在大模型技术快速发展的今天,模型规模的不断扩展已成为推动性能提升的核心因素。但传统的"密集"(Dense)架构,其每次推理都需调用全部参数,正面临着计算成本和能耗的巨大瓶颈。

面对这一困境,混合专家模型(Mixture-of-Experts, MoE)凭借其创新性的稀疏结构脱颖而出。到2025年,该技术已被公认为打造万亿参数级超大语言模型(LLM)与高性能多模态模型的主流解决方案之一。
MoE的核心理念在于"条件计算"(Conditional Computation),其通过将大型神经网络拆分为若干功能独立的"专家"子模块,并借助"门控网络"(Gating Network)或"路由器"(Router)实现按需激活特定专家处理输入数据。
具体而言,MoE采用任务分解策略:复杂任务被拆分为多个专项子任务,由特定专家分别处理。
在该架构中,各"专家"专注于差异化信息的学习与处理,而"路由器"则基于输入特征动态匹配最优专家,将其输出作为最终结果。
这种机制使得模型总参数量可以极大增加,从而提升模型容量和知识存储能力,但每次前向传播的实际计算量(FLOPs)却能维持在较低水平,实现了模型规模与计算效率的"解耦"。
更多AI大模型学习视频及资源,都在智泊AI。
一、MoE模型简史
MoE模型的思想源头可追溯至1991年Michael Jordan与Geoffrey Hinton等学者发表的奠基性论文《Adaptive Mixture of Local Experts》。
