文章目录
说明
- 本文内容结合网络资料和实战总结,仅供学习和交流使用。
- 本文实验环境为Ubuntu 24+单卡3090,只训练了1个轮次,但可以通过日志明显看到损失值的下降,如果需要进一步提升模型性能,可以寻找更多数据集和增加训练轮次、硬件,进行微调训练。
主流微调工具
- 模型微调三剑客:unsloth、Llam_factory、ms-SWIFT。
- unsloth 是一个专为大型语言模型(LLM)设计的微调框架,旨在提高微调效率并减少显存占用。它通过手动推导计算密集型数学步骤并手写 GPU 内核,实现无需硬件更改即可显著加快训练速度。unsloth 与 HuggingFace 生态兼容,可以很容易地transformers、peft、trl 等库结合,以实现模型的监督微调(SFT)和直接偏好优化(DPO),仅需模型的加载方式,无需对现有训练代码进行修改。
- LLaMA-Factory 是一个统一且高效的微调框架,旨在为超过 100 种大型语言模型(LLMs)和视觉语言模型(VLMs)提供便捷的微调支持。 用户能够灵活地定制模型以适应各种下游任务。
- ms-swift(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭社区(ModelScope)开发的高效微调和部署框架,旨在为研究人员和开发者提供一站式的大模型与多模态大模型的训练、推理、评测、量化和部署解决方案,提供基于 Gradio 的 We和量化操作,简化大模型的全链路流程。
环境准备
- 创建虚拟环境,并安装依赖包(这里建议使用魔法环境)。
conda create -n deepseek-ft python=3.13.9
conda activate deepseek-ft
pip install unsloth
pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
pip install datasets
conda install ipykernel
python -m ipykernel install --user --name deepseek-ft --display-name deepseek-ft
pip install wandb
pip install nbformat
pip install load_dotenv
- 在项目根目录下创建
.env文件,并根据实际情况修改。
WANDB_API_KEY="local-xxxx"
WANDB_NOTEBOOK_NAME="/home/yang/code/deepseek-ft/train.ipynb"
jupyter lab
- 最后,验证模型以及环境是否可用。如果出现以外的错误,可以尝试将transformers降级
pip show transformers==4.57.1。
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = torch.bfloat16
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/home/yang/models/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
print(model)
print(tokenizer)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 现在继续你的推理代码
question = "请问如何证明根号2是无理数?"
# 在调用 tokenizer 时,明确要求返回 attention_mask
inputs = tokenizer(
[question],
return_tensors="pt",
padding=True, # 如果处理多条,这个会自动填充
truncation=True, # 截断过长的文本
).to("cuda")
# 将 attention_mask 传递给 model.generate
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask, # 【关键修改】传入 attention_mask
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])
prompt_style_chat = """请写出一个恰当的回答来完成当前对话任务。
### Instruction:
你是一名助人为乐的助手。
### Question:
{}
### Response:
<think>{}"""
question = "你好,好久不见,我研究生日子真难过!"
# 调用 tokenizer 时,让它生成 attention_mask
inputs = tokenizer(
[question],
return_tensors="pt",
padding=True,
).to("cuda")
# 手动创建 attention_mask
# 1 代表非 pad token,0 代表 pad token
# 对于单条输入,如果没有 padding,attention_mask 全是 1
attention_mask = inputs['attention_mask']
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=attention_mask, # 传入手动创建的 mask
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])
医疗数据集下载和处理
mkdir delicate_medical_r1_data
modelscope download --dataset krisfu/delicate_medical_r1_data --local_dir ./delicate_medical_r1_data
import json
# 定义数据文件的路径
data_file_path = '/home/yang/dataset/delicate_medical_r1_data/r1_data_example.jsonl'
# 存储数据的列表
data_list = []
print(f"正在从 {data_file_path} 加载数据...")
try:
# 'r' 表示读取模式, encoding='utf-8' 是一个好习惯
with open(data_file_path, 'r', encoding='utf-8') as f:
for line in f:
# jsonl 文件的每一行都是一个独立的 JSON 对象
data_list.append(json.loads(line))
print(f"成功加载 {len(data_list)} 条数据。")
# --- 查看前3条内容 ---
print("\n--- 前3条数据内容 ---")
for i, item in enumerate(data_list[:3]):
print(f"--- 第 {i+1} 条 ---")
# 使用 json.dumps 可以让输出格式更美观
print(json.dumps(item, indent=2, ensure_ascii=False))
print("-" * 20) # 分隔线
except FileNotFoundError:
print(f"错误:找不到文件 {data_file_path}")
print("请检查文件路径是否正确,或者你的Python脚本是否在正确的目录下运行。")
except Exception as e:
print(f"读取文件时发生错误: {e}")
正在从 /home/yang/dataset/delicate_medical_r1_data/r1_data_example.jsonl 加载数据...
