C/C++基础题
cpp
switch (表达式) {
case 常量1:
// 当表达式的值等于常量1时执行的代码
break; // 可选,用于跳出switch语句
case 常量2:
// 当表达式的值等于常量2时执行的代码
break;
// ... 更多case
default:
// 当表达式的值不匹配任何case时执行的代码(可选)
break;
}1. switch(表达式), 其中表达式不能是什么类型?
表达式的结果必须是整数类型 (
int、char、enum等)或可隐式转换为整数的类型(如short),不能是浮点数、字符串等。
2. 描述C++程序的内存由哪几部分组成,每个区域分别有什么作用和特点
地址从高到底依次是,栈、堆、全局 / 静态存储区、常量存储区(只读数据段)、代码区
3. 什么时候分配内存会产生内存碎片
内存碎片分为外部碎片和内部碎片
外部碎片: 内存总空闲容量足够,但因空闲块被已分配的内存分割成不连续的小块,无法满足连续内存的申请需求
内部碎片: 编译器或操作系统为提高访问效率,要求内存块按特定字节对齐(如 4 字节、8 字节)。例如,申请 3 字节内存,实际分配 4 字节,多余的 1 字节就是内部碎片。
操作系统按页(如 4KB)管理内存,若申请 5KB 内存,会分配 2 个页(8KB),未使用的 3KB 就是内部碎片。

4. 负数的编码方式是什么,简述一下它的原理
负数的补码编码通过 "模运算" 将负数转化为等效正数,核心是 "取反加 1",其最大价值是让加减法运算统一为加法,同时解决了原码 / 反码的逻辑缺陷(如正负零、运算复杂)。这也是补码成为计算机中负数唯一标准编码方式的原因。
5. 浮点数的编码方式是什么,简述一下它的原理
浮点数通过 IEEE 754 标准编码,本质是 "二进制科学计数法",将数值拆分为符号、指数、尾数三部分存储,既保证了大范围的数值表示,又通过尾数提供了一定精度。
6. 可执行程序是如何生成的
预处理(*.i)、编译(*.s)、汇编(*.o)、链接(*.exe)
7. 可执行程序是如何变成进程的
举例:Linux 中
./a.out的执行过程
- 用户输入
./a.out,Shell 进程(命令解释器进程) 调用fork创建子进程,再通过execve系统调用加载a.out。- 操作系统为子进程创建 PCB,分配 PID(如 1234)。
- 加载器解析
a.out的 ELF(Executable and Linkable Format) 格式,分配内存:代码段加载到0x400000,数据段到0x600000,栈到0x7fffffff附近。- 设置 PC(程序计数器 ) 为
0x400430(_start入口),栈中压入命令行参数。- 子进程进入就绪队列,被 CPU 调度后,开始执行
_start→main函数,成为运行中的进程。
8. 在C语言中如何调用C++函数
在 C 语言中调用 C++ 函数需要解决名字修饰(Name Mangling) 的问题。C++ 为了支持函数重载、类成员函数等特性,会对函数名 进行修饰(如添加参数类型、返回值等信息),而 C 语言不进行名字修饰,导致 直接调用时无法匹配函数地址。解决方法是通过
extern "C"关键字让 C++ 函数按 C 语言的规则编译,避免名字修饰。
9. 请描述几种常见的C/C++的缺陷和陷阱
| 类别 | 缺陷 / 陷阱 | 示例代码 | 规避方法 |
|---|---|---|---|
| 内存管理 | 野指针 | cpp int* p; *p = 10; // 未初始化指针 delete p; *p = 20; // 已释放指针 |
指针初始化时设为nullptr,释放后及时置空;优先使用智能指针(unique_ptr)。 |
| 内存泄漏 | cpp void func() { int* p = new int[100]; /* 忘记delete[] p; */ } |
配对使用new/delete、malloc/free;用vector替代动态数组。 |
|
| 双重释放 | cpp int* p = new int; delete p; delete p; // 重复释放 |
释放后将指针置为nullptr(释放nullptr安全);用智能指针自动管理。 |
|
| 数组与指针 | 数组越界 | cpp int arr[3] = {1,2,3}; arr[5] = 10; // 越界访问 |
用vector的at()做边界检查;循环中严格控制下标范围。 |
| 数组衰减丢失长度 | cpp void func(int arr[]) { /* arr是指针,无长度信息 */ } |
函数参数同时传递数组长度(如func(int arr[], int len));用vector。 |
|
| 未定义行为 | 有符号整数溢出 | cpp int a = INT_MAX; int b = a + 1; // 溢出,行为未定义 |
使用无符号整数(溢出行为可预测);用__builtin_add_overflow检查。 |
| 空指针解引用 | cpp int* p = nullptr; *p = 10; // 未定义行为 |
访问指针前检查是否为nullptr。 |
|
| 返回局部变量的指针 / 引用 | cpp int* func() { int a=10; return &a; } // 返回野指针 |
避免返回栈内存的指针 / 引用;用动态内存(需手动释放)或静态变量(谨慎使用)。 | |
| 类型转换 | 有符号与无符号混合运算 | cpp unsigned int a=1; int b=-2; if(a < b) { /* 条件错误 */ } |
避免混合类型运算;必要时显式转换(static_cast<long long>)。 |
| 指针类型不匹配 | cpp float f=3.14f; int* p=(int*)&f; *p=10; // 破坏float内存 |
避免随意转换指针类型;使用reinterpret_cast时确保内存布局兼容。 |
|
| C++ 特有 | 基类析构函数非虚函数 | cpp class Base { ~Base() {} }; class Derived : public Base { ~Derived() {} }; |
基类析构函数声明为virtual。 |
| 默认浅拷贝导致双重释放 | cpp class String { char* data; /* 未自定义拷贝构造 */ }; String s2 = s1; |
自定义拷贝构造和赋值运算符(深拷贝);或用delete禁用默认函数。 |
|
| 宏滥用 | 宏文本替换逻辑错误 | cpp #define ADD(a,b) a+b; int x = ADD(1,2)*3; // 结果为7(预期9) |
用const定义常量,inline函数替代宏函数;宏加括号(如(a)+(b))。 |
10. 重写,重载,重定义这三者有什么区别
重写(Override, 也叫覆盖)、重载(Overload)、重定义(Redefine,也叫隐藏)
- 重写 :聚焦 "继承 + 虚函数 + 多态",子类覆盖父类虚函数,参数 / 返回值必须一致。
- 重载:聚焦 "同一作用域 + 函数名相同 + 参数不同",与继承无关,用于实现同一功能的不同输入。
- 重定义 :聚焦 "继承 + 非虚函数",子类定义同名函数导致父类函数被隐藏
11. 说一说strcpy,sprintf,memcpy这三个函数的不同之处
| 对比维度 | strcpy |
sprintf |
memcpy |
|---|---|---|---|
| 核心功能 | 字符串拷贝(将源字符串复制到目标地址) | 格式化字符串输出(将格式化数据写入目标缓冲区) | 内存块拷贝(按字节复制任意类型的内存数据) |
| 操作对象 | 仅适用于以 \0 结尾的字符串(char*) |
适用于字符串及各种数据类型(int/float等) |
适用于任意类型的内存块(char/int/ 结构体等) |
| 拷贝终止条件 | 遇到源字符串的 \0 时停止(自动添加 \0 到目标) |
格式化字符串结束(\0 作为终止符) |
严格按照指定的字节数 拷贝(不依赖 \0) |
| 函数原型 | char* strcpy(char* dest, const char* src); |
int sprintf(char* buf, const char* fmt, ...); |
void* memcpy(void* dest, const void* src, size_t n); |
| 是否处理格式 | 不处理,仅简单拷贝字符串 | 支持格式化(如 %d/%s/%f) |
不处理格式,纯字节拷贝 |
| 安全性问题 | 无长度检查,若源字符串过长会导致目标缓冲区溢出 | 无长度检查,格式化后字符串过长会导致缓冲区溢出 | 需手动保证源和目标内存块不重叠且长度足够(否则可能越界) |
| 典型使用场景 | 字符串复制(如 strcpy(dest, "hello");) |
拼接 / 格式化字符串(如 sprintf(buf, "age=%d", 18);) |
复制非字符串数据(如结构体、数组,memcpy(dest, arr, 10*sizeof(int));) |
12. strlen和sizeof的区别
strlen是库函数 ,用于计算字符串的有效长度;sizeof是运算符,用于计算变量 / 类型占用的内存字节数。char s\[\] = "abc"; strlen(s); // 返回3('a','b','c',不含'\0')
char s\[\] = "abc"; sizeof(s); // 返回4(包含'\0',共4字节)
13. 二维数组是什么,函数指针是什么
二维数组是数组的数组 ,本质上是按行优先(C/C++ 中)顺序存储的连续内存块,用于表示具有行和列结构的数据(如矩阵、表格)。
类型 数组名[行数][列数],例如int matrix[3][4];表示 3 行 4 列的整型二维数组。函数指针是指向函数的指针变量,它存储的是函数在内存中的入口地址,可通过函数指针调用函数,实现 "以函数为参数" 或 "动态选择执行函数" 等灵活操作。
14. 简述值传递,指针传递的区别
| 对比维度 | 值传递 | 指针传递 |
|---|---|---|
| 传递的内容 | 实参的值(副本) | 实参的地址(指针值的副本) |
| 形参与实参的关系 | 形参是独立变量,与实参无关联 | 形参和实参指向同一块内存 |
| 是否能修改实参 | 不能(修改的是副本) | 能(通过指针间接修改实参内容) |
| 内存开销 | 复制实参的值(大对象开销大) | 复制地址(通常 8 字节,开销小) |
15. C++中const关键字的作用
在 C++ 中,
const关键字用于声明常量或限制对象的修改权限 ,其核心作用是 "只读",const的用法灵活,可修饰变量、指针、函数参数、函数返回值、成员函数和成员变量。
- 修饰变量:定义不可修改的常量。
- 修饰指针 / 引用:限制对指向内容的修改,或限制指针本身的指向。
- 修饰函数参数 / 返回值:保护实参指向的内容或者本身不能被修改,或限制返回结果的修改。
- 修饰类成员函数 / 变量:确保成员函数内不能修改成员变量的值,或定义类的常量成员。注意,const修饰的成员变量必须在初始化列表中进行初始化
16. C++中static关键字的作用
static的核心功能是控制 "存储方式" 和 "可见性":
- 修饰全局变量:将全局变量的作用域限制在当前源文件(
.c/.cpp)内,避免不同文件中同名全局变量的冲突。- 修饰局部变量:改变局部变量的存储方式,使其生命周期延长至整个程序运行期间(而非函数调用结束后销毁),但作用域仍限于函数内部。
- 修饰类成员(成员变量、成员函数):将成员 "共享化"(属于类而非对象),支持无对象访问。
17. C++中class和struct的区别
| 对比维度 | class |
struct |
|---|---|---|
| 默认成员访问权限 | 成员默认是 private(私有):类外无法直接访问,需通过公有成员函数访问。 |
成员默认是 public(公有):类外可直接访问成员变量和函数。 |
| 默认继承方式 | 继承时默认是 private 继承:基类的 public/protected 成员在派生类中变为 private。 |
继承时默认是 public 继承:基类的 public/protected 成员在派生类中保持原有访问权限。 |
18. 单例的自动释放,单例的单例的三种线程安全的实现方式
https://blog.csdn.net/m0_68381723/article/details/150264197?spm=1001.2014.3001.5501
19. string的底层实现原理
std::string通常包含 3 个核心成员(以 GCC 的basic_string为例):
- 字符指针(
char* _M_data) :指向存储字符串的动态数组(堆内存),数组以\0结尾(兼容 C 风格字符串)。- 当前长度(
size_t _M_length) :记录字符串的有效字符数(不含结尾的\0)。- 容量(
size_t _M_capacity) :记录当前动态数组的总容量(可容纳的最大字符数,不含结尾的\0),避免频繁扩容。为避免字符串频繁分配堆内存的开销, string的底层实现在历史上主要有三种方式
- Eager Copy(深拷贝)
- COW(Copy-On-Write 写时复制)
- SSO(Short String Optimization 短字符串优化)
https://blog.csdn.net/m0_68381723/article/details/150545494?spm=1001.2014.3001.5501
20. 谈谈深拷贝和浅拷贝,以及如何实现
| 类型 | 复制内容 | 指针成员行为 | 安全性 | 实现方式 |
|---|---|---|---|---|
| 浅拷贝 | 仅成员变量值 | 共享同一块堆内存 | 不安全(易崩溃) | 编译器默认生成 |
| 深拷贝 | 成员变量值 + 指针指向的内容 | 各自拥有独立的堆内存 | 安全 | 手动实现拷贝构造和赋值运算符 |
如何实现深拷贝?
