目录
项目介绍
在信息时代的浪潮下,图书馆作为知识存储与传播的核心枢纽,其馆藏资源正从传统纸质文献向电子书籍、数据库、音视频资料等多形态延伸,规模呈现指数级增长。同时,读者对文献获取的即时性、便利性要求显著提升,不仅需要线下借阅服务,更期待通过线上平台实现馆藏查询、预约借阅、续借退订等功能,传统管理模式已难以满足多元化需求。
随着智慧校园建设的推进,图书馆作为重要组成部分,亟需通过数字化转型实现管理升级。开发一套集成馆藏管理、读者服务、数据统计、资源共享等功能的图书馆管理系统,既能解决人工操作的低效问题,又能通过线上线下融合服务提升读者体验,同时为图书馆的资源优化、服务创新提供数据支持,成为推动图书馆向智能化、现代化转型的关键举措。
语言:python
框架:django/flask
软件版本:python3.7.7
数据库:mysql
数据库工具:Navicat
前端框架:vue.js
通过比较两个不同因素的框架,可以看出Flask和Django不能被标记为单一功能中的最佳框架。当Django在快速发展的大型项目中看起来更好并且提供更多功能时,Flask似乎更容易上手。这两个框架对于开发Web应用程序都非常有用,应根据当前的需求和项目的规模来选择它们。
最新python的web框架django/flask都可以开发.基于B/S模式,前端技术:nodejs+vue+Elementui+html+css
,前后端分离就是将一个单体应用拆分成两个独立的应用:前端应用和后端应用,以JSON格式进行数据交互.充分保证了系统代码的良好可读性、实用性、易扩展性、通用性、便于后期维护等特点
当前,多数中小型图书馆仍依赖人工登记、纸质台账或简易工具进行管理,存在诸多效率瓶颈。例如,图书入库需逐本手动录入信息,易出现错漏;读者借阅时需人工检索书架位置,耗时费力;文献逾期提醒依赖人工排查,容易遗漏;馆藏资源的借阅热度、损耗情况等数据缺乏系统化分析,导致采购与剔除决策缺乏依据。此外,不同校区或分馆之间的资源共享存在壁垒,数据不通畅使得读者难以跨区域利用馆藏,限制了资源利用率的提升。
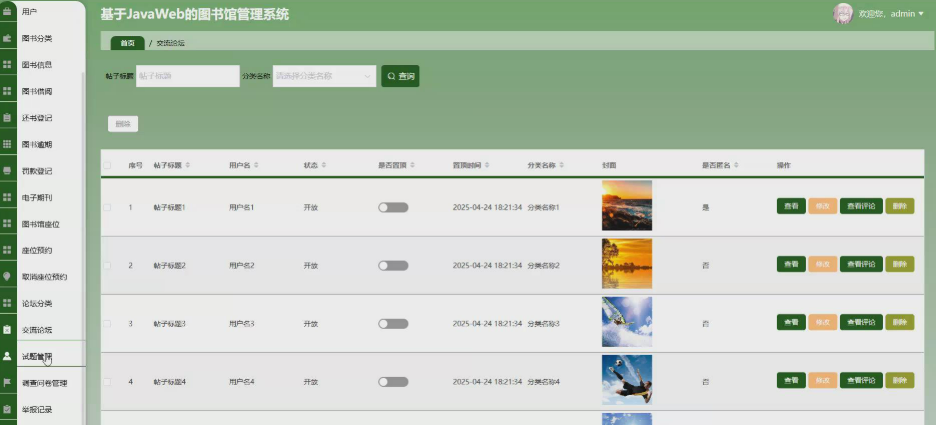
本项目具体实现截图

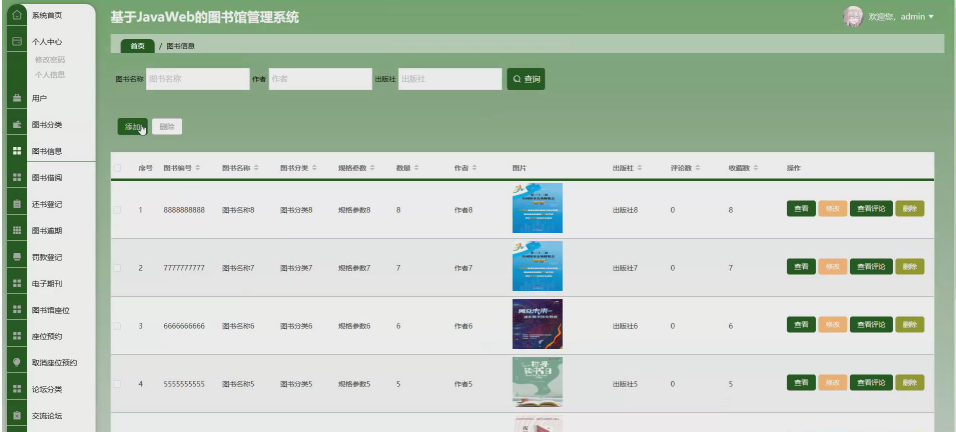
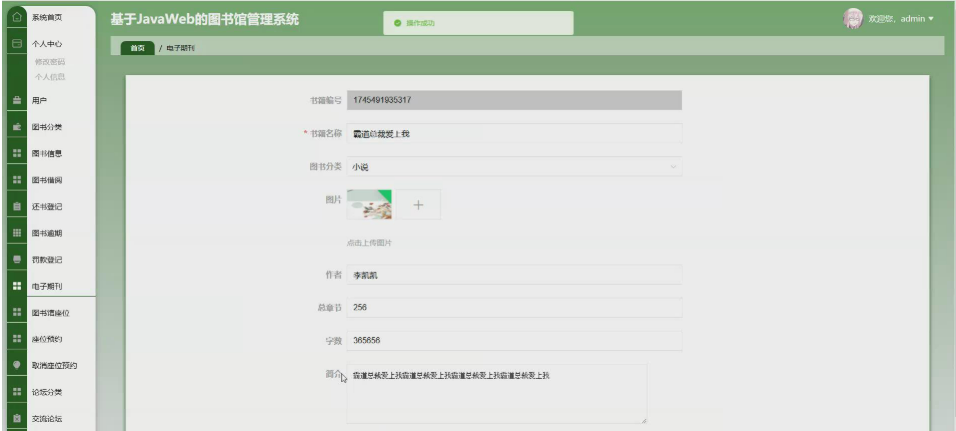
开发技术
前端开发框架:vue.js
数据库 mysql 版本不限
后端语言框架支持:
1 java(SSM/springboot)-idea/eclipse
2.Nodejs+Vue.js -vscode
3.python(flask/django)--pycharm/vscode
4.php(thinkphp/laravel)-hbuilderx
数据库工具:Navicat/SQLyog等都可以
而且VScode包含很多插件并且免费,下载更加快捷方便,可以给我们提供很多便捷条件。运行的便捷给我提供很大帮助。
Echarts有着与众不同的特点和惊艳全场的视觉效果,Echarts有以下几种特点:
1、开源软件,并且提供了非常炫酷的图形界面,还有各种直观的数据分析图形
2、使用简单,软件本身已经封装了js,只要引用到位就会有得到完美展示
3、兼容性好,基于html5,有着良好的动画渲染效果。