成功加载 2407 条数据。
--- 前3条数据内容 ---
--- 第 1 条 ---
{
"instruction": "xx",
"question": "xxx",
"think": "xxx",
"answer": "xxx",
"metrics": {
"quality_f1": 1.0
}
}
- 转化数据,将其修改为我们微调需要的格式,处理的结果保存为
./data/formatted_data_zh_merged.jsonl。
import json
import os
# 定义中文提示词模板
train_prompt_style = """以下是一个任务说明,配有提供更多背景信息的输入。
请写出一个恰当的回答来完成该任务。
在回答之前,请仔细思考问题,并按步骤进行推理,确保回答逻辑清晰且准确。
### 指令:
您是一位具有高级临床推理、诊断和治疗规划知识的医学专家。
请回答以下医学问题。
### 问题:
{}
### 回答:
<think>
{}
</think>
{}"""
EOS_TOKEN = '<|end▁of▁sentence|>'
# 定义数据转换函数
def formatting_prompts_func(examples):
# examples 是一个字典列表,例如: [{"key": "value"}, {"key": "value"}]
# 使用列表推导式从每个字典项中提取所需字段
questions = [f"{item['instruction']}\n\n{item['question']}" for item in examples]
thinks = [item['think'] for item in examples]
answers = [item['answer'] for item in examples]
texts = []
# zip 函数现在可以正确地并行遍历这三个列表
for question, think, answer in zip(questions, thinks, answers):
text = train_prompt_style.format(question, think, answer) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
# 加载本地数据集
data_file_path = '/home/yang/dataset/delicate_medical_r1_data/r1_data_example.jsonl'
data_list = []
output_dir = './data'
output_file = os.path.join(output_dir, 'formatted_data_zh_merged.jsonl')
print(f"正在从 {data_file_path} 加载数据...")
try:
with open(data_file_path, 'r', encoding='utf-8') as f:
for line in f:
data_list.append(json.loads(line))
print(f"成功加载 {len(data_list)} 条数据。")
# 应用格式化函数
formatted_dataset = formatting_prompts_func(data_list)
#查看转换后的前2条数据
print("\n--- 转换后的前2条数据 ---")
for i in range(min(2, len(formatted_dataset["text"]))):
print(f"--- 第 {i+1} 条 ---")
print(formatted_dataset["text"][i])
# print(formatted_dataset["text"][i][:1000] + "..." if len(formatted_dataset["text"][i]) > 1000 else formatted_dataset["text"][i])
print("-" * 50)
# 创建输出目录(如果不存在)
if not os.path.exists(output_dir):
print(f"创建输出目录: {output_dir}")
os.makedirs(output_dir, exist_ok=True)
# 保存转换后的数据
with open(output_file, 'w', encoding='utf-8') as f:
for text in formatted_dataset["text"]:
f.write(json.dumps({"text": text}, ensure_ascii=False) + '\n')
print("\n转换后的数据已保存到 formatted_data_zh_merged.jsonl")
except FileNotFoundError:
print(f"错误:找不到文件 {data_file_path}")
except Exception as e:
print(f"处理文件时发生错误: {e}")
正在从 /home/yang/dataset/delicate_medical_r1_data/r1_data_example.jsonl 加载数据...
