一、概念:Agent 是什么?
1.1 有"自主能力"的AI实体
Agent又称为AI Agent,通常称之为"智能体",专业定义是:由大语言模型(LLM)驱动,具备感知环境变化、自主决策并主动执行行动的智能系统,比如能自动写代码、做 PPT、帮用户订外卖的 AI,都属于 Agent。不同于传统聊天机器人 "你问我答" 的被动模式,Agent 就像一个有独立思考和行动能力的协作伙伴 ------ 只需告诉它最终目标,它就能自己拆解任务、选择工具、甚至能处理一些不符合预期的场景,最终交付结果。
- 从系统结构看:Agent的思考方式与人类很像,是一个 "感知--思考--行动" 的闭环系统,它能够获取外部信息,利用LLM进行理解、推理和规划,再通过工具或执行器对环境产生影响。
- 从能力特征看:Agent 不仅仅是能回答问题的聊天机器人,它还具备自主性、目标导向性和持续学习能力,它可以在没有用户持续指导的情况下,根据目标自动拆解任务、选择策略、调用工具,并在遇到问题时进行自我修正。
- 从技术本质看:Agent 的核心是 "大语言模型 + 外部工具 + 记忆与规划机制",LLM 提供理解与推理能力,工具让它能够与现实世界交互,而记忆与规划机制则让它具备长期任务管理和复杂推理的能力。

上面提到了Agent的一些特征,为了更直观地解释它与传统聊天机器人的不同,可以从几个维度进行对比:
| 维度 | 传统Chatbot | AI Agent(智能体) |
|---|---|---|
| 核心目标 | 回答用户问题,提供信息 | 完成指定任务,交付结果 |
| 主动性 | 被动响应,你问才答 | 主动规划,推进任务 |
| 记忆能力 | 仅保留短期对话上下文,易遗忘 | 具备长期记忆系统,记住用户偏好、历史行为 |
| 交互能力 | 仅文本/语音交互,无法联动外部工具 | 可调用API、工具 |
| 输出形式 | 文本/语音回复 | 具体行动+任务结果(如点了一个外卖,订好了车票) |
传统AI vs Agent
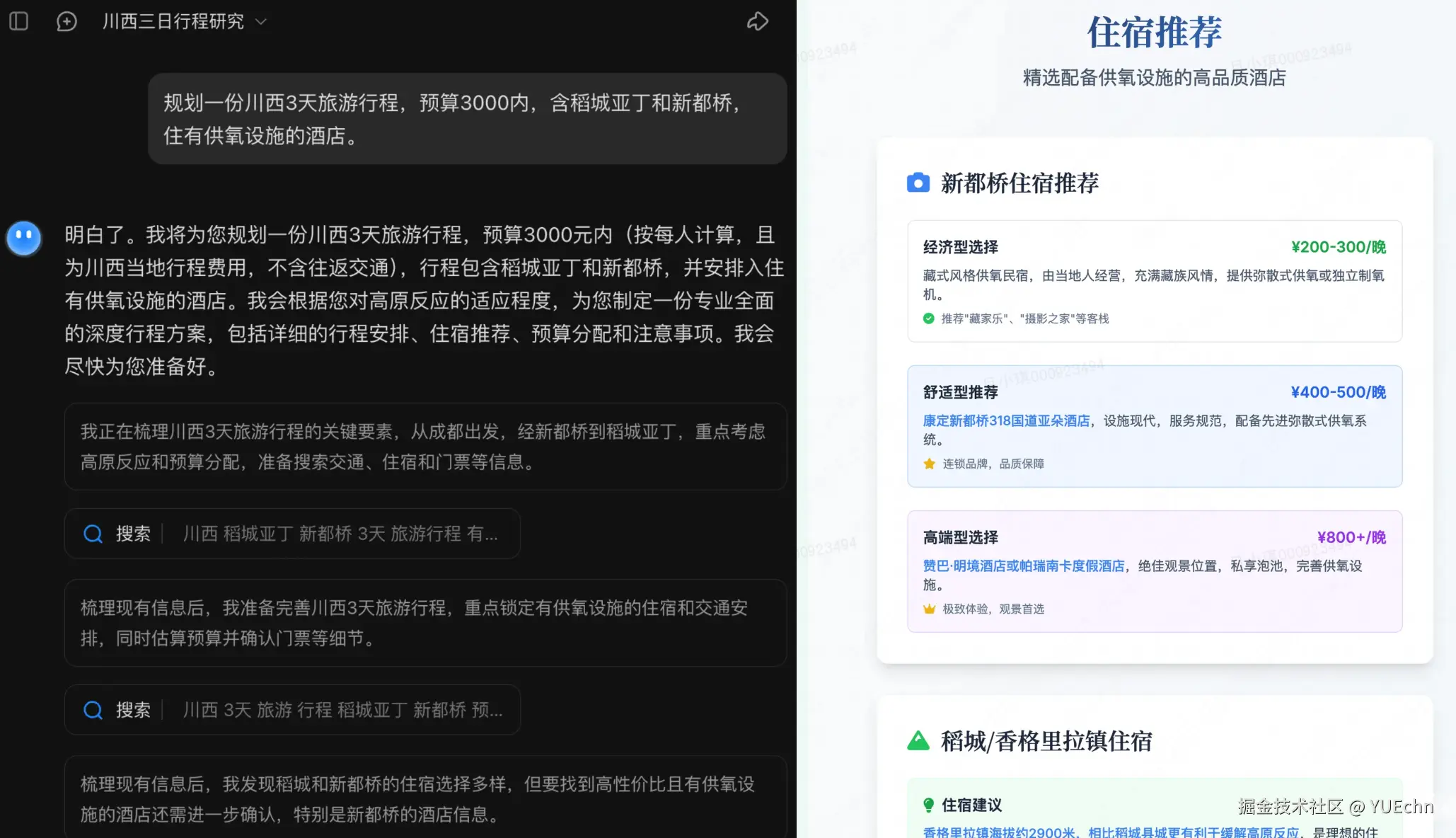
【场景设定】 规划一份川西3天旅游行程,预算3000内,含稻城亚丁和新都桥,住有供氧设施的酒店。
【回复效果】
(1) 🤖 传统AI (DeepSeek)
js
**一、行程概览**
- **主题**:高原风光+摄影之旅
- **天数**:3天
- **预算**:≤3000元/人
- **特色**:稻城亚丁核心景区、新都桥摄影天堂、全程供氧酒店
**二、详细行程**
**第一天:成都-康定-新都桥 (宿:新都桥供氧酒店)**
- 早晨:成都出发,经雅康高速抵达康定