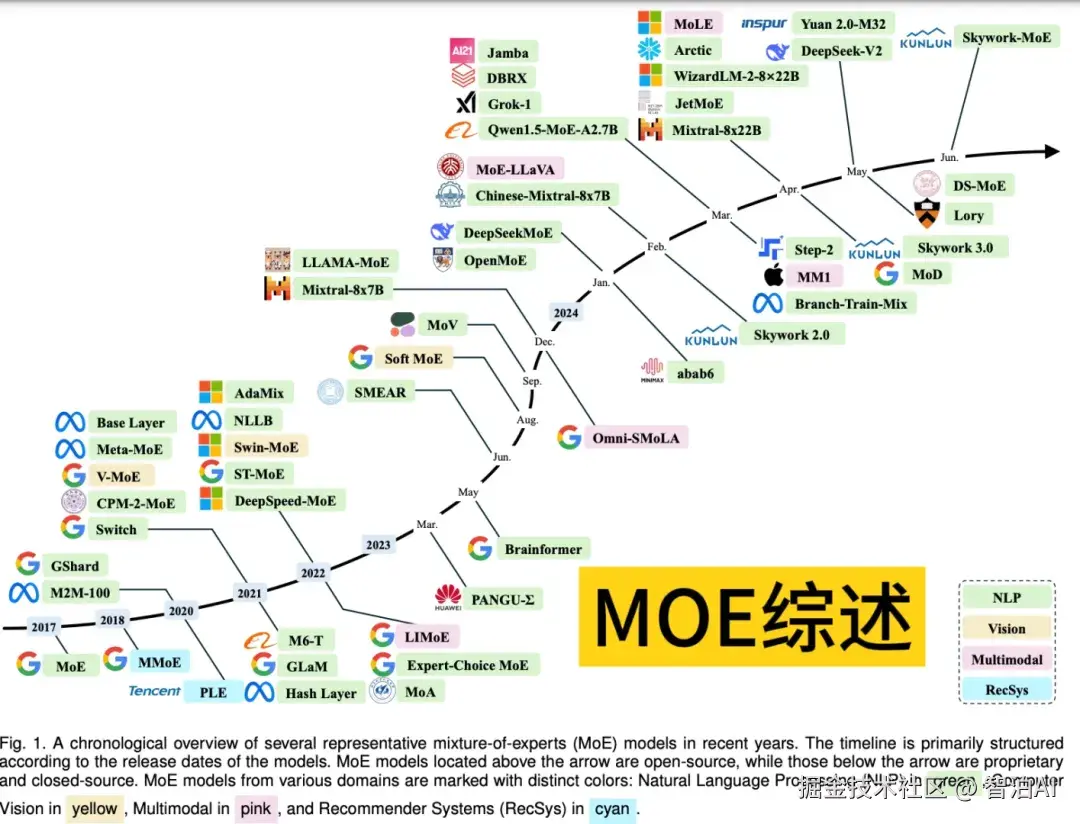
该研究首次系统阐述了"分而治之"的核心理念------通过将复杂问题拆解为子问题并由专业化模型分别处理,构建了类似人类专家协作的架构体系。
在MoE框架中,各专家模块聚焦特定领域任务,门控网络则依据输入特征智能分配计算资源。这种机制既确保了模型性能优势,又实现了计算效率的大幅提升。
2010-2015年,混合专家模型(MoE)的进步主要源于组件专家与条件计算两大方向。
组件专家通过将MoE整合至深层网络结构,显著提升了模型的效率与规模扩展能力;条件计算则借助动态网络组件激活机制,进一步优化了计算资源利用率。

2017年,谷歌团队在论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》中提出将MoE与LSTM(长短期记忆网络)融合,利用稀疏性特征实现大规模模型的快速推理。
该技术虽在机器翻译领域取得显著效果,但仍需应对通信开销高和训练稳定性不足等问题。
后续研究中,MoE技术持续深化。2020年,谷歌通过GShard项目首次将MoE集成至Transformer架构,并开发出支持分布式并行计算的高效框架,为自然语言处理领域的大规模训练与推理奠定基础。