成功加载 2407 条数据。
--- 转换后的前2条数据 ---
--- 第 1 条 ---
以下是一个任务说明,配有提供更多背景信息的输入。
请写出一个恰当的回答来完成该任务。
在回答之前,请仔细思考问题,并按步骤进行推理,确保回答逻辑清晰且准确。
### 指令:
您是一位具有高级临床推理、诊断和治疗规划知识的医学专家。
请回答以下医学问题。
### 问题:
xxx
### 回答:
<think>
xxx
</think>
xxx<|end▁of▁sentence|>
创建输出目录: ./data
转换后的数据已保存到 formatted_data_zh_merged.jsonl
模型微调
# 导入必要的库
from unsloth import FastLanguageModel, is_bfloat16_supported
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
import os
# =============================================================================
# 模型配置参数 (针对RTX 3090优化)
# =============================================================================
# 3090有24GB显存,建议使用4bit量化以节省显存
max_seq_length = 2048 # 3090可以处理2048长度,如遇OOM可降至1024
dtype = torch.bfloat16 # 3090支持bfloat16,比fp16更稳定
load_in_4bit = True # 启用4bit量化,显著降低显存占用
# =============================================================================
# 加载基础模型和数据集
# =============================================================================
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="/home/yang/models/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
)
data_file_path = './data/formatted_data_zh_merged.jsonl'
# 使用 datasets 库加载 JSONL 文件 它会自动将每一行解析为一个字典,并组合成一个数据集对象
dataset = load_dataset('json', data_files=data_file_path, split='train')
# 打印一些信息以验证加载是否成功
print(f"成功加载数据集,共 {len(dataset)} 条样本。")
print("第一条样本预览:")
print(dataset[0])
# ------------------------------------
# =============================================================================
# LoRA微调配置 (针对3090优化)
# =============================================================================
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA秩,3090可以处理16-32
target_modules=[ # 需要微调的模块
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16, # LoRA缩放参数,通常设为r的1-2倍
lora_dropout=0, # 3090训练时可以设为0以加速
bias="none", # 不训练偏置项
use_gradient_checkpointing="unsloth", # 启用梯度检查点节省显存
random_state=3407, # 随机种子
use_rslora=False, # 不使用RSLoRA
loftq_config=None, # 不使用LoFTQ
)
# =============================================================================
# 训练参数配置 (针对3090优化)
# =============================================================================
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2, # 数据处理并行度,3090可以设为2-4
args=TrainingArguments(
# 训练轮次
num_train_epochs = 1,
