从链表到侵入式结构
- 以"学生信息链表"为应用场景。
- 通过对比两种链表实现,说明侵入式结构(intrusive data structure)与非侵入式结构(non-intrusive data structure) 的差异。
- 结合实际开发(内核 vs 用户态、性能 vs 可维护性)讨论各自优劣。
在C语言中,链表是最常见的动态数据结构之一。通常我们会为每个节点定义一个包含数据和指针的结构体,用于存储和连接元素。然而,在系统级编程(如Linux内核)中,我们常看到另一种实现方式------"侵入式链表"。
二者虽然都能实现链表功能,但在设计哲学、灵活性与性能上存在显著差异。本文以"学生信息管理系统"为例,展示两种链表设计方式的不同实现与适用场景。
非侵入式链表(Non-Intrusive Linked List)
介绍
非侵入式链表将"数据"和"链表节点"分离。 链表节点结构独立于业务数据,节点仅负责维护指针关系。
示例代码
ini
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct Student {
int id;
char name[32];
int age;
} Student;
typedef struct Node {
Student *data;
struct Node *next;
} Node;
Node *create_node(Student *stu) {
Node *node = malloc(sizeof(Node));
node->data = stu;
node->next = NULL;
return node;
}
void append(Node **head, Student *stu) {
Node *new_node = create_node(stu);
if (*head == NULL) {
*head = new_node;
return;
}
Node *cur = *head;
while (cur->next) cur = cur->next;
cur->next = new_node;
}
void print_list(Node *head) {
while (head) {
printf("ID: %d, Name: %s, Age: %d\n",
head->data->id, head->data->name, head->data->age);
head = head->next;
}
}特点与优劣
- ✅ 数据结构独立,可被多个链表、哈希表、树结构同时使用。
- ✅ 修改链表逻辑不会影响业务结构。
- ❌ 每个节点要单独分配内存(malloc两次),增加内存碎片与访问开销。
- ❌ 数据和节点分离,局部性(cache locality)较差
侵入式链表(Intrusive Linked List)
介绍
侵入式结构直接将链表指针嵌入业务结构体内部。 数据本身"知道"它属于哪个链表,这种方式常用于操作系统内核(如Linux list_head) 和高性能网络框架中。
示例代码
ini
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct Student {
int id;
char name[32];
int age;
struct Student *next; // 侵入式指针
} Student;
void append(Student **head, Student *stu) {
stu->next = NULL;
if (*head == NULL) {
*head = stu;
return;
}
Student *cur = *head;
while (cur->next) cur = cur->next;
cur->next = stu;
}
void print_list(Student *head) {
while (head) {
printf("ID: %d, Name: %s, Age: %d\n",
head->id, head->name, head->age);
head = head->next;
}
}
特点和劣势
- ✅ 数据与节点合一,内存连续、cache 友好。
- ✅ 无需额外分配内存,减少开销。
- ✅ 更适合系统编程、内核模块、高性能场景。
- ❌ 数据结构耦合性强,不能轻易复用(一个结构体难以同时挂在多个链表上)。
- ❌ 抽象层次低,可维护性较差。
对比与设计思考
| 维度 | 非侵入式结构 | 侵入式结构 |
|---|---|---|
| 内存布局 | 数据与节点分离 | 数据与节点合一 |
| 封装性 | 强,模块独立 | 弱,耦合紧密 |
| 性能 | 较低(多次 malloc,cache miss) | 高(连续访问) |
| 通用性 | 可适配不同链表/容器 | 只能服务于特定链表 |
| 典型场景 | 应用层数据结构库 | 内核、驱动、高性能系统 |
延伸:Linux 内核链表的侵入式设计
基本数据结构与初始化
arduino
struct list_head {
struct list_head *next, *prev;
};这就是内核侵入式链表的核心:双向循环链表的节点。任意包含 struct list_head 成员的结构就可以"挂链" ------ 这是侵入式设计的本质(链表指针嵌入业务结构)。
常用初始化宏 / 函数:
- LIST_HEAD_INIT(name):静态初始化(把 next/prev 都指回自己)。
- LIST_HEAD(name):在定义时同时静态初始化一个 list head。
- INIT_LIST_HEAD(struct list_head *list):运行时将 list->next = list->prev = list,把它变成空链表头。实现中会使用 WRITE_ONCE 保证写操作的可见性/内存序。
插入与删除的低级实现
内核在 list.h 中把对指针的实际修改抽成了 list_add()、 list_del() 等内部函数,然后在上面封装 list_add() / list_add_tail() / list_del() 等接口。这种分层便于对"批量操作"或"已知邻节点"的优化。基本思想和步骤都是直接操作 next/prev 四个指针。
