从GPT3演进到ChatGPT,从GPT4赋能GitHub Copilot的发展历程中,微调技术发挥了关键作用。
本文将系统解析微调(fine-tuning)的核心概念、实际应用价值,以及LoRA(Low-Rank Adaptation)的创新原理。
一、什么是 fine-tuning
GPT-3基于海量互联网语料训练后,其原生设计并不针对对话场景优化。例如当输入"中国的首都是哪里?"时,GPT-3可能输出"美国的首都是哪里?"
这是由于训练数据中这两组问答的高频共现导致。这类输出显然无法满足ChatGPT的对话需求,需要通过多阶段优化提升其对话能力。
CPT3模型的微调流程包含四个核心阶段:
预训练阶段:在海量文本数据上训练,建立基础语言理解能力(形成GPT3雏形)
监督微调:通过标注数据引导模型适应对话任务,输出更符合人类对话习惯
强化学习:利用用户反馈(如点赞/差评数据)持续优化输出质量,增强多轮对话连贯性
迭代更新:定期微调模型以适应新需求,同时保障内容安全性和伦理合规性
1.1. 为什么要 fine-tuning
1.1.1. 微调对预训练模型特定任务的强化作用
领域专项优化:微调将模型的通用能力聚焦于特定领域。以情感分类为例,预训练模型虽具备基础能力,但通过微调可显著提升其在该领域的表现。
知识扩展:微调能引入新知识,例如针对模型身份类问题(如"你的开发者是谁?"),可通过微调使其生成符合预期的回答。
更多AI大模型学习视频及资源,都在智泊AI。
1.1.2. 微调对模型性能的提升
抑制幻觉:微调有效减少模型生成虚假或无关内容的概率。
输出稳定性:在保持创造性的前提下(如调整temperature参数),微调确保输出质量波动较小,避免忽高忽低的结果。
内容过滤:模型可经微调拒绝敏感话题(如宗教评价),在安全审查场景中尤为重要。
效率优化:通过参数精简和微调,降低推理延迟,提升响应速度。
1.1.3. 微调保障数据安全
灵活部署:支持本地或私有云部署,实现完全自主控制。
数据保护:企业核心数据无需外泄,避免竞争优势流失。
安全定制:针对机密数据,可构建高安全等级的微调环境,不依赖第三方服务商。
1.1.4. 微调的经济性优势
降低开发成本:以Meta开源的Llama 3.1 405B为例,其训练需24000张H100集群运行54天,而基于开源模型的微调(如量化技术)可大幅降低成本。
推理成本优化:相同性能下,微调模型参数量更少,单次请求成本更低。
资源可控性:通过调整参数和资源配置,平衡性能、耗时与成本,实现灵活优化。
1.2. 一些相关概念区分
1.2.1. 基于人类反馈的强化学习(RLHF)与监督微调(SFT)

根据OpenAI公开的技术资料,ChatGPT的性能提升主要依赖微调(SFT)和基于人类反馈的强化学习(RLHF)两大技术路径。
从GPT3到ChatGPT的演进流程可概括为四个阶段:预训练 → 监督微调(SFT) → 强化学习(RLHF) → 模型修剪与优化。这两种核心技术的差异主要体现在以下方面:
技术原理差异
微调通过监督学习使模型输出更符合人类对话习惯,而强化学习则通过建立奖励机制来优化输出质量。具体而言:
监督微调(SFT):利用标注数据对预训练模型进行针对性训练,属于有监督学习范式。根据训练方式不同,还可细分为无监督微调(利用未标注数据)和自监督微调(通过生成伪标签实现)
强化学习(RL):模型通过与环境交互获得奖励信号,以最大化长期累积奖励为目标。在NLP领域,RLHF(基于人类反馈的强化学习)是典型应用,其流程包含:
初始模型生成(监督学习阶段)
人类评审员对输出结果进行质量排序
训练奖励模型(reward model)对输出评分
通过强化学习优化生成策略
实践对比
从实施难度来看,强化学习在数据标注成本、训练复杂度、时间投入和效果不确定性等方面均显著高于微调。
RLHF需要先构建人工标注的奖励模型,再经过多轮迭代优化,而SFT在特定任务中通常能以更低成本获得良好效果。因此在实际应用中,微调仍是主流选择。
1.2.2. 继续预训练与微调
ChatGPT作为通用型对话工具,其应用场景覆盖广泛。而在垂直行业或专业领域中,类似产品的定位会呈现更精细的划分。
例如常见的医疗专用大模型、法律合规大模型、金融风控大模型等,这类"行业专用模型"多数基于基础模型通过持续预训练实现。
持续预训练是指利用特定领域数据对已预训练模型进行二次训练,旨在增强模型对专业领域的认知适配性。
此类数据通常具有体量大、无标注的特征。微调则侧重提升模型在具体任务中的性能表现,通常采用小规模标注数据集进行针对性优化。
两种方法可协同应用,以金融安全领域为例,针对欺诈行为分类标注这类具体任务,模型的典型训练流程为:
基础预训练(基于全网海量数据,企业级训练)→ 领域预训练(使用行业专有数据,跨业务部门实施)→ 任务微调(依托业务场景数据,各业务单元独立优化)。
1.3. 小结
通过微调可以提升模型在特定任务上的表现。相对于预训练、强化学习,在生产过程中,使用到微调技术的场景更多。
二、如何 Fine-tuning
2.1. 微调的基本原理
微调是指对已训练完成的神经网络模型参数进行针对性调整,使其更适配特定任务或数据分布。
通过在小型新数据集上对模型的部分或全部层级进行二次训练,模型能够在继承原有知识的前提下,针对新任务实现性能优化,从而增强在垂直领域的能力表现。
依据调整范围的不同,微调策略可分为全局微调与局部微调两类。
全局微调(Full Model Fine-Tuning)会更新模型全部参数,适用于目标任务与预训练任务存在显著差异,或需要极致性能输出的场景。
该方案虽能达成最优效果,但需消耗大量计算资源与存储空间,且在小数据量场景下易引发过拟合问题。而局部微调(Partial Fine-Tuning)仅激活部分参数进行更新,其余参数保持冻结状态。
该方式有效降低了计算与存储开销,并缓解了过拟合风险,尤其适合数据量有限的任务,但在处理复杂任务时可能制约模型潜力的充分释放。
实际生产环境中,局部微调更为普遍。考虑到大模型参数规模庞大,即使仅调整部分参数仍需可观的计算资源。
当前主流的解决方案是参数高效微调(Parameter-Efficient Fine-Tuning, PEFT),该方法通过引入低秩矩阵(如LoRA)或适配器模块(如Adapters),显著减少了资源消耗。