# 批次大小配置 (关键参数)
pe| `logging_steps=10` | **每 10 步记录一次训练日志** |r_device_train_batch_size=1, # 3090建议从1开始,如显存充足可增至2
gradient_accumulation_steps=8, # 有效批次大小=1*8=8,适合3090
# 训练步数与学习率
warmup_steps=5, # 预热步数
max_steps=60, # 总训练步数
learning_rate=2e-4, # 3090推荐学习率
# 优化与精度设置
fp16=not is_bfloat16_supported(), # 3090支持bfloat16,所以设为False
bf16=is_bfloat16_supported(), # 3090启用bfloat16
optim="adamw_8bit", # 8bit优化器节省显存
weight_decay=0.01, # 权重衰减
lr_scheduler_type="linear", # 线性学习率衰减
# 其他设置
logging_steps=10, # 每10步记录一次
seed=3407, # 随机种子
output_dir="outputs", # 输出目录
),
)
#------该部分wandb监控代码(可选)
import wandb
from dotenv import load_dotenv
# 自动加载.env 文件
load_dotenv()
# 获取环境变量
WANDB_API_KEY = os.getenv('WANDB_API_KEY')
wandb.login(key=WANDB_API_KEY,relogin =True)
run = wandb.init(
entity="yuan",
project="deepseek-unsloth-ft",
settings=wandb.Settings(base_url="http://localhost:8000")
)
#------------
trainer_stats = trainer.train()
| 参数 |
作用 |
model=model |
指定需要进行微调的 预训练模型 |
tokenizer=tokenizer |
指定 分词器,用于处理文本数据 |
train_dataset=dataset |
传入 训练数据集 |
dataset_text_field="text" |
指定数据集中包含 训练文本的列 |
max_seq_length=max_seq_length |
最大序列长度,控制输入文本的最大 Token 数量 |
dataset_num_proc=2 |
数据加载的并行进程数,提高数据预处理效率 |
| 参数 |
作用 |
| num_train_epochs |
设置模型训练的轮次 |
per_device_train_batch_size=1 |
每个 GPU/设备 的训练批量大小(较小值适合大模型) |
gradient_accumulation_steps=8 |
梯度累积步数 (相当于 batch_size=1 × 8 = 8) |
warmup_steps=5 |
预热步数(初始阶段学习率较低,然后逐步升高) |
max_steps=60 |
最大训练步数(控制训练的总步数,此处总共约消耗60*8=480条数据) |
learning_rate=2e-4 |
学习率 (2e-4 = 0.0002,控制权重更新幅度) |
fp16=not is_bfloat16_supported() |
如果 GPU 不支持 bfloat16,则使用 fp16(16位浮点数) |
bf16=is_bfloat16_supported() |
如果 GPU 支持 bfloat16,则启用 bfloat16(训练更稳定) |
optim="adamw_8bit" |
使用 adamw_8bit(8-bit AdamW优化器)减少显存占用 |
weight_decay=0.01 |
权重衰减(L2 正则化),防止过拟合 |
lr_scheduler_type="linear" |
学习率调度策略(线性衰减) |
logging_steps=10 |
每 10 步记录一次训练日志 |
seed=3407 |
随机种子,保证实验结果可复现 |
output_dir="outputs" |
训练结果的输出目录 |
- 避免冲突:明确地关闭一个选项,同时开启另一个选项,可以防止训练器在配置上产生歧义。
| 特性 |
bfloat16 (BF16) |
fp16 (FP16) |
| 数值范围 |
与 float32 相同 |
比 float32 小得多 |
| 数值精度 |
8位有效数字 |
10位有效数字 |
| 主要优势 |
不易出现数值上溢/下溢 ,训练更稳定,通常不需要损失缩放。 |
数值范围小,容易出现梯度为零或无穷大的问题,通常需要损失缩放来维持训练稳定。 |
| 适用场景 |
大模型训练的首选,尤其当模型对数值稳定性敏感时。 |
在不支持BF16的硬件上是唯一选择,或者在某些推理场景下为了极致性能。 |
微调效果简单验证
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 现在继续你的推理代码
question = "医生,我最近耳鸣得厉害,听说电刺激疗法对耳鸣有帮助,这种疗法适合我吗?"
