| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之Milvus向量数据库全解析 |
前情摘要
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
本文章目录
- 零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
-
-
- 一、先搞懂:为什么需要分区-分片-段?
- 二、通俗理解:用图书馆比喻看懂三者关系
-
- [1. 分区(Partition):按"主题"划分楼层](#1. 分区(Partition):按“主题”划分楼层)
- [2. 分片(Shard):同一楼层的"平行书架"](#2. 分片(Shard):同一楼层的“平行书架”)
- [3. 段(Segment):书架上的"可拆卸书盒"](#3. 段(Segment):书架上的“可拆卸书盒”)
- 三、三者核心区别:一张表看清
- 四、协作流程:数据如何在三层结构中流转?
-
- [1. 写入流程(新书进图书馆)](#1. 写入流程(新书进图书馆))
- [2. 查询流程(用户找书)](#2. 查询流程(用户找书))
- 五、最佳实践:避坑指南+配置示例
-
- [1. 分区使用最佳实践](#1. 分区使用最佳实践)
-
- [✅ 推荐做法](#✅ 推荐做法)
- [❌ 错误示范](#❌ 错误示范)
- 代码示例:创建分区
- [2. 分片配置最佳实践](#2. 分片配置最佳实践)
-
- [✅ 推荐做法](#✅ 推荐做法)
- [❌ 错误示范](#❌ 错误示范)
- 代码示例:创建集合时指定分片数
- [3. 段优化最佳实践](#3. 段优化最佳实践)
-
- [✅ 推荐做法](#✅ 推荐做法)
- 代码示例:段配置与合并
- 六、核心总结
-
零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
上一篇我们全面拆解了Milvus向量数据库的基础特性、架构和核心概念,知道了Collection、Entity这些"数据容器"的作用。但面对亿级甚至千亿级向量数据,Milvus是如何高效组织和检索的?核心就在于"分区-分⽚-段"这三层数据结构------这也是很多同学最容易混淆的点。今天就用"图书馆管理"的通俗比喻,带你吃透三者的关系、作用,再送上可直接落地的最佳实践!

一、先搞懂:为什么需要分区-分片-段?
Milvus的核心优势是"海量数据下的高性能检索",而这三层结构正是实现这一优势的关键:
- 没有它们,千亿级向量会变成"一锅乱粥",查询时需要全量扫描,速度慢到无法使用;
- 分区解决"数据筛选"问题,减少查询范围;
- 分⽚解决"并行处理"问题,提升读写吞吐量;
- 段解决"存储优化"问题,方便数据合并、压缩和维护。
简单说,这三层结构就像图书馆的"分层管理体系",让海量数据变得"井井有条",查询和写入效率翻倍。
二、通俗理解:用图书馆比喻看懂三者关系
把Milvus的Collection(集合)类比成一个超大型图书馆 ,里面存放着上亿本"数据图书"。为了管好这些书,图书馆设计了三层管理逻辑,对应Milvus的三层结构:
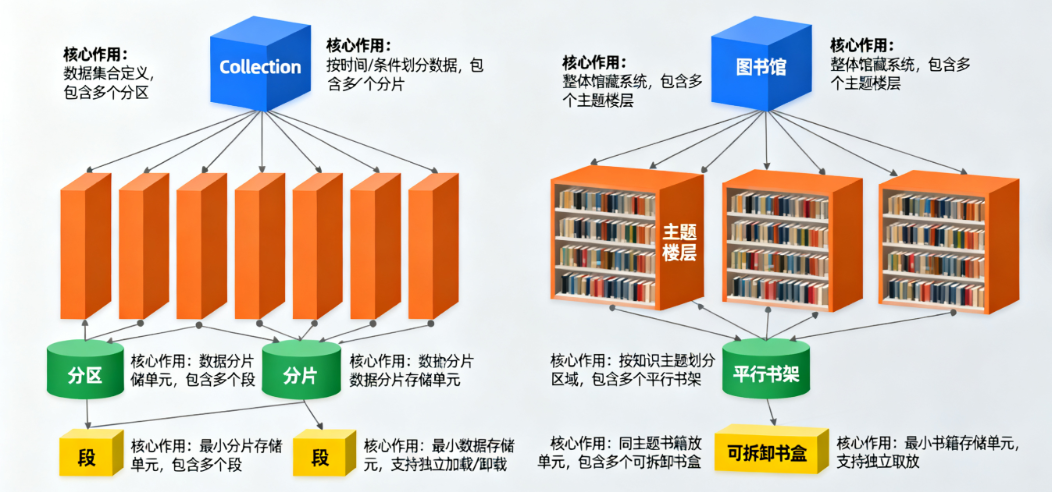
1. 分区(Partition):按"主题"划分楼层
- 定义:Collection的逻辑划分,按业务维度将数据分组,比如按类别、时间、地域等。
- 图书馆类比:图书馆按主题分楼层------1楼科技区、2楼文学区、3楼艺术区、4楼少儿区。
- 核心作用:查询时只扫描目标分区,避免全量遍历。比如想找"AI相关的书",直接去1楼科技区,不用跑遍所有楼层。
