1.概述
What is Prometheus?
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud.
Prometheus是一个开源系统监控和警报工具包,最初由 SoundCloud构建。Prometheus 将其指标收集并存储为时间序列数据,即指标信息与其记录的时间戳一起存储,同时还有称为标签的可选键值对。
Prometheus 是一个监控平台,它通过抓取目标上的 HTTP 指标端点来收集目标的指标。它是唯一一个直接受Kubernetes支持的系统,也是整个云原生生态系统的事实标准。
Features (特征)
- 具有由指标名称和键/值对标识的
时间序列数据的多维数据模型 - PromQL,一种灵活的查询语言 ,可以利用这种维度
- 不依赖分布式存储;单个服务器节点是自主的
- 时间序列收集通过
HTTP上的拉取模型进行 - 通过中间网关支持推送时间序列
通过服务发现或静态配置发现目标- 多种图形和仪表板支持模式
主 Prometheus 服务器作为单个整体二进制文件独立运行,没有外部依赖。
What are metrics?(指标)
用外行人的话来说,指标就是数值测量。时间序列指的是记录随时间的变化。
例如,当请求数量较高时,应用程序可能会变慢。如果您掌握了请求数量指标,就可以找出原因并增加服务器数量来处理负载。
Components(组成)
Prometheus 生态系统由多个组件组成,其中许多是可选的:
抓取并存储时间序列数据的主要Prometheus 服务器- 用于
检测应用程序代码的客户端库 - 支持短期工作的推送网关
- HAProxy、StatsD、Graphite 等服务的专用导出器。
- 一个用于处理警报的警报管理器
- 各种支持工具
大多数 Prometheus 组件都是用Go编写的,因此很容易构建和部署为静态二进制文件。
Prometheus 的架构和它的一些生态系统组件:
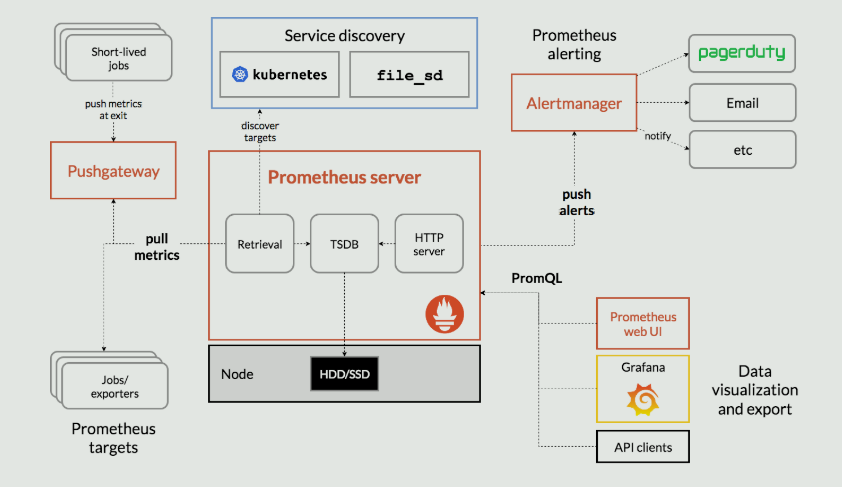
Prometheus 会从已插桩作业中抓取指标,可以直接抓取,也可以通过中间推送网关(针对短期作业)抓取。它会将所有抓取的样本存储在本地,并对这些数据运行规则,以便从现有数据中聚合并记录新的时间序列,或生成警报。您可以使用Grafana或其他 API 消费者来可视化收集到的数据。
Prometheus 可以实现高可用性吗?
是的,请在两台或多台独立的机器上运行相同的 Prometheus 服务器。相同的警报将被Alertmanager进行重复数据删除。
Alertmanager 通过将多个 Alertmanager 实例互连,构建 Alertmanager 集群,从而实现高可用性。集群实例使用由HashiCorp 的 Memberlist库管理的 Gossip 协议进行通信。
如何将日志输入 Prometheus?