2021年,Switch Transformer和GLaM模型通过改进门控策略与专家模块设计,进一步释放了MoE在自然语言处理中的潜力。
当前,MoE的应用已超越自然语言处理范畴,逐步拓展至计算机视觉、多模态学习等前沿领域,展现出更广泛的研究价值。
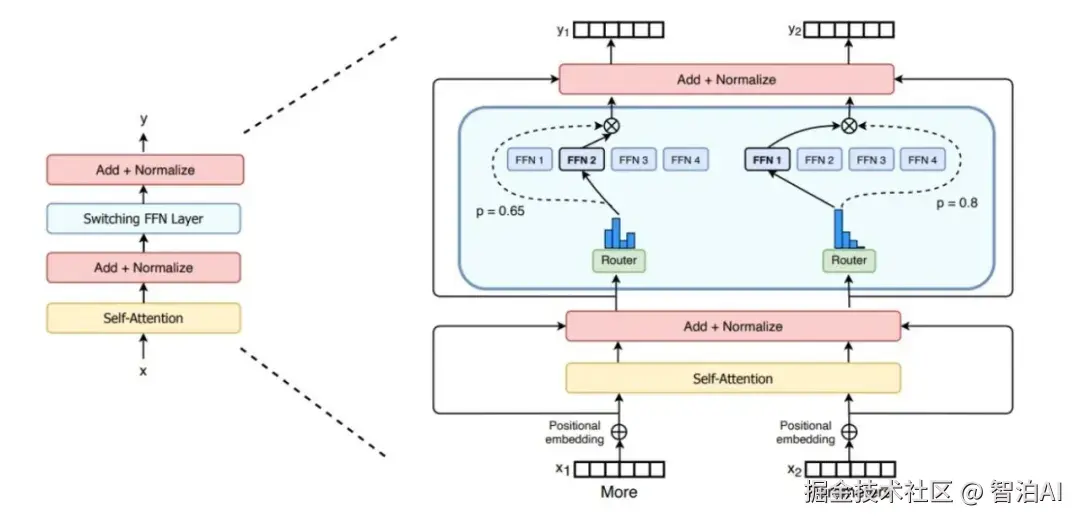
二、MoE模型的核心架构与工作原理
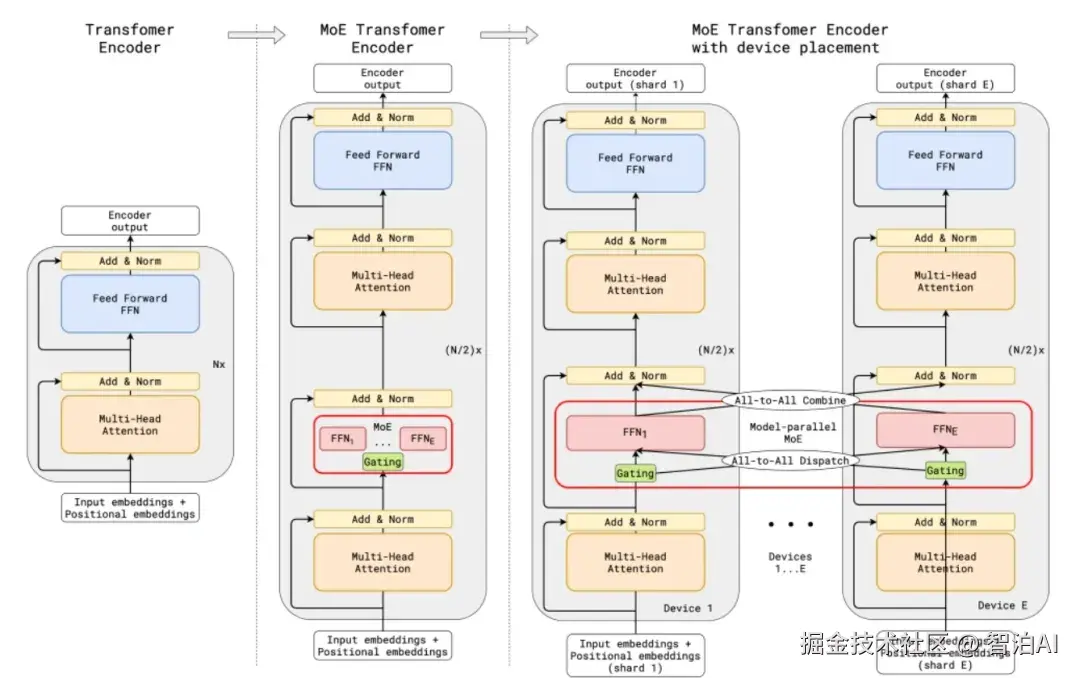
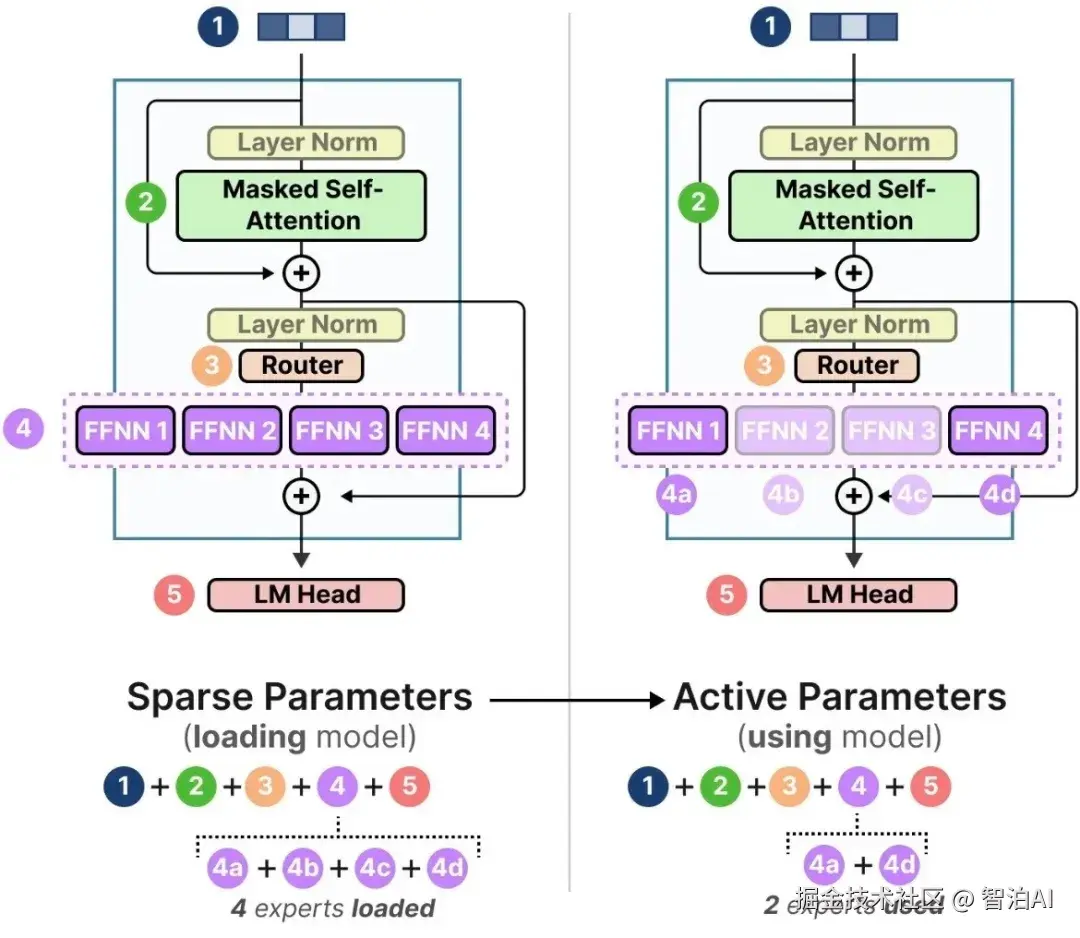
MoE架构并非单一固定的设计,但其核心组件和工作流程具有共通性。一个典型的MoE层通常嵌入在Transformer架构中,用于替代其中的前馈网络(Feed-Forward Network, FFN)层。

工作原理:条件计算与稀疏激活
MoE的工作流程可分解为三个核心阶段:分发-计算-整合,具体实现如下:
分发 (Dispatch)
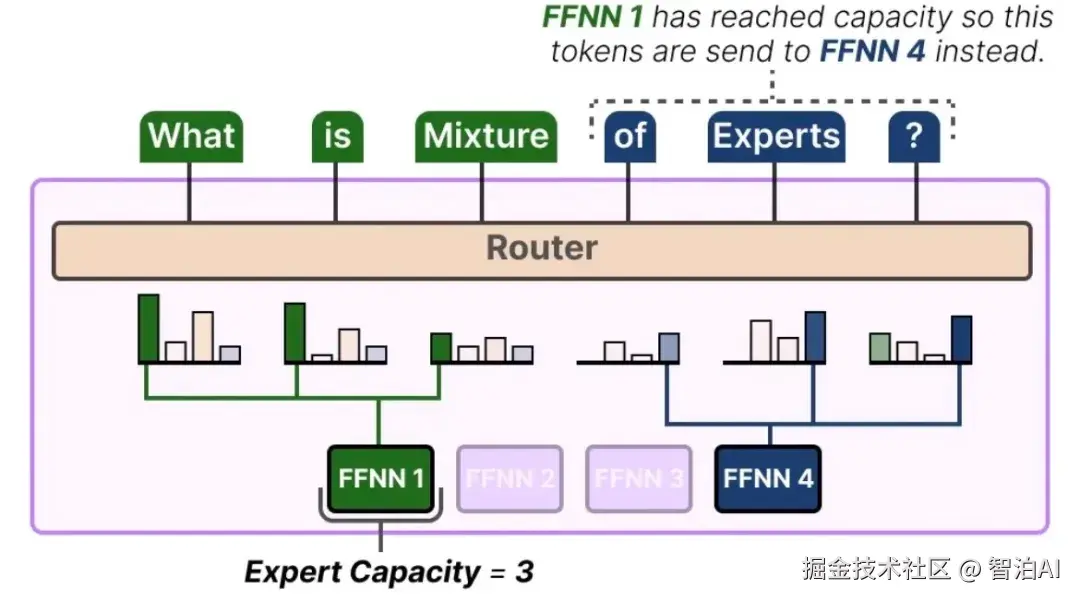
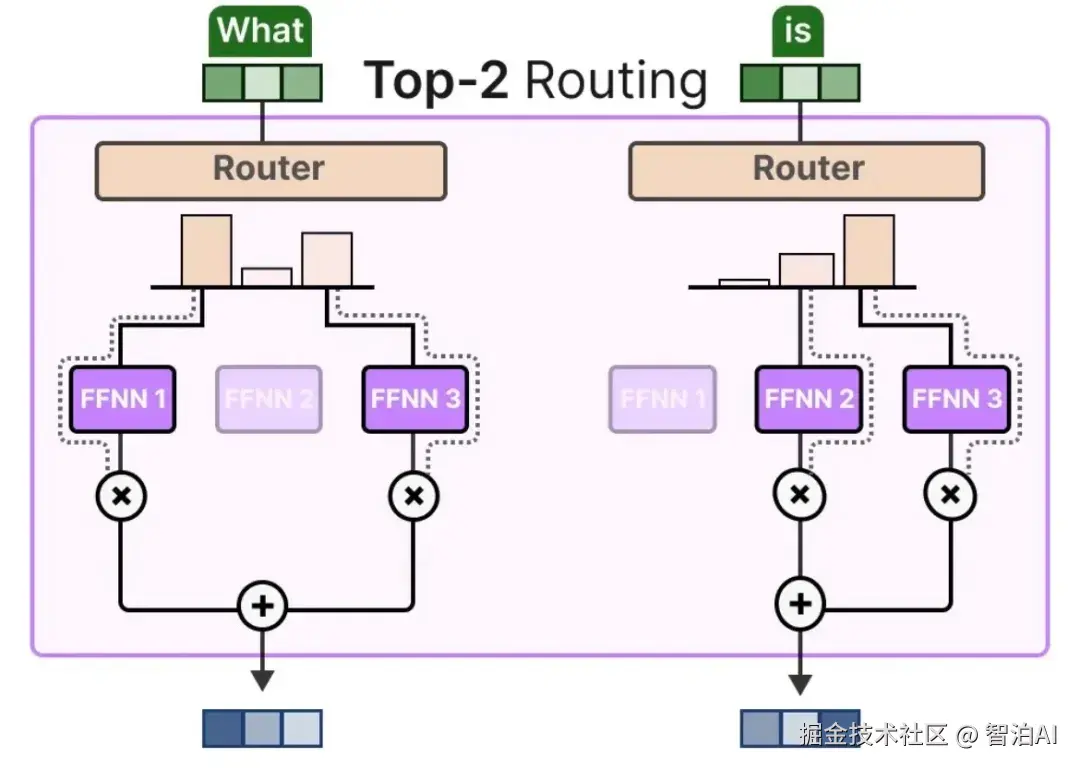
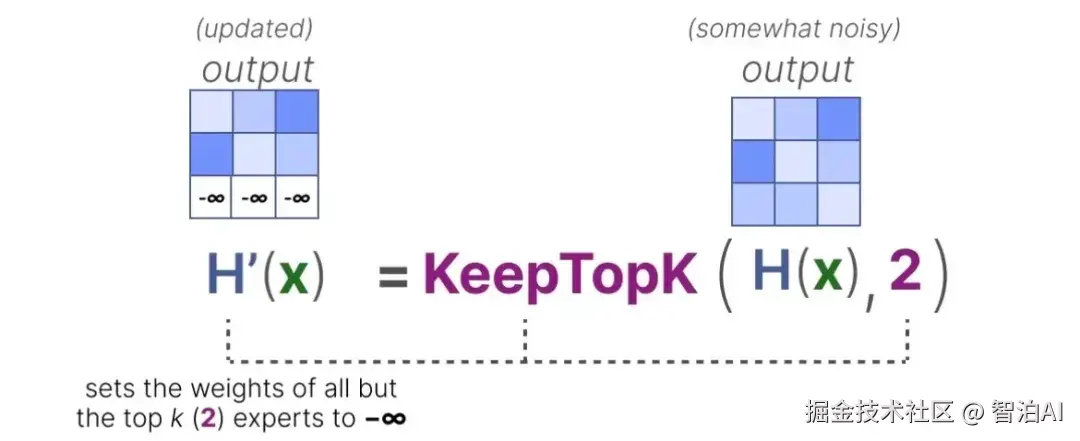
输入批次中的每个令牌均通过门控网络动态筛选,门控网络会为其分配Top-K个最匹配的专家子集。
