在构建大规模语言模型(LLM)训练框架时,Megatron-Core 无疑是业界的标杆。然而,直接修改 Megatron 源码往往是"牵一发而动全身",不仅维护困难,还难以跟进上游的更新。
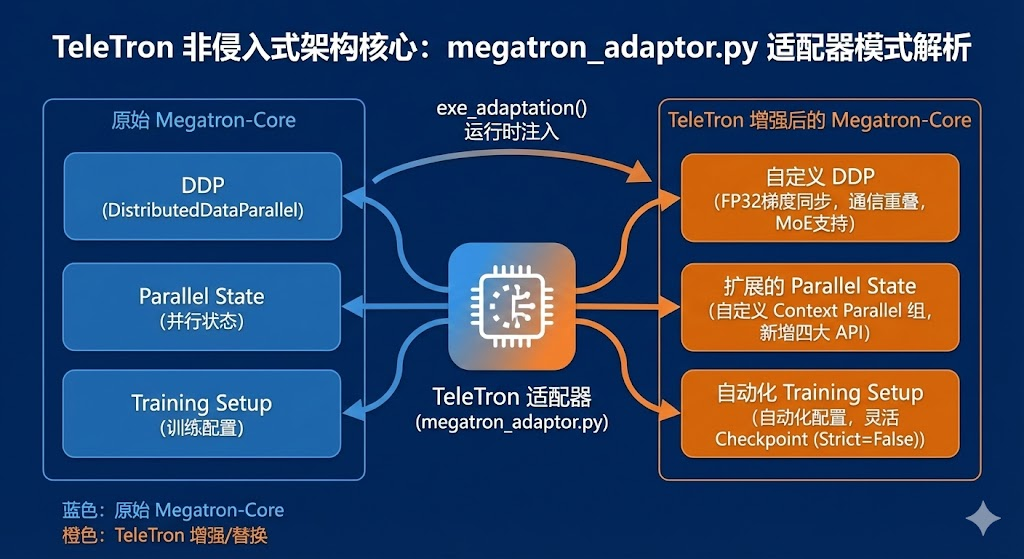
TeleTron 项目通过一个极其优雅的 megatron_adaptor.py 文件,向我们展示了如何利用适配器模式(Adapter Pattern),在不侵入 Megatron 源码的前提下,注入自定义的 DDP 实现、扩展并行能力并优化训练流程。
本文将深入剖析 TeleTron 的核心适配机制,带你领略这一"非侵入式架构"的魅力。
核心机制:一行代码引发的"运行时注入"
megatron_adaptor.py 的魔法源于 exe_adaptation() 函数。当模块被加载时(Line 48),这个函数会自动执行,像"手术刀"一样在运行时替换掉 Megatron 的关键组件。
python
# 伪代码示意
def exe_adaptation():
# 替换 DDP 实现
megatron.core.DistributedDataParallel = CustomDistributedDataParallel
# 装饰并行初始化函数
megatron.core.parallel_state.initialize_model_parallel = wrapper(...)
# ...这种模式的三大优势:
-
非侵入性:无需修改 Megatron-Core 库的任何一行代码。
-
模块化:自定义逻辑独立封装,与框架解耦。
-
兼容性:保持原有接口签名,下游代码无感切换。
深度剖析 1:重新定义 DistributedDataParallel (DDP)
TeleTron 对 DDP 的重写不仅仅是替换,更是对数值稳定性 和通信效率的双重优化。
1. 梯度同步的"精度魔法"
在混合精度训练中,梯度的数值稳定性至关重要。TeleTron 重写了 ParamAndGradBuffer.start_grad_sync,引入了智能的类型转换策略:
-
通信前 (Cast to FP32):在执行 All-Reduce 之前,将梯度强制转换为 float32。这有效避免了低精度下的下溢出问题。
-
通信后 (Back to BF16):通信完成后立即转回 bfloat16,既保证了计算精度,又节省了显存。
2. 通信与计算的完美"重叠" (Overlap)
为了压榨 GPU 性能,新的 DDP 实现了增强的梯度管理:
-
分桶策略:将模型梯度切分成更小的 Bucket。
-
异步通信 :通过 overlap_grad_reduce 参数,利用 Hook 机制在反向传播(Backward)的同时触发梯度的异步 All-Reduce。当计算还在进行时,通信已经悄然开始。
-
专家并行支持:不仅支持 Dense 参数,还为 Mixture-of-Experts (MoE) 的参数分配了独立的缓冲区和通信组。
深度剖析 2:打通 Context Parallel 的"任督二脉"
Megatron 原生对 Context Parallel(上下文并行)的支持可能存在限制,TeleTron 通过装饰器模式巧妙地扩展了 parallel_state。
1. 聪明的"欺骗"策略
在 initialize_model_parallel 的装饰器中,适配器做了一个动作:
-
它接收 context_parallel_size 参数,但在调用原始 Megatron 函数时,将其强制设为 1。
-
为什么要这么做? 这避免了 Megatron 原生逻辑抛出不兼容错误,随后适配器在外部手动创建自定义的 Tensor + Context Parallel 进程组。
2. 严密的 World Size 验证
装饰器增加了一层额外的检查,确保:
Total World Size%(TP×PP×CP)==0保证了分布式拓扑的合法性。
3. 新增的四大护法函数
为了支持新的并行模式,适配器向 Megatron 注入了四个全新 API:
-
get_tensor_context_parallel_group()
-
get_tensor_context_parallel_rank()
-
get_tensor_context_parallel_world_size()
-
get_tensor_context_parallel_src_rank()
这使得上层应用可以像调用原生 API 一样轻松处理 Context Parallel 逻辑。
深度剖析 3:极致丝滑的模型与优化器配置
你是否厌倦了手动解析几百个参数来配置 Optimizer?TeleTron 再次利用装饰器优化了 setup_model_and_optimizer。
1. 自动化配置
利用 Python 的 dataclasses,装饰器动态提取 OptimizerConfig 的字段,并从 args 中自动填充。这意味着:你再也不用写冗长的参数传递代码了。
2. 灵活的检查点加载 (Strict=False)
在微调或迁移学习场景下,模型结构往往与 Checkpoint 不完全匹配。TeleTron 强制开启 strict=False,允许加载部分权重的模型。这对于实验性质的开发极其友好。
总结
TeleTron 的 megatron_adaptor.py 是Python 动态特性与设计模式结合的典范。
它没有选择"硬分叉(Hard Fork)" Megatron-Core,而是选择了一条更优雅的道路:
-
用适配器替换核心组件(DDP 性能优化)。
-
用装饰器增强原有功能(Context Parallel 扩展)。
-
用元编程简化配置流程(自动化 Setup)。
对于想要深入理解分布式训练架构,或者试图定制 Megatron 的开发者来说,TeleTron 提供了一份满分作业。
参考文件:megatron_adaptor.py, distributed_data_parallel.py, parallel_state.py, training.py
喜欢这篇文章?欢迎点赞、收藏并关注,获取更多 LLM 底层架构硬核解析!