不要!改用Grafana Loki或OpenSearch之类的工具。
更长的答案:Prometheus 是一个收集和处理指标的系统,而不是事件日志系统。Grafana 的博客文章 《日志、指标和图表,我的天哪!》 详细介绍了日志和指标之间的区别。
When does it fit? (什么时候合适)
Prometheus 非常适合记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合高度动态的面向服务架构的监控。在微服务领域,它对多维数据收集和查询的支持尤为突出。
Prometheus 的设计注重可靠性,旨在成为您在发生故障时可以快速诊断问题的系统。每个 Prometheus 服务器都是独立的,不依赖于网络存储或其他远程服务。当您的基础架构的其他部分出现故障时,您可以依赖它,而无需额外搭建基础设施来使用它。
When does it not fit?(什么时候不合适)
Prometheus 重视可靠性。即使在故障情况下,您也可以随时查看系统的可用统计信息。
如果您需要 100% 的准确性(例如按请求计费),那么 Prometheus 并非理想之选,因为它收集的数据可能不够详细和完整。在这种情况下,您最好使用其他系统来收集和分析计费数据,并使用 Prometheus 进行其余监控。
词汇表
词汇表:https://prometheus.io/docs/introduction/glossary/
下载、安装、配置、启动 Prometheus
参考:https://prometheus.io/docs/introduction/first_steps/
配置 Prometheus
Prometheus 的配置文件是YAML 格式。Prometheus 下载包中包含一个名为 <example_config_name> 的示例配置文件prometheus.yml,您可以以此为起点进行配置。
重要概念
数据模型
Prometheus 基本上将所有数据存储为时间序列:属于同一指标和同一组带标签维度的带时间戳的值流。
除了存储的时间序列之外,Prometheus 还可能根据查询结果生成临时的派生时间序列。
指标名称和标签
每个时间序列都由其指标名称和称为标签的可选键值对唯一标识。
指标名称:
指定所测量的系统的一般特征(例如http_requests_total- 收到的 HTTP 请求总数)。
指标名称可以包含 ASCII 字母、数字、下划线和冒号。它必须符合正则表达式a-zA-Z_:a-zA-Z0-9_:*。
注意:冒号保留用于用户定义的记录规则。导出器或直接检测不应使用它们。
度量标签:
启用 Prometheus 的维度数据模型,以识别同一指标名称的任意给定标签组合。它标识该指标的特定维度实例(例如:所有使用该方法发送POST至/api/tracks处理程序的 HTTP 请求)。
查询语言允许基于这些维度进行筛选和聚合。
任何标签值的改变,包括添加或删除标签,都会创建一个新的时间序列。
标签可以包含 ASCII 字母、数字以及下划线。它们必须与正则表达式匹配a-zA-Z_a-zA-Z0-9_*。
以(两个"_")开头的标签名称__保留供内部使用。
标签值可以包含任何 Unicode 字符。
标签值为空的标签被认为等同于不存在的标签。
示例
样本构成实际的时间序列数据。每个样本包含:
- float64 值
- 毫秒精度的时间戳
注意:从 Prometheus v2.40 开始,实验性地支持原生直方图。现在,样本值不再是简单的 float64 类型,而是可以采用完整的直方图形式。
符号
给定一个指标名称和一组标签,时间序列通常使用以下符号来识别:
bash
<metric name>{<label name>=<label value>, ...}例如,具有指标名称api_http_requests_total和标签的时间序列method="POST"可以handler="/messages"写成这样:
bash
api_http_requests_total{method="POST", handler="/messages"}指标类型
Prometheus 客户端库提供四种核心指标类型。目前,这些指标类型仅在客户端库(用于启用针对特定类型用途的定制 API)和线路协议中有所区分。Prometheus 服务器尚未使用类型信息,而是将所有数据扁平化为无类型时间序列。
Counter(计数器)
计数器是一种累积指标,表示一个单调递增的计数器,其值只能在重启时增加或重置为零。
例如,您可以使用计数器来表示已处理的请求数、已完成的任务数或错误数。
不要使用计数器来显示可能减少的值。例如,不要使用计数器来显示当前正在运行的进程数,而应该使用仪表。
计数器的客户端库使用文档:https://prometheus.github.io/client_java/getting-started/metric-types/#counter
Gauge(仪表)
仪表是表示可以任意上升或下降的单个数值的指标。
仪表通常用于测量温度或当前内存使用情况等值,但也用于测量可以上升和下降的"计数",例如并发请求的数量。
仪表的客户端库使用文档:https://prometheus.github.io/client_java/getting-started/metric-types/#gauge
Histogram(直方图)
直方图会采集观测值(通常是请求时长或响应大小等)并按可配置的桶进行计数。它还会计算所有观测值的总和。
具有基本指标名称的直方图<basename>在抓取过程中显示多个时间序列:
- 观察桶的累积计数器,显示为
<basename>_bucket{le="<upper inclusive bound>"} - 所有观测值的总和,显示为
<basename>_sum - 已观察到的事件数量,显示为
<basename>_count
直方图的客户端库使用文档::https://prometheus.github.io/client_java/getting-started/metric-types/#histogram
Summary(摘要)
与直方图类似,摘要会从观察结果中抽样(通常是请求时长和响应大小等)。它不仅提供观察结果的总数以及所有观察值的总和,还会计算滑动时间窗口内可配置的分位数。
基本指标名称为的摘要<basename>在抓取过程中暴露了多个时间序列:
- 流式φ分位数(0≤φ≤1)的观测事件,暴露为
<basename>{quantile="<φ>"} - 所有观测值的总和,显示为
<basename>_sum - 已观察到的事件数量,显示为
<basename>_count
摘要的客户端库使用文档:https://prometheus.github.io/client_java/getting-started/metric-types/#summary
Jobs and instances(作业和实例)
在 Prometheus 术语中,一个可以抓取的端点被称为一个实例 (instance),通常对应一个进程。具有相同用途的实例集合(例如,为了实现可扩展性或可靠性而复制的进程)被称为一个作业(job) 。
自动生成的标签和时间序列
当 Prometheus 抓取目标时,它会自动在抓取的时间序列上附加一些标签,用于识别抓取的目标:
job:目标所属的配置作业名称。
instance:<host>:<port>被抓取的目标 URL 部分。