计算 (Compute)
令牌被路由至选定的专家模块进行并行处理,其余专家处于闲置状态,不参与当前计算任务。
整合 (Combine)
根据门控网络生成的权重系数,对每个令牌对应的K个专家输出结果进行加权融合,生成最终输出。
这种机制使MoE模型在保持庞大总参数量(如Mixtral 8x7B6含8个专家,总参数约47B)的同时,实际推理中每个令牌仅激活2个专家,计算量相当于12.9B的密集模型。
其推理成本(FLOPs)仅与激活专家数相关,显著低于同等参数规模的密集模型。
三、MoE模型的训练挑战与关键优化技术
尽管MoE在扩展性上优势显著,但其训练过程远比密集模型复杂,需要一系列精巧的算法技术来保证训练的稳定性和效率。
核心挑战:负载不均衡
在训练过程中,一个常见的棘手问题是负载不均衡(Load Imbalance):门控网络可能倾向于频繁选择少数几个"热门"专家,而其他专家则很少被激活,成为"冷门"专家。
这会导致模型训练效率低下,部分参数得不到充分训练,最终损害模型性能 。
关键优化技术详解
分布式训练与并行策略
由于Mixture-of-Experts(MoE)模型的参数量级庞大,单卡GPU显存无法容纳完整模型,必须采用分布式训练架构。
除传统的数据并行(DP)与张量并行(TP)外,MoE创新性地提出专家并行(EP)机制:通过将不同专家模块动态分配到多GPU或多计算节点上实现负载均衡。