4、多种数据格式无需转换直接使用,对与直接传入包括二维表,key-value表等多种格式的数据源,通过简单的设置encode属性就可以完成从数据到图形的映射,这使Mysql的数据更容易的被引用
PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
IDEA是Java语言的一个收费的企业集成开发环境,是企业级开发中使用最多的IDE工具,也有很多开发者称它为沉浸式开发工具,免除了很多繁杂的配置,让开发者专注于代码的开发。有一些非常好用的辅助开发的功能,比如可以一键查看源码,而不需要先去官网下载并导入源码包等。还可以自动下载一些包,免去了项目初始进行导包的繁杂,让开发变得更加快捷和灵活。
PHP是英文超文本预处理语言Hypertext Preprocessor的缩写。PHP 是一种 HTML 内嵌式的语言,是一种在服务器端执行的嵌入HTML文档的脚本语言,语言的风格有类似于C语言,被广泛地运用
Flask 是一个轻量级的 Web 框架,使用 Python 语言编写,较其他同类型框架更为灵活、轻便且容易上手,小型团队在短时间内就可以完成功能丰富的中小型网站或 Web 服务的实现。
Django用Python编写,属于开源Web应用程序框架。采用(模型M、视图V和模板t)的框架模式。该框架以比利时吉普赛爵士吉他手詹戈·莱因哈特命名。该架构的主要组件如下:
SpringBoot整合了业界上的开源框架
hadoop集群技术
Hadoop是一个分布式系统的基础框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop的框架最核心的设计就是:HDFS和MapReduce。Hadoop实现了一个分布式文件系统,简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。
同时Hadoop有着高可靠性、高拓展性、高效性、高容错性的特点,非常适合于此次题目的使用
Java 最大的两个特点就是功能强大和简单易用。Java可以让程序员进行复杂的编程而不必为储存管理对象等问题所烦恼,把精力和时间更多的放在研发与设计上,极大地提高了开发者的工作效率和工作热情。
大数据类设计开发的基本流程是:
利用 python语言编写网络爬虫程序,实现了从网上爬取数据资料,使用urllib函数以及re模块、 pymongo模块进行源代码的获取、编辑和数据的导出,从最初给定的一个或多个的网页链接地址(URL)开始,先读取网页的内容,然后再提取网页中的URL加入新的链接队列(URL队列)中,并把当前网页存入网页数据库中,接着再从新的URL队列中取出一个或多个的URL,读取新链接的网页内容,如此不断循环下去,直至遍历了所有的网页或者达到外部给定的条件为止。
(1)数据采集与清洗
数据采集与清洗是开发项目的首要环节。通过Spider爬虫技术使用requests、BeautifulSoup等库,从各大考目标网站等渠道自动抓取海量的数据,随后,利用Pandas等数据处理库对采集到的数据进行清洗,去除重复、无效或错误的数据,确保数据的质量和准确性,为后续分析提供可靠的基础。
(2)数据存储与管理
完成数据清洗后,进入数据存储与管理阶段。采用MySQL关系型数据库,利用Python的数据库连接库如PyMySQL、SQLAlchemy等,将清洗后的数据有序存储。通过设计合理的数据库表结构,实现数据的高效查询、更新和管理。同时,确保数据的安全性和稳定性,为系统的长期运行提供保障。