# 在调用 tokenizer 时,明确要求返回 attention_mask
inputs = tokenizer(
[question],
return_tensors="pt",
padding=True, # 如果处理多条,这个会自动填充
truncation=True, # 截断过长的文本
).to("cuda")
# 将 attention_mask 传递给 model.generate
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask, # 传入 attention_mask
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0]) # 通常只解码第一个结果
<|begin▁of▁sentence|>医生,我最近耳鸣得厉害,听说电刺激疗法对耳鸣有帮助,这种疗法适合我吗?有什么注意事项吗?
### 回答:
<think>
嗯,用户问的是关于耳鸣的电刺激疗法,还有是否适合他们以及注意事项。首先,我需要回忆一下耳鸣的常见原因和电刺激疗法的基本原理。耳鸣通常是由于血管扩张导致血液流动不畅,或者是神经系统的调节问题。电刺激疗法可能通过电流刺激外周神经来促进血管收缩,从而减少血液流动不畅的情况。
接下来,我得考虑用户的具体情况。用户提到自己耳鸣得厉害,可能已经尝试过其他方法不管效果如何,现在想了解电刺激疗法的可行性。首先要确定是否适合他们。电刺激疗法通常用于中重度的耳鸣,特别是伴随眩晕、头痛或耳朵充血的情况。如果用户的情况符合这些症状,那么可能适合。反之,如果耳鸣轻微,或者伴随其他严重症状如血压升高或心脏病,可能不适合。
然后是注意事项。首先是病情严重性,如果有心脏问题,比如高血压或心脏病,电刺激可能会加重症状,所以必须排除。另外,电刺激可能会导致耳朵或头部不适,所以需要提醒用户术前检查,确保没有其他问题。还有术后恢复时间,可能需要休息一段时间,避免剧烈运动或其他激烈活动。
用户可能没有明确提到病史,比如心脏病史或者其他感染史,所以需要建议他们咨询医生,确保安全。另外,电刺激疗法的效果可能因人而异,不能保证效果,所以要强调这一点,避免用户有过高的期望。
还要考虑用户可能的潜在疑虑,比如疗法的风险、是否有副作用。电刺激疗法虽然安全,但也可能有轻微不适,所以需要解释清楚。同时,可能需要提到术前准备,比如避免咖啡因、烟酒等,保持良好的生活习惯。
最后,总结的时候要结构清晰,先判断是否适合,再列出注意事项,最后建议咨询医生。确保回答准确且易懂,避免专业术语过多,让用户容易理解。
</think>
您好,关于耳鸣的电刺激疗法,确实是一种常见的治疗方法。但在决定是否适合您之前,建议您先咨询医生,了解您的具体病情,确保没有其他严重的健康问题,比如心脏病或高血压等。电刺激疗法通常用于中重度耳鸣,特别是伴有眩晕、头痛或耳朵充血的情况。如果您有任何心脏或血压问题,或者耳鸣持续时间较长,可能需要进一步检查。如果您决定进行电刺激疗法,术前需要做好充分的准备,确保安全。术后可能需要休息一段时间,避免剧烈运动或其他过度活动。希望您能够尽快找到适合自己的治疗方法,祝您早日恢复健康。<|end▁of▁sentence|>
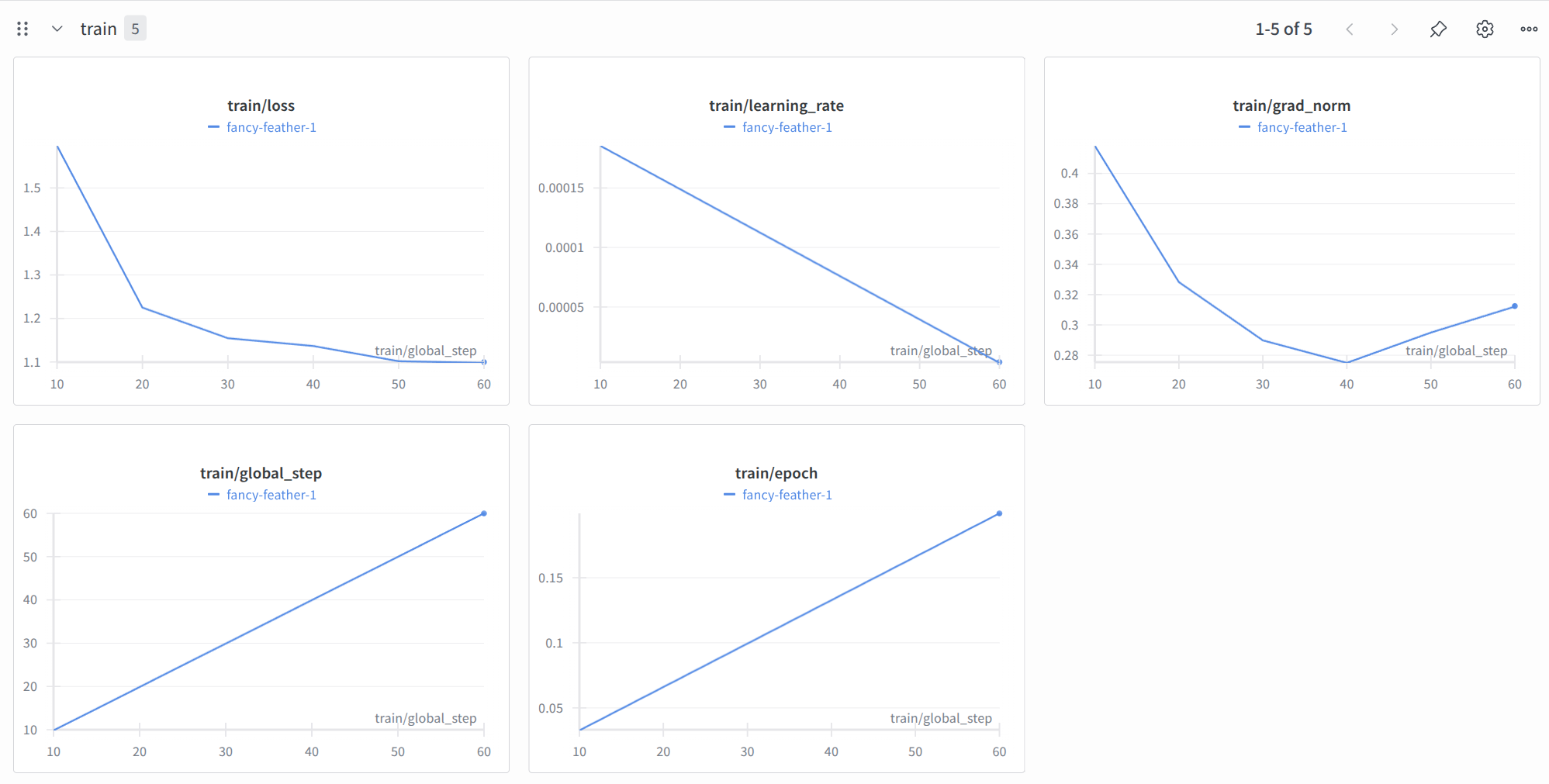
wandb日志查看
- 访问本地
localhost:8000即可查看训练过程的详细日志。
模型合并和导出
- unsloth在微调结束后,会自动更新模型权重(在缓存中),无需手动合并模型权重即可直接调用微调后的模型。所以存在两种模型到处方式:一种是微调完后立即导出,一种是后续导出(重新加载基础模型和权重)。
立即导出方式
new_model_local = "deepseek-r1-distill-8b-merged-finetuned"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
后续导出方式
- 在训练结束后,重新加载基座模型和训练权重导出模型。
# 导入必要的库
import torch
from unsloth import FastLanguageModel
from transformers import AutoTokenizer
# =============================================================================
# 配置参数
# =============================================================================
# 训练输出目录,里面包含LoRA 适配器权重
lora_adapter_path = "outputs"
# 保存最终合并模型的新目录
merged_model_path = "/home/yang/models/deepseek-r1-distill-8b-merged-finetuned"
# 基础模型的路径,unsloth 需要它来重建模型架构
base_model_name = "/home/yang/models/DeepSeek-R1-Distill-Llama-8B"
