模式下,输出包含详细推理过程。
- 关闭思考模式,输出直接给答案。
- Prompt加
/no_think,无论API参数如何,都只输出答案。
四、Qwen3适用场景与实战建议
- 多端部署:适合手机、IoT、车载等多种硬件,灵活选型。
- 高透明度AI:教育、科研、代码生成等需要"可解释性"的场合首选。
- 超长文本/多语言:文档分析、全球化产品、法律合规等强需求。
- 高性价比推理:MoE架构让企业级部署更省钱。
- 开源自定义:二次开发、私有化部署无压力。
五、总结
Qwen3 + Unsloth 的组合,堪称国产大模型微调和推理的新范式。无论你是AI开发新手还是企业技术负责人,都能用极低门槛把AI能力集成到自己的产品中。只要学会上面这套流程,你就能让AI"会思考"、会解释、会多语言,还能轻松微调出专属模型!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。