混合并行架构:当前主流MoE训练框架(如Megatron-LM、DeepSpeed)普遍采用数据、张量与专家并行的三重混合策略,通过协同调度充分释放集群计算潜力。
通信瓶颈优化:专家并行会触发高频All-to-All通信,即各GPU需向其他节点专家发送令牌并聚合结果。
针对此瓶颈的优化方案包括:部署高速互联硬件(如NVLink、Infiniband)、升级通信库(如NCCL)以及构建拓扑感知的并行任务分配算法。

边缘设备部署与推理优化
将大规模MoE模型部署至手机、车载终端等边缘设备是前沿研究方向。核心挑战在于边缘设备有限的存储与算力与MoE模型海量参数之间的矛盾,现有解决方案包括:
专家卸载(Expert Offloading):仅将高频使用的专家权重常驻GPU/NPU缓存,低频专家保留于CPU内存或闪存,按需动态加载。
智能路由策略(Cache-Aware Routing):设计优先选择已缓存专家的路由算法,最大化局部访问率以降低延迟。
模型轻量化(Model Distillation & Compression):通过知识蒸馏将大MoE模型压缩为小规模密集模型或精简MoE架构,适配边缘资源约束。
实验表明,EdgeMoE与SiDA-MoE等方案可有效降低移动端推理延迟(最高达3倍)并减少内存占用。
四、性能基准:MoE模型 vs. 稠密模型