# =============================================================================
# 1. 加载微调后的 LoRA 模型和 Tokenizer
# =============================================================================
print("正在加载微调后的 LoRA 模型...")
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=base_model_name,
# 从基础模型加载最大序列长度和数据类型,保持一致
max_seq_length=2048,
torch_dtype=torch.bfloat16,
load_in_4bit=True, # 加载时仍然使用4bit量化以节省内存
)
print("LoRA 模型加载成功!")
# =============================================================================
# 2. 合并 LoRA 适配器并卸载
# =============================================================================
print("正在合并 LoRA 权重到基础模型中...")
# merge_and_unload 会将 LoRA 权重合并,并移除 PEFT 包装,返回一个标准的 Transformers 模型
merged_model = model.merge_and_unload()
print("模型合并完成!")
# =============================================================================
# 3. 保存合并后的完整模型和 Tokenizer
# =============================================================================
print(f"正在将合并后的模型保存到: {merged_model_path}")
# 保存模型权重和配置文件
merged_model.save_pretrained(merged_model_path, safe_serialization=True)
# 保存分词器文件
tokenizer.save_pretrained(merged_model_path)
print("模型和分词器保存成功!")
# =============================================================================
# (可选) 4. 将模型推送到 Hugging Face Hub
# =============================================================================
# 如果你想将模型公开,可以取消下面的注释并填写你的信息
# 首先需要登录: huggingface-cli login
# try:
# print("正在将模型推送到 Hugging Face Hub...")
# merged_model.push_to_hub("你的HuggingFace用户名/你的仓库名称", private=False)
# tokenizer.push_to_hub("你的HuggingFace用户名/你的仓库名称", private=False)
# print("模型推送成功!")
# except Exception as e:
# print(f"推送失败: {e}")
print("\n所有操作已完成!")
print(f"你可以在 '{merged_model_path}' 目录中找到最终的模型文件。")
# =============================================================================
# (可选) 5. 验证加载合并后的模型
# =============================================================================
print("\n正在验证加载新保存的模型...")
from transformers import AutoModelForCausalLM, AutoTokenizer
# 使用标准的 Transformers 库加载模型
try:
test_model = AutoModelForCausalLM.from_pretrained(
merged_model_path,
device_map="auto", # 自动分配GPU/CPU
torch_dtype=torch.bfloat16
)
test_tokenizer = AutoTokenizer.from_pretrained(merged_model_path)
print("验证成功!模型已成功加载为标准的 Transformers 模型。")
except Exception as e:
print(f"验证失败: {e}")