需手动定义拷贝构造函数 和拷贝赋值运算符,对指针成员进行堆内存的独立复制。
21. string的赋值操作是深拷贝还是浅拷贝
std::string的赋值操作在逻辑上是深拷贝 (保证对象独立性),但底层可能通过 COW(旧实现)或 SSO(新实现)进行优化,减少不必要的内存复制,兼顾安全性和性能。对于使用者而言,无需关心底层优化细节,只需知道std::string的赋值会确保两个字符串相互独立,修改一个不会影响另一个,即表现为深拷贝的行为。
22. 什么时候重载赋值运算符与复制拷贝函数
当类的成员变量涉及堆内存分配 (如
new/delete)或其他需要手动管理的资源(如FILE*、锁等)时,默认的浅拷贝会导致问题:
- 浅拷贝仅复制指针地址,而非指针指向的资源,导致多个对象共享同一份资源。
- 析构时会重复释放资源(崩溃),或修改一个对象会影响其他对象(数据混乱)。
23. 序列式容器的insert,erase的出错情况以及出错原因
| 容器类型 | insert 后迭代器失效情况 |
erase 后迭代器失效情况 |
特殊注意事项 |
|---|---|---|---|
vector |
若扩容,所有迭代器失效;否则插入位置后的迭代器失效 | 被删除位置及之后的迭代器失效 | 扩容后原内存释放,迭代器变为野指针 |
list |
所有迭代器均有效(仅调整节点指针) | 仅被删除元素的迭代器失效,其他迭代器有效 | 插入 / 删除效率高,迭代器稳定性好 |
deque |
头部 / 尾部插入可能失效;中间插入几乎全失效 | 头部 / 尾部删除可能失效;中间删除几乎全失效 | 分段内存管理,迭代器稳定性差 |
24. 解决hash冲突的方法
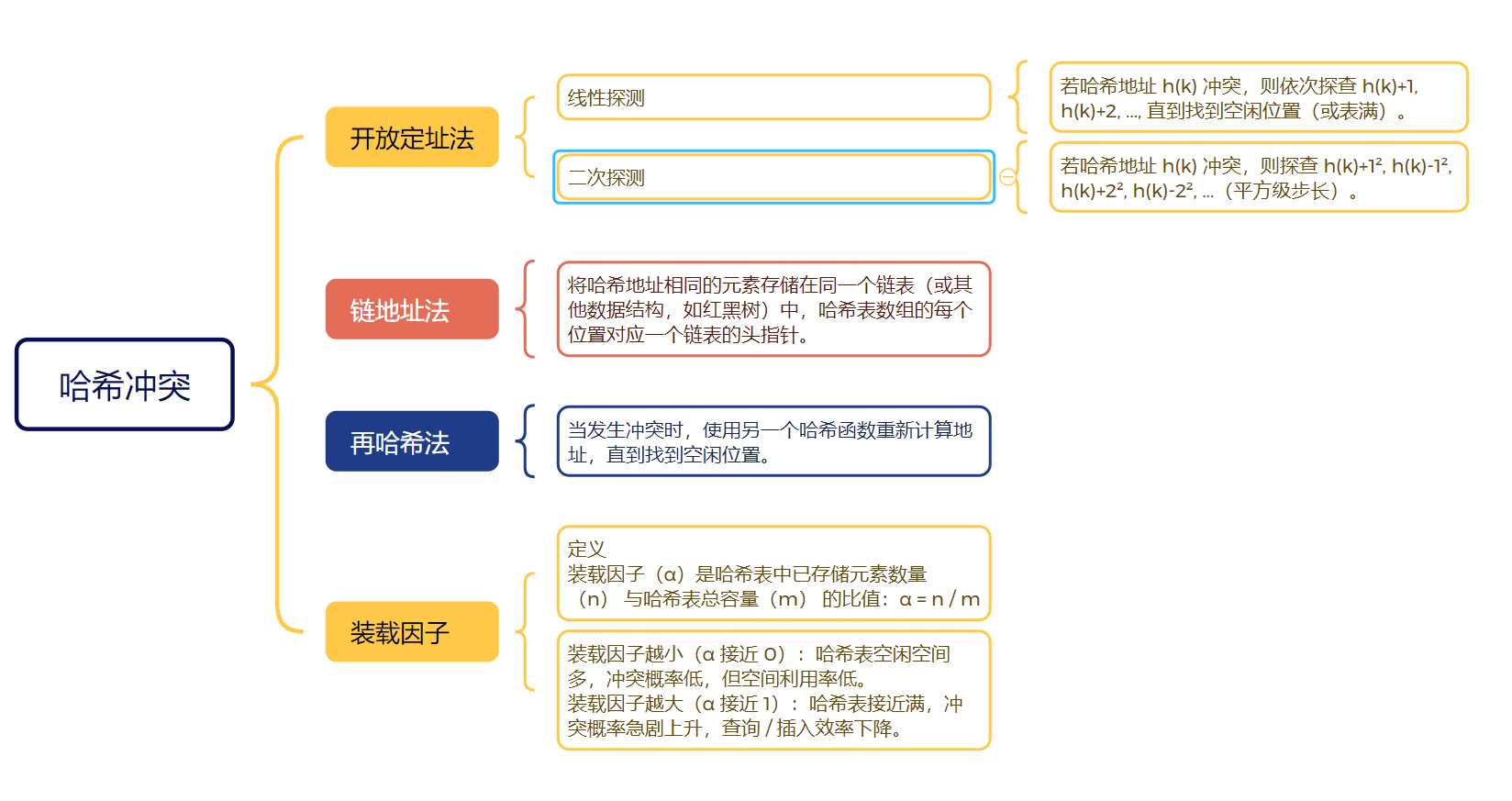
25. C++中类型转换有哪几种,简述一下他们的区别
| 转换类型 | 核心作用 | 安全性 | 适用场景 |
|---|---|---|---|
| 隐式转换 | 编译器自动完成的 "安全" 转换 | 较安全(可能丢失数据) | 基本类型小转大、派生类转基类 |
static_cast |
编译期验证的显式转换 | 较安全(需手动保证合理性) | 基本类型互转、void 指针转换、非 const 转 const |
const_cast |
修改指针 / 引用的 const 属性 | 依赖使用场景(可能 UB) | 移除 / 添加 const 限定(仅指针 / 引用) |
reinterpret_cast |
重新解释底层二进制 | 极不安全(依赖平台) | 无关类型指针转换、整数与指针互转 |
dynamic_cast |
运行时检查的类指针 / 引用转换 | 安全(有检查机制) | 多态场景下的向下转型 |
关键原则
- 优先使用隐式转换和
static_cast,避免reinterpret_cast(除非底层操作必需)。const_cast仅用于临时移除const(确保原对象可修改)。- 多态场景的向下转型必须用
dynamic_cast,避免类型错误。- 避免 C 风格强制转换(
(Type)expr),因其可能被编译器解析为任意一种显式转换,隐藏风险。
26. C++中函数指针和指针函数的区别
| 对比维度 | 函数指针(Pointer to Function) | 指针函数(Function Returning Pointer) |
|---|---|---|
| 本质 | 指针变量(指向函数的地址) | 函数(返回值为指针) |
| 声明形式 | 返回值类型 (*指针名)(参数列表) |
返回值类型* 函数名(参数列表) |
| 关键符号 | (*指针名) 必须加括号,强调 "指针" 属性 |
* 属于返回值类型,与函数名无关 |
| 作用 | 存储函数地址,动态调用函数 | 执行逻辑后返回一个指针 |
| 语法记忆 | "函数的指针" → 先看 "指针",后看 "函数" | "返回指针的函数" → 先看 "函数",后看 "返回指针" |
27. void*的大小是多少
void*(无类型指针)的大小与其他类型指针的大小相同 ,取决于当前系统的地址总线宽度(即 CPU 架构),与指针指向的数据类型无关。
28. 简述malloc和free的实现原理
内存池
malloc(size_t size)的作用是从堆中分配一块至少size字节的连续内存,并返回指向该内存的指针。已分配和释放的内存块通过特定数据结构(如空闲链表 )管理。
malloc会遍历空闲链表,寻找一块大小不小于size的空闲块(称为 "适配"),常见适配策略有:
- 首次适配(First Fit):从链表头开始,找到第一个足够大的块。
- 最佳适配(Best Fit) :遍历所有块,找到大小最接近
size的块(减少内存浪费)。- 下次适配(Next Fit):从上次分配的位置继续查找(减少链表头部的碎片检查)。
为管理内存块(区分已分配 / 空闲、记录大小等),
malloc会在每个内存块的头部 (用户可见指针的前几个字节)存储元数据(块大小、标记位(已分配 / 空闲)、指向前后空闲块的指针(用于维护空闲链表))**
free(void* ptr)**的作用是将malloc分配的内存块释放,使其重新变为空闲状态,可供后续malloc分配。可以获取块的大小和标记位,将其标记为 "空闲"。释放的块可能与相邻的空闲块(前向或后向)物理地址连续,此时需要将它们合并为一个大的空闲块,避免 "内存碎片"(大量小空闲块无法满足大内存分配需求)。
29.为何free的时候,只需要传递堆空间的地址就可以了
free会将ptr减去元数据区的大小(例如,若元数据占 8 字节,则metadata = (char*)ptr - 8),从而找到元数据的起始地址。
30. malloc申请内存后,怎么保证一定申请到了呢,你会申请完后直接使用这片内存吗
在使用
malloc申请内存时,不能保证一定能申请成功 ,因为堆内存资源是有限的(受系统内存大小、进程内存限制等因素影响)。因此,申请内存后必须先检查是否成功,再使用内存 ,否则可能因空指针(NULL)导致程序崩溃或未定义行为。
31. new/delete与malloc/free的异同
本题主要考察new和delete的底层原理, 可参考
https://blog.csdn.net/m0_68381723/article/details/150016761?spm=1001.2014.3001.5501
32. 指针和引用的区别, 引用作为函数返回时为什么不能返回局部变量
指针与引用的核心区别:指针是存储地址的变量(可空、可重指向),引用是变量的别名(必须初始化、不可改指向)。
引用不能返回局部变量:因局部变量在函数结束后销毁,返回的引用会成为 "悬空引用",访问时导致未定义行为。引用返回仅适用于生命周期长于函数的变量。
33. 内联函数和宏定义的区别
内联函数 :是编译器层面的函数,声明时需加
inline关键字,遵循函数的语法规则(参数类型、返回值、函数体用{}包裹)。编译时,编译器会尝试将函数调用替换为函数体代码(但不保证一定内联,取决于编译器优化策略)。宏定义:是预处理器层面的文本替换指令,无语法结构,仅在预编译阶段将 "宏名" 替换为 "替换文本"。替换过程不理解 C++ 语法(如类型、作用域),仅做字符串匹配。
34. 静态变量什么时候初始化
全局静态变量 / 类静态成员变量 :在程序启动(main 前) 初始化,仅一次。
局部静态变量 :在函数首次调用时初始化,仅一次,且线程安全(C++11 后)。
默认初始化:未显式初始化的静态变量均默认初始化为 0(或空指针),区别于自动变量(局部非静态变量,未初始化时为随机值)。
35. 动态编译和静态编译
| 对比维度 | 静态编译(静态链接) | 动态编译(动态链接) |
|---|---|---|
| 可执行文件体积 | 大(包含所有库代码) | 小(仅包含依赖信息) |
| 运行依赖 | 无(独立运行) | 依赖系统中存在对应的动态库 |
| 启动速度 | 快(无需加载外部库) | 稍慢(需动态加载库) |
| 库更新 | 需重新编译程序 | 无需重新编译(库接口兼容时) |
| 内存占用 | 高(每个程序单独包含库代码) | 低(多个程序共享同一份库内存) |
| 适用场景 | 需独立部署(如离线工具、嵌入式设备) | 多程序共享库(如系统工具、大型应用) |
36. inline函数的使用,缺点是什么
调试困难 : 内联函数在编译时被嵌入调用处,失去了独立的函数调用栈信息。调试时,无法在
inline函数内部设置断点(或断点行为异常),难以追踪函数执行过程。增加编译时间 : 由于
inline函数的代码需要在每个调用处展开,编译器需要处理更多代码量,会延长编译和链接时间(尤其是大型项目)。此外,inline函数通常需要在头文件中定义(而非仅声明),若函数修改,所有包含该头文件的源文件都需重新编译,进一步增加维护成本。
37. 为什么拷贝构造函数必须传引用而不能传值
拷贝构造函数的作用是用一个已存在的对象初始化另一个新对象 (如
A a(b);或A a = b;时调用)。如果拷贝构造函数的参数是传值 (即按值传递),那么在调用拷贝构造函数时,编译器需要先将实参对象拷贝一份 作为函数的形参。而拷贝实参的过程,又会再次调用拷贝构造函数(因为本质是 "用已有对象初始化新对象")。
这会形成一个无限循环:调用拷贝构造函数 → 传值需要拷贝实参 → 再次调用拷贝构造函数 → 再次拷贝实参 → ... 最终导致栈溢出(Stack Overflow)。
拷贝构造函数的三个调用时机 :
1.用一个已存在的对象初始化另一个新对象
**2.**值传递
3.函数的返回值是对象时, 会调用拷贝构造函数
38. 类中静态函数占用内存吗
| 函数类型 | 内存占用特点 | 与对象的关系 |
|---|---|---|
| 非静态成员函数 | 代码存放在全局代码段(仅一份),不占用对象内存 | 依赖对象(通过 this 指针访问成员) |
| 静态成员函数 | 代码存放在全局代码段(仅一份),不占用对象内存 | 不依赖对象(无 this 指针) |
39. 在构造函数初始化和在列表初始化的区别
| 对比维度 | 初始化列表 | 构造函数体内赋值 |
|---|---|---|
| 初始化时机 | 构造函数体执行前,直接初始化成员 | 成员先默认初始化,再在体内赋值 |
| 效率 | 更高(尤其自定义类型,少一次默认构造) | 更低(多一次默认构造和赋值) |
| 适用场景 | 所有成员(推荐优先使用),尤其是常量、引用、无默认构造的自定义类型 | 仅适用于可默认初始化且允许赋值的成员 |
| 必要性 | 某些场景必须使用(如常量、引用) | 不能用于必须在初始化时赋值的成员 |
40. 泛型编程的意义
泛型编程的核心意义是:在保证类型安全和执行效率的前提下,通过抽象通用逻辑,实现代码的最大化复用。它解决了 "为不同类型重复编写相似代码" 的问题,降低了开发和维护成本,同时提升了代码的通用性和抽象能力
41. 面向对象的三大特征的意义
封装解决了 "对象内部如何安全管理" 的问题,是模块化的基础;
继承解决了 "相似类如何复用代码" 的问题,是层次化抽象的核心;
多态解决了 "通用接口如何适配不同实现" 的问题,是灵活扩展的关键。
三者协同作用,使面向对象编程能够构建出高内聚、低耦合、易维护、可扩展的复杂软件系统,尤其适合模拟现实世界的复杂关系(如企业管理系统、游戏角色系统等)。
42. 类指针初始化为空指针后调用成员函数会出问题吗
非静态成员函数 :空指针调用属于未定义行为 。若函数未访问
this指针或非静态成员,可能 "看似正常",但存在崩溃风险;若访问了成员,则必然崩溃。静态成员函数 :空指针调用安全 (因不依赖
this指针)。
43. 基类和派生类的构造函数和析构函数的执行顺序
构造顺序:派生类依赖基类的功能,必须先确保基类初始化完成("先有基础,再有扩展")。
析构顺序:派生类可能使用基类的资源,需先释放派生类自身资源,再释放基类资源(避免基类资源提前释放导致派生类访问无效资源)。
44. 模板和实现可不可以不写在一个文件里面,为什么
模板的声明和实现通常必须放在同一个文件(如头文件),因为:
模板需要在使用时(实例化)才能生成具体代码,编译器必须同时看到声明和实现。
分离到不同文件会导致编译器在实例化时找不到实现,产生链接错误。
曾经写过一个RingBuffer模版类,因为分开了导致链接错误
45. 请简述你了解使用过的C++11的新特性
智能指针 , 自动类型推导(
auto和decltype),移动语义(&&右值引用和move)lambda 表达式 constexpr关键字
final禁止类被继承或虚函数被重写
46. 说一说你了解的关于lambda函数的全部知识
https://blog.csdn.net/m0_68381723/article/details/151080736?spm=1001.2014.3001.5501
47. C++中的智能指针,三种指针解决的问题及区别
https://blog.csdn.net/m0_68381723/article/details/150857222?spm=1001.2014.3001.5501
48. 请解释32位/64位系统具体指的是什么长度,对系统有何影响
寄存器位数(核心定义)
- 32 位系统:CPU 的通用寄存器(如 EAX、EBX)宽度为 32 位,一次最多能处理 32 位(4 字节)数据。
- 64 位系统:CPU 的通用寄存器(如 RAX、RBX)宽度为 64 位,一次最多能处理 64 位(8 字节)数据。
这是 "32 位 / 64 位" 的本质区别,决定了系统的基础运算能力。
内存寻址能力(最显著影响)
CPU 通过 "地址总线" 访问内存,地址总线的位数与寄存器位数通常一致,决定了系统能支持的最大内存容量:
- 32 位系统 :地址总线为 32 位,最大可寻址空间为
2^32 = 4GB(理论值)。实际中,由于系统预留部分地址给硬件(如显卡、BIOS),可用内存通常在 3.2~3.8GB 之间,无法识别超过 4GB 的内存。- 64 位系统 :地址总线为 64 位,理论最大寻址空间为
2^64 ≈ 18EB(1EB=1024PB),远超当前硬件极限(主流主板支持的内存通常为 128GB~2TB)。这是升级 64 位系统的核心动力之一 ------ 支持更大内存,满足高性能应用(如视频渲染、大数据处理)的需求。
49. 简述系统物理内存和虚拟内存之间的联系与区别
物理内存:指计算机硬件中的实际存储器(如 DDR4、DDR5 内存条),是 CPU 可直接访问的物理硬件空间,用于临时存储正在运行的程序和数据。其容量由硬件决定(如 8GB、16GB),速度快但成本较高。