arduino
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}访问/类型转换
侵入式链表的关键是如何从链表节点结构(struct list_head *)回到包含它的业务结构体。内核用两个组成:offsetof(标准宏)+ container_of, container_of 宏的作用是:已知某个结构体成员的指针,通过成员在结构体中的偏移量,计算出包含该成员的结构体的起始地址。简单来说,它可以让你从成员指针"反推出"结构体指针,这是 Linux 内核侵入式数据结构设计中非常常用的技巧。
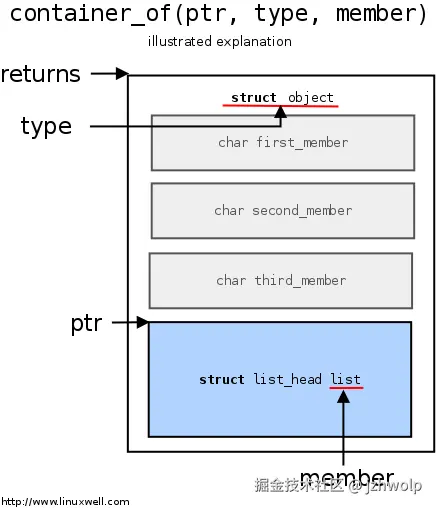
scss
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
代码示例
scss
/* student_list.c
*
* 单文件示例:侵入式链表 + container_of / list_entry
* 演示:插入、遍历、在遍历中安全删除
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stddef.h> /* offsetof */
/* -------------------- 基本类型与宏 -------------------- */
/* 内核风格的双向循环链表节点 */
struct list_head {
struct list_head *next, *prev;
};
/* offsetof 用标准头文件提供 */
/* 简化版 container_of(可移植):
* ptr: 指向 member 的指针
* type: 包含 member 的结构体类型
* member: 成员名
*/
#define container_of(ptr, type, member) \
((type *)((char *)(ptr) - offsetof(type, member)))
/* list_entry: 从 list_head 指针得到包含它的结构体指针 */
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
/* 遍历宏:迭代 list_head 指针 */
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/* 按 entry(宿主结构体)遍历 */
#define list_for_each_entry(entry, head, member) \
for (entry = list_entry((head)->next, typeof(*entry), member); \
&entry->member != (head); \
entry = list_entry(entry->member.next, typeof(*entry), member))
/* 安全遍历:在循环体可能删除当前元素时使用 */
#define list_for_each_entry_safe(entry, tmp, head, member) \
for (entry = list_entry((head)->next, typeof(*entry), member), \
tmp = list_entry(entry->member.next, typeof(*entry), member); \
&entry->member != (head); \
entry = tmp, tmp = list_entry(tmp->member.next, typeof(*tmp), member))
/* LIST 初始化(运行时) */
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list->prev = list;
}
/* -------------------- 链表基本操作 -------------------- */
/* 在 head 后插入 new(头插) */
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/* 在 tail 前插入 new(尾插) */
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
/* 从链表删除 entry(不重置 entry 指针) */
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
/* 注意:为了简单,这里不把 entry->next/prev 置为 POISON 值或 self */
}
/* -------------------- 学生结构 + 操作 -------------------- */
struct student {
int id;
char name[32];
struct list_head list; /* 侵入式成员 */
};
void add_student_tail(struct list_head *head, int id, const char *name)
{
struct student *s = malloc(sizeof(*s));
if (!s) {
perror("malloc");
exit(EXIT_FAILURE);
}
s->id = id;
strncpy(s->name, name, sizeof(s->name) - 1);
s->name[sizeof(s->name) - 1] = '\0';
INIT_LIST_HEAD(&s->list);
list_add_tail(&s->list, head);
}
void print_students(struct list_head *head)
{
struct list_head *pos;