- 实际应用:电商平台将商品向量按"电器/服装/食品"分区,用户查询"手机"时,只检索"电器分区";日志数据按"2024-01/2024-02"时间分区,查询上月日志时无需扫描全年数据。
2. 分片(Shard):同一楼层的"平行书架"
- 定义:Partition的物理分布单元,将一个分区的数据均匀拆分到多个节点上。
- 图书馆类比:1楼科技区有10个结构相同的平行书架,每个书架都存放部分科技类书籍,总量覆盖全部分区数据。
- 核心作用:实现并行读写。比如10个用户同时找科技类书,可分别在10个书架上并行查找,不用排队;写入新数据时,也能分散到多个书架,避免单个书架拥挤。
- 实际应用:分布式集群中,一个"电器分区"的数据被拆分成8个分⽚,分布在8台服务器上,写入和查询时8台机器并行工作,吞吐量提升8倍。
3. 段(Segment):书架上的"可拆卸书盒"
- 定义:Shard的最小物理存储单元,数据最终以段为单位存储在磁盘和内存中。
- 图书馆类比:每个书架由多个可拆卸书盒组成,新书先放进"临时书盒"(活跃段),书盒装满后密封成"固定书盒"(密封段),后续可统一压缩归档。
- 核心作用:优化存储和查询效率。小书盒会被自动合并成大书盒(段合并),减少存储碎片;密封后的书盒可压缩,节省空间;查询时按书盒批量扫描,比单本查找更快。
- 实际应用:Milvus中,段默认按512MB大小切割,新写入数据先进入"增长段",达到阈值后自动"密封",后台异步合并小段,提升查询性能。
三、三者核心区别:一张表看清
| 维度 | 分区(Partition) | 分⽚(Shard) | 段(Segment) |
|---|---|---|---|
| 层级关系 | Collection下的逻辑划分 | Partition下的物理分布 | Shard下的最小存储单元 |
| 管理方式 | 用户手动创建、指定 | 系统自动分配、路由 | 系统完全自动管理 |
| 核心目的 | 业务隔离,减少查询范围 | 负载均衡,提升并行能力 | 存储优化,加速读写 |
| 可见性 | 对用户可见(可指定查询) | 对用户透明(无需关注) | 对用户完全透明 |
| 类比对象 | 图书馆的"楼层主题区" | 楼层内的"平行书架" | 书架上的"可拆卸书盒" |
四、协作流程:数据如何在三层结构中流转?
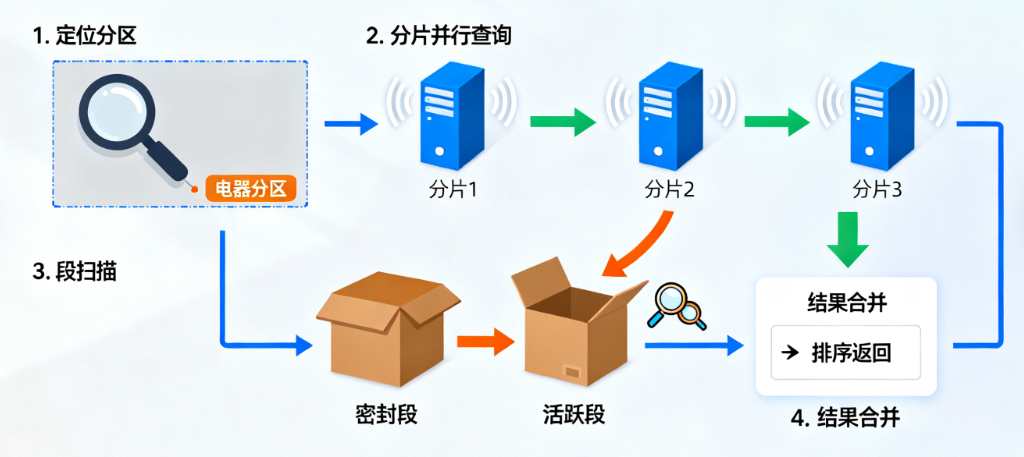
以"电商平台上传10万条商品向量数据"为例,看分区-分片-段的协作过程:
1. 写入流程(新书进图书馆)
- 数据分类:10万条数据中,3万条电器、5万条服装、2万条食品,分别写入对应的"电器分区""服装分区""食品分区"(用户指定分区);
- 分片分配:系统将每个分区的数据均匀分配到3个分⽚(假设集群有3个节点),比如"电器分区"的3万条数据,每个分⽚存储1万条;
- 段存储:每个分片内,数据按512MB大小自动切割成段,新数据先写入"增长段",写满后密封为"固定段";
- 后台优化:系统异步合并小段,比如将2个100MB的段合并成200MB的大段,减少存储碎片。
2. 查询流程(用户找书)
- 定位分区:用户查询"价格<1000元的手机",先筛选"电器分区"(排除服装、食品分区);
- 分片并行查询:查询请求同时发送到"电器分区"的3个分⽚,每个分片并行扫描自己的段数据;
- 段扫描:每个分片内,扫描所有相关段(只看密封段+活跃段),筛选出符合"价格<1000元"且向量相似的结果;
- 结果合并:收集3个分片的结果,排序后返回给用户。
五、最佳实践:避坑指南+配置示例
这部分是核心干货,直接告诉你怎么用、怎么避坑,新手也能快速上手!