虚拟内存 :是操作系统提供的一种内存抽象技术,通过软件将物理内存和部分磁盘空间(如 Windows 的 "页面文件"、Linux 的 "swap 分区")结合,为程序提供一个 "连续的、远超物理内存容量" 的虚拟地址空间。程序访问的是虚拟地址,由操作系统负责映射到实际的物理内存或磁盘。
50. 简述你熟悉的编译器的不同优化级别,以及编译器优化一些基本的思想
-O0(默认级别,无优化)
- 不进行任何优化,编译速度最快,生成的代码与源码逻辑几乎一一对应(便于调试,变量和语句顺序保留)。
- 适用于开发阶段,确保调试信息准确(如断点位置、变量值与源码一致)。
-O1(基础优化)
- 启用基础优化,如:
- 删除无用代码(死代码消除);
- 合并常量计算(常量折叠,如
2+3直接替换为5);- 简单的循环展开(减少循环控制开销);
- 寄存器分配优化(减少内存访问)。
- 编译时间适中,代码性能提升明显,仍保留大部分调试信息。
-O2(中度优化,最常用)
- 在
-O1基础上增加更多优化,如:
- 更复杂的循环优化(循环变量递增优化、循环合并);
- 函数内联(将小函数嵌入调用处,减少函数调用开销);
- 指令重排(调整指令顺序,利用 CPU 流水线);
- 消除冗余加载 / 存储(重复的内存读写合并)。
- 编译时间较长,性能接近最优,调试信息部分保留(部分变量可能被优化掉),是生产环境的默认选择。
51. 函数 bool less(float x,float y){return *(int*)&x < *(int*)&y;}是否能正确计算float的大小关系
- 浮点数与整数的二进制表示逻辑完全不同,符号位、指数位的含义在
int中不适用。- 对负数、特殊值(如 NaN)的比较结果必然错误,即使正数也存在边缘案例。
52. 谈一下模板template
https://blog.csdn.net/m0_68381723/article/details/150920924?spm=1001.2014.3001.5501
53. 空类里有什么函数, 空类占几个字节
默认构造函数(Default Constructor)
析构函数(Destructor)
拷贝构造函数(Copy Constructor)
拷贝赋值运算符(Copy Assignment Operator)
移动构造函数(C++11 及以后)
移动赋值运算符(C++11 及以后)
在 C++ 中,空类(没有任何成员变量和虚函数的类)的大小为 1 字节。这个字节不存储任何实际数据,仅用于保证每个对象拥有唯一的地址。
54. A继承B,C两个空类,对A进行强转成B,C,地址空间有什么变化呢
对于
class A : public B, public C {};(B和C都是空类),编译器会将A的大小优化为1字节 。此时,B和C作为基类,不会为A增加额外的内存开销。当A继承两个空类B和C时,由于空基类优化,A的内存布局中B和C没有额外的内存偏移。因此,将A强转为B*或C*时,地址值保持不变 ,与原A的地址完全一致。
55. public/private继承的关系及应用场景
56. 如果我有一块地址空间,我怎么在这个地址空间内调用构造函数
可通过定位 new 表达式(placement new) 实现。这种方式直接在指定地址调用对象的构造函数,而不分配新内存。
new (地址) 类型(构造函数参数);定位 new 构造的对象必须手动调用析构函数 (因
delete会释放内存,而此处内存是外部管理的,不能释放)
57. sizeof(A)是多少
cpp
class A{
int a;
short b;
double c;
virtual void func(){}
static int d;
};要确定类
A的大小,需分析其成员的内存布局(考虑内存对齐和虚函数表指针):1. 成员类型与内存占用
int a:占 4 字节。short b:占 2 字节。double c:占 8 字节。- 虚函数
virtual void fun():引入虚函数表指针(vptr),在 64 位系统占 8 字节,32 位系统占 4 字节。static int d:静态成员不占用类实例的内存(存于全局数据区)。2. 内存对齐规则(以 64 位系统为例)
内存对齐要求成员的起始地址是其大小的整数倍,类的总大小是最大成员对齐值(此处为
double的 8 字节)的整数倍。
a(4 字节):起始地址 0,占用 0~3 字节。b(2 字节):起始地址 4,占用 4~5 字节;因需对齐到 8 字节,填充 2 字节(6~7 字节)。c(8 字节):起始地址 8,占用 8~15 字节。vptr(8 字节):起始地址 16,占用 16~23 字节。总大小为 24 字节(满足 8 字节对齐)。
总结
- 64 位系统下,
class A的大小为 24 字节。- 32 位系统下,
vptr占 4 字节,总大小为 20 字节(需按 8 字节对齐,最终为 24 字节)。静态成员
d不影响类实例大小,虚函数表指针是影响大小的关键因素。
58. 什么是内存泄露,如何检测和防止
内存泄漏是指程序在运行过程中,动态分配的内存空间不再被使用时,未被正确释放,导致这部分内存无法被系统回收和再利用的现象。
Valgrind(Linux) :是一款强大的内存调试工具,其中的
memcheck工具可检测内存泄漏、内存越界等问题。例如在 Linux 终端使用valgrind --leak-check=full ./your_program命令运行程序,它会输出详细的内存泄漏报告,包括泄漏内存的大小、位置等信息。内存泄漏的防止方法 1. 使用智能指针 2. 减少动态内存分配的使用 3.严格遵循内存分配与释放的配对原则
59. 什么是野指针,什么情况下会产生野指针
野指针是指指向已释放内存或未合法初始化的指针,其指向的内存地址无效,操作野指针会导致程序崩溃、数据损坏等未定义行为。
cpp
int* p = new int(10);
delete p;
// p 未置空,此时 p 成为野指针
*p = 20; // 操作野指针,未定义行为60. 如何避免野指针
指针声明时立即初始化, 声明指针时,若暂时无合法指向,直接初始化为
nullptr(C++11 及以后)或NULL,避免指针值随机。使用智能指针替代裸指针
61.逗号运算符
在 C/C++ 等编程语言中,逗号运算符(,)是一种特殊的运算符,主要用于将多个表达式连接成一个表达式,并按从左到右的顺序依次执行这些表达式,最终返回最右边表达式的值。
逗号运算符的基本用法
-
表达式序列执行当多个表达式用逗号分隔时,编译器会从左到右依次执行每个表达式,忽略除最后一个表达式外的返回值,最终结果为最后一个表达式的值。
示例:
cppint a = 1, b = 2, c; c = (a++, b++, a + b); // 先执行a++(a变为2),再执行b++(b变为3),最后计算a+b=5,赋值给c // 结果:c = 5,a=2,b=3 -
在 for 循环中的应用 逗号运算符常用于
for循环的初始化或更新部分,实现多个变量的操作。示例:
cppfor (int i = 0, j = 10; i < j; i++, j--) { printf("%d, %d\n", i, j); } // 初始化:i=0、j=10;每次循环后i++且j-- -
注意优先级 逗号运算符的优先级非常低 ,低于赋值运算符和大部分其他运算符。如果需要将逗号表达式作为一个整体,通常需要用括号
()包裹。反例(错误用法):
cppint x = 1, 2, 3; // 错误!这里的逗号是变量声明分隔符,不是运算符 int y = (1, 2, 3); // 正确,y的值为3(最后一个表达式的值)
STL
STL包括哪些内容
vector底层实现
vector和deque的区别
vector和list的区别
vector,list在添加删除的效率方面有什么不同
释放vector的内存的处理方式
vector迭代器失效的情况有哪些
map和unordermap的区别
stl中的unordered_map和unordered_set有什么区别
自己实现unordered_map的话,你会考虑到什么问题呢
clear和erase的区别
迭代器失效问题
swap函数的作用
简单叙述一下STL容器相关知识,特征等
stl当中vector,list,map在内存中的数据结构有什么区别
erase的返回值
请你来介绍一下 STL 的空间配置器
STL 容器用过哪些,查找的时间复杂度是多少,为什么?
迭代器用过吗?什么时候会失效?
说一下STL中迭代器的作用,有指针为何还要迭代器?
说说 STL 中 resize 和 reserve 的区别
43. map,set是怎么实现的,为什么使用红黑树
map和set通常基于红黑树(Red-Black Tree) 实现。红黑树被选为
map和set的底层结构,是因为它完美匹配了这两种容器的核心需求:有序性、高效的动态操作(插入 / 删除)、可预测的性能
22. vector和dequeue的底层原理
https://blog.csdn.net/m0_68381723/article/details/150984440?spm=1001.2014.3001.5501
21. list 的特殊操作
在 C++ 标准库中,
std::list是基于双向链表 实现的容器(定义于<list>头文件),与数组式容器(如vector、array)相比,它的特殊操作主要源于链表的特性 ------插入、删除元素时无需移动其他元素,因此支持高效的任意位置操作。链表拼接(
splice)
作用 :将一个
list中的元素转移 到另一个list中(无需复制元素,仅调整指针),是list独有的高效合并操作,时间复杂度为 O(1) (与元素数量无关)。当然它也可以实现在一个list中的元素位置转移三种重载形式:
splice(pos, other):将整个other的元素转移到当前链表的pos位置前,other变为空。splice(pos, other, it):将other中it指向的单个元素转移到当前链表的pos位置前。splice(pos, other, first, last):将other中[first, last)范围内的元素转移到当前链表的pos位置前。反转链表(
reverse)去重(unique)排序(sort)移除元素(remove/remove_if)
动态多态(虚函数)
什么是虚函数
多态的使用条件
虚函数的原理是什么/工作机制
const在二级指针的应用
面向对象与面向过程的区别
拷贝构造的调用时机
为什么构造函数不能是虚函数
为什么静态函数不能是虚函数
为什么内联函数不能是虚函数
为什么友元函数不能是虚函数
为什么模板函数不能是虚函数
为什么全局函数不能是虚函数
如果在构造函数中调用虚函数,调用的过程是怎么样的
虚函数表的作用和存储地址
构造函数可以设置成虚函数吗
虚函数表里存放的内容是什么时候写进去的
虚函数和纯虚函数的区别
为什么析构函数一般写成虚函数
动态多态的实现过程和静态多态的实现过程
要实现动态联编(动态绑定),必须使用什么来调用虚函数
什么是多态,多态分为几种,多态的应用场景有哪些
C++的多态如何实现
virtual()=0是什么意思
虚函数和虚继承是怎么实现的
参考https://blog.csdn.net/m0_68381723/article/details/150610151?spm=1001.2014.3001.5501
Linux
1. 说说Linux中的常用的命令
cd ls pwd ll mkdir rm mv find grep ps -elf ping man sudo history
2. 创建软连接的命令是什么
在 Linux 中,创建软连接(符号链接,Symbolic Link)的命令是
ln -s,语法格式如下:
ln -s 源文件或目录 目标软连接名说明:
-s是关键选项,用于指定创建的是软连接(若省略-s,则创建硬连接)。- 源文件 / 目录:必须使用绝对路径或相对路径明确指定其位置(建议使用绝对路径,避免软连接因目录切换而失效)。
- 目标软连接名:创建的软连接文件的名称,指向源文件 / 目录。
3. /proc文件夹下放的是什么
/proc是 Linux 系统中的一个特殊虚拟文件系统(伪文件系统),它不占用实际磁盘空间,而是实时运行时动态生成的,用于提供内核和进程的实时信息接口 。用户和程序可以通过读取或写入/proc下的文件,获取系统状态、进程详情、硬件信息等,也可用于临时配置内核参数。CPU 信息 :通过
cat /proc/cpuinfo查看 CPU 核心数、型号、缓存大小等(例如判断服务器是否为多核)。内存使用 :
cat /proc/meminfo可获取总内存、空闲内存、缓存 / 缓冲区占用等细节(比free命令更全面)。系统负载与运行时间 :
/proc/loadavg查看系统平均负载,/proc/uptime了解系统运行时长。
4. Linux下有哪些文件类型
| 文件类型 | 标识符号(ls -l 首字符) |
描述与特点 | 典型示例 |
|---|---|---|---|
| 普通文件 | - |
存储文本、二进制数据或程序代码,是最常见的文件类型。 | /etc/passwd(文本)、/bin/ls(可执行程序) |
| 目录文件 | d |
用于管理文件和子目录,存储文件名与 inode 的映射关系。 | /home、/usr/local |
| 符号链接(软链接) | l |
类似快捷方式,指向其他文件 / 目录,可跨文件系统,目标可不存在。 | /usr/bin/python3 -> /usr/bin/python3.8 |
| 硬链接 | -(与普通文件相同) |
与目标文件共享 inode,是文件的 "别名",不可跨文件系统,目标必须存在。 | 用 ln 源文件 硬链接名 创建的文件 |
| 管道文件(匿名) | p |
用于进程间通信(IPC),单向传递数据,进程结束后自动消失,由 ` | ` 符号创建。 |
| 命名管道(FIFO) | p |
功能同管道,但可持久化存在,需手动创建(mkfifo),允许无关进程通信。 |
myfifo(用 mkfifo myfifo 创建) |
| 字符设备文件 | c |
按字符流访问的设备(如输入设备),数据传输以单个字符为单位。 | /dev/tty(终端)、/dev/input/mouse0(鼠标) |
| 块设备文件 | b |
按固定大小数据块访问的设备(如存储设备),适合高效读写大块数据。 | /dev/sda(硬盘)、/dev/sda1(分区) |
| 套接字文件 | s |
用于进程间网络或本地通信,是网络编程的基础(如 TCP/UDP 通信)。 | /var/run/docker.sock(Docker 套接字) |
5. Linux查看内存,磁盘,端口,进程,线程的命令有哪些
| 类别 | 常用命令 | 功能说明 | 示例 |
|---|---|---|---|
