第六章
重点:
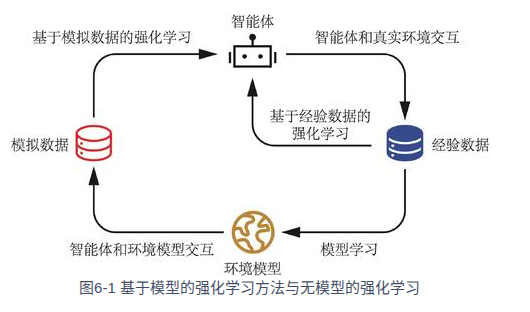
提出了有模型算法和无模型算法。
强化学习算法有两个重要的评价指标:一个是算法收敛后的策略在初始状态下的期望回报,另一个是样本复杂度,即算法达到收敛结果需要在真实环境中采样的样本数量。


核心的改动应该是指这个,利用模型去(学习or记录)一个占用度量对应的奖励和下一状态,然后使用它去更状态新价值函数,从代码上看也是做了类似的工作。

Q-planning可以有效加速收敛。
有必要反问一下这么做的动机是什么?
口胡一下,即为什么要在现在去做随机更新价值的这个动作:占用度量的状态价值函数的定义是当前状态到未来最终状态的累积懊悔(指负回报),而在前期更新状态价值函数时,对下一状态初始化其实都是0,没有形成传递链。只有随着迭代的深入,传递链才会被慢慢建立起来,而Q_learning做的工作实际上就是在加速传递链的建立。
问了GPT他也是认同的:
Q-learning / Q-planning 的目标是加速 Bellman 信号的传播,从而更快地建立起状态之间的价值传递链。