当AI的进化带来的惊喜越来越少,我们不禁要问:大模型时代是否已经触及天花板?
昨晚,GPT-5.1正式发布,这距离GPT-5的面世仅过去了三个月。新版本带来了两个变体:Instant专注于快速响应和对话流畅性,Thinking则致力于复杂推理任务。
OpenAI宣称,GPT-5.1在数学和编程任务上有所改进,并提供了八种对话风格预设,从"专业"到"古怪"不等。
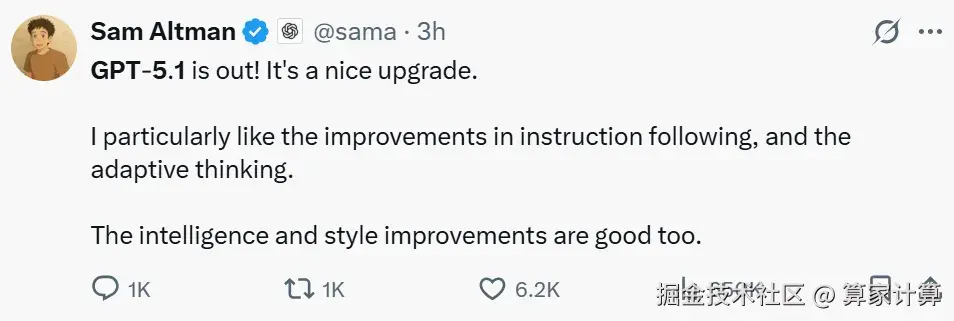
然而,翻看官方博客,你会发现一个有趣的现象:几乎没有提及性能提升的具体数据。要知道,亮出各种基准测试分数高调"炫技"可是OpenAI发布每一代新模型时,惯常的风格。
从技术层面看,GPT-5.1确实做出了一些改进。它引入了自适应推理能力,可以根据问题复杂程度自动调整思考时间。简单任务获得更快响应,复杂问题则得到更深入的思考。
在交互层面,OpenAI终于开始重视长期以来被诟病的问题------ ChatGPT的"机器感"。现在,GPT-5.1不仅"智商"更高,"情商"也有所提升。
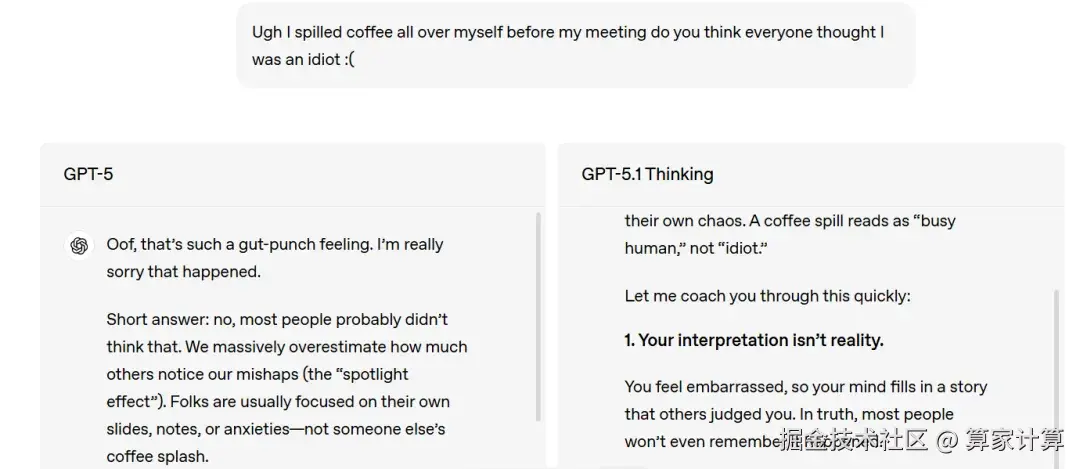
这些改进确实令ChatGPT更加易用,但与之前版本相比,几乎没有突破性的能力提升。
近段时间,ChatGPT等热门大模型持续在优化迭代,但大家或许都有一个相同的感受:大模型每次升级带给我们的惊喜,越来越少了。
尽管官方尝试用"革命性突破"、"性能碾压"这样震撼的字眼吸引用户,但真正体验下来,大部分人的反应仍然是"大差不大"。
大模型为什么越来越"没活"了?