| 内存 | free |
查看系统内存使用概况(总内存、已用、空闲、缓存等) | free -h(人性化显示,单位为 GB/MB) |
top |
实时查看内存和 CPU 占用(按 M 键按内存排序) |
直接输入 top,按 q 退出 |
|
htop |
增强版 top,界面更直观(需安装) |
htop(支持鼠标操作,按内存排序更方便) |
|
cat /proc/meminfo |
查看内存详细信息(内核级数据,free 命令的数据源) |
cat /proc/meminfo |
| 类别 | 常用命令 | 功能说明 | 示例 |
|---|---|---|---|
| 磁盘 | df |
查看磁盘分区的空间使用情况(总容量、已用、可用) | df -h(人性化显示,如 /dev/sda1 的使用情况) |
du |
查看目录或文件的磁盘占用大小 | du -sh /home(查看 /home 目录总大小) |
|
lsblk |
列出块设备(硬盘、分区等)的布局信息 | lsblk(显示磁盘分区结构,如 sda 及其分区 sda1) |
|
fdisk -l |
查看磁盘分区表详细信息(需 root 权限) | sudo fdisk -l(显示所有磁盘的分区情况) |
| 类别 | 常用命令 | 功能说明 | 示例 | ||
|---|---|---|---|---|---|
| 端口 | netstat |
查看网络连接和端口监听状态(较旧,部分系统默认不安装) | netstat -tuln(显示所有监听的 TCP/UDP 端口) |
||
ss |
替代 netstat 的高效工具,查看端口和连接 |
ss -tuln(同 netstat,速度更快) |
|||
lsof -i :端口号 |
查看指定端口的占用进程 | lsof -i :8080(查看 8080 端口被哪个进程占用) |
|||
| `ss -lntu | grep 端口号 ` | 过滤查看指定端口是否在监听 | `ss -lntu | grep 3306`(检查 MySQL 端口是否监听) |
| 类别 | 常用命令 | 功能说明 | 示例 |
|---|---|---|---|
| 进程 | ps |
查看当前进程快照 | ps -ef(显示所有进程详细信息)、ps aux(BSD 风格,含资源占用) |
top |
实时查看进程资源占用(CPU、内存),按 P 键按 CPU 排序 |
top -p 1234(仅查看 PID 为 1234 的进程) |
|
pgrep 进程名 |
根据进程名查找 PID | pgrep python(查找所有 python 进程的 PID) |
|
pkill 进程名 |
根据进程名终止进程(类似 kill) |
pkill -9 python(强制终止所有 python 进程) |
|
kill PID |
终止指定 PID 的进程 | kill -9 1234(强制杀死 PID 为 1234 的进程) |
| 类别 | 常用命令 | 功能说明 | 示例 |
|---|---|---|---|
| 线程 | ps -T -p PID |
查看指定进程(PID)的所有线程 | ps -T -p 1234(查看 PID 1234 进程的线程,SPID 为线程 ID) |
top -H -p PID |
实时查看指定进程的线程资源占用(按 H 键切换线程模式) |
top -H -p 1234(实时监控 PID 1234 进程的线程 CPU / 内存占用) |
|
pstree -T PID |
以树状图显示进程的线程结构 | pstree -T 1234(查看 PID 1234 进程的线程树) |
|
cat /proc/[PID]/task/ |
查看进程的线程列表(内核级数据,每个子目录对应一个线程 ID) | ls /proc/1234/task/(列出 PID 1234 进程的所有线程 ID) |
6.是否在Linux系统下用过gdb或者别的调试工具,对gdb来说,用过哪些功能
除了gdb还用过valgrind, 配合 gdb 检测内存泄漏

7. 内存泄露怎么检查,怎么避免
Valgrind(Linux 首选) 其
memcheck工具可检测未释放内存、越界访问等问题。使用方法:
valgrind --leak-check=full --show-leak-kinds=all ./your_program # 运行程序并检查泄漏可以给上面的命令取别名(alias)
输出会显示泄漏内存的大小、分配位置(文件名 + 行号),例如:
==1234== 40 bytes in 1 blocks are definitely lost in loss record 1 of 1 ==1234== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==1234== by 0x400536: func (test.c:5) # 内存分配的位置 ==1234== by 0x400559: main (test.c:12)避免:核心是减少手动内存管理,用智能指针和容器,明确释放责任
8.如果是在一个循环内出现问题,使用gdb调试需要等待很长时间,应该怎么处理
设置条件断点(最常用)
利用
gdb的条件断点功能,让程序仅在循环满足特定条件(如达到目标次数、变量出现异常值)时暂停,跳过前面的无效循环。语法:
bashbreak 文件名:行号 if 条件表达式示例场景:
循环第
100000次时触发问题:
bashbreak loop.c:20 if i == 100000 # loop.c:20 是循环体内的关键行,i 是循环计数器循环中变量
buf为空指针时触发:
bashbreak process.c:50 if buf == nullptr # process.c:50 是使用 buf 的行数组索引越界(如
index >= 1000)时触发:
bashbreak array.c:30 if index >= 1000 # array.c:30 是访问数组的行优势:无需手动单步,程序会自动运行到满足条件时暂停,直接定位问题场景。
9. 什么是coredump文件?
coredump(核心转储)文件是程序崩溃时(如段错误、非法指令等),操作系统将进程的内存快照(包括代码、数据、堆栈、寄存器状态等)写入的文件。它相当于程序崩溃瞬间的 "现场照片",是定位崩溃原因的关键依据。
10. 如何用 gdb 调试 coredump 文件?
- 准备工作
- 确保程序编译时添加了
-g选项(保留调试符号,否则无法查看行号和变量)。 - 找到崩溃生成的
coredump文件(如/tmp/core-myprogram-1234-1690000000)。
-
加载
coredump文件到gdbgdb [程序路径] [coredump 文件路径]
示例:
gdb ./myprogram /tmp/core-myprogram-1234-1690000000- 核心调试命令
| 命令 | 作用 | 示例 |
|---|---|---|
bt / backtrace |
查看崩溃时的函数调用栈(关键!) | bt 显示从 main 到崩溃函数的调用链 |
frame N / f N |
切换到栈帧 N(查看上层函数的状态) |
f 1 切换到调用崩溃函数的上层函数 |
info locals |
查看当前栈帧的局部变量 | 定位变量是否异常(如野指针、越界值) |
print 变量名 |
打印指定变量的值 | p ptr 查看指针地址,p *ptr 查看指向内容 |
info registers |
查看崩溃时的寄存器状态 | 重点看 rip(当前指令地址)、rsp(栈指针) |
disassemble |
反汇编当前函数(无调试符号时用) | 结合 rip 定位崩溃的指令位置 |
四、常见场景分析示例
-
段错误(
SIGSEGV)Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x000055f8a5b7123 in func (ptr=0x0) at test.c:10
10 *ptr = 100; // 崩溃行:解引用空指针
(gdb) bt
#0 0x000055f8a5b7123 in func (ptr=0x0) at test.c:10
#1 0x000055f8a5b7150 in main () at test.c:20
- 分析:
func函数中ptr是NULL(空指针),解引用导致段错误,需检查main中调用func时传入的参数是否正确。
-
栈溢出(递归过深)
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x000055f8a5b7110 in recursive_func (n=100000) at test.c:5
5 recursive_func(n+1); // 无限递归
(gdb) bt
#0 0x000055f8a5b7110 in recursive_func (n=100000) at test.c:5
#1 0x000055f8a5b7110 in recursive_func (n=99999) at test.c:5
#2 0x000055f8a5b7110 in recursive_func (n=99998) at test.c:5
... // 大量重复的栈帧
- 分析:
recursive_func递归次数过多,导致栈溢出,需限制递归深度或改用循环。
五、注意事项
- 调试符号必须存在 :若程序被
strip命令剥离了调试符号(file命令显示stripped),gdb无法显示行号和变量名,需用原始未剥离的程序调试。 coredump文件可能很大 :尤其是内存占用高的程序,需确保磁盘空间充足(可通过ulimit -c限制大小)。- 多线程崩溃 :用
info threads查看所有线程状态,thread N切换到崩溃线程,再用bt查看其堆栈。 - 内核版本兼容 :若
coredump在不同内核版本的系统上生成,可能导致gdb解析异常,尽量在相同环境下调试。
总结
coredump 是程序崩溃的 "黑匣子",通过 gdb 加载后,核心是用 bt 查看崩溃调用栈,结合 print、info locals 分析变量状态,快速定位崩溃原因(如空指针、越界、栈溢出等)。对于偶发或难以复现的崩溃,coredump 是最有效的调试手段之一。
11. 什么时候使用静态库和动态库
| 维度 | 静态库(Static Library) | 动态库(Dynamic Library) |
|---|---|---|
| 链接时机 | 编译时(完整复制到可执行文件) | 运行时(仅记录引用,程序启动后加载) |
| 可执行文件体积 | 较大(包含库代码) | 较小(仅包含库引用) |
| 部署依赖性 | 无(独立运行) | 依赖库文件(缺失会导致 "找不到库" 错误) |
| 更新成本 | 需重新编译整个程序 | 直接替换库文件,无需重新编译程序 |
| 内存占用 | 多个程序重复加载,占用高 | 多个程序共享一份库,占用低 |
| 适用场景 | 独立部署、启动快、版本稳定 | 共享依赖、频繁更新、控制体积 |
总结
- 用静态库:程序需独立运行、依赖版本固定、对启动速度要求高,或库体积小。
- 用动态库:多程序共享依赖、需频繁更新库、希望减小可执行文件体积,或内存受限。
12. linux文件系统读入文件的过程
Linux 文件系统读文件的核心流程是:用户请求→权限校验→页缓存查找(命中则直接拷贝,未命中则磁盘 IO)→磁盘数据加载到页缓存→数据拷贝到用户态→返回结果。
13. 为什么文件描述符是一个整数
内核中维护了一个名为文件描述符表 (File Descriptor Table)的数据结构,用于记录进程打开的文件、套接字、管道等资源。这个表本质上是一个数组(或类似数组的结构),而数组的索引天然是整数。
14. 在Linux中, 什么是CFS
CFS(Completely Fair Scheduler,完全公平调度器) 是 Linux 内核中管理普通进程的核心调度器,通过 "虚拟运行时间" 和 "红黑树" 实现了进程间的公平调度,即让每个进程获得 "按比例" 的 CPU 运行时间,避免某些进程长期占用 CPU 而导致其他进程饥饿。
进程和线程
1. 进程和线程的区别
- 进程:操作系统分配资源(如内存、文件描述符)的基本单位,是一个独立运行的程序实例,拥有完整的地址空间、数据栈、文件句柄等资源。
- 线程:进程内的一个执行单元,共享所属进程的资源(内存、文件句柄等),仅拥有独立的栈空间和寄存器状态,是 CPU 调度的基本单位。
2. 多进程和多线程的区别,换句话说什么时候该用多线程,什么时候该用多进程
| 场景维度 | 多进程 | 多线程 |
|---|---|---|
| 资源共享 | 不共享资源(独立内存、文件句柄等) | 共享进程资源(内存、全局变量等) |
| 崩溃影响 | 一个进程崩溃不影响其他进程(隔离性好) | 一个线程崩溃可能导致整个进程崩溃 |
| 通信成本 | 需用 IPC 机制(如管道、共享内存),效率低 | 直接通过共享内存通信,效率高(需同步锁) |
| 资源开销 | 大(创建 / 销毁耗时,内存占用高) | 小(轻量级,适合高频创建销毁) |
| CPU 利用率 | 适合多核并行(充分利用多个 CPU 核心) | 适合并发(同一进程内多任务切换) |
用多线程:任务间共享数据多、通信频繁、资源有限、IO 密集型(追求低开销和高效协作)。
用多进程:任务间独立、需隔离崩溃风险、CPU 密集型、安全性要求高(追求稳定性和并行能力)。
3. 中断和异常的区别
| 类型 | 定义 | 触发源(本质区别) | 举例 |
|---|---|---|---|
| 中断 | 外部硬件(如设备、定时器)向 CPU 发送的异步信号,用于请求 CPU 处理外部事件。 | 外部硬件触发(与当前执行的指令无关) | 键盘按键、鼠标点击、磁盘 IO 完成、网络数据包到达 |
| 异常 | CPU 在执行指令过程中检测到的内部错误或特殊条件,是同步事件。 | 内部指令执行触发(与当前指令直接相关) | 除零错误、内存访问越界、调试断点、页缺失 |
4. 进程间通信方式有哪些
| 通信方式 | 速度 | 适用场景 | 特点 |
|---|---|---|---|
| 管道 / FIFO | 中 | 简单数据传递、亲缘 / 非亲缘进程 | 半双工,无结构数据 |
| 信号 | 快 | 事件通知、简单控制 | 信息少,异步 |
| 共享内存 | 最快 | 高频、大数据量通信 | 需同步机制 |
| 消息队列 | 中 | 按类型传递结构化数据 | 有消息边界 |
| 信号量 | 快 | 同步与互斥 | 不传递数据,仅控制访问 |