(3)数据处理与分析
数据处理与分析是系统的核心环节。利用Python的强大数据处理能力,通过Numpy、Scipy等科学计算库对存储的数据进行统计分析、数学建模和机器学习等操作。通过聚类分析、回归分析等方法挖掘数据背后的规律和趋势,这一阶段将数据转化为有价值的信息,为决策提供支持。
(4)可视化与展示
最后,进入可视化与展示阶段。利用Python的可视化库如Matplotlib、Seaborn、Plotly等,将复杂的数据分析结果以直观、易懂的图表形式展示出来。通过设计交互式仪表盘,使用户能够轻松筛选、对比和分析数据。同时,结合Web开发技术Django等,将可视化结果嵌入到Web页面中,可视化与展示环节使数据变得生动易懂,提升了用户体验和系统的实用性。
论文大纲
第一章 引言
1.1 研究背景与意义
1.2 研究目的与目标
1.3 论文结构概述
第二章 系统需求分析与设计
2.1 系统需求分析
2.1.1 用户需求分析
2.1.2 功能需求分析
2.1.3 性能需求分析
2.2 系统设计
2.2.1 系统架构设计
2.2.2 功能模块设计
2.2.3 数据库设计
第三章 系统实现
3.1 开发环境搭建
3.2 前端实现
3.2.1 页面设计与布局
3.2.2 交互逻辑实现
3.3 后端实现
3.4 数据库实现
3.4.1 数据库连接与操作
3.4.2 数据存储与查询优化
第四章 系统测试
4.1 测试环境搭建
4.2 功能测试
4.3 性能测试
4.4 安全性测试
第五章 系统评估与优化
5.1 系统评估
5.1.1 用户体验评估
5.1.2 系统性能评估
5.1.3 安全性评估
第六章 结论与展望
6.1 研究总结
6.2 研究创新点
6.3 未来研究方向
致谢
结论
学习了解并熟练掌握 python的语法规则和基本使用,对网络爬虫的基础知识进行了一定程度的理解,提高对网页源代码的认知水平,学习用正则表达式来完成匹配查找的工作,了解数据库的用途,学习数据库的安装和使用及配合 python的工作,基于Python在资源管理平台上,通过搭建面向互联网特定网站,使用网络爬虫技术抓取信息资源数据采集系统,对了解各种类型爬虫的原理和具体实现过程,分析对比各种类型网络爬虫原理、以及优点,缺点。结合互联网特征,采取URL去重和判断主题相关性。
推荐算法:采用协同过滤、内容基推荐等算法,结合用户的历史数据与实时行为,实现个性化金融产品的精准推荐。不断优化算法,提高推荐的准确性和个性化程度,减少冷启动问题和稀疏性问题对推荐效果的影响。
性能与稳定性:确保系统在处理大规模用户请求和高并发访问时仍能保持稳定的性能和良好的响应速度。对系统进行性能优化和稳定性测试,以确保其能够高效运行。
源码lw获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!
需要成品或者定制,加我们的时候,不满意的可以定制,同行可拿货,招校园代理
文章最下方名片联系我即可~ 所有项目都经过测试完善,本系统包修改时间和标题,包安装部署运行调试,本系统还支持springboot/laravel/express/nodejs/thinkphp/flask/django/ssm/springcloud 微服务分布式等框架