printf("当前学生列表:\n");
list_for_each(pos, head) {
struct student *s = list_entry(pos, struct student, list);
printf(" id=%d, name=%s\n", s->id, s->name);
}
}
/* 释放链表(安全删除并 free) */
void free_all_students(struct list_head *head)
{
struct student *s, *tmp;
list_for_each_entry_safe(s, tmp, head, list) {
list_del(&s->list);
free(s);
}
}
/* -------------------- 主程序(演示) -------------------- */
int main(void)
{
struct list_head student_list;
INIT_LIST_HEAD(&student_list);
add_student_tail(&student_list, 1001, "Alice");
add_student_tail(&student_list, 1002, "Bob");
add_student_tail(&student_list, 1003, "Charlie");
add_student_tail(&student_list, 1004, "Diana");
print_students(&student_list);
puts("");
/* 示范:仅有 list_head 指针时,如何用 container_of / list_entry 恢复 student 指针 */
struct list_head *node = student_list.next->next; /* 指向 Bob 的节点(第二个) */
struct student *stu = container_of(node, struct student, list);
printf("从节点反推到结构体:id=%d, name=%s\n\n", stu->id, stu->name);
/* 在遍历中安全删除:删除名字以 'C' 开头的学生 */
printf("在遍历中删除 name 以 'C' 开头的学生...\n");
struct student *p, *q;
list_for_each_entry_safe(p, q, &student_list, list) {
if (p->name[0] == 'C') {
printf(" 删除 %s (id=%d)\n", p->name, p->id);
list_del(&p->list);
free(p);
}
}
puts("");
print_students(&student_list);
puts("");
/* 清理剩余节点 */
free_all_students(&student_list);
return 0;
}
编译&&运行
ini
gcc -Wall -Wextra -o student_list student_list
./student_list
当前学生列表:
id=1001, name=Alice
id=1002, name=Bob
id=1003, name=Charlie
id=1004, name=Diana
从节点反推到结构体:id=1002, name=Bob
在遍历中删除 name 以 'C' 开头的学生...
删除 Charlie (id=1003)
当前学生列表:
id=1001, name=Alice
id=1002, name=Bob
id=1004, name=Diana总结
- 想象一个书架上摆着很多书,每本书都是一个完整的"结构体"。
- 每本书里都有一个书签(成员),标记你正在看的页。
- 现在,你手里只有一张书签(就像拿到成员指针),你想知道它属于哪本书(即找到包含它的结构体)。
这时:
- offsetof 就像你知道书签在书里的位置(比如它夹在第 50 页),也就是成员在结构体中的偏移量。
- container_of 就像你用书签的位置和它在书里的偏移量,推算出整本书的起始位置,从而拿到整本书的信息。
总结形象说法
- offsetof = 书签在书里的位置
- container_of = 通过书签找到整本书
也就是说,从局部线索回到整体对象。
| 特性 | 侵入式(Intrusive) | 非侵入式(Non-Intrusive) |
|---|---|---|
| 定义 | 链表节点指针嵌入到业务结构体内部 | 链表节点独立于业务结构体,通过指针引用业务数据 |
| 内存布局 | 成员指针与业务数据在同一内存块内 | 节点结构与业务数据分开,通常节点里只保存指针 |
| 示例 | Linux 内核 list_head + task_struct / sk_buff |
标准 C++ STL list、Java LinkedList、C 语言中 struct node { void *data; struct node *next; } |
| 性能 | 高:少一次内存分配,缓存友好,遍历效率高 | 较低:每个节点单独分配,可能导致更多内存分配和访问 |
| 灵活性 | 低:业务结构体必须知道链表存在,修改结构体比较困难 | 高:业务结构体无需关心链表,可以被多个容器复用 |
| 可复用性 | 低:同一对象同时挂多个链表需要多个成员指针 | 高:同一对象可被多个链表引用,只需多一个节点或指针 |
| 删除/插入 | 直接操作节点指针即可,高效 | 需要通过节点找到业务数据,再操作,效率略低 |
| 安全性 | 稍低:不小心修改指针容易破坏链表 | 较高:节点与数据分离,修改节点不会破坏数据结构本身 |
| 使用场景 | 内核、驱动、高性能系统、游戏引擎等 | 应用层通用数据结构、业务逻辑、标准库容器 |
总结一句话
-
侵入式 = "业务结构体自带链表节点,性能高但耦合紧密"。
-
非侵入式 = "链表节点独立于业务数据,灵活可复用但性能稍低"。