| 套接字 | 中 / 慢 | 跨主机或本地复杂通信 | 灵活,支持网络和本地 |
5. 线程间通信的方式
| 通信方式 | 核心原理 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 共享内存 | 线程共享进程的全局变量、堆内存、静态变量 | 所有需要传递数据的场景(最常用) | 无需数据拷贝,效率最高;使用简单 | 需同步机制避免数据竞争;多线程读写易导致混乱 |
| 互斥锁(Mutex) | 保证同一时间只有一个线程访问共享资源(互斥) | 保护临界区(如全局变量、共享缓存的读写) | 防止并发修改,确保数据一致性 | 滥用可能导致死锁;加锁解锁有轻微性能开销 |
| 条件变量 | 线程等待特定条件(如 "数据就绪"),满足时被唤醒 | 生产者 - 消费者模型;线程间协作(等待 / 通知) | 高效实现线程同步,避免忙等(减少 CPU 浪费) | 必须与互斥锁配合使用;需注意虚假唤醒问题 |
| 信号量 | 通过计数器控制并发线程数(同步或互斥) | 限制资源访问数(如连接池);生产者 - 消费者模型 | 功能灵活,可实现互斥或多线程并发控制 | 计数器管理复杂,易因操作不当导致逻辑错误 |
| 信号(Signal) | 向指定线程发送信号(如SIGUSR1)传递通知 |
简单事件通知(如终止线程、状态刷新) | 实现简单,适合异步通知 | 信号是进程级资源,易被其他线程抢占;携带信息少 |
| 线程局部存储(TLS) | 为每个线程分配独立变量副本(隔离数据) | 线程私有状态(如线程 ID、临时缓存) | 避免数据共享,无需同步;线程间互不干扰 | 不用于通信,仅用于隔离;变量生命周期与线程绑定 |
关键说明:
- 线程通信的核心是 **"共享内存 + 同步机制"**:共享内存负责数据传递,互斥锁 / 条件变量等负责保证安全性。
- 选择时优先考虑共享内存配合条件变量 / 互斥锁,这是线程通信的 "黄金组合",兼顾效率和安全性。
- 信号和 TLS 更多用于特定场景(通知或隔离),而非主要数据通信方式。
6. Linux程序运行找不到动态库.so文件的三种解决办法
1. 临时添加库路径(仅当前终端有效)
通过LD_LIBRARY_PATH环境变量指定动态库的搜索路径,适用于临时测试场景。操作步骤 :在终端中执行以下命令(将/path/to/library替换为.so 文件所在的目录路径):
bash
export LD_LIBRARY_PATH=/path/to/library:$LD_LIBRARY_PATH- 原理:
LD_LIBRARY_PATH是 Linux 动态链接器(ld.so)优先搜索的路径,添加后程序可临时找到库文件。 - 局限性:仅在当前终端生效,关闭终端后失效,且不建议在生产环境长期使用(可能引发路径冲突)。
2. 永久添加库路径(系统级配置)
通过修改动态链接器的配置文件,将库路径永久添加到系统搜索路径中,适用于长期使用的场景。操作步骤:
-
编辑
/etc/ld.so.conf.d/目录下的配置文件(建议新建一个以.conf为后缀的文件,如my_libs.conf):bashsudo vim /etc/ld.so.conf.d/my_libs.conf -
在文件中添加.so 文件所在的目录路径(例如
/usr/local/my_libs),保存退出。 -
执行以下命令更新动态链接器的缓存,使配置生效:
bashsudo ldconfig
- 原理:
/etc/ld.so.conf.d/目录下的.conf文件会被动态链接器读取,ldconfig命令会生成缓存文件/etc/ld.so.cache,系统启动时会加载这些路径。 - 优势:配置永久生效,适用于系统级别的库管理。
3. 将库文件复制到系统默认搜索路径
将.so 文件直接复制到系统默认的动态库搜索路径(如/usr/lib、/usr/lib64、/lib等),适用于通用库的安装。操作步骤 :使用cp命令将.so 文件复制到默认路径(以/usr/lib为例):
bash
sudo cp /path/to/your/library.so /usr/lib/之后更新动态链接器缓存:
bash
sudo ldconfig- 原理:系统默认会搜索
/usr/lib、/lib等目录,复制后库文件会被自动识别。 - 注意事项:避免随意复制文件导致系统库冲突,建议优先使用软件包管理器(如
apt、yum)安装库,手动复制仅作为临时方案。
7. 结束进程的方式有哪些
调用退出函数: exit(status):进程终止前会执行清理操作(如刷新缓冲区、调用atexit注册的函数),然后退出并返回status给父进程。
kill :向指定 PID 的进程发送信号(默认SIGTERM)。语法:kill [信号] <PID>示例:
cpp
kill 1234 # 发送SIGTERM终止PID=1234的进程
kill -9 1234 # 发送SIGKILL强制终止
kill -SIGINT 1234 # 发送SIGINT(等价于Ctrl+C)8. 什么是会话
一个终端通常对应一个会话,会话中的进程通过终端进行输入输出。
会话中只有一个前台进程组 ,可以接收终端的输入和信号(如
Ctrl+C发送的SIGINT)。其他进程组为后台进程组 ,不直接接收终端输入,但仍可通过终端输出。例如:在终端运行
ping baidu.com &,ping进程会进入后台进程组,而终端命令行所在的 shell 进程组为前台。
9. 守护进程和后台进程的区别,怎么创建这两个
后台进程的创建非常简单,只需在终端命令后加&,或通过Ctrl+Z暂停进程后用bg命令放入后台。
直接启动为后台进程
cpp
# 在命令后加&,进程进入后台运行
ping www.baidu.com & # 后台执行ping命令将前台进程转为后台
cpp
# 1. 前台运行进程(按Ctrl+C可终止)
ping www.baidu.com
# 2. 按Ctrl+Z暂停进程,此时进程状态为Stopped
# 输出:[1]+ Stopped ping www.baidu.com
# 3. 用bg命令将暂停的进程放入后台继续运行
bg %1 # %1表示jobs命令中显示的进程编号([1])守护进程的实现, 有两种方式, 一种是直接编程实现, 一种是通过工具实现
10. 写时拷贝
在传统的进程创建中,
fork()会为子进程复制父进程的全部内存数据(包括代码、数据、堆、栈等)。但实际上,子进程创建后往往会立即调用execve()加载新程序,导致之前的内存复制完全浪费。写时拷贝的优化逻辑是:
- 创建子进程时不立即复制内存:父进程和子进程共享同一块物理内存,内核通过页表(虚拟内存到物理内存的映射)标记这些内存页为 "只读"。
- 仅在修改内存时复制 :当父进程或子进程尝试写入共享内存页时,内核才会为修改方复制该内存页的副本,保证双方后续的修改互不影响(读操作仍共享内存)。
11. 自旋锁
| 特性 | 自旋锁(Spin Lock) | 互斥锁(Mutex) |
|---|---|---|
| 失败处理 | 自旋(循环尝试获取),不释放 CPU | 阻塞(放弃 CPU,进入等待队列) |
| 上下文切换 | 无(自旋时占用 CPU) | 有(阻塞时切换线程,唤醒时再次切换) |
| 适用场景 | 临界区执行时间极短,且处理器核心数充足 | 临界区执行时间较长,或无法预测 |
| 资源消耗 | 自旋时持续占用 CPU,可能导致 "忙等" 浪费资源 | 阻塞时不占用 CPU,但切换有开销 |
| 死锁风险 | 若持有锁的线程被调度出去(如被抢占),会导致其他线程长时间自旋 | 持有锁的线程阻塞时,其他线程进入等待队列,风险较低 |
自旋锁的适用场景
内核态同步:Linux 内核中大量使用自旋锁,因为内核代码的临界区通常很短(如操作数据结构),且内核线程阻塞的代价极高(可能导致系统响应延迟)。例如:内核中的链表、哈希表等数据结构的并发访问控制。
多处理器环境:自旋锁仅在多核心 CPU 上有意义。若在单核心 CPU 中使用,持有锁的线程会被调度器切换出去,导致其他线程无意义地自旋(直到时间片耗尽),反而浪费 CPU。
短临界区:当临界区操作时间远小于线程上下文切换时间(如简单的变量修改、指针操作),自旋等待的成本更低。
13. 什么是死锁?死锁产生的条件?怎么解决死锁问题
举个典型例子:
- 进程 A 持有资源 1,等待获取进程 B 持有的资源 2。
- 进程 B 持有资源 2,等待获取进程 A 持有的资源 1。此时,A 和 B 都无法继续执行,陷入无限等待,即发生死锁。
死锁产生的四个必要条件
死锁的发生必须同时满足以下四个条件,缺一不可:
互斥条件(Mutual Exclusion)持有并等待条件(Hold and Wait)不可剥夺条件(No Preemption)循环等待条件(Circular Wait)
解决死锁的方法
解决死锁的核心思路是破坏死锁产生的四个必要条件中的至少一个,具体方法可分为预防、避免、检测与恢复三类。
死锁避免(动态判断)在进程申请资源时,动态判断是否可能导致死锁,若可能则拒绝申请。最经典的算法是银行家算法(Banker's Algorithm)。
14. 信号量处理耗费多长时间,信号量同步会有什么问题
信号量的操作(如P/V,即wait/signal)涉及内核态与用户态的交互,其时间开销主要来自
系统调用开销 信号量操作(如semop系统调用)需要从用户态切换到内核态,完成后再切回用户态。一次上下文切换的时间通常在几百纳秒到几微秒(具体取决于 CPU 架构和系统负载)。
信号量同步可能存在的问题, 主要问题:死锁、优先级反转、惊群效应、性能损耗、逻辑漏洞等
15. sleep()调用后进程有哪些过程,在sleep()的过程中进程占用CPU了吗
sleep(n)调用后,进程会通过系统调用进入内核态,注册定时器并转为睡眠态(S),脱离 CPU 调度。休眠期间不占用 CPU,仅在定时器到期或被信号唤醒后,重新进入运行态等待 CPU 调度。
这一机制确保了 CPU 资源能被其他活跃进程有效利用,是多任务系统中进程协作的基础。
17. 什么是线程安全
线程安全(Thread Safety) 是指多线程环境中,一段代码(或函数、数据结构)在被多个线程同时访问或修改时,始终能表现出正确的行为,不会出现数据不一致、逻辑错误或不可预期的结果。
18. 多线程间共享数据,用什么方式来保存他们的安全性
通过 "锁" 限制同一时间只有一个(或一类)线程访问共享数据,是最经典的线程安全保障手段。
cpp
// C++示例:用mutex保护共享变量count
#include <mutex>
std::mutex mtx;
int count = 0;
void increment() {
std::lock_guard<std::mutex> lock(mtx); // 自动加锁,作用域结束后解锁
count++; // 临界区:安全修改共享变量
}19. 可重入函数是什么意思,为什么一定是线程安全的
可重入函数是指:函数在执行过程中可以被 "中断"(如被信号打断、或被其他线程 / 进程调用),且中断后再次进入该函数(重新执行)时,不会导致数据不一致或逻辑错误,最终能正确完成所有执行。
简单说,可重入函数允许 "重复进入",且多次进入的执行结果不受干扰。
可重入函数必然是线程安全的,但线程安全的函数不一定是可重入的。
20. 在Linux中如何区分fork后,哪个是子进程,哪个是父进程
核心区分依据:
fork()的返回值
fork()调用一次,会返回两次(父进程和子进程各返回一次),通过返回值的不同来区分:
- 父进程中 :
fork()返回子进程的进程 ID(PID,一个大于 0 的整数)。- 子进程中 :
fork()返回0。- 若
fork()失败(如资源不足),返回 **-1**(仅在父进程中返回,无新进程创建)。
21. 当子线程退出时,会向父线程发出什么信号
子线程退出时不会向父线程发送任何信号 。若需同步线程退出状态,需使用
pthread_join()、共享变量或条件变量等主动同步方式
22.什么是同步,异步。什么是阻塞,什么是非阻塞
同步和异步是指程序的执行方式。同步指的是调用者发出一个请求,被调用者进行
处理,处理完毕后返回结果给调用者,期间调用者会一直等待;而异步则是调用者发
出请求后不等待,而是继续执行其他操作,被调用者在处理完毕后通知调用者或者通
过回调函数来处理结果。
阻塞和非阻塞则是指调用者在等待结果时的状态。阻塞是指调用者在等待结果时会
被挂起,不能执行其他操作;非阻塞则是指调用者在等待结果时仍然可以执行其他操
作,不会被挂起。
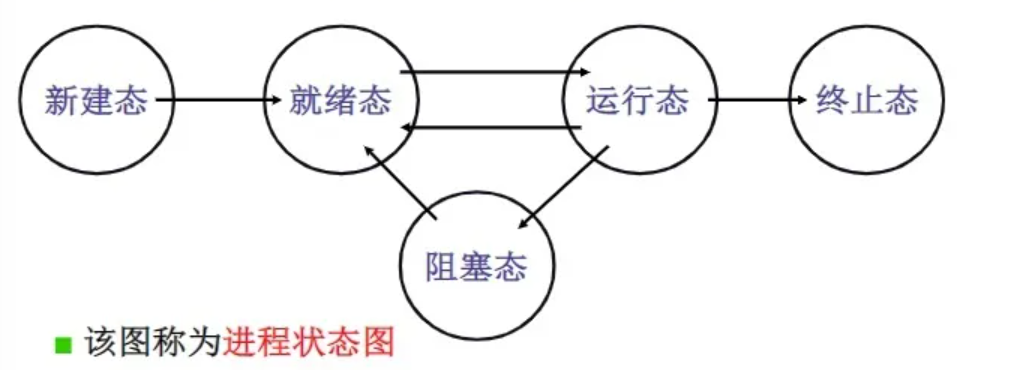
23. 进程的状态
24. 什么是孤儿进程,什么是僵尸进程,怎么避免僵尸进程
孤儿进程(Orphan Process)定义:当一个进程的父进程先于它退出,该进程就会成为孤儿进程。
僵尸进程(Zombie Process)定义 :当一个子进程退出后,其父进程未及时调用
wait()或waitpid()等系统调用来回收子进程的退出状态(如退出码、资源使用信息),此时子进程的进程控制块(PCB)仍会保留在系统中,成为僵尸进程。核心解决方案 :通过
wait()/waitpid()主动回收,或利用SIGCHLD信号异步处理,确保子进程退出状态被及时回收。
25. 解释一下用户态和核心态
| 特性 | 用户态(User Mode) | 核心态(Kernel Mode) |
|---|---|---|
| 权限级别 | 低权限(受限制) | 最高权限(无限制) |
| 可执行指令 | 只能执行非特权指令(如算术运算、局部变量操作等) | 可执行所有指令(包括特权指令,如修改 CPU 状态、操作硬件) |
| 资源访问 | 只能访问用户空间内存(进程私有数据),无法直接访问内核内存或硬件 | 可访问所有内存(用户空间 + 内核空间)和硬件资源(如磁盘、网卡) |
| 运行的程序 | 用户应用程序(如ls、chrome、自定义程序等) |
操作系统内核程序(如进程调度、内存管理、设备驱动等) |
26. 在什么场景下用户态和内核态会发生切换
用户态与内核态的切换本质是权限的交接,触发场景可归纳为:
- 用户主动请求:系统调用(用户程序需要内核服务)。
- 外部事件强制:硬件中断(设备通知内核处理事件)。
- 程序错误处理:异常(内核介入处理非法操作)。
- 系统资源管理:进程调度(内核切换运行的用户程序)。
27. 进程调度算法
面向作业: 先来先服务(First-Come, First-Served, FCFS)短作业优先(Shortest Job First, SJF)
面向 "用户体验": 时间片轮转(Round Robin, RR)优先级调度(Priority Scheduling)
28. 什么是分页,什么是分段?