- 中午:康定午餐 (推荐高原牦牛肉汤锅,人均50元)
- 下午:翻越折多山,抵达摄影天堂新都桥,拍摄秋色/藏居
- 晚上:入住新都桥供氧酒店 (预算300元/晚),适应高原环境
- **车程**:约6小时
- **费用**:
- 交通:拼车/班车约150元
- 住宿:供氧酒店300元
- 餐饮:早20+午50+晚50=120元
- 其他:氧气瓶备用30元
- **小计**:600元
**第二天:新都桥-稻城-香格里拉镇 (宿:香格里拉镇供氧酒店)**
- 早晨:新都桥出发,途经高尔寺山、卡子拉山
- 中午:理塘午餐 (推荐藏式简餐,人均40元)
- 下午:经兔儿山、海子山,抵达香格里拉镇
- 晚上:入住香格里拉镇供氧酒店 (预算350元/晚),为亚丁徒步准备
- **车程**:约7小时
- **费用**:
- 交通:拼车约200元
- 住宿:供氧酒店350元
- 餐饮:早20+午40+晚50=110元
- 门票:亚丁景区150元 (学生证/老年证有优惠)
- **小计**:810元
**第三天:稻城亚丁景区-返程**
- 全天:亚丁景区徒步 (推荐短线:冲古寺-珍珠海)
- 下午:16:00前出景区,返回香格里拉镇
- 傍晚:乘车返回稻城县城 (宿稻城或连夜返程,根据实际安排)
- **费用**:
- 交通:景区观光车120元+返程车费200元
- 餐饮:早20+午30+晚40=90元
- 住宿:稻城经济型供氧酒店300元 (若返程则不计)
- 其他:徒步物资50元
- **小计**:760元 (住稻城) / 460元 (连夜返程)
**三、预算总计**
- **方案A** (第三天住稻城):600+810+760=**2170元**
- **方案B** (第三天连夜返程):600+810+460=**1870元**
- **备用金**:300-500元 (应对突发情况)
**四、注意事项**
1. **高原反应**:全程住供氧酒店,建议提前服用红景天,徒步时携带便携氧气瓶
1. **交通提示**:川西路况复杂,建议选择正规拼车/包车,费用分摊更经济
1. **亚丁徒步**:景区内午餐需自备干粮,短线徒步约3-4小时,量力而行
1. **天气准备**:高原昼夜温差大,需备羽绒服、防晒霜、墨镜
1. **时间优化**:3天行程较紧凑,若时间允许建议增加1天适应高原
**五、节省预算技巧**
- 拼车分摊费用,选择经济型供氧酒店
- 亚丁景区门票可使用优惠证件
- 自备部分干粮,减少餐饮开支
此行程在预算内覆盖核心景点,供氧酒店保障休息质量,适合时间有限但想体验川西精华的游客。根据实际状况灵活调整徒步强度,安全第一。(2) 🧠 Agent(Kimi 深度研究)