MoE模型的核心价值是在相似甚至更低的计算成本下,达到或超越更大规模的密集模型的性能。
大量研究和实践表明,MoE模型在性能和计算成本之间取得了更优的平衡。在相同的计算预算(FLOPs)下,MoE模型通常能展现出更低的困惑度(Perplexity)和更高的下游任务准确率 。
SwitchTransformer
Google的研究表明,Switch Transformer模型在计算量(220M参数)与T5-Base相近的情况下,性能可达到T5-Large(770M参数)的水平。在TPUv3硬件上,其推理速度相比同等计算量的密集模型提升最高达7倍。
GLaM
同为Google提出的GLaM模型,尽管总参数量达到1.2T,但推理成本仅为GPT-3 (175B)的1/3,同时在多项零样本(Zero-shot)NLP任务中表现更优。
Mixtral 8x7B
由Mistral AI开源的Mixtral 8x7B模型,通过约13B的激活参数,在基准测试中超越参数规模达70B的Llama 2 70B模型,被确立为开源领域的新标杆。

挑战与权衡
尽管推理高效,但MoE模型也存在固有挑战:
巨大的内存占用:需要存储所有专家的参数,对GPU显存要求极高。
复杂的训练系统:需要专门的并行策略(如专家并行)和通信优化,训练基础设施复杂。
通信开销:专家并行中的All-to-All通信是主要瓶颈,尤其是在大规模集群中。