1. 分页(Paging)
分页是将物理内存和进程的逻辑地址空间都分割成大小固定的块(称为 "页框" 和 "页面"),以实现内存的离散分配。
-
核心特点:
- 大小固定:页面(逻辑内存块)和页框(物理内存块)的大小完全相同(如 4KB、8KB,由系统设定)。
- 透明性:对用户(程序员)透明,用户无需关心分页细节,逻辑地址被硬件自动分割为 "页号 + 页内偏移量"。
- 地址映射:通过 "页表" 实现逻辑地址(页号)到物理地址(页框号)的映射,页内偏移量直接使用(因大小固定)。
- 解决的问题:主要解决内存 "外碎片" 问题(碎片总大小足够但单个碎片太小无法分配),提高内存利用率。
-
示意图:逻辑地址 → 页号(索引页表) + 页内偏移量 → 物理地址(页框号 + 页内偏移量)
2. 分段(Segmentation)
分段是将进程的逻辑地址空间按程序的逻辑结构(如函数、数据段、栈、堆等)分割成大小不固定的块(称为 "段"),每个段有独立的逻辑意义。
-
核心特点:
- 大小不固定:每个段的长度由其逻辑内容决定(如一个函数可能占 2KB,数据段可能占 10KB)。
- 用户可见:分段与程序结构对应(如代码段、数据段、栈段),用户编程时可能需要显式或隐式地使用段(如汇编中的段寄存器)。
- 地址映射:通过 "段表" 实现逻辑地址(段号 + 段内偏移量)到物理地址的映射,段表中记录段的起始物理地址和段长(需检查偏移量是否越界)。
- 解决的问题:主要满足程序的模块化需求,便于代码共享(如多个程序共享同一段库函数)、保护(对不同段设置读写执行权限)和动态增长(如栈 / 堆段可动态扩展)。
-
示意图:逻辑地址 → 段号(索引段表) + 段内偏移量 → 物理地址(段起始地址 + 段内偏移量,需检查偏移量 ≤ 段长)
29. 讲一讲你理解的虚拟内存
虚拟内存是操作系统为解决 "物理内存不足" 和 "内存高效利用" 设计的核心技术,本质是将物理内存与磁盘空间(虚拟内存分区 / 交换文件)结合,为进程提供远超实际物理内存的 "逻辑内存空间" 。
简单说,系统会让进程 "以为" 自己独占一块连续的大内存,实际却只把当前需要的部分加载到物理内存,暂时不用的数据存到磁盘,需要时再动态交换,既解决了大程序无法运行的问题,又提高了内存利用率。
30. 介绍一下几种典型的锁
1. std::mutex(互斥锁)
-
核心特性 :最基础的互斥锁,独占性 (同一时间仅允许一个线程持有锁),非递归(同一线程重复加锁会导致死锁)。
-
用法 :
lock():获取锁(若已被持有,当前线程阻塞)。unlock():释放锁(需与lock()配对,否则行为未定义)。try_lock():尝试获取锁(成功返回true,失败立即返回false,不阻塞)。
-
示例 :
cpp#include <mutex> std::mutex mtx; int shared_data = 0; void increment() { mtx.lock(); // 获取锁 shared_data++; // 临界区操作 mtx.unlock(); // 释放锁 } -
适用场景:保护短时间的临界区(如简单的共享变量修改),避免多线程竞态条件。
2. std::recursive_mutex(递归互斥锁)
-
核心特性 :允许同一线程多次获取锁 (内部维护 "加锁计数",解锁时需对应次数的
unlock()),解决同一线程递归访问临界区的死锁问题。 -
用法 :与
std::mutex一致(lock()/unlock()/try_lock()),但支持递归加锁。 -
示例 :
cpp#include <mutex> std::recursive_mutex rmtx; int shared_data = 0; void recursive_func(int depth) { rmtx.lock(); if (depth > 0) { shared_data++; recursive_func(depth - 1); // 同一线程再次加锁 } rmtx.unlock(); // 需与加锁次数匹配(此处递归几次,解锁几次) } -
适用场景:递归函数中访问共享资源,或同一线程需多次进入临界区的场景。
3. std::shared_mutex(读写锁,C++17 引入)
-
核心特性 :区分 "读操作" 和 "写操作",优化 "读多写少" 场景的性能:
- 读锁(共享模式) :通过
lock_shared()获取,允许多个线程同时持有,适合读取共享资源。 - 写锁(排他模式) :通过
lock()获取,仅允许一个线程持有,写操作时独占资源(读锁与写锁互斥)。
- 读锁(共享模式) :通过
-
用法 :
- 读操作:
lock_shared()+unlock_shared() - 写操作:
lock()+unlock() - 尝试获取:
try_lock_shared()(读)、try_lock()(写)
- 读操作:
-
示例 :
cpp#include <shared_mutex> std::shared_mutex smtx; int shared_data = 0; // 读操作(共享访问) int read_data() { std::shared_lock<std::shared_mutex> lock(smtx); // 自动获取读锁 return shared_data; } // 写操作(独占访问) void write_data(int val) { std::unique_lock<std::shared_mutex> lock(smtx); // 自动获取写锁 shared_data = val; } -
适用场景:共享数据以读为主、写较少的场景(如缓存、配置文件读取)。
4. std::lock_guard(自动锁管理)
-
核心特性 :RAII 风格的锁包装器 ,在构造时自动获取锁,析构时自动释放锁,避免手动
unlock()遗漏导致的死锁。 -
用法 :模板类,需传入锁对象(如
std::mutex、std::recursive_mutex)。 -
示例 :
cpp#include <mutex> std::mutex mtx; int shared_data = 0; void safe_increment() { std::lock_guard<std::mutex> lock(mtx); // 构造时 lock() shared_data++; // 临界区 } // 析构时自动 unlock(),即使发生异常也能释放 -
适用场景 :几乎所有需要加锁的场景,替代手动
lock()/unlock(),是 C++ 中推荐的锁管理方式。
5. std::unique_lock(灵活的自动锁)
-
核心特性 :比
std::lock_guard更灵活的 RAII 锁包装器,支持:- 延迟加锁(构造时不立即获取锁,后续通过
lock()手动获取)。 - 转移锁的所有权(可通过
std::move()传递)。 - 尝试加锁(
try_lock())、超时加锁(try_lock_for()/try_lock_until())。
- 延迟加锁(构造时不立即获取锁,后续通过
-
用法 :模板类,兼容各种锁类型(
mutex、recursive_mutex、shared_mutex等)。 -
示例 :
cpp#include <mutex> std::mutex mtx; void flexible_operation() { std::unique_lock<std::mutex> lock(mtx, std::defer_lock); // 延迟加锁 // ... 其他操作 ... lock.lock(); // 手动获取锁 // 临界区操作 // 无需手动 unlock(),析构时自动释放 } -
适用场景:需要灵活控制锁的获取 / 释放时机(如条件变量配合、锁的转移)。
6. std::scoped_lock(多锁同时管理,C++17 引入)
-
核心特性 :同时管理多个锁,确保原子性获取所有锁,避免多线程交叉加锁导致的死锁(如线程 1 先锁 A 再锁 B,线程 2 先锁 B 再锁 A)。
-
用法:构造时传入多个锁对象,自动按顺序获取所有锁,析构时释放。
-
示例 :
cpp#include <mutex> std::mutex mtx1, mtx2; void safe_operation() { // 同时获取 mtx1 和 mtx2,避免死锁 std::scoped_lock lock(mtx1, mtx2); // 内部保证获取顺序一致 // 同时操作两个锁保护的资源 } // 析构时同时释放所有锁 -
适用场景:需要同时持有多个锁的场景(如操作跨多个资源的数据)。
总结
C++ 中的锁机制围绕 "安全性" 和 "灵活性" 设计,核心推荐用法:
- 基础互斥用
std::mutex+std::lock_guard(简单安全)。 - 递归场景用
std::recursive_mutex。 - 读多写少用
std::shared_mutex+std::shared_lock/std::unique_lock。 - 多锁管理用
std::scoped_lock(避免死锁)。 - 灵活控制用
std::unique_lock(延迟加锁、转移所有权等)。
31. 有哪些页面置换算法
最近最久未使用算法(Least Recently Used, LRU)
- 思想 :选择最近一段时间内最久未被访问的页面换出(基于 "局部性原理",近期未用的页面未来可能也不用)。
- 优点:性能接近最优,能有效利用程序访问的局部性。
- 缺点:实现复杂(需记录每个页面的访问时间,如用双向链表 + 哈希表,每次访问需更新位置),开销较大。
- 示例 :页面访问记录为
[1, 2, 3, 2, 1],当前内存[1, 2, 3],最久未用的是3,换出3。先进先出算法(First-In-First-Out, FIFO)最佳置换算法(Optimal, OPT) ......
32. 操作系统在进行线程切换时需要进行哪些动作
1. 触发线程切换的条件
线程切换通常由以下场景触发,切换前需先进入内核态(通过中断、系统调用等):
- 线程的时间片用完(抢占式调度);
- 线程主动阻塞(如调用
sleep()、等待锁 / IO 操作);- 更高优先级的线程就绪(抢占式调度);
- 线程执行结束或异常退出。
2. 保存当前线程的上下文(Context Saving)
当前线程(被切换出的线程)的执行状态需要被完整保存,以便后续恢复时能从断点继续执行。保存的上下文包括:
- CPU 寄存器 :
- 通用寄存器(如
eax、ebx等,存储线程执行中的临时数据);- 程序计数器(PC/IP,记录下一条要执行的指令地址);
- 栈指针(SP,指向当前线程的栈顶位置);
- 状态寄存器(如标志位寄存器,记录运算结果状态、中断屏蔽等)。
- 线程私有数据 :
- 线程控制块(TCB,Thread Control Block)中的信息,如线程状态(运行 / 就绪 / 阻塞)、优先级、栈地址、私有内存等。
- 内核态相关状态 :
- 若线程在切换时处于内核态(如执行系统调用),还需保存内核栈信息、页表寄存器(如 CR3,指向线程的页表)等。
3. 选择下一个要运行的线程(调度决策)
操作系统的调度器(Scheduler)根据预设的调度算法(如时间片轮转、优先级调度、多级反馈队列等),从就绪队列中选择下一个要执行的线程(目标线程)。
- 调度器需考虑线程优先级、等待时间、资源需求等因素,确保系统性能(如响应速度、吞吐量)最优。
4. 恢复目标线程的上下文(Context Restoring)
将目标线程的上下文从其 TCB 中加载到 CPU 和相关硬件中,使其继续执行:
- 恢复 CPU 寄存器:将保存的通用寄存器、PC、SP、状态寄存器等数据写入实际硬件寄存器;
- 切换内存空间:若目标线程与当前线程属于不同进程(线程切换跨进程),需更新页表寄存器(CR3),切换到目标进程的地址空间(虚拟内存映射);
- 更新内核态状态:恢复目标线程的内核栈、中断屏蔽位等,确保内核态操作的连续性。
5. 切换到用户态并继续执行
完成上下文恢复后,操作系统从内核态切换回用户态,CPU 开始执行目标线程的下一条指令(由 PC 寄存器指定的地址),目标线程进入 "运行" 状态。
33. 什么是软中断,什么还硬中断
硬中断是 "硬件→CPU" 的通知机制,用于快速响应外部设备事件,优先级高,处理需简洁(避免阻塞);
软中断是 "软件→CPU" 或 "内核内部" 的通知机制,用于系统调用、异常处理或延迟任务,灵活性更高。
34. CPU使用率和CPU负载是指什么,它们之间有什么关系
1. CPU 使用率
- 指一段时间内(如 1 秒)CPU 用于执行任务的时间占比,范围 0%~100%(多核心则按核心数叠加,如 4 核 CPU 最大使用率 400%)。
- 例如:CPU 使用率 80%,意味着该时间段内 CPU 有 80% 的时间在处理任务,20% 的时间处于空闲状态。
- 核心关注 "CPU 当前是否在干活、干得多满",是对已完成工作的统计。
2. CPU 负载
- 指某一时刻等待 CPU 处理的任务数量(包括正在 CPU 上运行的任务 + 排队等待 CPU 的任务)。
- 例如:CPU 负载为 3,意味着当前有 3 个任务需要 CPU 处理(可能 1 个正在运行,2 个排队)。
- 核心关注 "CPU 有多少活要干",是对待处理任务的压力统计。
线程池
解释一下进程同步和互斥,以及如何实现进程同步和互斥
讲一下线程池, 线程池有什么好处
为什么网络IO会被阻塞
IO模型有哪些
同步和异步的区别
阻塞和非阻塞的区别
同步,异步,阻塞,非阻塞的IO的区别
到底什么是reactor
谈一下对多线程的理解,如生产者-消费者问题
https://blog.csdn.net/m0_68381723/article/details/151643767?spm=1001.2014.3001.5501
网络编程
1. 简述七层模型和四层模型
OSI 七层模型(开放系统互连参考模型)
核心定位:理论化的通用网络架构,将网络通信流程拆分为 7 个独立层次,每层专注特定功能,通过接口协作。
从下到上(物理层→应用层)及核心功能:
- 物理层:传输原始比特流(如网线、光纤的电 / 光信号),定义硬件接口(接口类型、传输介质)。
- 数据链路层:将比特流封装为帧,处理物理层错误(校验)、实现局域网内寻址(MAC 地址)。
- 网络层:实现跨网络的路由转发(IP 地址),核心是路径选择和数据包交付。
- 传输层:提供端到端的可靠 / 高效传输(TCP/UDP),处理端口寻址、流量控制。
