那天我在一家互联网大厂面试,被问了一个看似简单、实则杀伤力极强的问题:
"小米,假如MySQL里有2000万条数据,Redis里只能存20万条,你该怎么保证Redis中的数据都是热点数据?"
当场我笑出了声,心想这题是"送命题"吧!但笑归笑,能不能答好,真能看出你是不是一个"实战派"的程序员。
今天这篇文章,就带你把这道题拆开、揉碎、讲透。
故事从一个"假想项目"开始
那天,面试官给了我一个场景:
"我们公司做电商系统,商品表有2000万条数据。商品详情页访问量巨大,但Redis内存有限,只能放20万条。
请你设计一个机制,保证Redis中的数据始终是最热的那部分。"
我当时想起了一个词------冷热分层缓存。
于是我就从用户行为开始分析。
从用户行为说起:热点数据的本质
在实际系统中,数据访问有一个著名规律:
二八法则(80/20原则) ------ 20%的数据,承载了80%的访问量。
也就是说,2000万条商品里,可能有几十万条才是真正被频繁访问的"热数据"。
这些热数据有几个特征:
- 高访问频率:比如热门商品、活动商品。
- 时间敏感性强:比如"秒杀商品"、"热榜"。
- 生命周期短:热点会变动,今天火的明天可能凉。
明白了这些特征,我们才能思考"如何动态维护Redis中的20万条"。
错误的开始:最容易掉坑的两个思路
在我刚工作那几年,也遇到过类似问题。那时我天真地以为,只要在Redis里设置个LRU(最近最少使用)策略就行。
事实证明:
想靠Redis自己搞定热点维护,基本等于让仓库管理员"凭感觉"去挑畅销品。
问题有三:
- Redis LRU是局部淘汰:它只在达到内存上限时才淘汰,不是全局最优。
- 访问波动太快:热点可能几分钟就变了,Redis反应太慢。
- 热点穿透/击穿/雪崩问题:一旦热点没命中,数据库就遭殃。
所以,仅靠Redis配置不够,我们得有一套完整的策略体系。
正确的思路:分层 + 动态 + 指标驱动
我当时的回答思路是这样的(后来面试官很满意):
"我会设计一个冷热分层缓存架构,配合访问统计与异步更新机制,让Redis自动只保存真正的热点数据。"
具体拆解成三层:
第1层:读请求分层缓存架构
先从读请求入手,我们分三层:

请求流程:
先查本地 → 不命中查Redis → 仍不命中查MySQL并回填。
这样能减少Redis压力,同时也为"热点更新"打基础。
第2层:热度统计与异步上报
想知道哪些数据是热点,不能靠猜,要靠访问统计。
我们在应用层引入一个"热度计数器",每次用户访问商品详情时,就上报一次访问记录。这里有两种实现方式:
1、方案A:本地统计 + 定时上报
- 每台服务实例维护一个 ConcurrentHashMap<id, count>;
- 每隔1分钟,把统计结果异步汇总上报到MQ或Kafka;
- 消费端定时计算最近5分钟的访问量TopN。
2、方案B:滑动窗口 + Redis计数器
- 在Redis中使用 INCR 记录访问次数;
- 设置过期时间(比如10分钟),形成滑动时间窗口;
- 定时计算最近窗口内访问量TopN。
最后得到的TopN列表,就是当前"热点数据候选集"。
第3层:Redis热点数据维护策略
有了TopN数据,就可以动态维护Redis了。
思路是:
热点上升 → 自动写入Redis;
热点下降 → 自动淘汰。
可以用一个简单的后台任务来实现:

这样,Redis就能"自动呼吸",始终保持最有价值的数据。
加速策略:让Redis命中率更高
到这里,我们已经有了冷热分层 + 热度更新机制。但想让系统"更丝滑",还有一些优化小技巧:
1、热点预测预热
在大型活动(如双十一)前,可以根据历史访问日志提前预测哪些商品会热,然后批量加载入Redis。
这样一上线就能防止"冷启动"导致的击穿。
2、热点降级机制
当某一类数据突然暴涨,比如明星商品访问量暴增时,可以启用本地缓存或返回静态化数据页面,防止Redis被打爆。
3、异步更新 + 双写一致性
写操作时不要直接同步更新Redis,可以采用延迟双删策略:
- 删除缓存;
- 更新数据库;
- 延迟1秒再删一次缓存,防止并发脏数据。
4、Redis Key 设计与分片
为了防止单节点热点,可以给Key加前缀哈希分片,比如:
product:{hash(id)%10}:{id}
保证访问更均衡。
5、Bloom Filter 防止穿透
对于不存在的数据,用布隆过滤器提前拦截,减少数据库压力。
关键指标:让热点机制"看得见"
很多人做完缓存策略就结束了,但真正的高手,会监控数据热度变化。
你可以用Prometheus + Grafana监控:
- Redis命中率;
- 热点数据更新频率;
- MySQL QPS变化;
- 热度榜TopN曲线。
一旦发现热点变动趋势异常,就能提前扩容或预热。
面试官的追问:那如果"热点突发"怎么办?