1.2 演进脉络:从单点LLM 到自主智能体
Agent 不是突然出现的,而是 AI 技术一步步迭代的结果,可以简单通过三个阶段来查看的其演进过程: 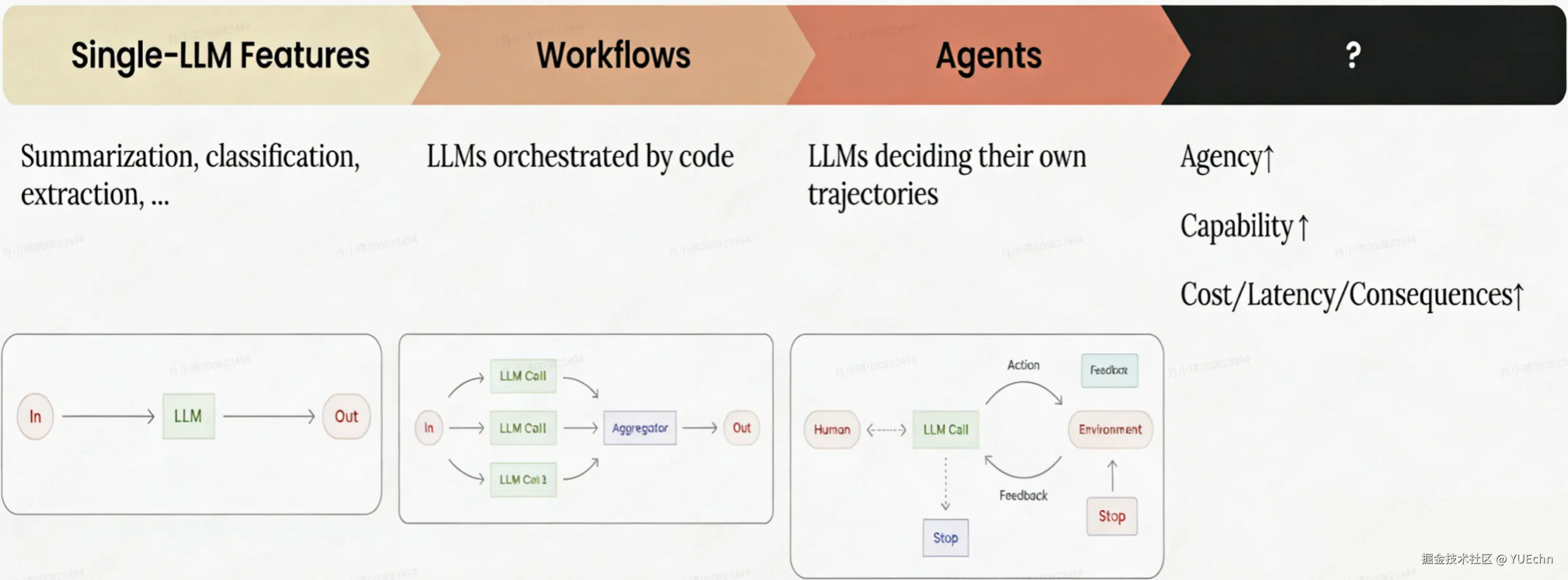 (1)单一LLM功能
(1)单一LLM功能
这是 LLM 应用的初始阶段,在这一阶段,大语言模型主要承担着一些固定且单一的任务,比如执行文本摘要、内容分类,或是从长文中提取关键信息。它的工作逻辑也很简单:接收一个明确输入,经过 LLM 处理后直接输出结果,直接给出相应的输出结果。整个过程完全依赖于用户所给出的指令,大语言模型并没有自主决策的空间,只能被动地响应用户的操作。
(2)工作流
在单一功能基础上,工作流阶段通过代码编排实现多模块协作,此时的AI不再是简单地单次调用一个大语言模型来完成任务,而是把多个大语言模型的任务像链条一样串联起来,分步骤地去完成更为复杂的工作。比如处理Excel数据统计任务时,首先由一个 LLM 调用负责理解与解析原始 Excel 表格结构,识别并转换字段数据格式;第二步调用另一个 LLM 进行统计计算与分析;第三步再调用一个 LLM 将分析结果转化为自然语言描述,还可能生成推荐的图表类型;最后一步进行整合,输出完整结果。在这个过程中,大语言模型仅仅是按照事先设定好的步骤,依次完成每一个子任务,最后将这些子任务的结果整合起来,形成最终的成果。
(3)智能体
智能体阶段标志着 LLM 从"被动执行"转向"主动决策" ,和前两个阶段最大的不同是,Agent 不再依赖预设的步骤:它会基于一个开放的目标,让 LLM 自主规划出完整的 "行动轨迹"。比如对于"完成旅行规划"的指令时,它会自己决定要先查天气、再选航班、接着订酒店,甚至在遇到酒店满房时主动调整方案。
二、核心模块:为什么能"自主干活"?
Agent之所以能实现自主决策、主动办事,核心是一套完整的技术架构在支撑。我们可以把它理解为"一个智能体的大脑+手脚",主要分为五大核心模块,各模块协同工作完成任务。
2.1 感知:有什么
感知模块是 Agent 与外部世界连接的桥梁,负责 "获取信息、感知变化",是所有决策和行动的基础,有两类关键信息:
- 主动感知:主动获取完成任务所需的外部数据,比如点外卖时感知用户当前地址、周边商家营业状态;研发场景中感知代码仓库的文件结构、需求文档的核心要求、运行状态;
- 被动接收:接收用户指令、工具执行反馈、环境变化通知,比如用户说 "加辣"、代码调试工具返回语法错误"。
感知模块能让 Agent 能精准把握任务背景和实时动态,避免 "盲目行动"
2.2 规划:做什么