- 会话层:建立、管理和终止通信会话(如连接建立、会话同步)。
- 表示层:处理数据格式转换(如加密、压缩、编码),确保接收方能解析数据。
- 应用层:为应用程序提供网络服务(如 HTTP、FTP、DNS 等协议)。
TCP/IP 四层模型(互联网参考模型)
核心定位:实际互联网的底层架构,简化七层模型,合并冗余层次,更注重实用性和可实现性。
从下到上(网络接口层→应用层)及核心功能:
- 网络接口层(对应七层的物理层 + 数据链路层):负责硬件接口和局域网内数据传输(如 MAC 地址、帧封装)。
- 网络层(与七层网络层一致):核心是 IP 协议,实现跨网络路由和数据包转发。
- 传输层(与七层传输层一致):提供 TCP/UDP 协议,负责端到端传输控制。
- 应用层(对应七层的会话层 + 表示层 + 应用层):整合上层功能,直接为应用提供服务(如 HTTP、DNS、SMTP 等)。
2. 请描述一下从输入URL到显示页面的全过程
1. 输入 URL 并解析
用户在浏览器地址栏输入 URL(如
https://www.example.com/path),浏览器首先解析 URL 的结构:
- 协议 :确定使用的协议(如
http/https/ftp等,这里以https为例)。- 域名 :提取服务器域名(如
www.example.com),忽略路径(/path)、端口(默认https为 443,http为 80)等。2. DNS 域名解析:将域名转换为 IP 地址
浏览器无法直接通过域名访问服务器,需先通过 DNS(域名系统)查询域名对应的 IP 地址(如
192.0.2.1),步骤如下:
- 浏览器缓存查询:检查本地缓存(浏览器缓存、操作系统缓存),若有该域名的 IP 记录,直接使用。
- 本地 DNS 服务器查询:若缓存未命中,向本地 DNS 服务器(如路由器分配的 ISP DNS)发送查询请求。
- DNS 递归查询:本地 DNS 服务器若自身无记录,会向上级 DNS 服务器(根域名服务器→顶级域名服务器→权威域名服务器)递归查询,最终获取 IP 地址并返回给浏览器。
3. 建立 TCP 连接(三次握手)
浏览器通过解析到的 IP 地址和端口(如
192.0.2.1:443)与目标服务器建立 TCP 连接:
- 第一次握手:浏览器发送 SYN(同步)报文,请求建立连接。
- 第二次握手:服务器收到 SYN,返回 SYN+ACK(同步 + 确认)报文,同意连接。
- 第三次握手:浏览器发送 ACK(确认)报文,连接正式建立。
4. 建立 TLS/SSL 连接(HTTPS 特有)
若协议为
https,需在 TCP 连接基础上通过 TLS/SSL 协议建立加密连接(确保数据传输安全):
- 浏览器发送客户端支持的加密算法列表、随机数等。
- 服务器选择加密算法,返回服务器证书(含公钥)和随机数。
- 浏览器验证证书有效性(通过 CA 机构),生成对称加密密钥,用服务器公钥加密后发送给服务器。
- 服务器用私钥解密获取对称密钥,双方后续通信使用该密钥加密。
5. 发送 HTTP 请求
连接建立后,浏览器向服务器发送 HTTP 请求(以
GET请求为例),请求内容包括:
- 请求行 :
GET /path HTTP/1.1(方法、路径、协议版本)。- 请求头 :
Host: www.example.com、User-Agent: Chrome/...、Cookie等(告知服务器客户端信息、身份等)。- 请求体 :
GET请求通常为空,POST请求会包含表单数据等。6. 服务器处理请求并返回响应
服务器接收到 HTTP 请求后,按以下流程处理:
- 服务器端程序(如 Nginx、Apache)解析请求,根据路径(
/path)和参数找到对应的处理逻辑(如调用后端 API、查询数据库)。- 处理完成后,生成 HTTP 响应,包括:
- 状态行 :
HTTP/1.1 200 OK(协议版本、状态码,200 表示成功)。- 响应头 :
Content-Type: text/html(数据类型)、Content-Length(数据长度)、Set-Cookie等。- 响应体:主要内容(如 HTML 文档、CSS/JS 文件、图片等二进制数据)。
7. 浏览器接收响应并解析渲染页面
浏览器接收到服务器返回的响应数据(以 HTML 为例),开始解析并渲染页面,核心步骤包括:
- HTML 解析:将 HTML 文本转换为 DOM 树(文档对象模型),标记出标签、属性、文本等结构。
- CSS 解析 :解析
<style>标签或外部 CSS 文件,生成 CSSOM 树(CSS 对象模型),记录样式规则。- 构建渲染树(Render Tree) :结合 DOM 树和 CSSOM 树,筛选出可见元素(如忽略
display: none的元素),并为每个元素应用样式,形成渲染树。- 布局(Layout):计算渲染树中每个元素的位置和大小(如宽高、坐标),确定在页面中的布局。
- 绘制(Paint):按布局结果,将元素的像素绘制到屏幕(如颜色、边框、阴影等)。
- 合成(Composite) :若页面包含分层元素(如
z-index、动画),浏览器会将各层绘制结果合成最终画面,显示在屏幕上。8. 断开连接(四次挥手)
页面渲染完成后,若 TCP 连接不再使用,会通过 "四次挥手" 断开:
- 浏览器发送 FIN 报文,请求关闭连接。
- 服务器返回 ACK,确认收到 FIN(此时服务器可能仍在发送数据)。
- 服务器数据发送完毕,发送 FIN 报文,请求关闭。
- 浏览器返回 ACK,连接正式关闭。
总结
整个过程可简化为:URL 解析→DNS 查 IP→建立连接(TCP+TLS)→HTTP 请求→服务器响应→浏览器渲染→断开连接。其中,DNS 缓存、CDN 加速(部分场景)、浏览器缓存等机制会优化流程,减少耗时,提升用户体验。
3. 简述一下socket的编程流程
服务器
- 创建 Socket :调用
socket()函数,指定协议族(如 IPv4 用AF_INET)、传输类型(TCP 用SOCK_STREAM),返回 Socket 描述符(文件句柄)。- 绑定(bind) :调用
bind()函数,将 Socket 与本地 IP 地址和端口号绑定(如127.0.0.1:8080),确保客户端能通过该地址找到服务器。- 监听(listen) :调用
listen()函数,将 Socket 设为监听状态,指定最大等待连接数(如允许 5 个客户端排队)。- 接受连接(accept) :调用
accept()函数,阻塞等待客户端连接;当客户端连接时,返回一个新的 Socket 描述符(用于与该客户端通信),原 Socket 继续监听其他连接。- 收发数据(recv/send) :通过
accept()返回的新 Socket,用recv()接收客户端数据,用send()向客户端发送数据。- 关闭连接(close) :通信结束后,调用
close()关闭与客户端的 Socket,若服务器停止服务,关闭监听 Socket。客户端
- 创建 Socket :同服务器端,调用
socket()创建客户端 Socket。- 连接服务器(connect) :调用
connect()函数,传入服务器的 IP 地址和端口号,与服务器建立 TCP 连接(触发三次握手)。- 收发数据(send/recv) :连接建立后,用
send()向服务器发送数据,用recv()接收服务器返回的数据。- 关闭连接(close) :通信结束后,调用
close()关闭客户端 Socket(触发四次挥手)。
write阻塞的原因有哪些
1. 发送缓冲区(Output Buffer)已满
每个 Socket 都有操作系统管理的发送缓冲区 ,
write函数的核心逻辑是把应用层数据拷贝到这个缓冲区,再由 OS 异步发送到网络。
- 若缓冲区已满(比如网络传输速度远慢于应用层写入速度,或之前发送的数据还没被 OS 推送出去),
write会阻塞,直到缓冲区有空闲空间(已发送的数据被清空)。- 例:用 TCP 给低速网络的对端高频发送大文件,缓冲区很快被占满,后续
write调用会阻塞。2. TCP 流量控制(接收方窗口为 0)
TCP 有流量控制机制,接收方会通过 TCP 报文头的 "窗口大小" 字段,告知发送方自己当前的接收缓冲区剩余容量。
- 若接收方的接收缓冲区已满(比如对端处理数据的速度跟不上接收速度),会向发送方通告 "窗口大小 = 0"。
- 发送方收到后会暂停发送,此时调用
write会阻塞,直到接收方处理完部分数据、更新窗口大小(发送窗口更新报文)为非零值。
4. IO多路复用
select,poll,epoll的区别,epoll的底层是如何实现的
epoll边沿触发具体实现方式
LT和ET的区别,应用场景
proactor和reactor的区别和特点
https://blog.csdn.net/m0_68381723/article/details/152508348?spm=1001.2014.3001.5501
5. 调用send函数发送数据不全怎么办
解决方法:循环发送
核心思路是:每次发送剩余未发送的数据,直到所有数据都被写入发送缓冲区
6. 1G的文件从A机器发送到B机器,怎么发
发送大文件(如 1G)需要考虑分块传输 (避免内存溢出)、进度确认 (确保数据完整性)和效率优化(如合理缓冲)。以下是基于 TCP 协议的 C 语言实现,分为服务器端和客户端,支持断点续传基础逻辑(通过文件偏移量定位)。
核心思路
- 分块读取:将 1G 文件按固定块大小(如 4KB)分多次读取,避免一次性加载到内存。
- 循环发送 :每次发送一块数据,确保所有字节发送完成(处理
send返回值小于请求长度的情况)。- 进度反馈:打印发送 / 接收进度,方便观察传输状态。
- 简单校验:通过文件大小确认传输完整性(实际场景可加 CRC 等校验)。
7. 什么是TCP的粘包问题?怎么解决
为什么会出现粘包?
TCP 是 "流协议",其核心特性决定了粘包的必然性:
- 字节流特性:TCP 将数据视为连续的字节流,不保留数据包的边界信息(发送方的 "一包数据" 对 TCP 来说只是一串字节)。
- Nagle 算法:为提高效率,TCP 会缓冲小数据包,合并后再发送(减少网络交互次数),可能导致多个小包被合并。
- 接收方缓冲 :接收方的 TCP 缓冲区会累积数据,应用层
recv调用可能一次性读取多个数据包的内容(取决于读取时机和缓冲区大小)。示例:
- 发送方分 3 次发送:
"hello"、"world"、"!"- 接收方可能一次读到:
"helloworld!"(完全粘包),或"hellowor"+"ld!"(部分粘包)。给数据包添加明确的边界标识,让接收方能够正确拆分多个数据包。常用方案如下:
1. 固定长度(定长包)
- 原理:约定每个数据包的固定长度(如 1024 字节),不足部分用填充符(如空格、0)补齐。
- 接收方处理:每次读取固定长度的数据,若读取到填充符则忽略(或截断)。
- 优点:实现简单。
- 缺点:灵活性差(不适合长度多变的数据),填充符浪费带宽。
- 适用场景:数据长度固定的场景(如物联网传感器固定格式数据)。
2. 长度前缀(包头 + 包体)
- 原理 :每个数据包分为两部分:
- 包头:固定长度(如 4 字节),记录包体的字节数(用整数表示)。
- 包体:实际数据(长度由包头指定)。
- 接收方处理 :
- 先读取固定长度的包头,解析出包体长度
len。- 再读取
len字节的包体,完成一个数据包的接收。- 优点:灵活适配任意长度数据,是最常用的方案。
- 示例 :
- 发送
"hello"(5 字节):包头为0x00000005(4 字节),包体为"hello",整体共 9 字节。- 接收方先读 4 字节得
5,再读 5 字节得"hello"。
8. Tcp和udp的区别
| 对比维度 | TCP | UDP |
|---|---|---|
| 连接方式 | 面向连接(需先建立连接,再传输数据) | 无连接(直接发送数据,无需建立连接) |
| 可靠性 | 可靠传输(保证数据不丢失、不重复、按序到达) | 不可靠传输(不保证数据交付,可能丢失、乱序) |
| 传输效率 | 效率较低(需处理确认、重传、流量控制等) | 效率较高(无额外控制开销,直接发送) |
| 数据边界 | 无边界(字节流,可能粘包) | 有边界(数据报独立,一次发送一个完整包) |
| 拥塞控制 / 流量控制 | 支持(避免网络拥塞,控制发送速率) | 不支持(发送速率不受限,可能导致拥塞) |
| 首部开销 | 较大(固定 20 字节,可选扩展) | 较小(固定 8 字节) |
| 适用场景 | 对可靠性要求高的场景(文件传输、网页加载等) | 对实时性要求高的场景(视频通话、游戏等) |
9. tcp三次握手建立连接的过程,三次握手过程通信双方各自的状态
| 阶段 | 客户端状态 | 服务器状态 | 核心动作 |
|---|---|---|---|
| 初始状态 | CLOSED |
LISTEN |
服务器等待连接,客户端未发起 |
| 第一次握手后 | SYN_SENT |
SYN_RCVD |
客户端等待服务器确认 |
| 第二次握手后 | ESTABLISHED |
SYN_RCVD |
客户端确认连接,服务器等待最终确认 |
| 第三次握手后 | ESTABLISHED |
ESTABLISHED |
连接建立,双方可传输数据 |
10. 为什么需要三次握手?
核心是 "双向确认":
- 第一次握手:服务器确认 "客户端能发"。
- 第二次握手:客户端确认 "服务器能收且能发"。
- 第三次握手:服务器确认 "客户端能收"。三次交互后,双方才能确定:"我能发给你,且能收到你的回复",为后续可靠数据传输奠定基础。若仅两次握手,服务器无法确认客户端是否能收到自己的响应,可能导致服务器资源浪费(如为无效连接维持状态)。
11. tcp四次挥手的过程,四次挥手过程中通信双方各自的状态
| 阶段 | 主动关闭方状态 | 被动关闭方状态 | 核心动作 |
|---|---|---|---|
| 初始状态 | ESTABLISHED |
ESTABLISHED |
双方正常通信 |
| 第一次挥手后 | FIN_WAIT_1 |
CLOSE_WAIT |
主动方等待确认,被动方准备关闭 |
| 第二次挥手后 | FIN_WAIT_2 |
CLOSE_WAIT |
主动方等待被动方的 FIN |
| 第三次挥手后 | TIME_WAIT |
LAST_ACK |
被动方等待最终确认 |
| 第四次挥手后 | TIME_WAIT→CLOSED |
CLOSED |
被动方先关闭,主动方等待后关闭 |
12. 为什么需要四次挥手?