五、MoE的应用领域扩展:从NLP到视觉与多模态
MoE技术率先在自然语言处理(NLP)领域取得显著突破,其应用范围正快速向计算机视觉与多模态等更多领域延伸。

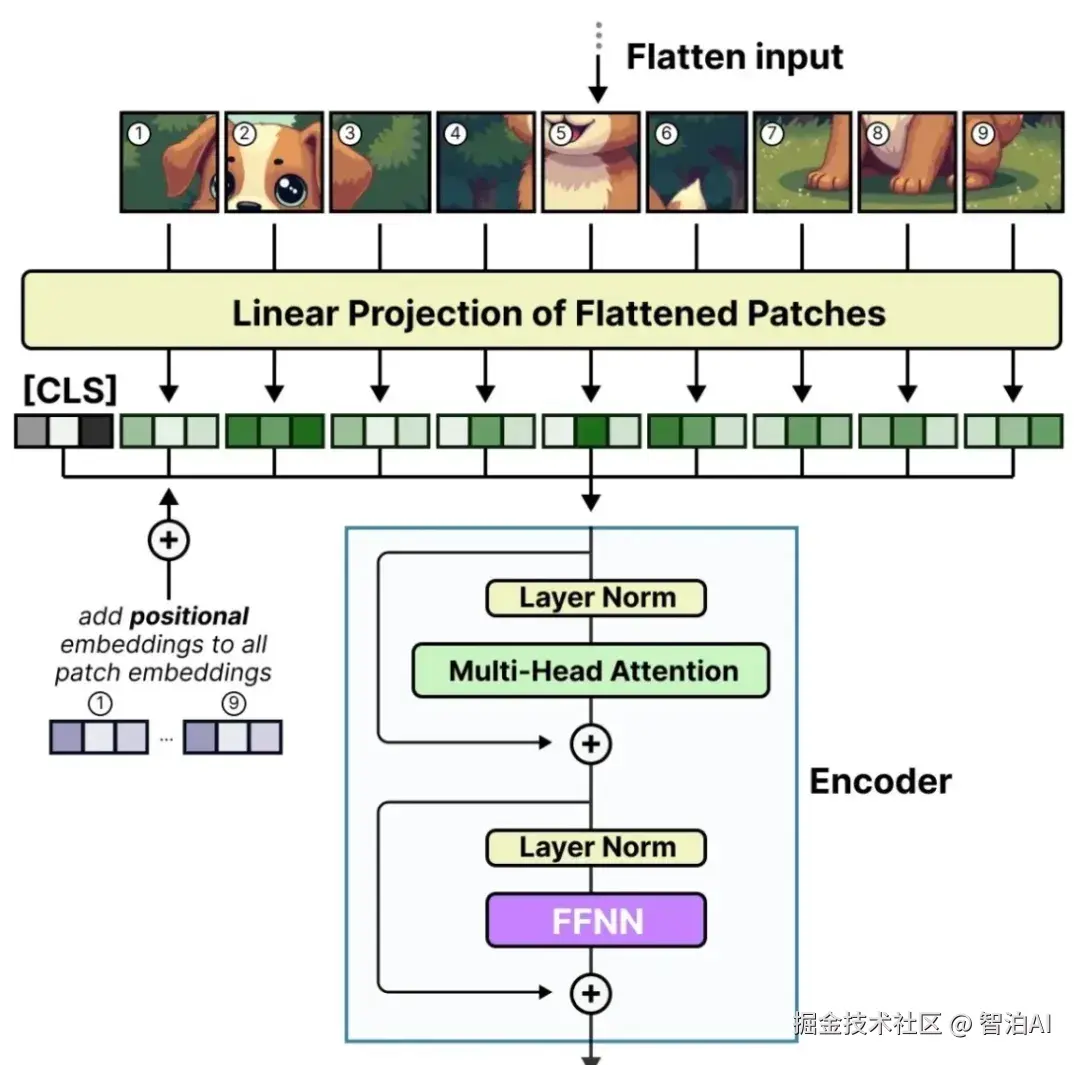
在视觉研究方面,科学家通过将MoE层嵌入Vision Transformer (ViT)架构,取代传统MLP模块,从而开发出V-MoE(Vision MoE)等创新模型。
该模型能智能地将图像块(patches)分配给特定专家模块,这些专家分别专注于解析各类视觉特征(如纹理构成、轮廓线条、局部物体结构)。
对于需要整合文本、图像、音频的复杂多模态任务,MoE技术表现出独特优势。
其机制允许模型灵活调配专家资源:例如部分专家专精文本语义解析,其他专家处理视觉特征提取,另有专家团队负责实现跨模态信息的协同与融合。
自2023年以来,涌现了大量多模态MoE模型,如 LIMoE、MoE-LLaVA、Ming-Lite-Omni等。
例如, MoE-LLaVA 在多个视觉问答(VQA)基准上,其性能显著优于其对应的非MoE密集模型基线 。
最后
MoE技术不仅是一项成熟且强大的技术,更是一个充满活力的研究领域。展望未来,它将驱动着更大、更强、更高效的AI模型的诞生。
更多AI大模型学习视频及资源,都在智泊AI。