1. 分区使用最佳实践
✅ 推荐做法
- 按"高选择性维度"分区:优先按时间(如2024Q1、2024-01)、类别、地域等查询频率高的维度划分;
- 控制分区数量:单个Collection的分区数不超过1000个,过多会导致元数据管理压力大,影响性能;
- 分区命名规范:用"维度+值"命名,比如"time_202401""category_electronics",便于管理。
❌ 错误示范
- 按"低选择性维度"分区:比如给每个用户创建一个分区,用户量达1万时,分区数就超标;
- 分区后不使用:创建了分区但查询时不指定分区,相当于白做了划分,还增加了管理开销。
代码示例:创建分区
python
from pymilvus import Collection
# 假设已创建Collection:products
collection = Collection(name="products")
# 1. 创建按类别划分的分区
collection.create_partition(partition_name="category_electronics")
collection.create_partition(partition_name="category_clothing")
collection.create_partition(partition_name="category_food")
# 2. 创建按时间划分的分区
collection.create_partition(partition_name="time_202401")
collection.create_partition(partition_name="time_202402")
# 3. 查询时指定分区(只查2024年1月的电器数据)
query_params = {
"data": [query_vector],
"partition_names": ["category_electronics", "time_202401"],
"limit": 10
}
results = collection.search(**query_params)2. 分片配置最佳实践
✅ 推荐做法
- 分片数计算公式:分片数 = 节点数 × 每节点CPU核数(比如8台8核机器,分片数设为64);
- 控制单分片数据量:单分片数据量建议在1000万-1亿向量之间,太小浪费资源,太大影响性能;
- 动态调整:根据业务增长扩容节点时,同步增加分片数,保持负载均衡。
❌ 错误示范
- 分片数远超资源:8核机器设置128个分⽚,导致线程频繁切换,性能下降;
- 分⽚数过少:10台机器只设2个分片,大部分机器闲置,无法发挥并行优势。
代码示例:创建集合时指定分片数
python
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
# 定义字段(同前文)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50),
FieldSchema(name="price", dtype=DataType.FLOAT)
]
schema = CollectionSchema(fields, description="商品向量库")
# 创建集合时指定分⽚数(64个分⽚,适配8台8核机器)
collection = Collection(
name="products",
schema=schema,
shards_num=64 # 核心配置:分⽚数
)3. 段优化最佳实践
✅ 推荐做法
- 调整段大小阈值:根据向量维度调整,维度>1024时设为512MB(减少内存压力),维度<1024时设为1024MB;
- 监控段状态:定期查看段信息,避免出现大量小段;
- 手动触发合并:数据写入高峰后,手动调用合并接口,优化存储结构。
代码示例:段配置与合并
python
from pymilvus import Collection, connections
connections.connect("default", host="localhost", port="19530")
collection = Collection(name="products")
# 1. 调整段大小阈值(通过Milvus客户端配置)
# 方式1:创建集合时通过schema配置(部分版本支持)
schema = CollectionSchema(
fields=fields,
description="商品向量库",
properties={"storage.segmentSize": 1024} # 段大小1GB(单位MB)
)
# 方式2:通过客户端设置全局属性
client = connections.get_connection_client("default")
client.set_property("dataCoord.segment.maxSize", "1024") # 最大段大小1GB
client.set_property("dataCoord.segment.sealProportion", "0.7") # 写入70%时密封
# 2. 查看段信息
segment_info = collection.get_segment_info()
print("当前段数量:", len(segment_info))
# 3. 手动触发段合并(数据写入后执行)
collection.compact()
print("段合并触发成功,后台异步执行")六、核心总结
- 分区管"逻辑分组",解决"查得少"的问题;分片管"物理分布",解决"跑得并行"的问题;段管"存储优化",解决"存得好"的问题;
- 最佳实践核心:分区按高选择性维度划分,分片数匹配集群资源,段大小适配向量维度;
- 新手建议:先从"时间分区+按核数设分片+默认段大小"入手,后续根据业务数据量和性能表现微调。
这三层结构是Milvus高性能的基石,掌握后就能灵活应对不同规模的业务场景------从几十万向量的小项目,到千亿向量的企业级系统,都能通过合理配置发挥Milvus的最大性能。