核心是 "全双工通信的双向关闭":
- 第一次挥手:主动方告知 "我不再发数据"。
- 第二次挥手:被动方确认 "收到你的关闭请求,我还可能发数据"。
- 第三次挥手:被动方告知 "我也不再发数据"。
- 第四次挥手:主动方确认 "收到你的关闭请求,连接可终止"。
13. 简述一下tcp的超时机制,分类
数据包超时重传(最核心)
- 场景 :发送方发送数据报文(如 DATA、SYN、FIN 等)后,未在 **超时时间(RTO,Retransmission Timeout)**内收到对应 ACK。
- 处理 :
- 重传该数据包,并重设超时计时器(重传后的 RTO 通常会指数退避,如加倍,避免网络拥塞加剧)。
- 若多次重传(通常 5 次,即
MAX_RETRIES)仍失败,则判定连接异常,终止连接。- 示例 :
- 客户端发送
SYN(三次握手第一步)后,未收到服务器的SYN+ACK,超时后重传SYN。- 发送方发送数据段
seq=100,未收到ack=200(假设数据长度 100),超时后重传该数据段。
14. tcp通信过程的状态是如何变化的
| 阶段 | 客户端状态流转 | 服务器状态流转 |
|---|---|---|
| 连接建立 | CLOSED→SYN_SENT→ESTABLISHED |
LISTEN→SYN_RCVD→ESTABLISHED |
| 数据传输 | ESTABLISHED |
ESTABLISHED |
| 连接关闭 | ESTABLISHED→FIN_WAIT_1→FIN_WAIT_2→TIME_WAIT→CLOSED |
ESTABLISHED→CLOSE_WAIT→LAST_ACK→CLOSED |
关键状态说明
LISTEN:服务器监听端口,等待连接请求。ESTABLISHED:连接正常,可双向传输数据(最常见状态)。TIME_WAIT:主动关闭方等待网络残留报文过期,避免新连接受干扰(核心作用)。CLOSE_WAIT:被动关闭方已收到关闭请求,但自身数据未发完(若长期停留,可能是应用层未调用close)。
15. 为什么time_wait状态需要经过2msl才能返回到close状态
2MSL 等待的核心原因: 确保被动关闭方收到最终 ACK
四次挥手的最后一步,主动关闭方发送
ACK报文后进入TIME_WAIT状态。若该ACK报文因网络延迟丢失,被动关闭方会因未收到确认而重传FIN报文。
- 2MSL 的等待时间足以覆盖:
- 被动关闭方重传
FIN的最大延迟(1MSL 内);- 主动关闭方收到重传的
FIN后,重新发送ACK的延迟(再 1MSL 内)。- 若等待时间不足,主动关闭方提前进入
CLOSED状态,可能无法处理被动关闭方重传的FIN,导致被动关闭方无法正常释放连接(长期停留在LAST_ACK状态)。
16. 如何根据ip获取对方的mac地址
根据 IP 地址获取对方 MAC 地址的过程依赖于ARP 协议(地址解析协议),其核心是通过 IP 地址查询对应的 MAC 地址(数据链路层地址),以便在局域网内进行数据传输。
ARP 协议用于在同一局域网内将 IP 地址映射到 MAC 地址,分为 "请求" 和 "响应" 两个步骤:
- ARP 请求 :当主机 A 需要获取主机 B(IP 为
192.168.1.100)的 MAC 地址时,会发送一个广播帧 (目标 MAC 为FF:FF:FF:FF:FF:FF),包含内容:"谁的 IP 是192.168.1.100?请回复你的 MAC 地址给我(主机 A 的 IP 和 MAC)"。- ARP 响应 :局域网内所有主机都会收到该广播,但只有 IP 为
192.168.1.100的主机 B 会回应一个单播帧 ,包含内容:"我的 IP 是192.168.1.100,MAC 地址是XX:XX:XX:XX:XX:XX"。- 缓存保存 :主机 A 收到响应后,会将 "IP→MAC" 映射存入本地ARP 缓存表(临时保存,有过期时间),后续通信直接使用该映射,无需重复查询。
17. http和https的区别
| 对比维度 | HTTP | HTTPS |
|---|---|---|
| 安全性 | 明文传输,不安全 | SSL/TLS 加密,安全 |
| 端口 | 80 | 443 |
| 底层协议 | TCP | TCP + SSL/TLS |
| 证书 | 无需 | 需 CA 颁发证书 |
| 连接延迟 | 低(无额外握手) | 稍高(需 SSL/TLS 握手,可优化) |
| 用途 | 非敏感数据传输 | 敏感数据(支付、登录、个人信息等) |
18. http有哪些常用的方法
GET
- 用途:从服务器获取资源(如网页、图片、API 数据)。
- 特点 :
- 请求参数附加在 URL 中(可见,有长度限制,通常 2KB-8KB)。
- 是 "安全的"(不修改服务器数据)和 "幂等的"(多次请求结果一致)。
- 示例 :
GET /api/users?id=1(获取 ID 为 1 的用户数据)。POST
- 用途:向服务器提交数据,通常用于创建资源或触发服务器处理(如表单提交、登录)。
- 特点 :
- 请求参数放在请求体(Body)中(不可见,无长度限制)。
- 可能修改服务器数据(如创建用户),非幂等(多次提交可能产生不同结果,如重复下单)。
- 示例:表单提交用户注册信息,数据在请求体中发送。
19. SSH基于TCP还是UDP?端口号
SSH(Secure Shell,安全外壳协议)基于TCP 协议 ,默认端口号为22。
具体说明:
协议基础:SSH 是一种用于远程登录和安全数据传输的协议,需要可靠的连接来保证数据的完整性和顺序性。TCP 的面向连接、可靠传输(重传机制、有序交付)特性恰好满足这一需求,因此 SSH 选择基于 TCP 实现。
端口号 :SSH 默认使用22 号端口,这是 IANA(互联网号码分配机构)分配的标准端口。实际应用中,为提高安全性,服务器可能会修改 SSH 端口(如改为 2222 等非默认端口),但客户端连接时需显式指定修改后的端口。
20. 讲一下WLAN
WLAN(Wireless Local Area Network,无线局域网)是指通过无线通信技术(主要是无线电波)实现设备之间的局域网连接,无需物理线缆即可实现数据传输,是有线局域网的无线扩展。我们日常所说的 "WiFi" 是 WLAN 的一种主流实现技术(由 IEEE 802.11 系列标准定义),因此常将两者通俗地等同,但严格来说 WiFi 是 WLAN 的技术子集。
21. HTTP1.0和HTTP1.1的区别
| 特性 | HTTP 1.0 | HTTP 1.1 |
|---|---|---|
| 连接方式 | 短连接(默认关闭) | 长连接(默认 keep-alive) |
| 请求方法 | GET、POST、HEAD | 新增 PUT、DELETE、OPTIONS 等共 8 种 |
| 缓存控制 | 依赖 Expires |
新增 Cache-Control、ETag 等 |
| 分块传输 | 不支持(需 Content-Length) |
支持 Transfer-Encoding: chunked |
| 虚拟主机支持 | 不支持(无 Host 头部) |
强制 Host 头部,支持虚拟主机 |
| 管道化 | 不支持 | 支持(有限制) |
22. HTTP2.0与HTTP1.1的区别
| 特性 | HTTP/1.1 | HTTP/2 |
|---|---|---|
| 协议类型 | 文本协议 | 二进制协议(帧封装) |
| 多路复用 | 不支持(串行执行,队头阻塞) | 支持(并行处理多个请求,无队头阻塞) |
| 头部压缩 | 不支持(重复发送完整头部) | 支持 HPACK 算法(字典压缩) |
| 服务器推送 | 不支持 | 支持(主动推送依赖资源) |
| 流优先级 | 不支持 | 支持(指定资源加载顺序) |
| 连接利用 | 多连接并行(有限制) | 单连接多路复用 |
设计模式
面向对象的设计原则有哪些
面向对象的设计模式有哪些
为什么用组合而不要用继承
单例模式的构造函数,单例模式的创建过程,如何保证线程安全
如何使用单例模式,有什么注意事项
如果用单例模式时创建了多个对象,如何定位问题
请简述一下适配器模式
实现一个简单的观察者模式
使用过的设计模式,应用场景,如何应用?阐述业务背景和应用方式
如果某个模块运行突然奔溃,但崩溃的几率不大,如何定位并解决这个问题
模块偶发崩溃(概率低、难以复现)通常与内存问题(如野指针、越界)、线程竞争、资源竞争、未定义行为 等隐性问题相关。由于其随机性,定位难度较高,需结合日志埋点、工具监控、代码审计等多维度手段,逐步缩小范围。
一. 初步信息收集:捕获崩溃现场
1. 开启核心转储(core dump)
崩溃时生成 core 文件(内存快照),是定位偶发问题的关键。
- 临时开启:
ulimit -c unlimited(当前终端有效,设置 core 文件大小无限制)。 - 永久生效:修改
/etc/security/limits.conf,添加* soft core unlimited和* hard core unlimited,重启后生效。 - 配置 core 文件路径:
echo "/tmp/core-%e-%p-%t" > /proc/sys/kernel/core_pattern(文件名包含程序名、PID、时间,便于追溯)。 - 当模块崩溃时,
/tmp目录会生成 core 文件,后续可用gdb 程序名 core文件分析堆栈。
2. 添加详细日志(关键操作埋点)
针对模块的核心流程(如函数调用、资源申请 / 释放、状态切换、边界条件)添加日志,记录:
- 时间戳、线程 ID(
pthread_self())、函数名、关键变量值(尤其是指针、数组索引、计数器)。 - 资源操作:内存分配(
malloc/new的地址、大小)、释放(free/delete的地址)、文件句柄 / 锁的获取与释放。 - 异常分支:
if (err) { log("错误原因: %d, 变量x: %d", err, x); },避免遗漏错误处理。 - 日志输出到文件(如
/var/log/模块名.log),确保包含足够上下文(如崩溃前 100 条日志)。
二、定位方向:常见偶发崩溃原因及排查
1. 内存问题(最常见)
偶发崩溃常因野指针、内存越界、double free等,仅在特定输入或时机触发(如内存布局恰好满足覆盖条件)。
- 用 core 文件分析 :
gdb 程序名 core文件后,执行bt查看崩溃时的堆栈,定位崩溃的函数和行号。- 若堆栈混乱(如函数名显示
??),参考前文 "堆栈信息不准" 的处理方法,结合反汇编(disassemble)和内存查看(x/100x 地址)。 - 检查崩溃点的变量:
print 指针变量看是否为0x0(空指针)或异常地址(如0xdeadbeef);print 数组索引看是否超出范围。
- 工具辅助 :
- 若能复现(即使概率低),用
valgrind --tool=memcheck --leak-check=full ./模块名运行,它能检测未初始化内存、越界访问、野指针等,输出详细位置(需耐心等待崩溃触发)。 AddressSanitizer(编译时加-fsanitize=address -g):对内存错误的检测更灵敏,崩溃时会打印详细的越界位置、内存分配 / 释放记录。
- 若能复现(即使概率低),用
2. 线程竞争与同步问题
多线程环境下,未保护的共享资源(如全局变量、队列)可能因调度顺序导致偶发崩溃(如读写冲突、条件变量使用不当)。
- 日志分析 :
- 查看崩溃前的线程日志,对比不同线程对共享资源的操作顺序(如线程 A 读取时线程 B 修改,导致数据不一致)。
- 重点检查:互斥锁(
pthread_mutex)是否正确加锁 / 解锁、条件变量(pthread_cond)是否存在虚假唤醒或超时、原子操作是否覆盖所有共享变量访问。
- 工具辅助 :
helgrind(valgrind --tool=helgrind ./模块名):检测线程竞争和锁错误,报告潜在的 race condition。gdb调试多线程:崩溃时用info threads查看所有线程状态,thread 线程ID切换到崩溃线程,bt查看其堆栈。
3. 资源竞争与耗尽
- 文件句柄 /socket 耗尽 :模块频繁打开文件 / 网络连接但未及时关闭,当句柄数达到系统限制(
ulimit -n)时,open()/socket()会失败,若未处理错误可能导致崩溃。- 日志中记录
open()/close()的返回值,统计当前句柄数(ls /proc/[PID]/fd | wc -l)。
- 日志中记录
- 内存泄漏累积 :轻微内存泄漏在短时间内不明显,但运行数天后内存耗尽,触发 OOM 杀死进程。
- 用
valgrind --tool=memcheck --leak-check=full检测泄漏点,或定期记录模块的内存占用(ps -p [PID] -o %mem,rss)。
- 用
- 信号处理不当 :如未捕获
SIGPIPE(管道断裂)、SIGSEGV(段错误),或信号处理函数中调用了不安全函数(如printf),导致二次崩溃。- 用
gdb查看崩溃信号:info signal或 core 文件中bt顶部的Signal received信息。
- 用
4. 未定义行为(UB)
C/C++ 中的未定义行为(如数组越界、整数溢出、空指针解引用)可能在不同编译环境、输入数据下表现不同,导致偶发崩溃。
- 代码审计重点 :
- 数组 / 容器访问:检查所有
[]操作的索引是否在[0, 长度-1]范围内(尤其是循环中的动态索引)。 - 指针操作:
malloc/new后是否检查NULL,free/delete后是否置空,避免二次释放或野指针。 - 整数运算:是否可能溢出(如
i++超过INT_MAX),尤其在循环条件或内存分配大小中(malloc(i * sizeof(int))若i溢出可能导致分配过小)。 - 类型转换:
void*转具体类型时是否匹配,向下转型(dynamic_cast)失败是否处理。
- 数组 / 容器访问:检查所有
三、复现与验证
-
构造触发条件:
- 若崩溃与输入相关,用模糊测试工具(如
AFL)生成大量随机输入,提高崩溃概率。 - 若与并发相关,用
pthread_setconcurrency(n)或脚本多进程 / 多线程调用模块,模拟高并发场景。
- 若崩溃与输入相关,用模糊测试工具(如
-
最小化测试用例:逐步剥离无关代码,保留触发崩溃的最小逻辑(如单独的函数、线程逻辑),排除干扰因素,便于定位。
-
对比环境差异 :若在特定机器 / 系统版本上更容易崩溃,对比编译选项(
gcc -v)、库版本(ldd 模块名)、内核版本(uname -a),排查兼容性问题(如旧库的 bug)。
四、解决与验证
-
针对性修复:
- 内存问题:添加边界检查、初始化指针、使用智能指针(
unique_ptr)、避免free后复用。 - 线程竞争:用互斥锁保护共享资源、条件变量确保同步、避免在锁内执行耗时操作。
- 资源问题:及时释放句柄 / 内存、增加错误处理(如
if (fd < 0) { log error; return; })。
- 内存问题:添加边界检查、初始化指针、使用智能指针(
-
长期监控:
- 修复后,通过灰度发布观察崩溃是否复现,对比修复前后的日志和监控数据。
- 保留 core 文件和日志收集机制,便于后续可能的新问题定位。
总结
偶发崩溃的定位核心是 "捕获现场(core + 日志)→ 工具分析(valgrind/ASan)→ 代码审计(聚焦内存 / 线程 / 资源)→ 复现验证"。由于问题隐蔽,需结合静态分析(代码审查)和动态监控(工具 + 日志),逐步排除不可能因素,最终锁定根因。