规划是指接收用户目标后,利用 LLM 的推理能力将复杂任务分解为多步执行清单。规划有两种常见方式,适配不同场景:
- 全局规划:一开始就制定完整计划,比如点外卖时先规划 "筛选口味→匹配预算→对比评分→下单",这种适用于一些流程固定、目标明确的任务;
- 局部规划:就是边做边规划,比如优化代码时,需先规划 "分析性能瓶颈→修改核心逻辑→运行测试→查看结果",若测试发现新问题,再调整下一步规划,适合需要灵活应对变化的任务。
该环节一方面让Agent明确行动蓝图,厘清任务间的依赖关系与先后顺序,另一方面能让Agent掌握任务的主动权,它不是被动地回答用户问题,而是可以主动告诉用户用户接下来会做什么。
2.3 工具调用:怎么做
LLM 虽然很聪明,但受限于训练数据的滞后性以及无法直接与现实世界进行交互并执行具体操作,因此干不了实事,而工具就充当了 Agent 的手脚。工具调用是Agent为弥补知识的局限和执行能力的不足,主动识别并调用外部工具(如搜索引擎、API、数据库)来获取实时信息、执行计算或操作外部系统。
不仅解决了因训练数据滞后导致的LLM信息不实时、不准确的问题,更关键地突破了其纯文本交互的边界,使其能真正落地执行任务。同样以写代码的场景为例,为了让他能改变外部环境,那么就需要接上查看文件列表、读写文件内容、运行中断命令等能力的工具,有了这些工具,大模型就可以自己查看文件、修改代码、运行终端,整个过程,不需要用户参与,完全自动化。
2.4 记忆:记什么
记忆是Agent用于存储、管理和检索信息的内部系统,通常可以分为短期记忆、长期记忆与外部记忆三类:
- 短期记忆:类似草稿纸,记录当前会话的上下文,确保多轮对话的连贯推进;
- 长期记忆:类似RAG,跨会话保存用户偏好、历史交互记录以及任务经验等,以支持信息的长期复用;
记忆能够赋予Agent类似人类的"记住过去"的能力,并且在长期积累实现能够持续学习与进化,让Agent智能体能构建并维护一个统一的用户认知,从而在任何一次交互中都能提供连贯、个性化的服务。
PS:没有记忆的Agent也无法成为一个真正自主、可靠的智能助理。
2.5 反思:怎么样
Agent虽然很聪明,但也会犯错,反思模块就是 Agent 的 自我纠错机制。Agent在执行任务期间或结束后,它会对自身执行过程与结果的审视与评估机制,识别其中的错误或低效之处,并据此调整后续的推理路径。
 这个过程不仅能即时修正当前错误(如重新计算或补充信息),还可以提炼成功经验与失败教训,更新策略知识,从而提升任务完成的成功率与整体智能水平。
这个过程不仅能即时修正当前错误(如重新计算或补充信息),还可以提炼成功经验与失败教训,更新策略知识,从而提升任务完成的成功率与整体智能水平。