面试官继续追我问:
"如果某个新商品突然爆红,系统来不及同步进Redis怎么办?"
我答:
"可以结合消息队列 + 异步监听机制,让访问日志实时触发热点检测。"
举个例子:
- 用户访问详情 → 上报消息队列;
- 消费端监听访问流量;
- 当某个商品的访问量在1分钟内暴涨超过阈值(比如1000次);
- 立即触发预加载入Redis。
这样热点突发也能"秒级响应"。
延伸:还能用哪些"黑科技"?
一些大厂更进一步,甚至会用到:
- LFU (Least Frequently Used) 策略替代LRU;
- Redis + Caffeine 双缓存协同;
- 基于滑动时间窗口的热度模型;
- 流式计算(Flink)实时统计访问量;
- AI 热点预测(例如基于历史访问序列训练模型)。
这些都能让热点数据维护更智能。
总结复盘:这道题到底考什么?
其实,这道题考的并不是"你背了多少Redis命令",而是考察你能不能从业务逻辑、系统设计、数据波动三个维度综合思考。
我后来总结了一句口诀:
"冷热分层是骨架,热度统计是灵魂,动态更新是血液。"
能把这三点讲清楚,你不仅能拿下面试,还能写出真正可落地的方案。
写在最后
那次面试我顺利过了,面试官笑着说:
"你这回答不是背书,是讲了个能跑起来的系统。"
我回到家后,心里还挺有成就感。其实每次面试题背后,都藏着真实的工程智慧。它逼你去思考系统的本质,而不是死记硬背。如果你正准备面Java社招面试,记住这点:
技术不是堆叠,而是思考。
最后送你一句话:
"热数据永远有限,但聪明的人能让有限的资源发挥无限的价值。"
要点复盘(方便收藏)
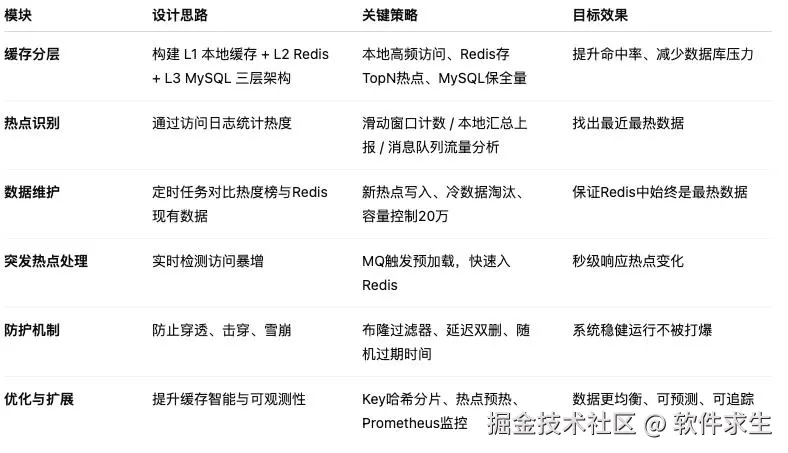
END
我是小米,一个喜欢分享技术的31岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号"软件求生",获取更多技术干货!