语义理解是模型的根基能力,语义检索则是一种特定的检索方法。
尽管语义理解和语义检索常被提及,但许多人仍未能清晰辨析二者之间的异同、内在关联及其实际应用场域。
在大语言模型的自然语言处理框架中,系统运作通常划分为自然语言理解(NLU)与自然语言生成(NLG)两个阶段;而在RAG架构中,同样对应着两类核心机制------语义理解与语义检索。
那么,在RAG体系内,语义理解与语义检索究竟有何不同?各自适用于哪些场景?或者说,RAG流程中的哪个环节归属于语义理解,哪个环节又属于语义检索?
语义理解和语义检索
在 RAG 的流程中,用户发起查询后,系统依据该问题执行标量(条件查询)或向量检索(语义检索),旨在获取与问题语义匹配的文档片段,继而用于支撑模型的增强式生成。
简单流程如下图所示:
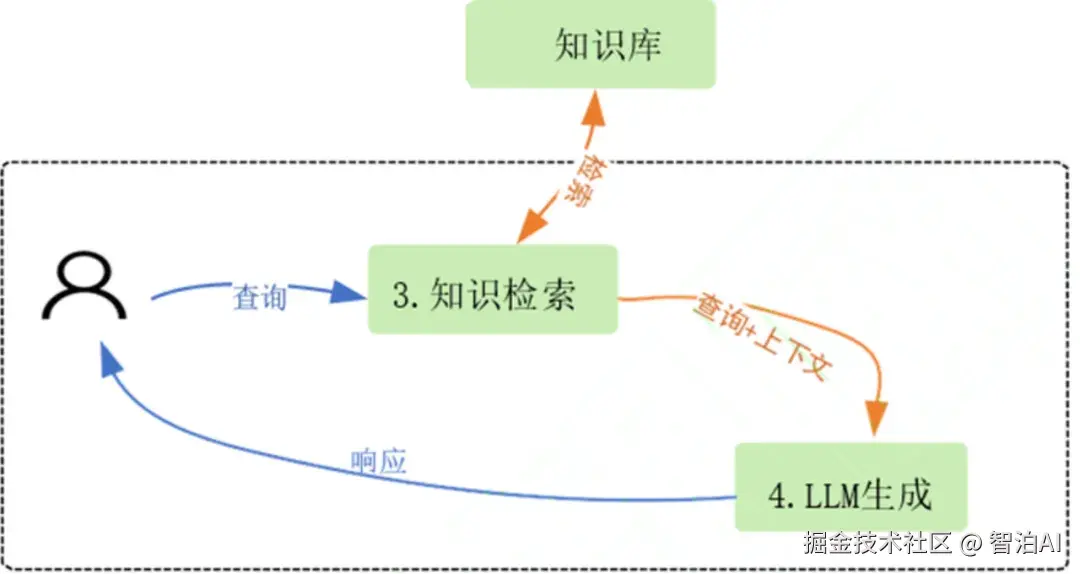
在传统RAG架构中,语义检索占据核心地位,这是因为自然语言问答本质上依赖对语义的匹配,而非基于关键词的条件筛选;正因如此,RAG系统引入向量数据库------其根本动因在于语义检索的技术底层是向量空间中的相似度计算。
部分人对向量数据库存在误解,或将其过度神化;实际上,它与传统关系型数据库并无本质差异,唯一的扩展在于新增了向量列,用以支持向量计算能力;因此,任何涉及向量运算的场景,均可适用向量数据库,涵盖智能问答、智能搜索等典型应用。
向量数据库的本质,是在关系型数据库结构上追加了向量列,而该列的唯一功能是执行相似度检索;真正驱动模型生成的,仍是原始文档内容------这正如我们通过ID或Name字段定位记录,但实际使用的却是表中其他字段的数据。
OK,明白了语义检索的底层逻辑,接下来聊聊语义理解;此前提到,大模型在生成过程中需依赖语义理解与语义生成两个环节;而在基于智能体的RAG系统里,语义理解同样扮演着关键角色,甚至可以说,它才是智能体真正的核心所在。
在增强型检索的智能体架构中,我们部署了多个查询工具,每个工具都配置了专属的查询参数;这些参数的核心功能,正是用于执行语义查询或条件筛选------但这些参数,究竟是如何被构建出来的呢?
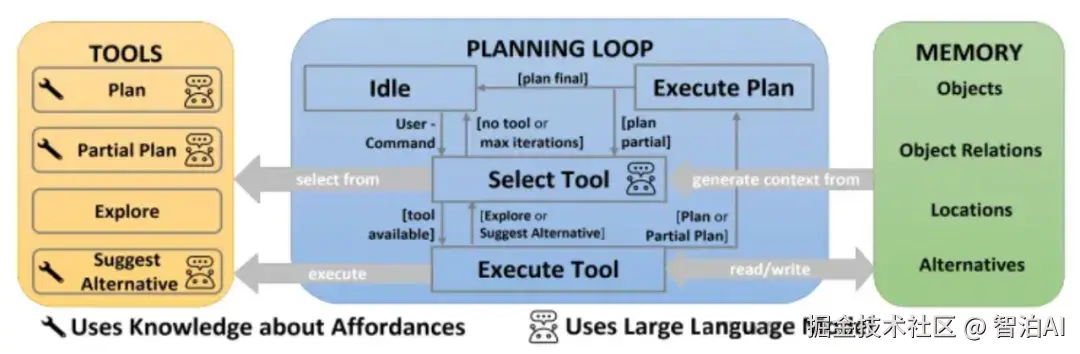
大模型通过解析用户问题,推导出工具调用所需的参数值,进而执行外部操作------由此可见,语义理解在智能体架构中居于核心地位;一旦该能力失效,工具调用的输出必然偏离预期。
在RAG框架下,语义理解与语义检索分属不同功能模块:前者是模型固有的语言解析能力,后者则是实现信息召回的一种方式,虽突破了传统基于关键词的精确匹配机制,但其底层逻辑仍与之同源。