三、运行模式 :单 Agent 到多 Agent 协同
3.1 ReAct
ReAct全称是Reasoning And Acting,是一种结合语言模型推理能力 与外部工具调用能力 的智能体架构,通过循环执行 思考 (Thought) → 行动 (Action) → 观察 (Observation) 三个步骤,来完成任务。
- 思考 (Thought): LLM根据任务进行推理,分解复杂任务,制定行动计划
- 行动 (Action): 模型从可用的工具列表中选择合适的工具,生成调用参数,工具可以是API调用、数据库查询、计算函数等
- 观察 (Observation): 执行工具后,Agent观察返回的结果,判读是否需要继续下一步行动或范围最终结果
3.2 Plan And Execute
规划设计模式是一种通过提前计划和组织任务步骤来提高效率和准确性的方法。在这种模式中,模型将复杂任务分解为多个步骤,并依次执行每个步骤,以达到预期的目标。该模式将任务拆解为两个主要阶段:
- 规划阶段 (Planning): 由 Planner 模块负责,接收用户的高层目标,并输出一个结构化的多步计划。该计划通常包含按顺序排列的步骤、每个步骤的目标、所需调用的工具及参数占位符,有时还会定义步骤间的依赖关系。此阶段旨在将模糊目标转化为一条清晰的执行路线图。
- 执行阶段 (Execution): 由 Executor 模块负责,逐条执行计划中的步骤。它根据步骤描述调用相应工具或子Agent,收集并存储执行结果,同时监控执行状态。若执行失败或环境变化,可触发 Replanner 模块进行局部或全局的重规划,以修正后续步骤。所有步骤完成后,由 Finalizer 模块整合结果,生成最终答案
3.3 Multi-agent Collaboration: 1+1>2
单个智能体在处理明确问题、约束性任务时较为高效和准确,但面对复杂、多领域任务时,其能力往往受限。因此,多智能体协作出现了,这是一种将复杂任务分解,由多个具备不同专长的智能体分工合作、共享信息,以共同完成目标的运行模式。每个智能体拥有独立的角色、目标、工具集和知识范围,通过预设的通信与协调机制(如消息传递、任务分配、结果聚合)进行交互,其中由主智能体负责来调度子智能体,最终交付整体任务结果。
相较于单智能体系统,多智能体的核心优势体现在三方面:(1) 更强的并行处理能力:可同时推进多个子任务,大幅提升复杂任务的执行效率;(2) 更清晰的职责分工:每个智能体聚焦自身专长领域,降低单一模块故障对整体任务的影响;(3) 更高的系统鲁棒性:通过多智能体的冗余设计与协同补位,增强系统应对动态环境变化和任务突发状况的适应能力。