Transformer架构的边界已现
首先,Transformer架构已经越来越接近能力边界。
自其被提出以来,Transformer已经彻底改变了自然语言处理、计算机视觉等多个领域的发展轨迹,深刻影响了ChatGPT等大语言模型的开发和应用。
【图片来源于网络,侵删】
OpenAI最早将Transformer算法能力和语言进行结合,用ChatGPT开创了大模型时代,更开启了席卷至今天的AI风暴。
然而,当前大模型普遍基于的Transformer架构,似乎正在接近其能力边界。从GPT-3到GPT-4的飞跃令人惊叹,但从GPT-4到GPT-5,再到现在的GPT-5.1,进步幅度明显收窄。
可以预见,技术发展随着时间推移确实有过快速飞跃,但到今天已经慢慢感觉到天花板了。
数据、算法与算力的三重限制
当然,除了模型架构的局限,大模型发展面临的挑战也受到了其他方面的影响。
当前,互联网上易于获取的文本资源已被大规模挖掘,这导致高质量训练数据的日益稀缺。硬件方面,随着算力成本呈现指数级增长,训练尖端AI模型的成本已接近10亿美元规模,远超历史上其他技术开发项目。
与此同时,算法创新遭遇瓶颈,简单地增加参数数量已无法带来相应的性能提升。
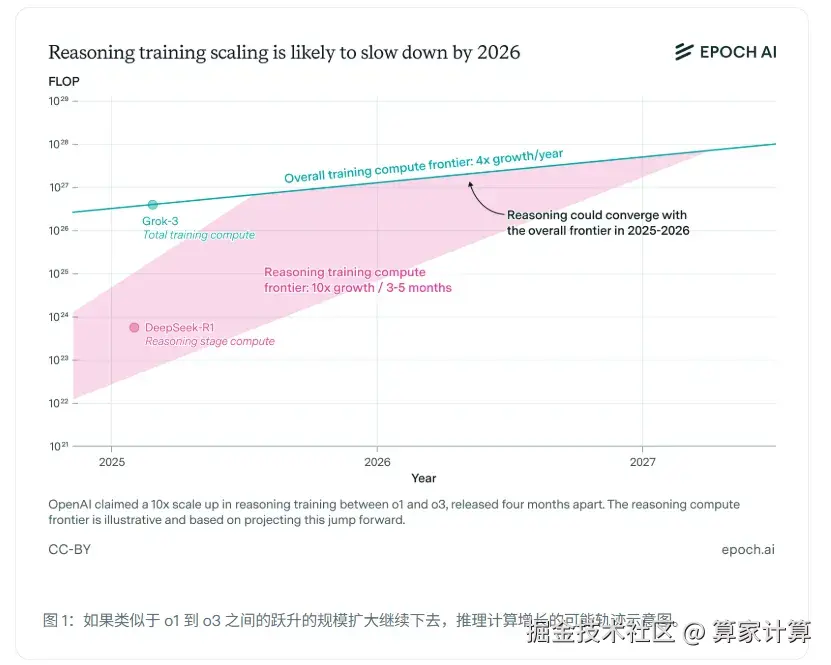
面对预训练模型的瓶颈,行业曾将希望寄托于推理模型。OpenAI的o3系列、DeepSeek的R1模型确实在复杂推理任务上表现出色。但研究表明,推理模型的快速发展可能同样面临限制。
独立研究团队Epoch AI分析认为,如果按照当前推理模型每几个月计算能力翻10倍的速度,估计最多一年就会撞上算力资源的天花板。到2026年,扩展速度将会放缓,回落到每年4倍的增速水平。
【图片来源:Epoch AI】
小模型与本地化的新路径
当云端大模型进展放缓时,产业探索的重心开始转移。小模型与本地化部署正成为AI发展的新方向。
例如,DeepSeek R1的知识蒸馏技术,将671B参数大模型的能力压缩到仅8B参数的小模型中,不仅在保持原有能力的基础上,还在AIME 2024测试中反超原模型10%。
同时,端侧AI正在崛起。英伟达推出DGX Spark,将AI训练与推理能力缩小到可部署在桌面端的规模。苹果则推出了M5芯片,显著提升单位功耗的AI计算效率,使笔记本与平板在离线状态下即可完成复杂生成任务。
大模型本身进展缓慢,行业焦点自然转向AI智能体。然而,行业存在严重的"贴牌智能体"现象,即厂商将普通的聊天机器人改头换面宣称为智能体。
真正的AI智能体需要具备三要素:感知世界、自主决策、执行行动,并最终与环境形成闭环反馈。而当前大模型在决策能力上仍有明显不足。
从模型为中心到应用为核心
大模型发展速度的放缓,实则是行业成熟的标志。任何技术都会经历从爆发期到平稳期的演进。当基础模型进步减速,产业注意力自然会从"模型创新"转向"应用落地"。
这意味着,在模型性能接近瓶颈时,数据质量与治理能力将取代模型性能成为核心竞争力。
大模型创新放缓并非AI行业的终结,而是新征程的开始。当基础技术趋于稳定,真正的创新将从实验室转向各行各业的应用场景。
未来,AI的发展可能不再由少数几个大模型的突破所引领,而是由无数个针对特定场景的精细化应用所推动。这对于整个行业来说,或许是最好的消息。