其中,LoRA作为高效微调技术的代表,在保持模型原有性能的前提下,大幅降低了微调所需的参数量与计算成本,实现了对特定任务的高效适配,尤其适用于大模型的微调场景。
2.2. 什么是 LoRA
2.2.1. LoRA 基本概念
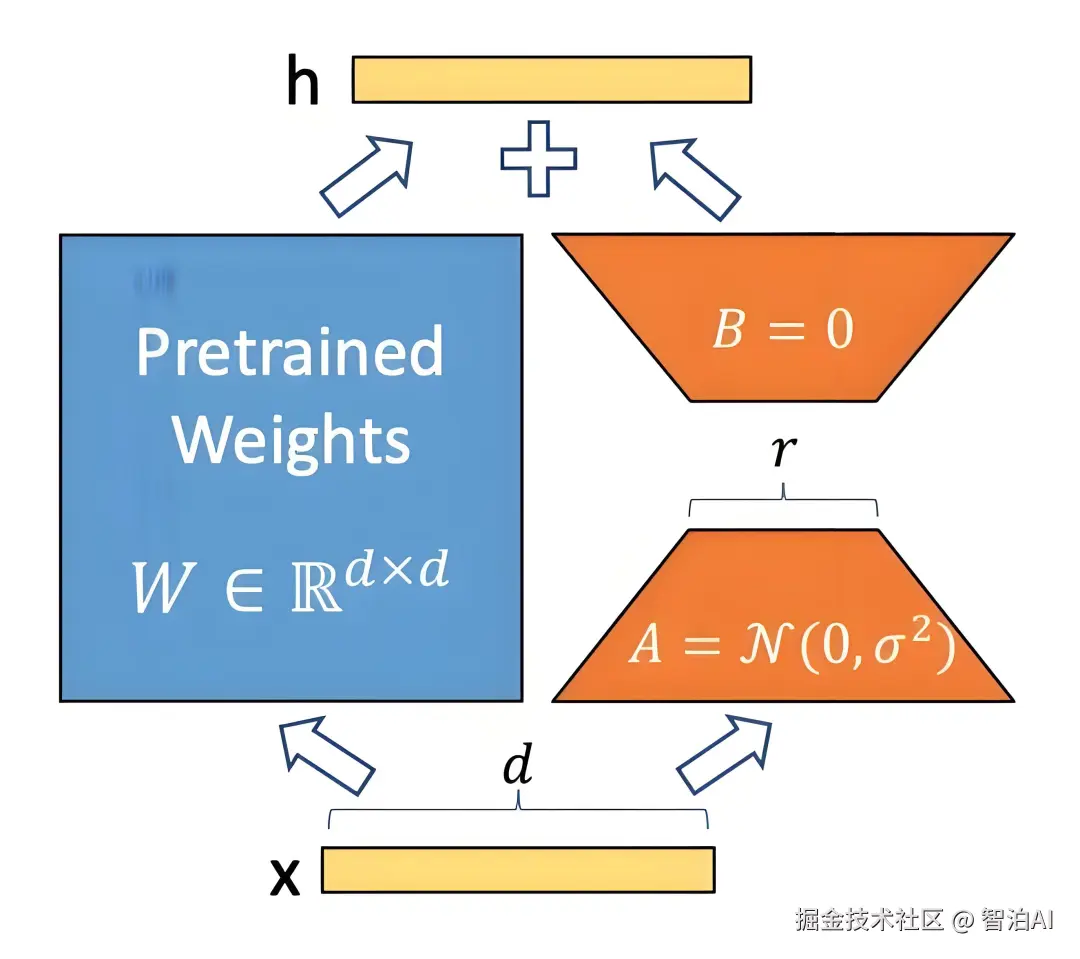
LoRA(Low-Rank Adaptation)通过引入低秩矩阵来减少微调过程中需要更新的参数数量(矩阵A和矩阵B),从而显著降低计算资源需求(降低为之前1/3,论文中数据)。
LoRA 另外一个非常重要的特性是:可重用性。由于LoRA不改变原模型的参数,它在多任务或多场景的应用中具有很高的可重用性。不同任务的低秩矩阵可以分别存储和加载,灵活应用于不同任务中。
比如在手机终端上,要跑应用的终端大模型。一个应用的模型会处理不同的任务,可以针对不同的任务,训练不同的 LoRA 参数,运行时基于不同任务,使用相同的基座模型,动态加载需要的 LoRA 参数。
相对于一个任务一个模型,可以大大降低存储、运行需要的空间。
2.2.2. LoRA 原理分析
在机器学习中,通常会使用非常复杂的矩阵来让模型处理数据。这些结构通常都很"全能",它们可以处理非常多种类的信息。
但研究表明,让模型去适应特定任务时,模型其实并不需要用到所有这些复杂的能力。相反,模型只需要利用其中一部分就能很好地完成任务。
打个比方,这就像你有一把瑞士军刀,里面有很多工具(像剪刀、螺丝刀等等),但是在解决特定任务时,通常只需要用到其中的几个工具就可以完成大多数工作。
在这个例子中,模型的矩阵就像瑞士军刀,虽然它很复杂(全秩),但实际上你只需要用到一些简单的工具(低秩)就足够了。
也就是说微调的时候,只调整那些对特定任务有影响的参数就可以了。
原始矩阵维度较高,假设为 dk 维矩阵W0,要想进行矩阵调整,并且保持矩阵的数据(为了重用),最简单方式是使用矩阵加法,增加一个 dk 维度的矩阵ΔW。
但如果微调的数据,还是一个d*k维度的矩阵,参数量就很多。LoRA 通过将后者表示为低秩分解,来减少参数的量级。


上面表格为在 WikiSQL 和 MultiNLI 上使用不同秩r的 LoRA 验证准确率。适配 Wq 和 Wv时,只有1的秩就足够了,而仅训练Wq则需要更大的r。
Wq, Wk, Wv, Wo为 Transformer架构中自注意力模块中的权重矩阵。
2.3. 微调过程
微调基本过程,大概如下:

三、结语
本文介绍了微调的基本概念,以及如何对语言模型进行微调。微调虽成本低于大模型的预训练,但对于大量参数的模型微调成本仍非常之高。
好在有摩尔定律,相信随着算力增长,微调的成本门槛会越来越低,微调技术应用的场景也会越来越多。
"Textbooks Are All You Need" 这篇论文中强调了数据质量对预训练的重要性,deep learning的课程中,也强调了训练数据的 Quality。
想起 AngelList 创始人 Naval 的一句话,"Read the Best 100 Books Over and Over Again " ,微调之于模型,类似于人去学习技能/特定领域知识。
高质量的输入非常重要,正确方式可能是:阅读经典,反复阅读。
更多AI大模型学习视频及资源,都在智泊AI。